Prometheus介绍
- 1. Prometheus 简介
- 2. Prometheus 的特点
- 3. Prometheus 的架构
- 4. Prometheus 的基本组件
- 5. Prometheus工作流程
- 6. Prometheus和Zabbix对比
- 7. Prometheus的部署模式
- 7.1 基本高可用模式
- 7.2 基本高可用+远程存储
- 7.3 基本HA + 远程存储 + 联邦集群方案
- 8. Prometheus能监控什么
- 9. Prometheus对kubernetes的监控

1. Prometheus 简介
普罗米修斯(古希腊语:Προμηθεύς、英语:Prometheus,名字的含义是“先见之明”),是古希腊神话中泰坦一族的神明之一,他是地母盖亚与乌拉诺斯的儿子伊阿珀托斯与克吕墨涅所生,和厄庇墨透斯是兄弟。普罗米修斯曾与智慧女神雅典娜共同创造了人类,普罗米修斯负责用泥土雕塑出人的形状,雅典娜则为泥人灌注灵魂,并教会了人类很多知识。普罗米修斯还反抗宙斯,将火种带到人间。
Prometheus是由前 Google 工程师从 2012 年开始在Soundcloud以开源软件的形式进行研发的系统监控和告警工具包,自此以后,许多公司和组织都采用了 Prometheus 作为监控告警工具。Prometheus 的开发者和用户社区非常活跃,它现在是一个独立的开源项目,可以独立于任何公司进行维护。为了证明这一点,Prometheus 于 2016 年 5 月加入CNCF基金会,成为继Kubernetes之后的第二个 CNCF 托管项目。
Prometheus支持多种语言(Go,java,python,ruby官方提供客户端,其他语言有第三方开源客户端)
Cloud Native Computing Foundation,云原生计算基金会(简称CNCF)是一个开源软件基金会,它致力于云原生(Cloud Native)技术的普及和可持续发展。官网 https://www.cncf.io/
2. Prometheus 的特点
- 多维度数据模型
- 灵活的查询语言(PromQL):可以对采集的metrics指标进行加法,乘法,连接等操作;
- 可以直接在本地部署,不依赖其他分布式存储;
- 通过基于HTTP的(pull)方式采集时序数据;
- 可以通过中间网关(pushgateway)的方式把时间序列数据推送到prometheus server端;
- 可通过服务发现或者静态配置来发现目标服务对象(targets)。
- 有多种可视化图像界面,如Grafana等。
- 高效的存储,每个采样数据占3.5 bytes左右,300万的时间序列,30s间隔,保留60天,消耗磁盘大概200G。
- 做高可用,可以对数据做异地备份,联邦集群,部署多套prometheus,pushgateway上报数据
多维度数据模型:每一个时间序列数据都由metric度量指标名称和它的标签labels键值对集合唯一确定:这个metric度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收http请求的总计数)。labels开启了Prometheus的多维数据模型:对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。(例如:所有包含度量名称为/api/tracks的http请求,打上method=POST的标签,则形成了具体的http请求)。这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。改变任何度量上的任何标签值,则会形成新的时间序列图。
3. Prometheus 的架构
Prometheus 的整体架构以及生态系统组件如下图所示:
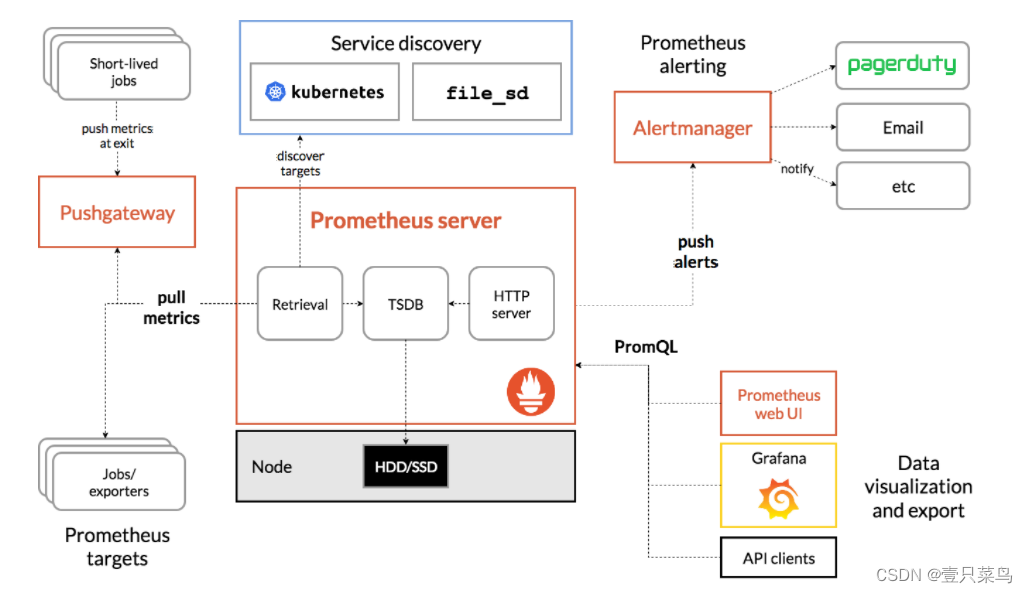
- Prometheus Server:Retrieval通过 HTTP Server定时向服务动态发现的目标抓取metrics(指标)数据,每个抓取目标都需要暴露一个HTTP服务接口(符合Prometheus规范)用 于Prometheus定时抓取。并将采集来的监控数据持久化后存在TSDB中;
- PromQL查询:可以通过Prometheus WebUi,Api Clients或Grafana使用PromQL来查询各种指标数据;
- 告警推送:将计算后超过阈值的告警发送至Alertmanager,经过Alertmanager的进一步分组,抑制,静默后发送到更丰富的告警通道;
- 采集目标:被采集的目标既可以是各种官方Exporter,也可以是实现了Prometheus规范的三方接口(如Nacos和Arrangodb的metrics接口),如:PushGateway等
TSDB:时间序列数据库 (Time Series Database , 简称 TSDB)是一种 高性能、低成本、稳定可靠的在线时间序列数据库
4. Prometheus 的基本组件
- Prometheus Server: 用于收集和存储时间序列数据。
- Client Library: 客户端库,检测应用程序代码,当Prometheus抓取实例的HTTP端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到prometheus server端。
- Exporters: prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到prometheus server端,所有向promtheus server提供监控数据的程序都可以被称为exporter
- Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去重,分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉, slack等。
- Grafana:监控仪表盘,可视化监控数据
- pushgateway: 各个目标主机可上报数据到pushgateway,然后prometheus server统一从pushgateway拉取数据。
5. Prometheus工作流程
- Prometheus server可定期从活跃的(up)目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态job或者服务发现的方式被prometheus server采集到,这种方式默认的pull方式拉取指标;也可通过pushgateway把采集的数据上报到prometheus server中;还可通过一些组件自带的exporter采集相应组件的数据;
- Prometheus server把采集到的监控指标数据保存到本地磁盘或者数据库;
- Prometheus采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到alertmanager
- Alertmanager通过配置报警接收方,发送报警到邮件,微信或者钉钉等
- Prometheus 自带的web ui界面提供PromQL查询语言,可查询监控数据
- Grafana可接入prometheus数据源,把监控数据以图形化形式展示出
6. Prometheus和Zabbix对比
前面的文章中,我们介绍了zabbix,同为监控软件的prometheus和zabbix,我们在生产环境中如何选择呢?
- 数据模型和查询语言
Prometheus使用一个称为PromQL的查询语言来查询和处理时间序列数据。PromQL支持许多数据模型和查询功能,包括度量标准、标签和聚合函数。Zabbix使用自己的数据模型和查询语言,包括项、触发器和动作等概念。 - 存储方式
Prometheus使用一种称为TSDB的时间序列数据库来存储时间序列数据。TSDB使用一种称为WAL的写前日志,以确保数据的可靠性。Zabbix使用关系型数据库来存储数据。 - 自动化和配置管理
Prometheus具有自动化和自动配置的能力,它可以自动发现服务和指标,并对它们进行监控。Zabbix也提供了类似的功能,但需要手动配置。 - 可视化和警报
Zabbix和Prometheus都支持可视化和警报功能。Zabbix提供了一个基于Web的前端界面,可以查看监控数据和设置警报。Prometheus通常与Grafana等工具一起使用,以实现更高级的可视化和警报功能。 - 性能和扩展性
Prometheus在性能和扩展性方面表现良好,能够处理大规模的时间序列数据。Zabbix也具有良好的性能和扩展性,但在大规模监控方面可能需要更多的资源和配置。
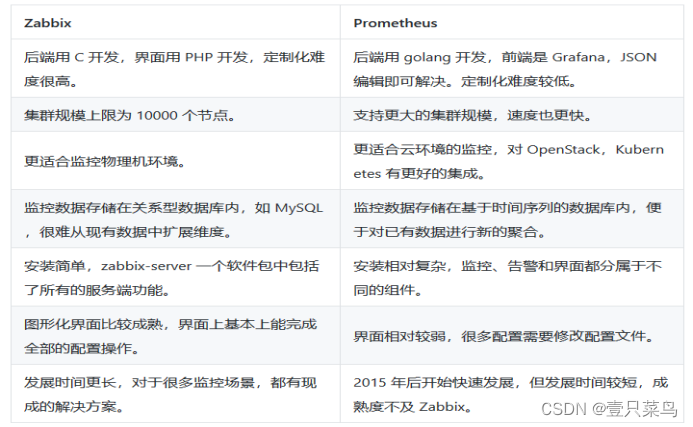
总结:
- Zabbix
上手难度要低很多,对于传统的服务器、系统、网络等都有优秀的监控能力,但是定制化程度低且对于云原生产品的支持也不太好,适合对于监控方面要求不高、整体技术能力较弱的传统企业使用。 - Prometheus是云原生时代的监控工具,因此对于Kubernetes等容器产品的支持非常友好,且定制化程度高。但是
上手难度也会更大,因此更适合具有较好技术能力、监控需求复杂的互联网企业使用。 - Zabbix 更加适合用于
本地计算机的监控,而 Prometheus 更适合在现在流行的云计算监控上使用。
7. Prometheus的部署模式
7.1 基本高可用模式
基本的HA模式只能确保Promthues服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
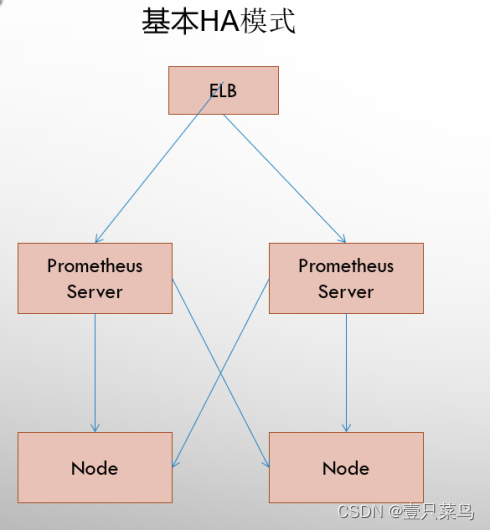
7.2 基本高可用+远程存储
在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当Promthues Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Promthues Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues Server的可迁移性的场景。
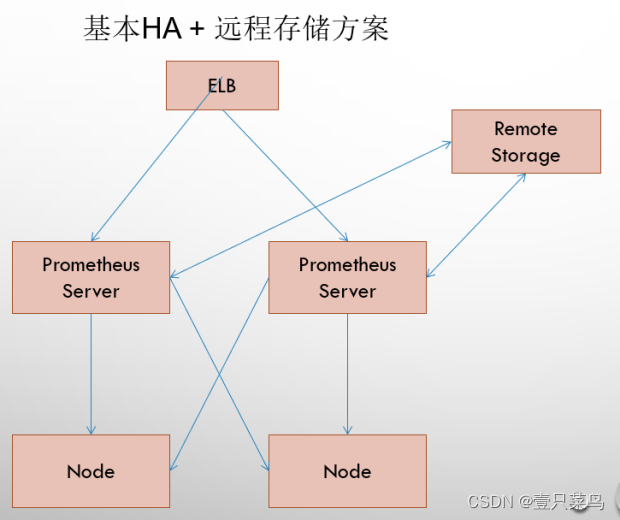
7.3 基本HA + 远程存储 + 联邦集群方案
Promthues的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。例如,一个Promthues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
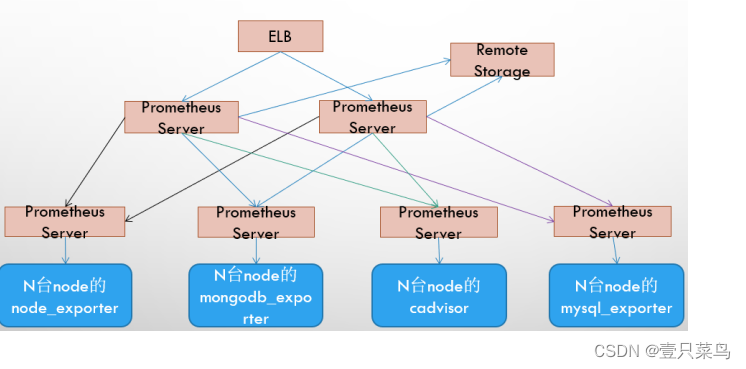
8. Prometheus能监控什么
# Databases---数据库Aerospike exporterClickHouse exporterConsul exporter (official)Couchbase exporterCouchDB exporterElasticSearch exporterEventStore exporterMemcached exporter (official)MongoDB exporterMSSQL server exporterMySQL server exporter (official)OpenTSDB ExporterOracle DB ExporterPgBouncer exporterPostgreSQL exporterProxySQL exporterRavenDB exporterRedis exporterRethinkDB exporterSQL exporterTarantool metric libraryTwemproxy
# Hardware related---硬件相关apcupsd exporterCollins exporterIBM Z HMC exporterIoT Edison exporterIPMI exporterknxd exporterNetgear Cable Modem ExporterNode/system metrics exporter (official)NVIDIA GPU exporterProSAFE exporterUbiquiti UniFi exporter
# Messaging systems---消息服务Beanstalkd exporterGearman exporterKafka exporterNATS exporterNSQ exporterMirth Connect exporterMQTT blackbox exporterRabbitMQ exporterRabbitMQ Management Plugin exporter
# Storage---存储Ceph exporterCeph RADOSGW exporterGluster exporterHadoop HDFS FSImage exporterLustre exporterScaleIO exporter
# HTTP---网站服务Apache exporterHAProxy exporter (official)Nginx metric libraryNginx VTS exporterPassenger exporterSquid exporterTinyproxy exporterVarnish exporterWebDriver exporter
# APIsAWS ECS exporterAWS Health exporterAWS SQS exporterCloudflare exporterDigitalOcean exporterDocker Cloud exporterDocker Hub exporterGitHub exporterInstaClustr exporterMozilla Observatory exporterOpenWeatherMap exporterPagespeed exporterRancher exporterSpeedtest exporter
# Logging---日志Fluentd exporterGoogle's mtail log data extractorGrok exporter
# Other monitoring systemsAkamai Cloudmonitor exporterAlibaba Cloudmonitor exporterAWS CloudWatch exporter (official)Cloud Foundry Firehose exporterCollectd exporter (official)Google Stackdriver exporterGraphite exporter (official)Heka dashboard exporterHeka exporterInfluxDB exporter (official)JavaMelody exporterJMX exporter (official)Munin exporterNagios / Naemon exporterNew Relic exporterNRPE exporterOsquery exporterOTC CloudEye exporterPingdom exporterscollector exporterSensu exporterSNMP exporter (official)StatsD exporter (official)
# Miscellaneous---其他ACT Fibernet ExporterBamboo exporterBIG-IP exporterBIND exporterBitbucket exporterBlackbox exporter (official)BOSH exportercAdvisorCachet exporterccache exporterConfluence exporterDovecot exportereBPF exporterEthereum Client exporterJenkins exporterJIRA exporterKannel exporterKemp LoadBalancer exporterKibana ExporterMeteor JS web framework exporterMinecraft exporter modulePHP-FPM exporterPowerDNS exporterPresto exporterProcess exporterrTorrent exporterSABnzbd exporterScript exporterShield exporterSMTP/Maildir MDA blackbox proberSoftEther exporterTransmission exporterUnbound exporterXen exporter
# Software exposing Prometheus metrics---Prometheus度量指标App Connect EnterpriseBallerinaCephCollectdConcourseCRG Roller Derby Scoreboard (direct)Docker DaemonDoorman (direct)Etcd (direct)FlinkFreeBSD KernelGrafanaJavaMelodyKubernetes (direct)Linkerd
9. Prometheus对kubernetes的监控
对于Kubernetes而言,我们可以把当中所有的资源分为几类:
- 基础设施层(Node):集群节点,为整个集群和应用提供运行时资源
- 容器基础设施(Container):为应用提供运行时环境
- 用户应用(Pod):Pod中会包含一组容器,它们一起工作,并且对外提供一个(或者一组)功能
- 内部服务负载均衡(Service):在集群内,通过Service在集群暴露应用功能,集群内应用和应用之间访问时提供内部的负载均衡
- 外部访问入口(Ingress):通过Ingress提供集群外的访问入口,从而可以使外部客户端能够访问到部署在Kubernetes集群内的服务
因此,如果要构建一个完整的监控体系,我们应该考虑,以下5个方面:
- 集群节点状态监控:从集群中各节点的kubelet服务获取节点的基本运行状态;
- 集群节点资源用量监控:通过Daemonset的形式在集群中各个节点部署Node Exporter采集节点的资源使用情况;
- 节点中运行的容器监控:通过各个节点中kubelet内置的cAdvisor中获取个节点中所有容器的运行状态和资源使用情况;
- 如果在集群中部署的应用程序本身内置了对Prometheus的监控支持,那么我们还应该找到相应的Pod实例,并从该Pod实例中获取其内部运行状态的监控指标。
- 对k8s本身的组件做监控:apiserver、scheduler、controller-manager、kubelet、kube-proxy