import pypdf# 输入和输出文件名
input_pdf_filename = 'file.pdf'
output_pdf_filename = 'file_with_toc.pdf'
csv_filename = 'output.csv'# 创建一个PdfWriter实例
writer = pypdf.PdfWriter()# 读取原始PDF文件
with open(input_pdf_filename, "rb") as input_pdf:reader = pypdf.PdfReader(input_pdf)writer.append_pages_from_reader(reader)# 读取CSV文件并创建书签
bookmarks = [] # 用于维护书签层级结构
toc_entries = [] # 用于存储书签信息# 读取CSV文件内容
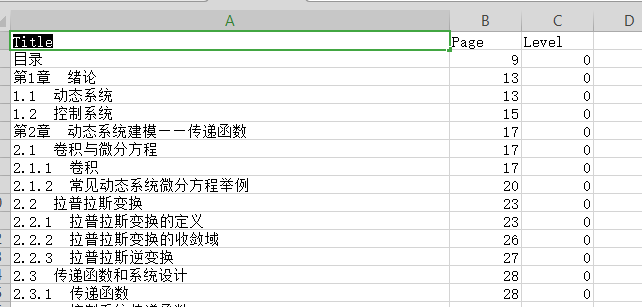
with open(csv_filename, 'r', encoding='GBK') as csv_file:next(csv_file) # 忽略第一行for line in csv_file:hierarchy, title, page_number = line.strip().split(',')page_number = int(page_number)# 根据父子层级关系确定层级数值level = hierarchy.count('.') + 1toc_entries.append((level, page_number, title))# 按CSV文件中的顺序,一行行添加书签并确保层级正确
for entry in toc_entries:level, page_number, title = entry# 根据层级确定父书签parent_bookmark = Noneif level > 1:# 从当前层级的上一层级开始查找父书签for i in range(level - 1, 0, -1):try:parent_bookmark = next(b for b in bookmarks if b.level == i)breakexcept StopIteration:continueelse:parent_bookmark = None# 添加书签bookmark = writer.add_outline_item(title=title, page_number=page_number, parent=parent_bookmark)bookmark.level = levelbookmarks.append(bookmark) # 添加到书签列表# 写入新的PDF文件
with open(output_pdf_filename, "wb") as output_pdf:writer.write(output_pdf)# 完成后关闭
writer.close()