| 课程链接 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology |
|---|---|
| 作业链接 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13287 |
| 实验三仓库链接 | https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践3 |
一、实验准备
1.查看Scrapy库安装

2.查看数据库安装

3.创建作业文件夹

二 、实验编写
作业1
- 数据采集实验
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践3/weather_spider
要求:指定一个网站,爬取该网站中的所有图片,例如中国气象网(http://www.weather.com.cn)。使用 scrapy 框架分别实现单线程和多线程的方式爬取。
输出信息:将下载的 Url 信息在控制台输出,并把下载的图片存储在 images 子文件中
1.创建 Scrapy 项目
(1)进入作业文件夹、创建新的 Scrapy 项目

(2)查看目录
(3)进入项目目录

2.编写爬虫
(1)创建爬虫文件
在 weather_spider/spiders 目录下创建一个爬虫文件:weather_spider.py
gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/weather_spider/weather_spider/spiders/weather_spider.py
(2)编辑爬虫文件,代码如下
点击查看代码
import scrapy
from itemadapter import ItemAdapter
import logging
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItemclass ImagePipeline(ImagesPipeline):def get_media_requests(self, item, info):for image_url in item['image_urls']:logging.info(f"Downloading image: {image_url}")yield scrapy.Request(image_url)def file_path(self, request, response=None, info=None, *, item=None):image_guid = request.url.split('/')[-1]return f'images/{image_guid}'def item_completed(self, results, item, info):image_paths = [x['path'] for ok, x in results if ok]if not image_paths:raise DropItem("Item contains no images")return item
(3)编辑 settings.py 文件,代码如下
gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/weather_spider/weather_spider/settings.py
点击查看代码
BOT_NAME = "weather_spider"
SPIDER_MODULES = ["weather_spider.spiders"]
NEWSPIDER_MODULE = "weather_spider.spiders"
# 启用图片下载管道
ITEM_PIPELINES = {'weather_spider.pipelines.ImagePipeline': 1,
}
# 配置图片存储路径
IMAGES_STORE = 'images'
# 配置并发请求数量
CONCURRENT_REQUESTS = 32
DOWNLOAD_DELAY = 0.5 # 每个请求之间的延迟时间
ROBOTSTXT_OBEY = True
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"(4)编辑 pipelines.py 文件,代码如下
gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/weather_spider/weather_spider/pipelines.py
点击查看代码
import scrapy
from itemadapter import ItemAdapter
import logging
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItemclass ImagePipeline(ImagesPipeline):def get_media_requests(self, item, info):for image_url in item['image_urls']:logging.info(f"Downloading image: {image_url}")yield scrapy.Request(image_url)def file_path(self, request, response=None, info=None, *, item=None):image_guid = request.url.split('/')[-1]return f'images/{image_guid}'def item_completed(self, results, item, info):image_paths = [x['path'] for ok, x in results if ok]if not image_paths:raise DropItem("Item contains no images")return item
(5)编辑 items.py 文件,代码如下
gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/weather_spider/weather_spider/items.py
3.运行爬虫
(1)在命令行或终端中,导航到项目根目录:scrapy crawl weather

(2)显示结果截图
gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践3/weather_spider/weather_spider/images/images
- 心得体会
虽然还是爬取天气网,但这次是第一次用scrapy框架,能感受到scrapy更加便捷,具有良好的可扩展性和灵活性。
作业2
- 数据采集实验
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践3/stock_spider
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath
MySQL数据库存储技术路线爬取股票相关信息。MySQL数据库存储
候选网站:
东方财富网:https://www.eastmoney.com/
新浪财经:http://finance.sina.com.cn/stock/
1.创建 Scrapy 项目
(1)进入作业文件夹、创建新的 Scrapy 项目

(2)查看目录

(3)进入项目目录

2.编写爬虫
(1)创建爬虫文件
在 stock_spider/spiders 目录下创建一个爬虫文件:stock_spider.py
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/stock_spider/stock_spider/spiders/stock_spider.py
(2)编辑爬虫文件,代码如下
点击查看代码
import scrapy
from stock_spider.items import StockItem
class StockSpider(scrapy.Spider):name = 'stock'allowed_domains = ['finance.sina.com.cn']start_urls = ['http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/lsjy/index.phtml']def parse(self, response):rows = response.xpath('//table[@class="list_table"]//tr')[1:] # 跳过表头for row in rows:item = StockItem()item['id'] = row.xpath('td[1]/text()').get()item['bStockNo'] = row.xpath('td[2]/a/text()').get()item['stockName'] = row.xpath('td[3]/a/text()').get()item['latestPrice'] = row.xpath('td[4]/text()').get()item['changePercent'] = row.xpath('td[5]/text()').get()item['changeAmount'] = row.xpath('td[6]/text()').get()item['volume'] = row.xpath('td[7]/text()').get()item['turnover'] = row.xpath('td[8]/text()').get()item['amplitude'] = row.xpath('td[9]/text()').get()item['highest'] = row.xpath('td[10]/text()').get()item['lowest'] = row.xpath('td[11]/text()').get()item['openPrice'] = row.xpath('td[12]/text()').get()item['closePrice'] = row.xpath('td[13]/text()').get()yield item
(3)编辑 settings.py 文件,代码如下
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/stock_spider/stock_spider/settings.py
点击查看代码
BOT_NAME = "stock_spider"
SPIDER_MODULES = ["stock_spider.spiders"]
NEWSPIDER_MODULE = "stock_spider.spiders"
ITEM_PIPELINES = {'stock_spider.pipelines.MySQLPipeline': 300,
}
# settings.py
DB_SETTINGS = {'db': 'stock_spider','user': 'root','passwd': '123456','host': 'localhost','port': 3306,
}
ROBOTSTXT_OBEY = False
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"(4)编辑 pipelines.py 文件,代码如下
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/stock_spider/stock_spider/pipelines.py
点击查看代码
import mysql.connector
from mysql.connector import errorcode
class MySQLPipeline:def __init__(self):self.connection = Noneself.cursor = Nonedef open_spider(self, spider):try:self.connection = mysql.connector.connect(host='localhost',user='root',password='123456',database='stock_spider')self.cursor = self.connection.cursor()self.create_table()except mysql.connector.Error as err:if err.errno == errorcode.ER_ACCESS_DENIED_ERROR:print("Something is wrong with your user name or password")elif err.errno == errorcode.ER_BAD_DB_ERROR:print("Database does not exist")else:print(err)self.cursor = Noneself.connection = Nonedef create_table(self):if self.cursor:create_table_query = """CREATE TABLE IF NOT EXISTS stocks (id INT AUTO_INCREMENT PRIMARY KEY,bStockNo VARCHAR(255),stockName VARCHAR(255),latestPrice VARCHAR(255),changePercent VARCHAR(255),changeAmount VARCHAR(255),volume VARCHAR(255),turnover VARCHAR(255),amplitude VARCHAR(255),highest VARCHAR(255),lowest VARCHAR(255),openPrice VARCHAR(255),closePrice VARCHAR(255))"""self.cursor.execute(create_table_query)self.connection.commit()def process_item(self, item, spider):if not self.cursor:return item # 如果 cursor 为 None,直接返回 iteminsert_query = """INSERT INTO stocks (bStockNo, stockName, latestPrice, changePercent, changeAmount, volume, turnover, amplitude, highest, lowest, openPrice, closePrice)VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""values = (item.get('bStockNo', ''),item.get('stockName', ''),item.get('latestPrice', ''),item.get('changePercent', ''),item.get('changeAmount', ''),item.get('volume', ''),item.get('turnover', ''),item.get('amplitude', ''),item.get('highest', ''),item.get('lowest', ''),item.get('openPrice', ''),item.get('closePrice', ''))try:self.cursor.execute(insert_query, values)self.connection.commit()except mysql.connector.Error as err:print(f"Error inserting data: {err}")return itemdef close_spider(self, spider):if self.cursor:self.cursor.close()if self.connection:self.connection.close()
(5)编辑 items.py 文件,代码如下
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/stock_spider/stock_spider/items.py
点击查看代码
import scrapy
class StockItem(scrapy.Item):id = scrapy.Field()bStockNo = scrapy.Field() # 股票代码stockName = scrapy.Field() # 股票名称latestPrice = scrapy.Field() # 最新报价changePercent = scrapy.Field() # 涨跌幅changeAmount = scrapy.Field() # 涨跌额volume = scrapy.Field() # 成交量turnover = scrapy.Field() # 成交额amplitude = scrapy.Field() # 振幅highest = scrapy.Field() # 最高lowest = scrapy.Field() # 最低openPrice = scrapy.Field() # 今开closePrice = scrapy.Field() # 昨收
3.运行爬虫
(1)在命令行或终端中,导航到项目根目录:scrapy crawl stock

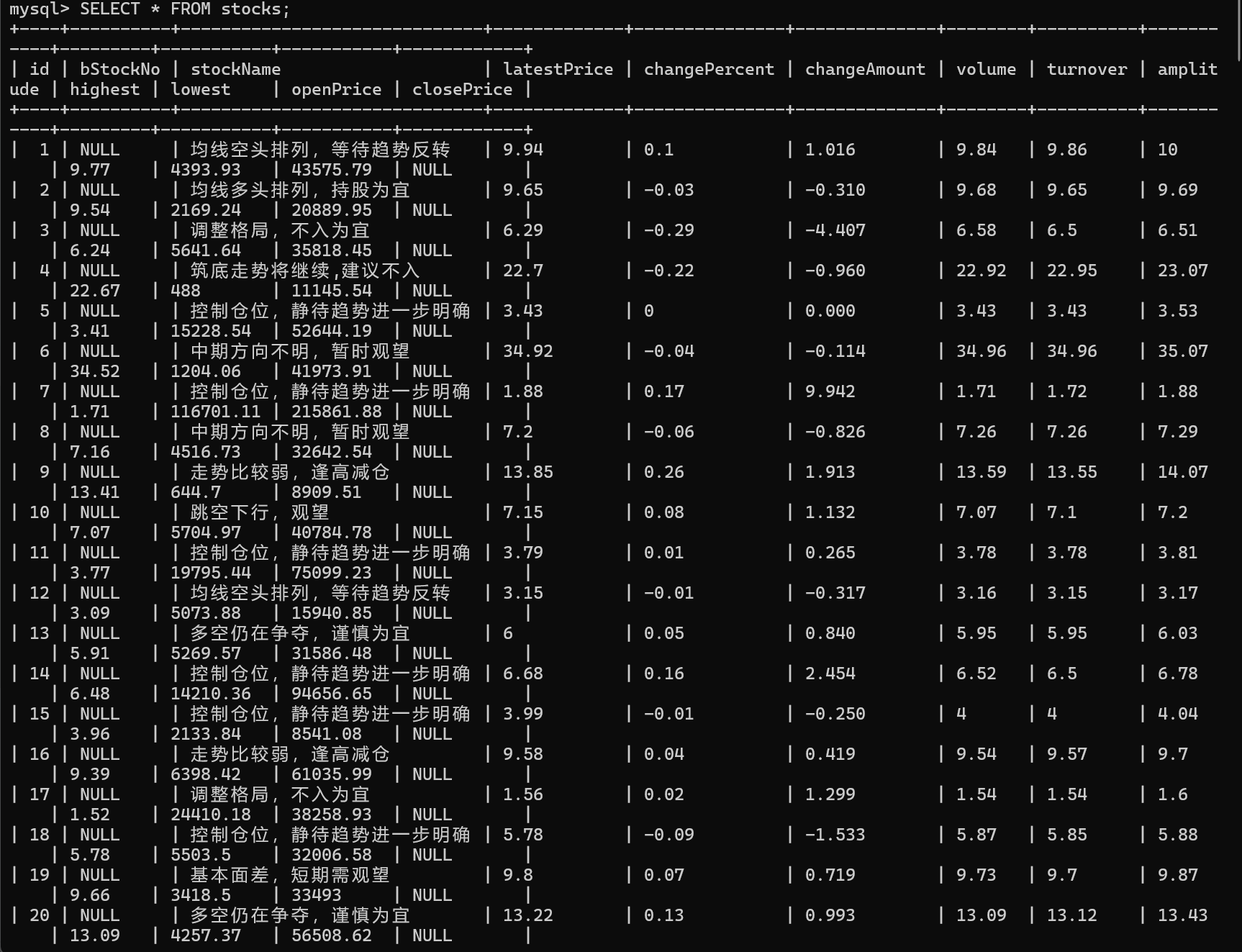
(2)显示结果截图
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践3/stock_spider/data
- 心得体会
在作业2中系统的学习了基本的使用scrapy框架爬取数据方法以及xpath爬取信息的方法,我在这一实验中一一体会,受益颇多。
作业3
- 数据采集实验
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践3/currency_project
要求: 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法; 使用 scrapy 框架 + Xpath + MySQL 数据库存储技术路线爬取外汇网站数据。使用 scrapy 框架 + MySQL 数据库存储技术爬取外汇网站数据。
候选网站: 招商银行网: https://www.boc.cn/sourcedb/whpj
输出信息: (MySQL 数据库存储和输出格式)
1.创建 Scrapy 项目
(1)进入作业文件夹、创建新的 Scrapy 项目

(2)查看目录
(3)进入项目目录

2.编写爬虫
(1)创建爬虫文件
在 currency_project/spiders 目录下创建一个爬虫文件:CurrencySpider.py
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/currency_project/currency_project/spiders/CurrencySpider.py
(2)编辑爬虫文件,代码如下
点击查看代码
import scrapy
from scrapy import signals
from scrapy.utils.log import configure_logging
from ..items import CurrencyItem
class CurrencySpider(scrapy.Spider):name = "currency"allowed_domains = ["boc.cn"]start_urls = ["https://www.boc.cn/sourcedb/whpj/"]def __init__(self, *args, **kwargs):# 配置日志输出configure_logging({'LOG_FORMAT': '%(levelname)s: %(message)s'})super().__init__(*args, **kwargs)def start_requests(self):for url in self.start_urls:yield scrapy.Request(url, callback=self.parse, errback=self.errback)def parse(self, response):# 使用XPath选择所有<tr>元素rows = response.xpath("//tr[position()>1]") # 忽略第一个<tr>元素# 遍历每个<tr>元素for row in rows:# 使用XPath选择当前<tr>下的所有<td>元素,并提取文本值currencyname = row.xpath("./td[1]//text()").get()hui_in = row.xpath("./td[2]//text()").get()chao_in = row.xpath("./td[3]//text()").get()hui_out = row.xpath("./td[4]//text()").get()chao_out = row.xpath("./td[5]//text()").get()zhonghang = row.xpath("./td[6]//text()").get()date = row.xpath("./td[7]//text()").get()time = row.xpath("./td[8]//text()").get()currency = CurrencyItem()currency['currencyname'] = str(currencyname)currency['hui_in'] = str(hui_in)currency['chao_in'] = str(chao_in)currency['hui_out'] = str(hui_out)currency['chao_out'] = str(chao_out)currency['zhonghang'] = str(zhonghang)currency['date'] = str(date)currency['time'] = str(time)yield currencydef errback(self, failure):self.logger.error(repr(failure))(3)编辑 settings.py 文件,代码如下
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/currency_project/currency_project/settings.py
点击查看代码
BOT_NAME = "currency_project"
SPIDER_MODULES = ["currency_project.spiders"]
NEWSPIDER_MODULE = "currency_project.spiders"
ITEM_PIPELINES = {'currency_project.pipelines.CurrencyPipeline': 300,
}
LOG_LEVEL = 'INFO'
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3307
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
MYSQL_DB = 'data acquisition'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'waihui (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = False(4)编辑 pipelines.py 文件,代码如下
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/currency_project/currency_project/pipelines.py
点击查看代码
import pymysql
class CurrencyPipeline:def __init__(self):# 初始化数据库连接参数self.host = "localhost"self.port = 3306self.user = "root"self.password = "123456"self.db = "data acquisition"self.charset = "utf8"self.table_name = "currency"def open_spider(self, spider):# 在爬虫启动时建立数据库连接self.client = pymysql.connect(host=self.host,port=self.port,user=self.user,password=self.password,db=self.db,charset=self.charset)self.cursor = self.client.cursor()# 创建表(如果不存在)create_table_query = """CREATE TABLE IF NOT EXISTS {} (id INT AUTO_INCREMENT PRIMARY KEY,currencyname VARCHAR(255),hui_in FLOAT,chao_in FLOAT,hui_out FLOAT,chao_out FLOAT,zhonghang FLOAT,date VARCHAR(255),time VARCHAR(255))""".format(self.table_name)self.cursor.execute(create_table_query)def process_item(self, item, spider):# 处理每个抓取的item,将其插入数据库# 转换hui_in字段,处理None值hui_in_value = item.get("hui_in")if hui_in_value == 'None':hui_in_value = Noneelse:try:hui_in_value = float(hui_in_value)except ValueError:hui_in_value = None# 转换hui_out字段,处理None值hui_out_value = item.get("hui_out")if hui_out_value == 'None':hui_out_value = Noneelse:try:hui_out_value = float(hui_out_value)except ValueError:hui_out_value = None# 转换chao_in字段,处理None值chao_in_value = item.get("chao_in")if chao_in_value == 'None':chao_in_value = Noneelse:try:chao_in_value = float(chao_in_value)except ValueError:chao_in_value = None# 转换chao_out字段,处理None值chao_out_value = item.get("chao_out")if chao_out_value == 'None':chao_out_value = Noneelse:try:chao_out_value = float(chao_out_value)except ValueError:chao_out_value = None# 转换zhonghang字段,处理None值zhonghang_value = item.get("zhonghang")if zhonghang_value == 'None':zhonghang_value = Noneelse:try:zhonghang_value = float(zhonghang_value)except ValueError:zhonghang_value = None# 准备要插入的数据args = [item.get("currencyname"),hui_in_value,chao_in_value,hui_out_value,chao_out_value,zhonghang_value,item.get("date"),item.get("time"),]print("Inserting data:", args)# 插入数据到数据库sql = "INSERT INTO {} (currencyname, hui_in, chao_in, hui_out, chao_out, zhonghang, date, time) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)".format(self.table_name)self.cursor.execute(sql, args)self.client.commit()# 返回处理后的itemreturn itemdef close_spider(self, spider):# 在爬虫关闭时关闭数据库连接self.cursor.close()self.client.close()
(5)编辑 items.py 文件,代码如下
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践3/currency_project/currency_project/items.py
点击查看代码
import scrapy
class CurrencyItem(scrapy.Item):currencyname = scrapy.Field()hui_in = scrapy.Field()chao_in = scrapy.Field()hui_out = scrapy.Field()chao_out = scrapy.Field()zhonghang = scrapy.Field()date = scrapy.Field()time = scrapy.Field()3.运行爬虫
(1)在命令行或终端中,导航到项目根目录:scrapy crawl currency

(2)显示结果截图
Gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践3/currency_project/data@0020acquisition
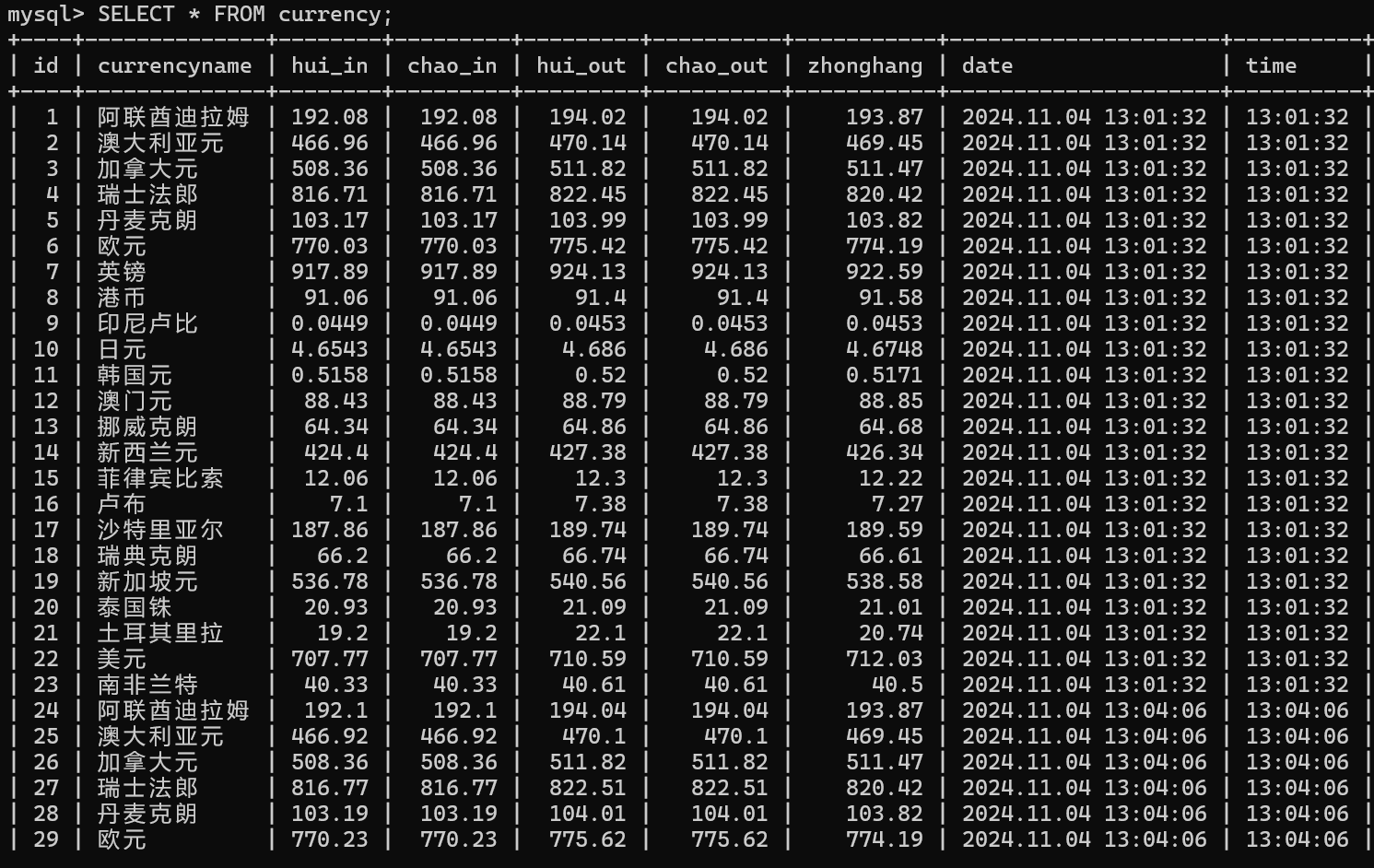
- 心得体会
通过本次实验,我熟练掌握了使用 Scrapy 框架结合 Xpath 技术爬取外汇网站数据,并将其存储到 MySQL 数据库的完整流程。定义了 CurrencyItem 类来存储数据,编写了 Spider 类提取外汇牌价信息,并通过 Pipeline 将数据序列化存储到 MySQL 中。实验过程加深了我对 Scrapy 框架的理解,提升了数据爬取和处理的能力。