01 引言

为了应对低、中、高阶智驾场景,以及当前 AI 模型在工业界的应用趋势,地平线推出了征程 6 系列芯片。
在软硬件架构方面,征程 6 不仅保持了对传统 CNN 网络的高效支持能力,还强化了对 Transformer 类型网络的支持,主要表现为大幅强化了对逐点计算、数据搬运的能力。基于征程 6 硬件平台的增强和算法移植的痛点,同时坚持 ‘软硬协同’ 的设计理念,征程 6 工具链衍生了诸多新特性。
在 征程 6 工具链性能分析与优化 1|编译器预估 perf 解读与性能分析 这篇文章中,我们解释了编译器预估 perf 中各个参数的含义以及对性能的初步分析。
本篇文章,我们将基于征程 6 软硬件特性,整理出征程 6 工具链算法优化常用策略。
02 模型性能优化建议
本节将结合笔者在征程 6 工具链参考算法的学习经验,整理常用的性能优化策略。
2.1 高效 backbone
HENet 是针对征程 6 平台专门设计的高效 backbone,其采用了纯 CNN 架构,总体可分为四个 stage,每个 stage 会进行 2 倍下采样。以下为总体的结构配置:
depth = [4, 3, 8, 6]
block_cls = ["GroupDWCB", "GroupDWCB", "AltDWCB", "DWCB"]
width = [64, 128, 192, 384]
attention_block_num = [0,0,0,0]
mlp_ratios, mlp_ratio_attn = [2, 2, 2, 3], 2
act_layer = ["nn.GELU", "nn.GELU", "nn.GELU", "nn.GELU""]
use_layer_scale = [True,True,True,True]
final_expand_channel, feature_mix_channel = 0,1024
down_cls = ["S2DDown", "S2DDown", "S2DDown", "None"71
模型相关细节可以参考 HENet 高效模型相关介绍。
2.2 算子优化建议
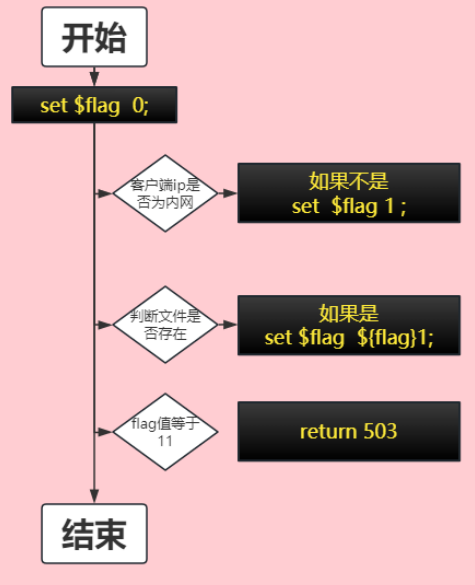
2.2.1 遵循硬件对齐原则
一般的 tensor shape 对齐到 2 的幂次,conv-like 的算子 H 维度对齐到 8、W 维度对齐到 16、C 维度对齐到 32,若设计尺寸不满足对齐规则时会对 tensor 自动进行 padding,造成无效的算力浪费。
2.2.2 尽量使用 BPU 算子搭建模型
BPU 算子本身性能远高于 CPU 算子,且 CPU 和 BPU 之间的异构调度还会引入量化、反量化节点,其计算因为需要遍历数据,所以耗时也与 shape 大小成正比。
所以建议结合用户手册中的算子支持列表,选择合适的 BPU 算子来搭建模型。
2.2.3 减少数据搬运操作
虽然征程 6 中大幅度强化了对数据搬运(transpose、reshape)操作的效率,但是建议在模型中还是避免频繁的数据搬运操作,同时注意 reshape 操作时,改动的维度越多,计算效率越低。
2.2.4 将 attention 层的 add、sum、mean 替换为 conv 计算
self.sum_ref_offset = nn.Linear(self.num_levels * self.num_heads * self.num_points * 2 * 2,self.num_levels * self.num_heads * self.num_points * 2,bias=False,
)
self.sum_ref_offset = nn.Linear(self.num_levels * self.num_heads * self.num_points * 2 * 2,self.num_levels * self.num_heads * self.num_points * 2,bias=False,
)self.add_pos = nn.Linear(self.embed_dims * 2,self.embed_dims,bias=False,
)
self.queries_mean_pad = nn.Conv2d(self.num_bev_queue * self.view_num,self.view_num,1,bias=False,
)
另外,笔者还建议将 Linear 替换为 Conv1x1 ,从而获得性能的进一步提升。
详情见:地平线 3D 目标检测 Bevformer 参考算法 V1.0
2.2.5 GridSample 性能优化
GridSample 是 BEV 坐标变换和 deformable conv 高频使用的算子,若 grid 的 size 过大或 H,W 分布的不均匀则可能会有带宽问题(该问题在征程 5 上常有发生,随着征程 6 的带宽增加,对 gridsample 的约束限制降低)或运行到 CPU 上,可以采用以下方式提供此算子的运行效率:
-
对 gridsample 计算做拆分,比如 Nx22223x4x2 的 gird,数据集中在 H 维度,导致硬件对齐后计算量相较于之前增加不少,所以在算法设计的时候可以将 22223 维度进行拆分,比如 Nx22223x4x2-->Nx313x284x2;
-
合理选择 BEV Grid 尺寸,征程 6 平台的带宽得到增强,但仍需考虑 BEV Grid 尺寸对模型性能的影响,并且综合衡量模型精度预期,选择合适的 BEV Grid 尺寸以获得模型性能和精度的平衡;
2.2.6 cumsum 算子替换
公版模型的 QCNetDecoder 中使用了征程 6 暂不支持的 torch.cumsum 算子,参考算法中将其替换为了 Conv1x1,相关代码如下:
self.loc_cumsum_conv = nn.Conv2d(self.num_future_steps,self.num_future_steps,kernel_size=1,bias=False,)self.scale_cumsum_conv = nn.Conv2d(self.num_future_steps,self.num_future_steps,kernel_size=1,bias=False,)
详情见:地平线轨迹预测 QCNet 参考算法-V1.0
2.2.7 Gather/GatherND 算子高效支持
在地平线以往的版本(OE3.0.17)中,Gather/GatherND 算子底层均为 CPU 实现,效率较低,在地平线征程 6 工具链即将发布的正式版本中,Gather/GatherND 算子将支持 BPU 加速,可以极大地提升计算效率。