真不会了,GDB把我榨干了,会了会回来填坑的
真不会了,GDB把我榨干了,会了会回来填坑的【入门笔记】CSE 365 - Fall 2024之Computing 101(pwn.college)
Your First Program 你的第一个程序
Your First Register 你的第一个寄存器
CPU的思维方式非常简单。 它移动数据,更改数据,基于数据做出决策,并基于数据采取行动。 大多数情况下,这些数据存储在寄存器中。
简而言之,寄存器是数据的容器。 CPU可以将数据放入寄存器,在寄存器之间移动数据,等等。 在硬件层面上,这些寄存器是使用非常昂贵的芯片实现的,它们被塞在令人震惊的微观空间中,以甚至连光速这样的物理概念都影响它们性能的频率访问。 因此,CPU可以拥有的寄存器数量是非常有限的。 不同的CPU体系结构有不同数量的寄存器,这些寄存器的名称也不同,等等。通常,程序代码可以出于任何原因使用10 ~ 20个“通用”寄存器,以及多达几十个用于特殊目的的寄存器。
在x86的现代版本x86_64中,程序可以访问16个通用寄存器。 在这个挑战中,我们将学习我们的第一个: rax 。 你好啊,rax!(扩展累加器寄存器)
rax ,一个单独的x86寄存器,只是x86 CPU庞大复杂设计中的一小部分,但这是我们将要开始的地方。 与其他寄存器类似, rax 是一个存储少量数据的容器。 使用 mov 指令将数据移动到。 指令被指定为操作符(在这个例子中是 mov )和操作数,它们表示额外的数据(在这个例子中,它将是指定的 rax 作为目标,以及我们要存储在那里的值)。
例如,如果你想将值 1337 存储到 rax 中,x86程序集看起来是这样的:
mov rax, 1337
你可以看到以下几点:
- 目的节点(
rax)在源节点(值1337)的前面 - 两个操作数之间用逗号分隔
- 这真是太简单辣!
在这个挑战中,您将编写您的第一个汇编程序。 必须将 60 的值移动到 rax 。 将你的程序写在一个具有 .s 扩展名的文件中,例如 rax-challenge.s (虽然不是强制的, .s 是汇编程序文件的典型扩展名),并将它作为参数传递给 /challenge/check 文件(例如 /challenge/check rax-challenge.s )。 你可以使用你最喜欢的文本编辑器,也可以使用pwn.college中的文本编辑器——VSCode工作空间来实现你的 .s 文件!
勘误: 如果你以前见过x86汇编,那么你可能见过它的一种稍微不同的方言。 pwn的方言。学院是“英特尔语法”,这是编写x86汇编的正确方式(提醒一下,x86是英特尔创造的)。 一些课程错误地教授“AT&T语法”的使用,造成了大量的困惑。 我们将在下一模块中稍微涉及到这个,然后,希望再也不用考虑AT&T语法了。
查看解析
mov rax, 60Your First Syscall 你的第一次系统调用
你的第一个程序崩溃了…… 别担心,它总会发生的! 在这个挑战中,你将学习如何让程序干净地退出,而不是崩溃。
启动程序和干净利落地停止程序是计算机操作系统处理的操作。 操作系统管理程序的存在、程序之间的交互、硬件、网络环境,等等。
你的程序使用汇编指令与CPU“交互”,例如你之前编写的 mov 指令。 类似地,你的程序使用 syscall (系统调用)指令与操作系统交互(当然是通过CPU)。
就像你可能使用电话与当地的餐馆进行交互来点餐一样,程序使用系统调用来请求操作系统代表程序执行操作。 稍微泛化一下,程序所做的任何不涉及数据计算的工作都是通过系统调用完成的。
程序可以调用很多不同的系统调用。 例如,Linux大约有330个不同的系统调用,但这个数字会随着时间的推移而变化,因为系统调用的增加和废弃。 每个系统调用都由一个系统调用编号表示,从0开始计数,程序通过将其系统调用编号移动到 rax 寄存器并调用 syscall 指令来调用特定的系统调用。 例如,如果我们想调用syscall 42(你稍后会了解的一个系统调用!),可以编写两条指令:
mov rax, 42
syscall
非常酷,而且超级简单!
在这个挑战中,我们将学习我们的第一个系统调用: exit 。
exit 系统调用导致程序退出。 通过显式退出,我们可以避免前一个程序遇到的崩溃!
现在, exit 的系统调用编号是 60 。 现在开始编写你的第一个程序:它应该将60移动到 rax ,然后调用 syscall 以干净利落地退出!
查看解析
mov rax, 60
syscallExit Codes 退出代码
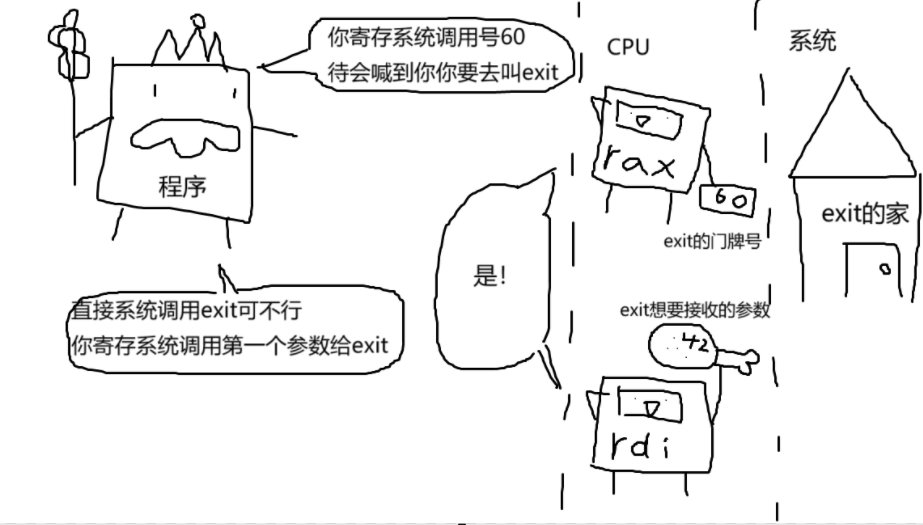
现在你可能知道了,每个程序在结束时都有一个退出代码。 这是通过向 exit 系统调用传递一个参数来完成的。
类似于在 rax 变量中指定系统调用编号(例如,60表示 exit ),参数也通过寄存器传递到系统调用。 系统调用可以接受多个参数,但 exit 只接受一个参数:退出代码。 系统调用的第一个参数是通过另一个寄存器传递的: rdi 。 rdi 是本次挑战的重点。
在这个挑战中,你必须让你的程序以 42 的退出代码退出。 因此,你的程序需要3条指令:
- 设置程序的退出代码(将其移动到
rdi)。 - 设置
exit系统调用(mov rax, 60)的系统调用号码。 syscall!
查看解析
mov rdi, 42
mov rax, 60
syscallBuilding Executables 构建可执行文件
你写了第一个程序? 但到目前为止,我们已经处理了将其构建为CPU可以实际运行的可执行文件的实际工作。 在这个挑战中,你将构建它!
要构建可执行二进制文件,你需要:
- 将程序集写入文件(通常使用
.S或.s语法)。在这个例子中,我们使用asm.s)。 - 将二进制文件汇编成可执行的目标文件(使用
as命令)。 - 链接一个或多个可执行目标文件到最终的可执行二进制文件(使用
ld命令)!
让我们一步一步来:
汇编文件包含您的汇编代码。 对于上一关,这可能是:
hacker@dojo:~$ cat asm.s
mov rdi, 42
mov rax, 60
syscall
hacker@dojo:~$
但是它需要包含更多的信息。 我们提到在本课程中使用英特尔汇编语法,我们需要让汇编程序知道这一点。 你可以通过在汇编代码的开头添加一个指令来实现这一点,例如:
hacker@dojo:~$ cat asm.s
.intel_syntax noprefix
mov rdi, 42
mov rax, 60
syscall
hacker@dojo:~$
.intel_syntax noprefix 告诉汇编器你将使用英特尔汇编语法,特别是它的变体,你不必为每条指令添加额外的前缀。 稍后我们将讨论这些,但现在,我们让汇编程序来解决这个问题!
接下来,我们将汇编代码。 这是使用汇编器 as 完成的,如下所示:
hacker@dojo:~$ ls
asm.s
hacker@dojo:~$ cat asm.s
.intel_syntax noprefix
mov rdi, 42
mov rax, 60
syscall
hacker@dojo:~$ as -o asm.o asm.s
hacker@dojo:~$ ls
asm.o asm.s
hacker@dojo:~$
这里, as 工具读取 asm.s ,将其汇编成二进制代码,并输出一个名为 asm.o 的目标文件。 这个目标文件实际上已经汇编了二进制代码,但还没有准备好运行。 首先,我们需要链接它。
在典型的开发工作流程中,源代码被编译,然后汇编成目标文件,通常有很多这样的文件(通常,程序中的每个源代码文件都会编译成自己的目标文件)。 然后将它们链接在一起,形成一个单独的可执行文件。 即使只有一个文件,我们仍然需要链接它,以准备最终的可执行文件。 这是通过 ld (源于术语“link editor链接编辑器”)命令完成的,如下所示:
hacker@dojo:~$ ls
asm.o asm.s
hacker@dojo:~$ ld -o exe asm.o
ld: warning: cannot find entry symbol _start; defaulting to 0000000000401000
hacker@dojo:~$ ls
asm.o asm.s exe
hacker@dojo:~$
这将创建一个 exe 文件,然后我们可以运行它! 如下所示:
hacker@dojo:~$ ./exe
hacker@dojo:~$ echo $?
42
hacker@dojo:~$
针不戳! 现在可以构建程序了。 在这个挑战中,继续并自己完成这些步骤。 构建你的可执行文件,并将其传递给 /challenge/check 作为flag!
_star
细心的学习者可能已经注意到 ld 打印出关于 entry symbol _start 的警告。 _start 符号本质上是 ld 的注释,说明ELF(可执行文件)执行时程序执行应该从哪里开始。 警告指出,如果没有指定的 _start ,执行将从代码的开头开始。 这对我们来说并没有关系!
如果想消除错误,可以在代码中指定 _start 符号,如下所示:
hacker@dojo:~$ cat asm.s
.intel_syntax noprefix
.global _start
_start:
mov rdi, 42
mov rax, 60
syscall
hacker@dojo:~$ as -o asm.o asm.s
hacker@dojo:~$ ld -o exe asm.o
hacker@dojo:~$ ./exe
hacker@dojo:~$ echo $?
42
hacker@dojo:~$
这里还有两行。 第二个参数 _start: 添加了一个名为start的标签,指向代码的起始位置。 第一个是 .global _start ,它指示 as 使 _start 标签在链接器级别全局可见,而不仅仅是在目标文件级别局部可见。 由于 ld 是链接器,因此该指令对于 _start 标签是必要的。
对于这个dojo中的所有挑战,从文件的开头开始执行是很好的,但是如果您不想看到弹出这些警告,现在您知道如何防止它们了!
查看解析
.intel_syntax noprefix
mov rdi, 42
mov rax, 60
syscall
as -o
ld -oTracing Syscalls 系统调用追踪
当你编写越来越大的程序时,你(是的,你也可以!)可能会在实现某些功能时犯错误,从而在程序中引入bug。 在这个模块中,我们将介绍一些用于调试程序的工具和技术。 第一个非常简单:系统调用跟踪程序 strace 。
给定一个要运行的程序, strace 将使用Linux操作系统的功能来自检并记录程序调用的每个系统调用及其结果。 例如,来看一下上一个挑战中的程序:
hacker@dojo:~$ strace /tmp/your-program
execve("/tmp/your-program", ["/tmp/your-program"], 0x7ffd48ae28b0 /* 53 vars */) = 0
exit(42) = ?
+++ exited with 42 +++
hacker@dojo:~$
如你所见, strace 报告了哪些系统调用被触发了,传递了哪些参数,以及返回了哪些数据。 这里用于输出的语法是 system_call(parameter, parameter, parameter, ...) 。 这种语法借用了一种名为C语言的编程语言,但我们现在不用担心。 只要记住如何阅读这个特定的语法即可。
在这个例子中, strace 报告了两个系统调用:第二个是程序用来请求终止的 exit 系统调用,你可以看到传递给它的参数(42)。 第一个是 execve 系统调用。 我们稍后将了解这个系统调用,但它有点像 exit 的反面:它用于启动一个新程序(在情景中,启动的程序是 your-program )。 在这种情况下,它实际上并不是由 your-program 调用的:它被strace检测到是strace工作方式的一个奇怪特征,我们稍后会研究。
在最后一行中,你可以看到 exit(42) 的结果,即程序退出时的退出代码为 42 !
现在, exit 系统调用很容易进行内部审查,而无需使用 strace ——毕竟, exit 的部分意义是为您提供一个可以访问的退出代码。 但其他系统调用就不那么明显了。 例如, alarm 系统调用(系统调用编号37)将在操作系统中设置一个定时器,当许多秒过去时,Linux将终止该程序。 alarm 的作用例如:在程序冻结时终止程序,但在本例中,我们将使用 alarm 来练习我们的 strace 窥探!
在这个挑战中,你必须 strace /challenge/trace-me 程序找出它传递给 alarm 系统调用的参数是什么值,然后调用 /challenge/submit-number 以获取到的参数值。 好运!
查看解析
strace /challenge/trace-meMoving Between Registers 寄存器之间的移动
好的,让我们再学习一个寄存器: rsi ! 就像 rdi , rsi 是一个可以存放一些数据的地方。 例如:
mov rsi, 42
当然,您也可以在寄存器之间移动数据! 看:
mov rsi, 42
mov rdi, rsi
就像第一行将 42 移动到 rsi ,第二行将 rsi 的值移动到 rdi 。 在这里,我们必须提及一个复杂的问题:这里的移动实际上指的是集合。 在上述片段之后, rsi 和 rdi 将会是 42 。 为什么选择 mov ,而不是像 set 这样合理的东西,这是一个谜(即使非常博学的人在被问到时也会诉诸各种各样的猜测),但它确实是,而我们就是这样约定俗成了。
不管怎样,迎接挑战吧! 在这个挑战中,我们将在 rsi 寄存器中存储一个秘密值,程序必须以该值作为返回码退出。 因为 exit 使用存储在 rdi 中的值作为返回码,所以你需要将 rsi 中的秘密值移动到 rdi 中。 好运!
查看解析
.intel_syntax noprefix
mov rdi, rsi
mov rax, 60
syscall
as -o
ld -oLoading From Memory 从内存中加载数据
正如你的程序所看到的,计算机内存是一个巨大的存储数据的地方。 就像街上的房子一样,内存的每个部分都有一个数字地址,就像街上的房子一样,这些数字(大部分)是连续的。 现代计算机有大量的内存,而典型的现代程序的内存视图实际上有很大的差距(想象一下:街道的一部分没有建房子,所以这些地址被跳过了)。 但这些都是细节:关键是,计算机在内存中存储数据,主要是按顺序存储。
在这一关卡,我们将练习访问存储在内存中的数据。 我们该怎么做呢? 回想一下,为了将一个值移动到寄存器中,我们这样做:
mov rdi, 31337
之后, rdi 的值为 31337 。 酷。 好吧,我们可以使用相同的指令来访问内存! 该命令还有另一种格式,它使用第二个参数作为访问内存的地址!思考一下我们的内存看起来像这样:
地址 │ 内容
+────────────────────+
│ 31337 │ 42 │
+────────────────────+
要访问内存地址31337处的内存内容,可以这样做:
mov rdi, [31337]
当CPU执行这条指令时,它当然知道 31337 是一个地址,而不是一个原始值。 如果你把指令想象成一个人告诉CPU该做什么,我们坚持我们的“街上的房子”类比,那么指令/人不是仅仅向CPU传递数据,而是指向街上的房子。 然后CPU会去那个地址,按门铃,打开前门,把里面的数据拖出来,放入 rdi 。 因此,这里的 31337 是一个内存地址,指向存储在该内存地址中的数据。 这条指令执行后,存储在 rdi 中的值将是 42 !
让我们把它付诸实践! 我在内存地址 133700 中存储了一个秘密数字,如下所示:
地址 │ 内容
+────────────────────+
│ 133700 │ ??? │
+────────────────────+
您必须取得这个秘密数字,并将其用作程序的退出代码。 要做到这一点,你必须将它读入 rdi ,如果你还记得的话,它的值是 exit 的第一个参数,并用作退出代码。 好运!
查看解析
.intel_syntax noprefix
mov rdi, [133700]
mov rax, 60
syscall
as -o
ld -oMore Loading Practice 更多的加载练习
你看起来还需要再多练习一下。 在这一关卡中,我们将secret值放在 123400 ,而不是 133700 ,如下所示:
Address │ Contents
+────────────────────+
│ 123400 │ ??? │
+────────────────────+
去把它载入 rdi 和 exit ,以此作为退出代码!
查看解析
.intel_syntax noprefix
mov rdi, [123400]
mov rax, 60
syscall
as -o
ld -o你更喜欢访问 133700 还是 123400 ? 你的回答可能会涉及到你的性格,但从技术角度来看,这并不是非常相关。 事实上,在大多数情况下,编写程序时根本不需要处理实际的内存地址!
这怎么可能呢? 通常,内存地址存储在寄存器中,我们使用寄存器中的值来指向内存中的数据! 让我们从这个内存配置开始:
Address │ Contents
+────────────────────+
│ 133700 │ 42 │
+────────────────────+
思考下面的汇编代码片段:
mov rdi, 133700
现在,你有以下情况:
Address │ Contents
+────────────────────+
│ 133700 │ 42 │◂┐
+────────────────────+ ││Register │ Contents │
+────────────────────+ │
│ rdi │ 133700 │─┘
+────────────────────+
rdi 现在保存了一个值,对应于要加载的数据的地址! 让我们加载它:
mov rdi, [rax]
这里,我们正在访问内存,但不是为内存读取指定固定地址(如133700),而是使用存储在rax中的值作为内存地址。通过包含内存地址,rax是一个指向我们想要访问的数据的指针!当我们使用rax代替直接指定它所存储的地址来访问它所引用的内存地址时,我们称之为指针解引用。在上面的示例中,我们解引用rax以将它指向的数据(地址为133700的值42)加载到rdi中。针不戳!
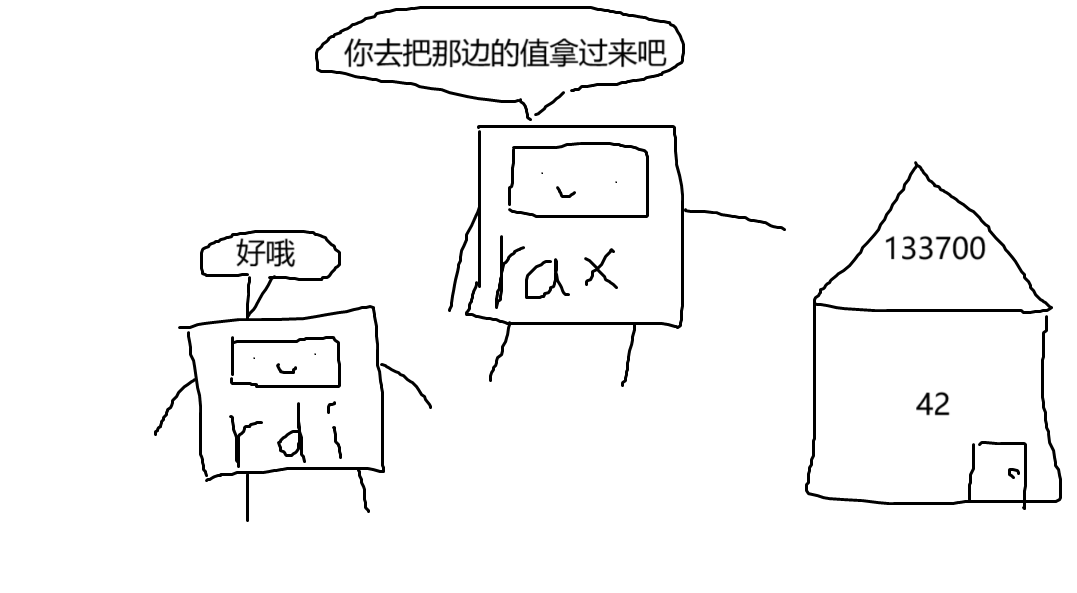
这也说明了另一点:这些寄存器是通用的! 到目前为止,我们一直使用 rax 作为系统调用索引,这并不意味着它不能有其他用途。 在这里,它被用作指向内存中秘密数据的指针。
类似地,寄存器中的数据也没有隐含的用途。 如果 rax 包含 133700 的值,我们写 mov rdi, [rax] , CPU将该值作为内存地址进行解引用。 但是如果我们在同样的条件下写 mov rdi, rax , CPU就会很高兴地把 133700 变成 rdi 。 对CPU来说,数据就是数据;只有以不同的方式使用时,它才会变得不同。
在这个挑战中,我们初始化 rax ,以包含存储在内存中的秘密数据的地址。 解引 rax ,将秘密数据转换为 rdi ,并使用它作为程序的退出代码来获取flag!
查看解析
.intel_syntax noprefix
mov rdi, [rax]
mov rax, 60
syscall
as -o
ld -oDereferencing Yourself 自我解引用
在上一关卡中,我们解除了 rax 的引用,将数据读入 rdi 。 有趣的是我们对 rax 的选择是任意的。 我们可以使用任何其他指针,甚至 rdi 本身! 没有什么能阻止你解除寄存器的引用,用解除引用的值重写它自己的内容!
例如,我们用 rax 。 我给每一行都加了注释:
mov [133700], 42
mov rax, 133700 # after this, rax will be 133700
mov rax, [rax] # after this, rax will be 42
在这段代码中, rax 从用作指针变成用于保存从内存中读取的数据。 CPU使这一切工作!
在这个挑战中,你将探索这个概念。 我们没有像之前那样初始化 rax ,而是将 rdi 作为指向秘密值的指针! 你需要解除它的引用,将该值加载到 rdi 中,然后将该值作为退出代码加载到 exit 中。 好运!
查看解析
.intel_syntax noprefix
mov rdi, [rid]
mov rax, 60
syscall
as -o
ld -oDereferencing with Offsets
所以现在你可以像专业人士一样在内存中解引用指针了! 但是指针并不总是直接指向你需要的数据。 例如,有时一个指针可能指向一个数据集合(比如一整本书),你需要在这个集合中引用其中所需的特定数据。
例如,如果指针(例如 rdi )指向内存中的一个数字序列,如下所示:
Address │ Contents
+────────────────────+
│ 133700 │ 50 │◂┐
│ 133701 │ 42 │ │
│ 133702 │ 99 │ │
│ 133703 │ 14 │ │
+────────────────────+ ││Register │ Contents │
+────────────────────+ │
│ rdi │ 133700 │─┘
+────────────────────+
如果想得到该序列的第二个数字,可以这样做:
mov rax, [rdi+1]
哇,超级简单! 在内存术语中,我们称这些数字为插槽字节:每个内存地址代表内存的一个特定字节。 上面的例子访问的是 rax 指向的内存地址后1字节的内存。 在内存中,我们称这1字节的差值为偏移量,因此在这个例子中,与 rdi 所指向的地址之间有一个偏移量为1。
让我们来实践这个概念。 和之前一样,我们将初始化 rdi 指向秘密值,但不是直接指向它。 这一次,secret值与 rdi 点的偏移量是8字节,类似于下面这样:
Address │ Contents
+────────────────────+
│ 31337 │ 0 │◂┐
│ 31337+1 │ 0 │ │
│ 31337+2 │ 0 │ │
│ 31337+3 │ 0 │ │
│ 31337+4 │ 0 │ │
│ 31337+5 │ 0 │ │
│ 31337+6 │ 0 │ │
│ 31337+7 │ 0 │ │
│ 31337+8 │ ??? │ │
+────────────────────+ ││Register │ Contents │
+────────────────────+ │
│ rdi │ 31337 │─┘
+────────────────────+
当然,实际的内存地址不是 31337 。 我们随机选择它,并将其存储在 rdi 。 用偏移量8去解引用rdi并获得flag!
查看解析
.intel_syntax noprefix
mov rdi, [rdi+8]
mov rax, 60
syscall
as -o
ld -oStored Addresses 存储地址
指针可以变得更有趣! 想象一下,你的朋友住在同一条街上的另一所房子里。 与其记住他们的地址,你可以把它写下来,然后把这张纸记录着他们的房子地址一起放在你的房子里。 然后,为了从朋友那里获取数据,需要将CPU指向你家,让它进入你家并找到朋友的地址,并将该地址用作指向他家的指针。
类似地,由于内存地址实际上只是值,它们可以存储在内存中,稍后再检索! 让我们探索一个场景,我们将值 133700 存储在地址 123400 ,将值 42 存储在地址 133700 。 请看下面的指令:
mov rdi, 123400 # after this, rdi becomes 123400
mov rdi, [rdi] # after this, rdi becomes the value stored at 123400 (which is 133700)
mov rax, [rdi] # 这里我们解引用rdi,将42读入rax!
哇! 这种地址存储在程序中非常常见。 地址和数据会被存储、加载、移动,有时甚至会相互混淆! 当这种情况发生时,可能会出现安全问题,并且您将在pwn.college的旅程期间轻松处理许多此类问题。
现在,让我们练习解除内存中地址的引用。 我将一个秘密值存储在一个秘密地址,然后将这个秘密地址存储在地址 567800 。 你必须读取地址,解引用它,获取秘密值,然后用它作为退出代码 exit 。 你能行的!
查看解析
.intel_syntax noprefix
mov rdi, [567800]
mov rdi, [rdi]
mov rax, 60
syscall
as -o
ld -oDouble Dereference 双重解引用
在最后的几个关卡中,你将:
- 使用我们告诉你的地址(在一个关卡中,
133700,在另一个关卡中,123400)从内存中加载一个秘密值。 - 使用我们放入
rax中的地址,以便您从内存中加载秘密值。 - 使用我们告诉你的地址(在最后一关卡中,
567800)将秘密值的地址从内存加载到寄存器中,然后使用该寄存器作为指针从内存中检索秘密值!
让我们把最后两个放在一起。 在这个挑战中,我们将 SECRET_VALUE 存储在内存中的地址 SECRET_LOCATION_1 ,然后将 SECRET_LOCATION_1 存储在内存中的地址 SECRET_LOCATION_2 。 然后,我们将 SECRET_ADDRESS_2 转化为 rax ! 使用 133700 表示 SECRET_LOCATION_1 ,使用123400表示 SECRET_LOCATION_2 ,得到的结果看起来像这样(在真正的挑战中,这些值是不一样的,而且是不可见的!)
Address │ Contents+────────────────────+┌─│ 133700 │ 123400 │◂┐│ +────────────────────+ │└▸│ 123400 │ 42 │ │+────────────────────+ ││││Register │ Contents │+────────────────────+ ││ rdi │ 133700 │─┘+────────────────────+
这里,你需要执行两次内存读取:一次解引用 rax ,从 rax 所指向的位置读取 SECRET_LOCATION_1 (也就是 SECRET_LOCATION_2 ),另一次解引用现在保存 SECRET_LOCATION_1 的寄存器,将 SECRET_VALUE 读取 rdi ,这样你就可以将它用作退出代码了!
听起来很多,但基本上你已经完成了所有这些。 去把它汇编起来!
查看解析
.intel_syntax noprefix
mov rdi, [rax]
mov rdi, [rdi]
mov rax, 60
syscall
as -o
ld -oTriple Dereference 三重解引用
好的,让我们把它扩展到一个更深的深度! 在这个挑战中,我们增加了一个额外的间接关卡,所以现在需要三次解引用才能找到秘密值。 像这样:
Address │ Contents+────────────────────+┌─│ 133700 │ 123400 │◂──┐│ +────────────────────+ │└▸│ 123400 │ 100000 │─┐ │+────────────────────+ │ ││ 100000 │ 42 │◂┘ │+────────────────────+ │││Register │ Contents │+────────────────────+ ││ rdi │ 133700 │───┘+────────────────────+
如您所见,我们将放置您必须解引用到rdi的第一个地址。 去获取值吧!
查看解析
.intel_syntax noprefix
mov rdi, [rdi]
mov rdi, [rdi]
mov rdi, [rdi]
mov rax, 60
syscall
as -o
ld -oHello Hackers
Writing Outpt 写出输出
让我们一起学习写文本吧!
不出所料,你的程序通过调用系统调用向屏幕写入文本。 具体来说,这是 write 系统调用,它的系统调用编号为 1 。 但write系统调用还需要通过其参数指定要写入的数据以及写入的位置。
您可能还记得,在Linux Luminarium 学习的管道模块实践中,文件描述符(FDs)的概念。 提醒一下,每个进程从3个FD开始。
- FD 0:标准输入是进程接收输入的通道。例如,shell使用标准输入来读取您输入的命令。
- FD 1:标准输出是处理输出正常数据的通道,例如在前面的挑战中打印给你的flag或实用程序的输出,如
ls - FD 2:标准错误是处理输出错误细节的通道。例如,如果你键入了错误的命令,shell会以标准错误的形式输出该命令不存在。
事实证明,在 write 系统调用中,这就是指定数据写入位置的方式! exit 系统调用的第一个(也是唯一的)参数是退出代码( mov rdi, 42 ),而 write 的第一个(但在这个例子中,不仅如此!)参数是文件描述符。 如果想写入标准输出,需要将 rdi 设置为1。 如果想写入标准错误,需要将 rdi 设置为2。 超级简单!
这就剩下我们要写什么了。 现在,你可以想象一个场景,我们通过另一个寄存器参数指定要写入的内容到 write 系统调用。 但是这些寄存器并不能容纳大量的数据,并且要写出像这个挑战描述这样长的内容,您需要多次调用 write 系统调用。 相对而言,这有很大的性能成本——CPU需要从执行程序的指令切换到执行Linux本身的指令,进行大量的日常计算,与硬件交互以获得在屏幕上显示的实际像素,然后再切换回来。 这是很慢的,所以我们尽量减少调用系统调用的次数。
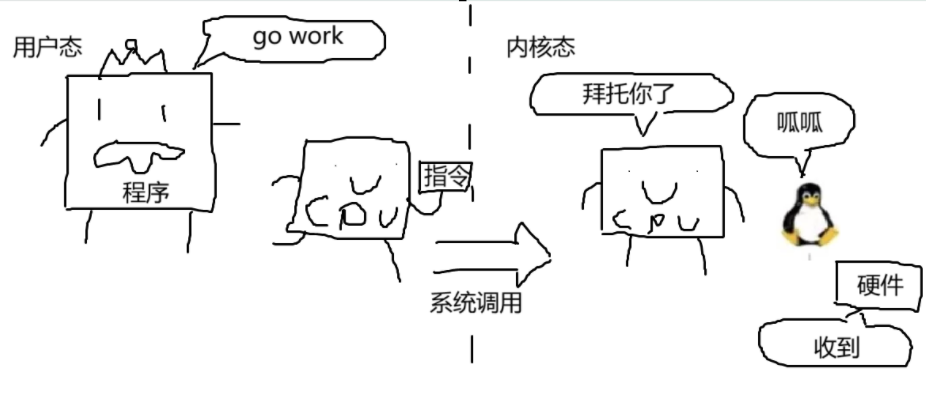
当然,解决这个问题的方法是同时编写多个字符。 write 系统调用通过两个参数来表示这些:a从(内存中的)哪里开始写,以及要写多少个字符。 这些参数作为第二个和第三个参数传递给 write 。 在我们从 strace 中学到的类C语法中,这将是:
write(file_descriptor, memory_address, number_of_characters_to_write)
举一个更具体的例子,如果你想从内存地址1337000写入10个字符到标准输出(文件描述符1),可以这样做:
write(1, 1337000, 10);
哇,很简单! 现在,我们实际上如何指定这些参数?
- 如上所述,我们将在
rdi寄存器中传递系统调用的第一个参数。 - 我们将通过
rsi寄存器传递第二个参数。 Linux中公认的惯例是,rsi用作系统调用的第二个参数。 - 我们将通过
rdx寄存器传递第三个参数。 这是整个模块中最令人困惑的部分:rdi(保存第一个参数的寄存器)与rdx非常相似,很容易混淆,不幸的是,由于历史原因,这种命名方式一直存在。 哦…… 只是我们得小心点。 也许像这样的助记法“rdi是初始参数,rdx是第三参数”? 或者只是把它想成是要追踪不同的名字相似的朋友,没什么大不了的。
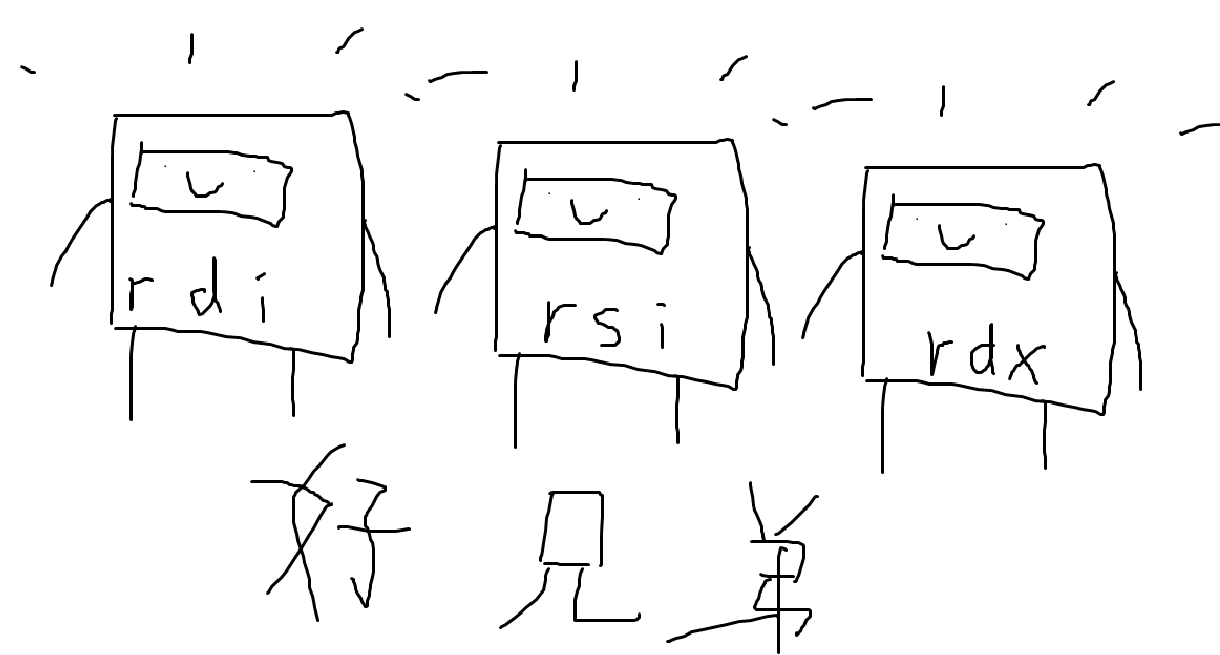
当然, write 系统调用指数变为 rax 本身: 1 。 除了 rdi 和 rdx 的混淆之外,这真的很简单!
现在,您知道如何将寄存器指向内存地址(从内存模块!),您知道如何设置系统调用编号,以及如何设置其余的寄存器。 所以,这应该是非常简单的!
与之前类似,我们将一个秘密字符值写入内存,地址为 1337000 。 对单个字符调用 write (就现在而言!我们稍后会做多字符写入)值到标准输出,然后我们会给你一个flag!
查看解析
.intel_syntax noprefix
mov rdi, 1
mov rsi, 1337000
mov rdx, 1
mov rax, 1
syscall
#上面的汇编代码进行伪c语言编码后得到`write(1, 1337000, 1)`
as -o
ld -oChaining Syscalls 链式系统调用
好吧,我们之前的解决方案写了输出,但后来崩溃了。 在这个关卡,您将写入输出,然后不会崩溃!
我们将通过调用 write 系统调用来做到这一点,然后调用 exit 系统调用来干净地退出程序。 我们如何调用两个系统调用? 就像你调用两个指令一样! 首先,你设置必要的寄存器并调用 write ,然后你设置必要的寄存器并调用exit!
你之前的解决方案有5个指令(设置 rdi ,设置 rsi ,设置 rdx ,设置 rax ,和 syscall )。 这个应该有这5个,再加上3个用于退出的 exit (将 rdi 设置为退出代码,将 rax 设置为系统调用索引60,以及 syscall )。 对于这个关卡,让我们以退出代码 42 退出!
查看解析
.intel_syntax noprefix
mov rdi, 1
mov rsi, 1337000
mov rdx, 1
mov rax, 1
syscall
mov rdi, 42
mov rax, 60
syscall
#上面的汇编代码进行伪c语言编码后得到`write(1, 1337000, 1);exit`
as -o
ld -oWriting Strings 写入字符串
好了,我们还有一件事要做。 你已经写出了一个字节,现在我们来练习写出多个字节。 我在内存位置 1337000 中存储了一个14字符的秘密字符串。 你能把它写出来吗?
提示: 与之前的解决方案相比,唯一需要修改的是 rdx 中的值!
查看解析
.intel_syntax noprefix
mov rdi, 1
mov rsi, 1337000
mov rdx, 14
mov rax, 1
syscall
mov rdi, 42
mov rax, 60
syscall
#上面的汇编代码进行伪c语言编码后得到`write(1, 1337000, 14);exit`
as -o
ld -oAssembly Crash Course 汇编语言速成课程
set-register 设置寄存器
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
在这一关卡,你将使用寄存器!请设置如下:
rdi = 0x1337
查看解析
.intel_syntax noprefix
mov rdi, 0x1337
as -o
ld -oset-multiple-register 设置多个寄存器
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
在这一关卡,您将使用多个寄存器。请设置如下:
rax = 0x1337r12 = 0xCAFED00D1337BEEFrsp = 0x31337
查看解析
.intel_syntax noprefix
mov rax, 0x1337
mov r12, 0xCAFED00D1337BEEF
mov rsp, 0x31337
as -o
ld -oadd-to-register 寄存器执行加法操作
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行一些公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
x86中有许多指令可以让你在寄存器和内存上执行所有普通的数学操作。
作为简写,当我们说 A += B 时,实际上是指 A = A + B 。
下面是一些有用的指令。
add reg1, reg2<=>reg1 += reg2sub reg1, reg2<=>reg1 -= reg2imul reg1, reg2<=>reg1 *= reg2
div 更复杂,我们稍后讨论。注意:所有 regX (正则表达式)都可以用常量或内存位置替换。
执行如下操作:
- 将
0x331337加进rdi
查看解析
.intel_syntax noprefix
add rdi, 0x331337
as -o
ld -olinear-equation-registers 线性方程寄存器
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
用你学到的知识,计算如下:
f(x) = mx + b ,其中:
m = rdix = rsib = rdx
将结果放入 rax 。
注意:在使用哪些寄存器方面, mul (无符号乘法)和 imul (有符号乘法)之间有重要的区别。
在这种情况下,你需要使用 imul 。
查看解析
.intel_syntax noprefix
imul rsi, rdi
add rsi, rdx
mov rax, rsi
as -o
ld -ointeger-division 整数的除法
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里,通常是 rax 。
x86中的除法比普通数学中的除法更特殊。这里称为整数数学(integer Math),意思是每个值都是整数。
例如: 10 / 3 = 3 。
为什么?
因为 3.33 向下取整为整数。
此关卡的相关指令如下:
mov rax, reg1div reg2
笔记:div是一个特殊的指令,它可以将128位的被除数除以64位的除数,同时存储商和余数,只使用一个寄存器作为操作数。
这个复杂的div指令是如何在128位的被除数(是寄存器的两倍大)上工作和操作的?
对于 div reg 指令,将执行以下操作:
rax = rdx:rax / regrdx = remainder
rdx:rax 表示 rdx 为128位被除数的上64位, rax 为128位被除数的下64位。
在调用 div 之前,你必须仔细看看 rdx 和 rax 中的内容。
请计算以下内容:
speed = distance / time ,其中:
distance = rditime = rsispeed = rax
注意,distance值最多为64位,因此 rdx 应该为0。
查看解析
.intel_syntax noprefix
mov rax, rdi
div rsi
#将被除数放入rax,除法计算完成后将结果放入rax中
as -o
ld -omodulo-operation 模运算
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
汇编中的模运算是另一个有趣的概念!
X86允许你得到 div 操作后的余数。
例如: 10 / 3 导致余数 1 。
余数与求模相同,也称为“取模”运算符。
在大多数编程语言中,我们使用符号 % 来表示mod。
请计算如下: rdi % rsi
将值置于 rax 。
查看解析
.intel_syntax noprefix
mov rax, rdi
div rsi
mov rax, rdx
#将被除数放入rax,除法计算完成后余数放在了rdx寄存器中
as -o
ld -oset-upper-byte 设置高字节
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里,通常是 rax 。
x86中另一个很酷的概念是能够独立访问较低的寄存器字节。
x86_64中的每个寄存器大小为64位(bits),在前面的关卡中,我们使用 rax 、 rdi 或 rsi 来访问完整的寄存器。
我们还可以使用不同的寄存器名称访问每个寄存器的较低字节。
例如 rax 的下32位可通过 eax 访问,下16位可通过 ax 访问,下8位可通过 al 访问。
MSB LSB
+----------------------------------------+
| rax |
+--------------------+-------------------+| eax |+---------+---------+| ax |+----+----+| ah | al |+----+----+
低寄存器字节访问适用于几乎所有寄存器。
仅使用一条移动指令,请将 ax 寄存器的高8位设置为 0x42 。
查看解析
.intel_syntax noprefix
mov ah, 0x42
#注意审题,ax寄存器的高8位是ah
as -o
ld -oefficient-modulo 高效模运算
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
事实证明,使用 div 运算符来计算求模运算是很慢的!
我们可以使用一个数学技巧来优化求模运算符( % )。编译器经常使用这个技巧。
如果我们有 x % y ,而 y 是2的幂,如 2^n ,则结果将是 x 中较低的 n 位。
因此,我们可以使用较低的寄存器字节访问来高效地实现模运算!
只使用以下指令:
mov
请计算以下内容:
rax = rdi % 256rbx = rsi % 65536
查看解析
.intel_syntax noprefix
mov al, dil ; rdi 的低 8 位移动到 rax 的低 8 位 (rax = rdi % 256)
mov bx, si ; rsi 的低 16 位移动到 rbx (rbx = rsi % 65536)
as -o
ld -oMSB LSB
+----------------------------------------+
| rax |
+--------------------+-------------------+| eax |+---------+---------+| ax |+----+----+| ah | al |+----+----+
MSB LSB
+----------------------------------------+
| rdi |
+--------------------+-------------------+| edi |+---------+---------+| di |+----+----+| dih| dil|+----+----+
byte-extraction 字节提取
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这一关卡,你将处理位逻辑和操作。这将涉及大量直接与存储在寄存器或内存位置中的位进行交互。你可能还需要使用x86中的逻辑指令: and , or , not , xor 。
在汇编中移动位是另一个有趣的概念!
X86允许你在寄存器中“移动”位。
例如, al ,即 rax 的最低8位。
al (以比特为单位)的值为:
rax = 10001010
如果我们使用 shl 指令向左移动一次:
shl al, 1
新值为:
al = 00010100
所有元素都向左移动,最高的比特位脱落,而右边增加了一个新的0。
你可以用它对你关心的部分做一些特殊的事情。
移位运算有一个很好的副作用,可以快速完成乘法(乘以2)或除法(除以2)运算,它也可以用于求模。
以下是重要的使用指令:
shl reg1, reg2<=> 将reg1向左移动reg2中的位数shr reg1, reg2<=> 将reg1向右移动reg2中的位数
注意:reg2可以被一个常量或内存位置替换。
只使用以下指令:
mov,shr,shl
请执行以下操作: 设置 rax 为 rdi 的第5位最低有效字节。
例如:
rdi = | B7 | B6 | B5 | B4 | B3 | B2 | B1 | B0 |
Set rax to the value of B4
查看解析
.intel_syntax noprefix
shr rdi, 32 ; 右移 32 位,保留 B4 及其以下位
mov al, dil ; 只保留最低有效字节8bit
as -o
ld -obitwise-and 按位与运算
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这一关卡,你将处理位逻辑和操作。这将涉及大量直接与存储在寄存器或内存位置中的位进行交互。你可能还需要使用x86中的逻辑指令: and , or , not , xor 。
汇编中的位逻辑是另一个有趣的概念!X86允许你对寄存器逐位执行逻辑操作。
在这个例子中,假设寄存器只存储8位。
rax 和 rbx 中的值为:
rax = 10101010rbx = 00110011
如果我们使用 and rax, rbx 指令对 rax 和 rbx 执行按位和,结果将通过逐个和每个比特对来计算,这就是为什么它被称为按位逻辑。
从左到右:
- 1 AND 0 = 0
- 0 AND 0 = 0
- 1 AND 1 = 1
- 0 AND 1 = 0
- ... …
最后,我们将结果组合在一起得到:
rax = 00100010
下面是一些真值表供参考:
-
AND 与
A | B | X ---+---+--- 0 | 0 | 0 0 | 1 | 0 1 | 0 | 0 1 | 1 | 1 -
OR 或
A | B | X ---+---+--- 0 | 0 | 0 0 | 1 | 1 1 | 0 | 1 1 | 1 | 1 -
XOR 异或
A | B | X ---+---+--- 0 | 0 | 0 0 | 1 | 1 1 | 0 | 1 1 | 1 | 0
如果不使用以下指令: mov , xchg ,(xchg 是一种汇编指令,用于交换两个操作数的值)请执行以下操作:
设置 rax 为 (rdi AND rsi)的值
查看解析
.intel_syntax noprefix
and rdi, rsi ; 将 rdi 和 rsi 进行 AND 运算,结果保存在 rdi 中
xor rax, rax ; 清除 rax,确保初始值为 0
or rax, rsi ; 将 rdi OR rax(此时 rax 为 0,rdi 不变)
as -o
ld -ocheck-even 检查是否为偶数
在这一关卡,您将使用寄存器。您将被要求修改或读取寄存器。
我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下是 rax 。
在这一关卡,你将处理位逻辑和操作。这将涉及大量直接与存储在寄存器或内存位置中的位进行交互。你可能还需要使用x86中的逻辑指令: and , or , not , xor 。
只使用以下指令:
andorxor
实现以下逻辑:
if x is even theny = 1
elsey = 0
其中:
x = rdiy = rax
查看解析
要实现这个逻辑,判断一个数 x 是否为偶数,可以检查其最低位(LSB)。如果最低位为 0,则 x 为偶数;如果最低位为 1,则 x 为奇数。
.intel_syntax noprefix
and rdi, 1 ; 检查 rdi 的最低位(rdi & 1,只检测最低位,若rdi为偶数则rdi为0)
xor rax, rax ; 清除 rax,初始化为 0
or rax, rdi ; 如果最低位为 1,则 rax 变为 1(rdi 是奇数),否则 rax 仍为 0
xor rax, 1 ; 将结果反转:如果是偶数,rax = 1;如果是奇数,rax = 0
as -o
ld -omemory-read 读取内存
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡中,你将使用内存。这需要你对内存中线性存储的数据进行读写。你可能还会被要求多次解除对我们动态放入内存供你使用的东西的引用。
到目前为止,你已经使用寄存器作为存储东西的唯一方式,本质上是像数学中的x这样的变量。
然而,我们也可以将字节存储到内存中!
回想一下,内存是可以寻址的,每个地址在该位置都包含一些内容。请注意,这类似于现实生活中的地址!
例如:真实地址“699 S Mill Ave, Tempe, AZ 85281”对应于“ASU Brickyard”。我们也会说它指向“ASU Brickyard”。我们可以这样表示:
['699 S Mill Ave, Tempe, AZ 85281'] = 'ASU Brickyard'
这个地址是特殊的,因为它是唯一的。但这也并不意味着其他地址不能指向同一个东西(因为一个人可以拥有多套房子)。
内存是完全一样的!
例如,你的代码存储在内存中的地址(当我们从你那里获取它时)是 0x400000 。
在x86中,我们可以访问内存位置中的东西,称为解引用,如下所示:
mov rax, [some_address] <=> Moves the thing at 'some_address' into rax
这也适用于寄存器中的内容:
mov rax, [rdi] <=> Moves the thing stored at the address of what rdi holds to rax
这和写入内存是一样的:
mov [rax], rdi <=> Moves rdi to the address of what rax holds.
因此,如果 rax 地址为 0xdeadbeef ,那么 rdi 将存储在地址 0xdeadbeef :
[0xdeadbeef] = rdi
注意:内存是线性的,在x86_64中,它从 0 到 0xffffffffffffffff (是的,非常巨大)。
请执行如下操作:将保存在 0x404000 的值放入 rax 。确保 rax 中的值是存储在 0x404000 中的原始值。
查看解析
.intel_syntax noprefix
mov rax, [0x404000]
as -o
ld -omemory-write 写入记忆
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡中,你将使用记忆。这需要你对内存中线性存储的数据进行读写。如果你感到困惑你可能还会被要求多次解除对我们动态放入内存供你使用的东西的引用。
请执行以下操作: 将保存在 rax 中的值放置到 0x404000 中。
查看解析
.intel_syntax noprefix
mov [0x404000], rax
as -o
ld -omemory-increment 内存增量
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡中,你将使用记忆。这需要你对内存中线性存储的数据进行读写。你可能还会被要求多次解除对我们动态放入内存供你使用的东西的引用。
请执行以下操作:
- 将保存在
0x404000中的值放入rax中。 - 将存储在地址
0x404000中的值增加0x1337。
确保 rax 中的值是存储在 0x404000 中的原始值,并确保 [0x404000] 现在是增加后的值。
查看解析
.intel_syntax noprefix
mov rax, [0x404000]
add qword ptr [0x404000], 0x1337
#`qword` 是 "quad word" 的缩写,表示 64 位(8 字节)数据。使用 ptr 关键字是为了告诉汇编器接下来的操作数是一个指针,指向内存地址中的数据。`qword ptr`明确指示操作数的大小,确保在执行加法时不会产生歧义。
as -o
ld -obyte-access 字节访问
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡中,你将使用记忆。这需要你对内存中线性存储的数据进行读写。如果你感到困惑你可能还会被要求多次解除对我们动态放入内存供你使用的东西的引用。
回想一下,x86_64中的寄存器是64位宽的,这意味着它们可以存储64位。类似地,每个内存位置都可以视为64位值。我们将64位(8字节)的东西称为四字词。
下面是内存大小名称的分类:
- Quad Word = 8 Bytes = 64 bits
- Double Word = 4 bytes = 32 bits
- Word = 2 bytes = 16 bits
- Byte = 1 byte = 8 bits
Bit——位
Byte——字节
Word——字
Double Word——双字
Quad Word——四字
在x86_64中,你可以在解引用地址时访问这些长度中的每一个,就像使用更大或更小的寄存器访问一样:
mov al, [address]<=>将最低有效字节从地址移到raxmov ax, [address]<=>将最低有效字从地址移到raxmov eax, [address]<=>将最低有效的双字从地址移到raxmov rax, [address]<=>将完整的四字内容从地址移动到rax
请记住,迁移到 al 并不完全清除上层字节。
请执行以下操作: 设置 rax 为 0x404000 的最低有效字节。
查看解析
.intel_syntax noprefix
mov al, [0x404000]
as -o
ld -omemory-size-access 内存大小访问
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡中,你将使用记忆。这需要你对内存中线性存储的数据进行读写。如果你感到困惑你可能还会被要求多次解除对我们动态放入内存供你使用的东西的引用。
回想一下:
- 内存大小名称的分解:
- Quad Word = 8 Bytes = 64 bits
- Double Word = 4 bytes = 32 bits
- Word = 2 bytes = 16 bits
- Byte = 1 byte = 8 bits
在x86_64中,你可以在解引用地址时访问这些长度中的每一个,就像使用更大或更小的寄存器访问一样:
mov al, [address]<=>将最低有效字节从地址移到raxmov ax, [address]<=>将最低有效字从地址移到raxmov eax, [address]<=>将最低有效的双字从地址移到raxmov rax, [address]<=>将完整的四字从地址移动到rax
请执行以下操作:
- 设置
rax为0x404000的最低有效字节。 - 设置
rbx为0x404000的最低有效字。 - 设置
rcx为0x404000的最低有效双字。 - 设置
rdx为0x404000的完整四字。
查看解析
.intel_syntax noprefix
mov al, [0x404000]
mov bx, [0x404000]
mov ecx, [0x404000]
mov rdx, [0x404000]
as -o
ld -olittle-endian-write 小端写入
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡中,你将使用记忆。这需要你对内存中线性存储的数据进行读写。你可能还会被要求多次解除对我们动态放入内存供你使用的东西的引用。
值得注意的是,你可能已经注意到,值的存储顺序与我们表示它们的顺序相反。
举个例子:
[0x1330] = 0x00000000deadc0de
如果你检查它在内存中的实际样子,你会看到:
[0x1330] = 0xde
[0x1331] = 0xc0
[0x1332] = 0xad
[0x1333] = 0xde
[0x1334] = 0x00
[0x1335] = 0x00
[0x1336] = 0x00
[0x1337] = 0x00
这种“反向”存储格式在x86中是有意为之的,它被称为“小端序”。
对于这个挑战,我们将为您提供每次运行时动态创建的两个地址。
第一个地址将放置在 rdi 。 第二个被放在 rsi 。
利用前面提到的信息,执行如下操作:
- Set
[rdi] = 0xdeadbeef00001337 - Set
[rsi] = 0xc0ffee0000
提示:将一个大常量赋值给一个未引用的寄存器可能需要一些技巧。尝试将一个寄存器设置为该常量的值,然后将该寄存器赋值给解除引用的寄存器。
查看解析
为了将一个常量写入内存地址,你通常需要先将常量加载到一个寄存器中,然后使用这个寄存器的值去写入内存。
.intel_syntax noprefix
mov rax, 0xdeadbeef00001337
mov [rdi], rax
mov rax, 0xc0ffee0000
mov [rsi], rax
#将两个 64 位的常量分别写入由 rdi 和 rsi 指向的内存地址,使用小端序存储数据。
as -o
ld -omemory-sum 内存求和
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡中,你将使用记忆。这需要你对内存中线性存储的数据进行读写。你可能还会被要求多次解除对我们动态放入内存供你使用的东西的引用。
回想一下,内存是线性存储的。
这是什么意思?
假设我们访问 0x1337 处的完整四字内容:
[0x1337] = 0x00000000deadbeef
内存的实际布局方式是逐字节排列,小端序:
[0x1337] = 0xef
[0x1337 + 1] = 0xbe
[0x1337 + 2] = 0xad
...
[0x1337 + 7] = 0x00
这对我们有什么用?
好吧,这意味着我们可以使用偏移量来访问相邻的元素,就像上面显示的那样。
假设你想要一个地址的第5个字节,你可以这样访问它:
mov al, [address+4]
记住,偏移量从0开始。
执行如下操作:
- 从
rdi中存储的地址中加载两个连续的四字。 - 计算前面步骤中的四词之和。
- 将和存储在
rsi的地址。
查看解析
.intel_syntax noprefix
mov rax, [rdi] ; 加载第一个四字到 rax
mov rbx, [rdi + 8] ; 加载第二个四字到 rbx
add rax, rbx ; 将两个值相加
mov [rsi], rax ; 将结果存储到 rsi 指向的地址
as -o
ld -ostack-subtraction 栈减法
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这一关卡,您将使用栈,动态扩展和收缩的内存区域。你需要对栈进行读写,这可能需要使用 pop 和 push 指令。你可能还需要使用栈指针寄存器( rsp )来知道栈指向哪里。
在这些关卡次中,我们将介绍栈。
栈是内存中的一个区域,可以存储稍后使用的值。
要在栈中存储一个值,我们使用 push 指令,而要取得一个值,我们使用 pop 指令。
栈是一种后进先出(LIFO)的内存结构,这意味着最后推入的值就是第一个弹出的值。
想象一下把盘子从洗碗机里拿出来。假设有1个红,1个绿,1个蓝。首先,我们把红色的放在柜子里,然后把绿色的放在红色的上面,然后是蓝色的。
我们的盘子堆看起来像这样:
Top ----> BlueGreen
Bottom -> Red
现在,如果我们想要一个盘子来做三明治,我们会从一堆盘子中取出最上面的那个,也就是最后一个进入橱柜的蓝色盘子,也就是第一个出来的盘子。
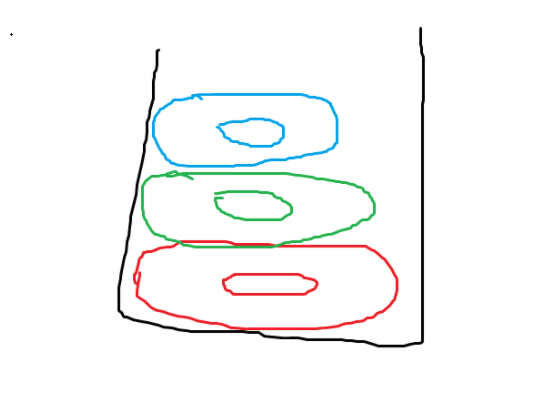
在x86上, pop 指令将从栈顶取出值并将其放入寄存器。
类似地, push 指令会将寄存器中的值压入栈顶。
使用这些指令,取栈顶的值,减去 rdi ,然后放回去。
查看解析
.intel_syntax noprefix
pop rax
sub rax, rdi
push rax
as -o
ld -oswap-stack-values 交换栈值
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这一关卡,您将使用栈,动态扩展和收缩的内存区域。你需要对栈进行读写,这可能需要使用 pop 和 push 指令。你可能还需要使用栈指针寄存器( rsp )来知道栈指向哪里。
在这一关卡,我们将探索栈的后进先出(LIFO)属性。
只使用以下说明:
pushpop
交换 rdi 和 rsi 中的值。
例子:
- 开始时
rdi = 2和rsi = 5 - 请在结束时满足
rdi = 5和rsi = 2
查看解析
.intel_syntax noprefix
push rdi
push rsi
pop rdi
pop rsi
as -o
ld -oaverage-stack-values 栈值平均
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这一关卡,您将使用栈,动态扩展和收缩的内存区域。你需要对栈进行读写,这可能需要使用 pop 和 push 指令。你可能还需要使用栈指针寄存器( rsp )来知道栈指向哪里。
在前面的关卡中,你使用 push 和 pop 来从栈中存储和加载数据。但是,你也可以直接使用栈指针访问栈。
在x86上,堆栈指针存储在特殊寄存器 rsp 中。 rsp 总是存储堆栈顶部的内存地址,即最后一个压入值的内存地址。
与内存关卡类似,我们可以使用 [rsp] 来访问 rsp 中的内存地址的值。
在不使用 pop 的情况下,计算栈上连续存储的4个四字的平均值。将平均值压入栈。
提示:
RSP+0x??Quad Word ARSP+0x??Quad Word BRSP+0x??Quad Word CRSPQuad Word D
查看解析
.intel_syntax noprefix
mov rax, [rsp]
mov rbx, [rsp+8]
mov rcx, [rsp+16]
mov rdx, [rsp+24]
add rax, rbx
add rax, rcx
add rax, rdx
shr rax, 2 ; 右移 2 位,即除以 4
push rax
as -o
ld -oabsolute-jump 绝对跳转
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡,您将处理控制流操作。这涉及到使用指令来间接和直接控制特殊寄存器 rip (指令指针)。你将使用诸如 jmp 、 call 、 cmp 以及它们的替代指令来实现所请求的行为。
前面,我们学习了如何以伪控制的方式操作数据,但是x86提供了直接操作控制流的实际指令。
操纵控制流有两种主要方法。
- Through a jump 通过跳转
- Through a call 通过调用
在这个关卡中,你将使用跳转。
有两种类型的跳转:
- Unconditional jumps 无条件的跳转
- Conditional jumps 条件跳转
无条件跳转总是会触发,并且不基于前面指令的结果。
如你所知,内存位置可以存储数据和指令。你的代码将存储在 0x400042 (每次运行都会改变)。
对于所有的跳转,有三种类型:
- 相对跳转:跳转到下一条指令的正或负偏移。
- 绝对跳转:跳转到特定地址。
- 间接跳转:跳转到寄存器中指定的内存地址。
在x86中,绝对跳转(跳转到特定地址)是通过首先将目标地址放入寄存器 reg ,然后执行 jmp reg 来完成的。
x86 指令集是变长指令集,这意味着每条指令的长度是变化的,取决于操作数的大小。绝对跳转通常涉及到 32 位或 64 位的目标地址,但指令长度有限,不能在一条指令中直接携带如此大的目标地址。
- 在 x86 32 位模式下,
jmp指令通常是 5 字节(包括操作码和 32 位的偏移量)。 - 在 x86-64 64 位模式下,
jmp指令则通常是 10 字节(包括操作码和 64 位的偏移量)。
虽然 jmp 可以直接处理较短的相对跳转(通过偏移量),但要处理一个 64 位的绝对跳转(在 x86-64 中),无法通过单个 jmp 指令直接指定一个完整的目标地址。于是就需要一种间接的方式:将目标地址加载到寄存器中,再通过 jmp reg 执行跳转。
在这个关卡中,我们会要求你做一个绝对的跳转。执行如下操作:跳转到绝对地址 0x403000 。
查看解析
.intel_syntax noprefix
mov rax, 0x403000
jmp rax
as -o
ld -orelative-jump 相对跳转
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡,您将处理控制流操作。这涉及到使用指令来间接和直接控制特殊寄存器 rip (指令指针)。你将使用诸如 jmp 、 call 、 cmp 以及它们的替代指令来实现所请求的行为。
回想一下,对于所有跳转,有三种类型:
- Relative jumps 相对跳转
- Absolute jumps 绝对的跳转
- Indirect jumps 间接的跳转
在这个关卡中,我们将要求你进行一个相对跳转。你需要在代码中填充一些空间,以便实现这个相对跳转。我们建议使用 nop 指令。它长度为 1 字节,并且非常可预测。
事实上,我们正在使用的汇编器有一个方便的 .rept 指令,您可以使用它来重复一些次汇编指令:GNU汇编器手册
这个关卡的有用说明:
jmp (reg1 | addr | offset)nop
提示:对于相对跳转,请思考如何在x86中使用 labels 。
利用上述知识,执行如下操作:
- 代码中的第一条指令是
jmp。 - 将
jmp跳转指令改为相对跳转,跳转到当前指令位置向后偏移 0x51 字节。 - 在相对跳转将重定向控制流的代码位置,将
rax设置为0x1。
查看解析
.intel_syntax noprefix
jmp skip ; 直接跳转到标签 skip,开始相对跳转
nop_padding:.rept 0x51 ; 重复 0x51 次nop ; 每次重复的指令.endr ; 结束重复指令
skip: ; 这里的代码将在 jmp 跳转后执行mov rax, 0x1 ; 将 rax 设置为 0x1
as -o
ld -o +------------------+| || Start || |+--------+---------+|v+------------------+| || jmp skip | <--- 相对跳转到 skip 标签| |+--------+---------+|v+------------------+| || nop_padding | <--- 这里的 nop 指令会被执行| |+--------+---------+|v+------------------+| || nop | <--- 多个 nop 指令(填充)| |+--------+---------+|v+------------------+| || skip | <--- 到达 skip 标签| |+--------+---------+|v+------------------+| || mov rax, 0x1 | <--- 设置 rax 为 0x1| |+------------------+|v+------------------+| || End || |+------------------+
在汇编中,jmp skip 是一种相对跳转,它的目标是 skip 标签,而不是直接跳过 nop_padding。在跳转指令中,目标地址是相对于当前指令的偏移量计算的。
编译器会根据 jmp 指令的位置和 skip 标签的位置计算出偏移量。即使 jmp 指令出现在 nop_padding 的前面,指令会根据偏移量跳转到 skip。
相对跳转:中间的指令会被执行,因为控制流是基于当前位置的偏移量进行计算的。
绝对跳转:中间的指令不会被执行,因为它直接跳转到指定地址,跳过了所有位于这个地址之前的指令。
jump-trampoline 跳转跳板
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器进行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡,您将处理控制流操作。这涉及到使用指令来间接和直接控制特殊寄存器 rip (指令指针)。你将使用诸如 jmp 、 call 、 cmp 以及它们的替代指令来实现所请求的行为。
现在,我们将前两个关卡结合起来执行以下操作:
- 创建一个两次跳转的跳板:
- 代码中的第一条指令是
jmp。 - 使
jmp从当前位置相对跳转到0x51字节。 - 在0x51处,编写如下代码:
- 将栈上的最高值放入寄存器
rdi。 jmp到绝对地址0x403000
- 将栈上的最高值放入寄存器
- 代码中的第一条指令是
查看解析
.intel_syntax noprefix
jmp skip ; 直接跳转到标签 skip,开始相对跳转
nop_padding:.rept 0x51 ; 重复 0x51 次nop ; 每次重复的指令.endr ; 结束重复指令
skip: ; 这里的代码将在 jmp 跳转后执行mov rdi, rsp ; 将栈上的最高值放入寄存器 rdimov rax, 0x403000jmp rax ; jmp 到绝对地址0x403000
as -o
ld -oconditional-jump 条件跳转
在这个关卡,您将处理控制流操作。这涉及到使用指令来间接和直接控制特殊寄存器 rip (指令指针)。你将使用诸如 jmp 、 call 、 cmp 以及它们的替代指令来实现所请求的行为。
我们将在这个关卡中使用动态值多次测试您的代码!这意味着我们将以各种随机的方式运行你的代码,以验证逻辑是否足够稳固,可以正常使用。
现在我们将介绍条件跳转——x86中最有价值的指令之一。在高级编程语言中,if-else结构的作用如下:
if x is even:is_even = 1
else:is_even = 0
这看起来应该很熟悉,因为它只能以位逻辑实现,你在之前的版本中已经实现过。在这些结构中,我们可以根据提供给程序的动态值来控制程序的控制流。
用jmp实现上述逻辑可以这样做:
; 假设 rdi = x, rax 为输出
; rdx = rdi 除以 2 的余数
mov rax, rdi
mov rsi, 2
div rsi
; 如果余数是 0,则为偶数
cmp rdx, 0 ; cmp指令执行的是减法操作,计算两个操作数的差值,但不会存储计算结果,只修改标志寄存器
; 如果余数不为 0,则跳转到 not_even 部分
jne not_even ; jne全称是 "Jump if Not Equal"(如果不相等则跳转)
; 如果是偶数,则继续执行下面的代码
mov rbx, 1
jmp done
; 只有在不是偶数时跳转到这里
not_even:
mov rbx, 0
done:
mov rax, rbx
; 后面还有更多指令
但通常情况下,你需要的不仅仅是一个if-else。有时你需要两个if检查,后面跟着一个else。要做到这一点,你需要确保你的控制流在失败后fall- through到下一个 if 。All语句在执行后必须跳转到相同的 done ,以避免else语句。
x86中有很多跳转类型,了解它们的使用方法将会很有帮助。它们几乎都依赖于一种叫做ZF的东西,即零标志。当a cmp 等于时,ZF设为1,否则设为0。
利用上面的知识,实现如下代码:
if [x] is 0x7f454c46:y = [x+4] + [x+8] + [x+12]
else if [x] is 0x00005A4D:y = [x+4] - [x+8] - [x+12]
else:y = [x+4] * [x+8] * [x+12]
其中:
x = rdi、y = rax。
假设每个解引用的值都是有符号dword。这意味着在每个内存位置上,这些值都可以从负值开始。
一个有效的解决方案将至少使用以下一次:
jmp(任意变体),cmp
查看解析
.intel_syntax noprefix
cmp dword ptr [rdi], 0x7f454c46
je yes
cmp dword ptr [rdi], 0x00005A4D
je yesyes
mov eax, [rdi+4]
imul eax, [rdi+8]
imul eax, [rdi+12]
jmp done
yes:mov eax, [rdi+4]add eax, [rdi+8]add eax, [rdi+12]jmp doneyesyes:mov eax, [rdi+4]sub eax, [rdi+8]sub eax, [rdi+12]
done:
as -o
ld -oindirect-jump 间接跳转
在这个关卡,您将使用控制流操作。这涉及到使用指令来间接或直接控制特殊寄存器 rip (指令指针)。你将使用诸如 jmp 、 call 、 cmp 以及它们的替代指令来实现所请求的行为。
我们将在这个关卡中使用动态值多次测试您的代码!这意味着我们将以各种随机的方式运行你的代码,以验证逻辑是否足够稳固,可以正常使用。
最后一种跳转类型是间接跳转,通常用于switch语句。Switch语句是一种特殊的if语句,它只使用数字来确定控制流的走向。
下面是一个例子:
switch(number):0: jmp do_thing_01: jmp do_thing_12: jmp do_thing_2default: jmp do_default_thing
本例中的开关工作在 number 上,它可以是0、1或2。如果 number 不是这些数字之一,则触发默认(default)。你可以认为这是一个简化的else-if类型结构。在x86中,你已经习惯了使用数字,所以你可以基于一个精确的数字来编写if语句也就不足为奇了。此外,如果你知道数字的范围,switch语句就可以很好地工作。
以跳转表的存在为例。跳转表是一个连续的内存段,其中保存了要跳转的地址。
在上面的例子中,跳转表如下所示:
[0x1337] = address of do_thing_0
[0x1337+0x8] = address of do_thing_1
[0x1337+0x10] = address of do_thing_2
[0x1337+0x18] = address of do_default_thing
使用跳转表,可以大大减少 cmps 的使用量。现在我们需要检查的是 number 是否大于2。如果是,就一直这样做:
jmp [0x1337+0x18]
否则:
jmp [jump_table_address + number * 8]
使用上述知识,实现以下逻辑:
if rdi is 0:jmp 0x40301e
else if rdi is 1:jmp 0x4030da
else if rdi is 2:jmp 0x4031d5
else if rdi is 3:jmp 0x403268
else:jmp 0x40332c
请按照以下约束条件执行上述操作:
- 假设
rdi不为负。 - 使用不超过1条
cmp指令。 - 使用不超过3个跳跃(任何变体)。
- 我们将在
rdi中为您提供要“接通”的数字。 - 我们将为您提供
rsi中的跳转表基址。
下面是一个示例表:
[0x40427c] = 0x40301e (addrs will change)
[0x404284] = 0x4030da
[0x40428c] = 0x4031d5
[0x404294] = 0x403268
[0x40429c] = 0x40332c
查看解析
.intel_syntax noprefix
cmp rdi, 3 ; 比较 rdi 和 3
jg default ; 如果 rdi > 3,跳转到默认跳转
; 如果 rdi 在 0 到 3 之间,使用跳转表
mul rdi, 8
jmp [rsi + rdi * 8] ; 使用 rsi 作为跳转表基地址,通过 rdi 计算偏移量进行跳转
default:jmp qword ptr [rsi + 32] ; 默认跳转到跳转表最后一个地址
done:
as -o
ld -oaverage-loop 循环计算平均值
现在,我们将在每次运行之前在内存中动态设置一些值。每次运行时,这些值都会改变。这意味着你需要对寄存器执行某种公式化的操作。我们会告诉你哪些寄存器是预先设置的,以及你应该把结果放在哪里。大多数情况下,它是 rax 。
在这个关卡,您将处理控制流操作。这涉及到使用指令来间接和直接控制特殊寄存器 rip (指令指针)。你将使用诸如 jmp 、 call 、 cmp 以及它们的替代指令来实现所请求的行为。
在上一关卡中,你计算了4个整数四字的平均值,这是要计算的固定数量的东西。但如何处理程序运行时得到的尺寸呢?
在大多数编程语言中,都存在一种称为for循环的结构,它允许你在有限的时间内执行一组指令。限定的数值可以在程序运行之前或运行期间确定,“during”表示这个值是动态给定的。
例如,可以使用for循环计算数字1 ~ n的和:
sum = 0
i = 1
while i <= n:sum += ii += 1
计算 n 连续四词的平均值,其中:
rdi=第一个四字内存地址rsi=n(循环的次数)rax=计算平均值
查看解析
.intel_syntax noprefix
mov rax, 0 ; 清空 rax (用来存储累加和)
mov rbx, rsi ; 将 n (rsi) 复制到 rbx,作为循环计数器
; 循环开始
.loop:cmp rbx, 0 ; 检查是否还有迭代次数je .done ; 如果 rcx == 0, 结束循环add rax, [rdi] ; 累加当前四字到 raxadd rdi, 8 ; 将 rdi 指向下一个四字 (8 字节对齐)dec rbx ; 减少迭代次数jmp .loop ; 跳回循环
.done:; 计算平均值 (除以 n); 将 rax 中的值除以 rsi (n)div rsi ; 将 rax 除以 n; 结果存储在 rax 中
as -o
ld -ocount-non-zero 计数非零值
在这个关卡,您将处理控制流操作。这涉及到使用指令来间接和直接控制特殊寄存器 rip (指令指针)。你将使用诸如 jmp 、 call 、 cmp 以及它们的替代指令来实现所请求的行为。
我们将在这个关卡中使用动态值多次测试您的代码!这意味着我们将以各种随机的方式运行你的代码,以验证逻辑是否足够稳固,可以正常使用。
在前面几关卡中,你发现for循环可以迭代很多次,动态和静态都是已知的,但如果你想迭代直到满足某个条件,会发生什么呢?
存在另一种循环结构,称为while-loop,可以满足这种需求。在while循环中,迭代直到满足某个条件。
举个例子,假设我们在内存中有一个相邻数字的位置,我们想要得到所有数字的平均值,直到找到一个大于或等于 0xff :
average = 0
i = 0
while x[i] < 0xff:average += x[i]i += 1
average /= i
利用以上知识,请执行以下操作:
在内存的连续区域中计算连续的非零字节,其中:
rdi=第1字节内存地址rax=连续非零字节数
另外,如果 rdi = 0 ,则设置 rax = 0 (我们将检查)!
下面是一个测试用例的例子:
rdi = 0x1000[0x1000] = 0x41[0x1001] = 0x42[0x1002] = 0x43[0x1003] = 0x00
设 rax = 3 。
查看解析
.intel_syntax noprefix
mov rax, 0 ; 初始化 rax 为 0,作为非零字节的计数器
mov rsi, 0 ; 初始化 rsi 为 0,用于计数连续的非零字节
; 检查 rdi 是否为零,如果是,则直接跳转到 done
test rdi, rdi ; test 只是检查 operand1 和 operand2 的按位与结果,更新标志寄存器,但不修改操作数本身。检查 rdi 是否为零
jz .done ; 如果 rdi 为零,则跳转到 done(设置 rax = 0)
.loop:cmp byte ptr [rdi], 0 ; 比较当前字节是否为零je .done ; 如果是零,跳转到 done(结束循环)add rax, 1 ; 非零字节计数器加 1add rdi, 1 ; 移动到下一个字节jmp .loop ; 继续循环
.done:; rax 中保存的是连续非零字节的数量; 结束程序as -o
ld -ostring-lower 字符串转小写
我们将在这个关卡中使用动态值多次测试您的代码!这意味着我们将以各种随机的方式运行你的代码,以验证逻辑是否足够稳固,可以正常使用。
在这一关卡,你将使用函数!这将涉及操作指令指针(rip),以及执行比通常更难的任务。您可能会被要求使用堆栈来存储值或调用我们提供的函数。
在前面的关卡中,我们实现了一个while循环来计算内存连续区域中连续非零字节的数量。
在这一关卡,用户将再次获得一个连续的内存区域,并循环遍历每个执行条件操作的区域,直到达到0字节。所有这些都将包含在一个函数中!
函数是一段不会破坏控制流的可调用代码。
函数使用“call”和“ret”指令。
“call”指令将下一条指令的内存地址压入栈中,然后跳转到存储在第一个参数中的值。
让我们以下面的指令为例:
0x1021 mov rax, 0x400000
0x1028 call rax
0x102a mov [rsi], rax
call将下一条指令的地址0x102a压入栈中。call跳转到0x400000,保存在rax中。
“ret”指令与“call”指令相反。
ret 弹出栈顶值并跳转到它。
让我们以下面的指令和栈为例:
Stack ADDR VALUE
0x103f mov rax, rdx RSP + 0x8 0xdeadbeef
0x1042 ret RSP + 0x0 0x0000102a
这里, ret 将跳转到 0x102a 。
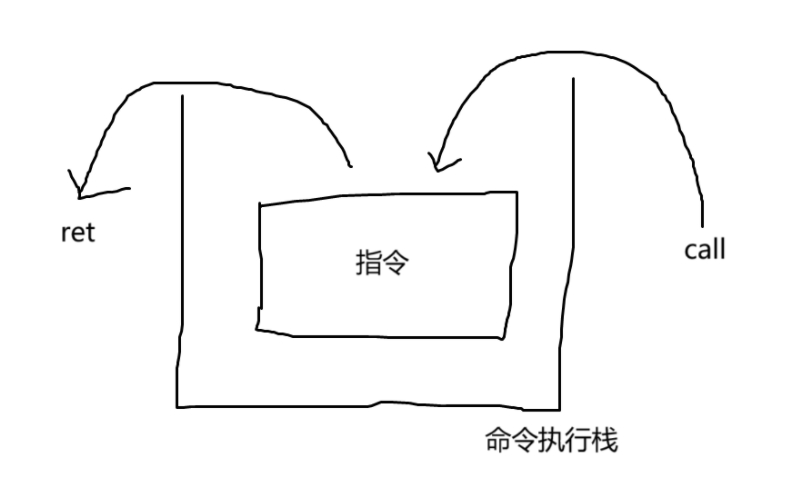
请实现以下逻辑:
str_lower(src_addr):i = 0if src_addr != 0:while [src_addr] != 0x00:if [src_addr] <= 0x5a:[src_addr] = foo([src_addr])i += 1src_addr += 1return i
foo 为 0x403000 。 foo 接受一个参数作为值,并返回一个值
所有函数(foo和str_lower)必须遵循Linux amd64调用约定(也称为System V amd64 ABI): System V AMD64 ABI
因此,你的函数 str_lower 应该在 rdi 中寻找 src_addr ,并将函数返回值放在 rax 中。
需要注意的是, src_addr 是内存中的一个地址(字符串所在的位置),而 [src_addr] 指的是存在于 src_addr 的字节。
因此, foo 函数接受一个字节作为它的第一个参数,并返回一个字节。
查看解析
.intel_syntax noprefix
str_lower:mov rbx, 0x403000 ; 将 foo 函数的地址 (0x403000) 加载到 rbx 寄存器中xor rcx, rcx ; 清空 rcx 寄存器,用作计数器,记录转换为小写字母的字节数test rdi, rdi ; 检查传入的字符串地址 (rdi) 是否为空jz done ; 如果 rdi 为 0,跳转到 done,表示字符串为空,无需处理
process_string:mov al, byte ptr [rdi] ; 将当前字节(rdi 指向的地址的值)加载到 al 寄存器中test al, al ; 检查当前字节是否为 NULL 字符(0x00),即字符串结束标志jz done ; 如果是 NULL 字符(0x00),跳转到 done,表示字符串结束cmp al, 0x5A ; 比较当前字符是否大于 'Z' (0x5A)jg skip_conversion ; 如果字符大于 'Z'(即不是大写字母),跳到 skip_conversion,跳过转换mov rsi, rdi ; 保存当前字符串地址 (rdi) 到 rsi,稍后恢复mov dil, al ; 将当前字节(大写字母)存入 rdi 寄存器的低字节部分(dil),作为 foo 函数的参数call rbx ; 调用 foo 函数,转换字节为小写字母,转换结果将返回在 al 寄存器mov rdi, rsi ; 恢复原始的 rdi 地址mov byte ptr [rdi], al ; 将转换后的字节(存储在 al 中)写回原地址,替换原来的字符inc rcx ; 增加转换计数器 rcx,记录已经转换为小写字母的字节数
skip_conversion:inc rdi ; 移动到下一个字符(增加 rdi,指向下一个字节)jmp process_string ; 跳回 process_string 继续处理下一个字符
done:mov rax, rcx ; 将转换的字节数(rcx)存入 rax,作为返回值ret ; 返回,rax 包含转换的小写字节数量
as -o
ld -o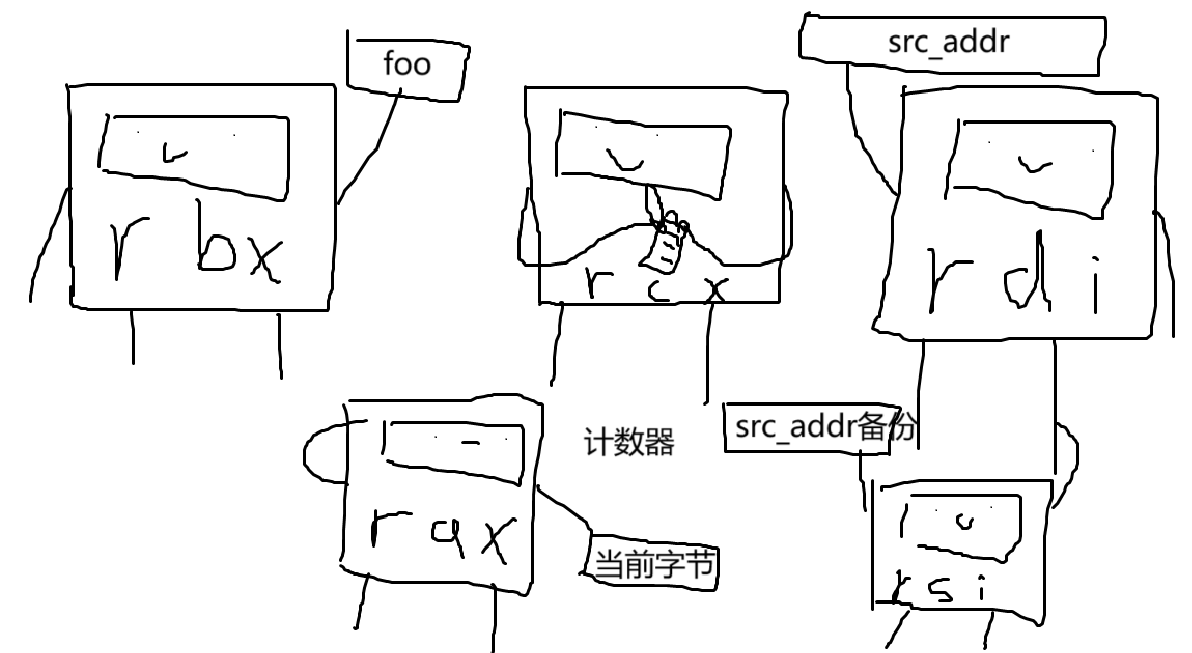
most-common-byte 最常见字节
我们将在这个关卡中使用动态值多次测试您的代码!这意味着我们将以各种随机的方式运行你的代码,以验证逻辑是否足够稳固,可以正常使用。
在这一关卡,你将使用函数!这将涉及操作指令指针(rip),以及执行比通常更难的任务。您可能会被要求使用堆栈来存储值或调用我们提供的函数。
在前一关卡中,你学习了如何创建第一个函数以及如何调用其他函数。现在我们将使用具有函数栈帧的函数。
函数栈帧是一组压入栈中的指针和值的集合,用于保存内容以供以后使用,并在栈上为函数变量分配空间。
首先,让我们讨论一下特殊寄存器 rbp ,即栈基指针。
rbp 寄存器用于告诉我们栈帧第一次从哪里开始。举个例子,假设我们想构建一个只在函数中使用的列表(一个连续的内存空间)。这个列表有5个元素,每个元素是一个dword。一个包含5个元素的列表已经占用了5个寄存器,因此,我们可以在堆栈上腾出空间!
程序集看起来像这样:
; 将栈基址设置为当前栈顶
mov rbp, rsp
; 将栈向下移动 0x14 字节 (5 * 4)
; 这相当于分配空间
sub rsp, 0x14
; 将 list[2] 赋值为 1337
mov eax, 1337
mov [rbp-0x8], eax
; 对列表进行更多操作...
; 恢复已分配的空间
mov rsp, rbp
ret
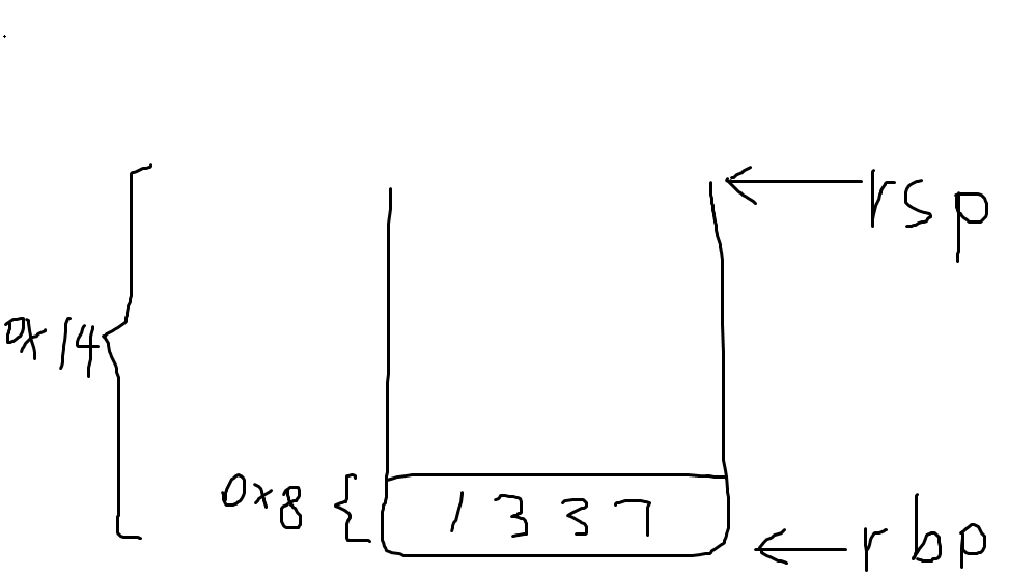
请注意, rbp 总是用于将栈恢复到最初的位置。如果我们在使用后不恢复堆栈,我们最终将耗尽。另外,注意我们是如何从 rsp 减去的,因为栈是向下增长的。为了让堆栈有更多的空间,我们减去所需的空间。 ret 和 call 仍然起作用。
再一次,请创建实现以下功能的函数:
most_common_byte(src_addr, size):i = 0while i <= size-1:curr_byte = [src_addr + i][stack_base - curr_byte] += 1i += 1b = 0max_freq = 0max_freq_byte = 0while b <= 0xff:if [stack_base - b] > max_freq:max_freq = [stack_base - b]max_freq_byte = bb += 1return max_freq_byte
假设:
- 任何字节的长度都不会超过0xffff
- 这个长度永远不会大于0xffff
- 这个列表至少有一个元素
约束:
- 你必须把“计数列表”放在堆栈上
- 您必须像恢复普通函数一样恢复堆栈
- 不能修改
src_addr处的数据
查看解析
.intel_syntax noprefix
.intel_syntax noprefix
most_common_byte:push rbp ; 保存调用者的基址寄存器(rbp),为函数的栈帧做好准备mov rbp, rsp ; 设置当前函数的栈帧基址sub rsp, 256 ; 为字节计数器数组分配 256 字节空间(用来记录每个字节出现的次数)xor rcx, rcx ; 将 rcx 清零,用作计数器(用于循环)
initialize_counting_list_with_zero:mov byte ptr [rbp + rcx - 256], 0 ; 将计数数组的当前字节位置初始化为 0inc rcx ; 增加 rcx,移动到下一个字节位置cmp rcx, 256 ; 检查 rcx 是否达到 256(即数组的末尾)jl initialize_counting_list_with_zero ; 如果 rcx 小于 256,继续初始化下一个字节xor rcx, rcx ; 清零 rcx,准备计数字节的出现次数
count_bytes:movzx eax, byte ptr [rdi + rcx] ; 加载当前字节(rdi 是字符串的起始地址)到 eax 寄存器inc byte ptr [rbp + rax - 256] ; 将该字节在计数数组中的计数加 1,数组位置为 rax-256inc rcx ; 移动到下一个字节cmp rcx, rsi ; 比较 rcx 和 rsi,rsi 是字符串的长度jl count_bytes ; 如果 rcx 小于 rsi,继续处理下一个字节
init_b_max_freq_max_freq_byte:xor rcx, rcx ; 清零 rcx,用作索引xor rdx, rdx ; 清零 rdx,用来存储当前字节出现的最大频率xor rbx, rbx ; 清零 rbx,用来存储具有最大频率的字节
find_most_common_byte:movzx eax, byte ptr [rbp + rcx - 256] ; 加载计数数组中的当前字节频率到 eaxcmp al, dl ; 比较当前字节的频率与当前最大频率(dl)jle next_byte ; 如果当前字节的频率小于等于最大频率,跳到下一个字节
update_max_freq_and_max_freq_byte:mov dl, al ; 更新最大频率(dl)mov bl, cl ; 更新最大频率字节(bl)
next_byte:inc rcx ; 移动到下一个字节位置cmp rcx, 256 ; 检查是否已遍历所有字节jl find_most_common_byte ; 如果 rcx 小于 256,继续检查下一个字节
return:mov al, bl ; 将具有最大频率的字节存入 al,作为返回值
restore:mov rsp, rbp ; 恢复栈指针pop rbp ; 恢复基址寄存器ret ; 返回
as -o
ld -oDebugging Refresher 调试进修
level1
运行/challenge/embryogdb_level1程序即会自动打开搭载了/challenge/embryogdb_level1程序的GDB(像是套娃),先是向我们显示了GDB程序的版权开头内容,我们输入run或r在GDB中运行/challenge/embryogdb_level1程序
运行后,会出现以下内容:
GDB是一个非常强大的动态分析工具,您可以使用它来了解程序在整个执行过程中的状态。在本模块中,您将熟悉gdb的一些功能。您正在运行gdb!程序当前处于暂停状态。这是因为它在这里设置了自己的断点。您可以使用‘ start ’命令启动程序,并在‘ main ’上设置断点。
您可以使用‘ starti ’命令来启动一个程序,在‘ _start ’上设置断点。
你可以使用命令“run”来启动一个程序,不带断点集。
您可以使用命令“attach <PID>”来附加到其他已经运行的程序。
可以使用命令‘ core <PATH> ’分析已运行程序的核心转储。
在启动或运行程序时,您可以以与在shell上几乎完全相同的方式指定参数。
例如,您可以使用‘ start <ARGV1> <ARGV2> <ARGVN> <STDIN_PATH> ’。使用命令‘ continue ’,或简称‘ c ’,以继续程序执行。
我们为了从断点处继续运行/challenge/embryogdb_level1程序,输入以下命令
continue
或
c
/challenge/embryogdb_level1程序继续运行,我们得到flag
level2
GDB是一个非常强大的动态分析工具,您可以使用它来了解程序在整个执行过程中的状态。在本模块中,您将熟悉gdb的一些功能。你可以用‘ info registers ’查看所有寄存器的值。
或者,您也可以使用‘ print ’命令或简称‘ p ’命令打印特定寄存器的值。例如,‘ p $rdi ’将以十进制形式打印$rdi的值。你也可以用十六进制‘ p/x $rdi ’打印它的值。为了解决这个问题,你必须用十六进制计算出寄存器r12的当前随机值。随机值已设置!
为了查看寄存器r12的当前随机值我们输入以下命令:
info registers #可以查看所有寄存器的值
p $r12 #以十进制形式打印$r12的值
p/x $r12 #以十六进制形式打印$r12的值
得到r12的值后,我们从断点处继续运行/challenge/embryogdb_level2程序,它会问我们r12寄存器中随机的值是多少,我们输入即可得到flag
level3
GDB是一个非常强大的动态分析工具,您可以使用它来了解程序在整个执行过程中的状态。在本模块中,您将熟悉gdb的一些功能。您可以使用‘ x/<n><u><f> <address> ’参数化命令检查内存的内容。
在这种格式中,‘ <u> ’是要显示的单位大小,‘ <f> ’是要显示的格式,‘ <n> ’是要显示的元素数量。有效单元大小为‘ b ’(1字节),‘ h ’(2字节),‘ w ’(4字节)和‘ g ’(8字节)。有效的格式是‘ d ’(十进制),‘ x ’(十六进制),‘ s ’(字符串)和‘ i ’(指令)。地址可以使用寄存器名、符号名或绝对地址来指定。
此外,您可以在指定地址时提供数学表达式。例如,‘ x/8i $rip ’将从当前指令指针中打印接下来的8条指令。‘ x/16i main ’将打印main的前16条指令。你也可以使用‘ disassemble main ’,或者简称‘ disas main ’,来打印main的所有指令。或者,‘ x/16gx $rsp ’将打印堆栈上的前16个值。‘ x/gx $rbp-0x32 ’将打印存储在堆栈上的本地变量。您可能希望使用正确的程序集语法查看指令。你可以用命令“set disassembly-flavor intel”来做。为了解决这个问题,你必须找出堆栈上的随机值(从‘ /dev/urandom ’读取的值)。考虑一下read系统调用的参数是什么。
为了查看堆栈上的随机值,我们应该从栈顶指针寄存器rsp入手,我们输入以下命令:
x/16gx $rsp
c #继续进程进程设置随机值
x/16gx $rsp
复制与旧值不同的新值(上面的旧值和相应的新值大部分相同)即可得到flag
level4
GDB是一个非常强大的动态分析工具,您可以使用它来了解程序在整个执行过程中的状态。在本模块中,您将熟悉gdb的一些功能。动态分析的一个关键部分是将程序运行到您感兴趣的状态。到目前为止,这些挑战已经为您自动设置了断点,以便在您可能感兴趣的状态下暂停执行。自己能够做到这一点非常重要。在程序的执行过程中,有多种方式可以向前移动。
您可以使用`stepi <n>`命令或`si <n>`命令(简写)向前单步执行一条指令。
您可以使用`nexti <n>`命令或`ni <n>`命令(简写)向前单步执行一条指令,同时跳过任何函数调用。`<n>`参数是可选的,但可以让您一次执行多个步骤。
您可以使用`finish`命令来完成当前正在执行的函数。
您可以使用`break *<address>`参数化命令在指定的地址设置断点。
您已经使用了`continue`命令,它将继续执行,直到程序遇到断点。在逐步执行程序时,您可能会发现始终显示一些值对您很有用。有多种方法可以做到这一点。
最简单的方法是使用`display/<n><u><f>`参数化命令,其格式与`x/<n><u><f>`参数化命令完全相同。
例如,`display/8i $rip`将始终显示接下来的8条指令。
另一方面,`display/4gx $rsp`将始终显示堆栈上的前4个值。
另一个选项是使用`layout regs`命令。这将GDB切换到TUI模式,并显示所有寄存器的内容,以及附近的指令。为了解决这个问题,您必须找出一系列将放置在堆栈上的随机值。强烈建议您尝试使用`stepi`、`nexti`、`break`、`continue`和`finish`的组合,以确保您对这些命令有良好的内部理解。这些命令在导航程序的执行过程中是绝对关键的。
为了更好地理解程序运行,我们可以使gdb进入TUI模式,显示所有寄存器的内容以及附近的指令
layout regs
如果显示出错了可以
为了查看堆栈上的随机值,我们应该从栈顶指针寄存器rsp入手,我们输入以下命令:
x/16gx $rsp
ni 18 #继续进程进程设置随机值,这一次没有断点处所以需要手动向前单步执行命令,这里执行了17次才设置了随机变量,ni 18指向前单步执行到第18条指令(包括当前)
x/16gx $rsp
复制与旧值不同的新值(上面的旧值和相应的新值大部分相同)会再次设置新的随机值并且跳转到下一个输入随机值的地方
(未完待续……)
![[SUCTF 2019]CheckIn](https://img2024.cnblogs.com/blog/3549480/202411/3549480-20241106000904571-983982594.png)