最近想着来玩一玩大数据, 前段时间集中过了一遍 java, 最近又看了一些基础的 scala, 我感觉吧, 我都不想学. 还是觉得用 sql, javascript, python 这种脚本语言操作起来顺手, 但这并不影响对这个大数据生态的理解和学习. 这里主要是来记录一下 spark + jupyter 环境的搭建, 说实话还折腾了好久才搞定. 主要是做个记录而已.
前置条件
- linux 环境, 我这里用的是 centos
- 安装了hadoop, 我这里用 hadoop3.2.0 搭建了一个 1主2从的伪分布式集群环境
- 用的是 VM 虚拟机, 我用的是 windows 环境, 用的终端工具是
SecureCRT贼好用 - 克隆了一个
客户端节点出来, 上面可以安装各类程序, 通过yarn来进行集群调度即可

安装 Spark on Yarn
用的是一个老版本 3.2.1, 从官网 https://archive.apache.org/dist/spark/spark-3.2.1/
下载 spark-3.2.1-bin-hadoop3.2.tgz 这个带 hadoop 的版本即可.
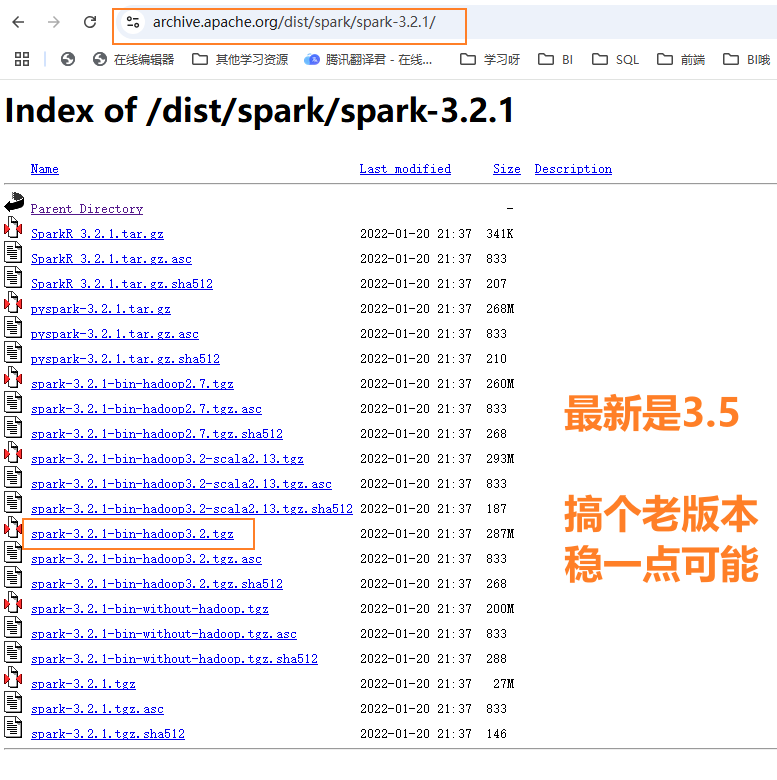
上传到客户端节点 /data/soft/ 目录下, 然后进行解压
tar -zxvf spark-3.2.1-bin-hadoop3.2.tgz
将它改个简短一点的名字, 叫 spark3 吧
mv spark-3.2.1-bin-hadoop3.2 spark3
重命名 spark-env.sh.template
cd spark3/conf
mv spark-env.sh.template spark-env.sh
配置上 JAVA_HOME 和 Hadoop 的配置目录即可.
vi spark-env
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_CONF_DIR=/data/soft/hadoop-3.2.0/etc/hadoop
:wq
这样就配置好了, 然后来配置一些环境变量方便后面使用, 我用的是 centos, 这里直接配置系统环境变量即可
vi /etc/profile
在末尾配置上
for i in /etc/profile.d/*.sh /etc/profile.d/sh.local ; doif [ -r "$i" ]; thenif [ "${-#*i}" != "$-" ]; then. "$i"else. "$i" >/dev/nullfifi
doneunset i
unset -f pathmungeexport JAVA_HOME=/data/soft/jdk1.8
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export HADOOP_CONF_DIR=/data/soft/hadoop-3.2.0/etc/hadoop
export SPARK_HOME=/data/soft/spark3export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_CONF_DIR:$SPARK_HOME/bin:$PATH然后执行文件让其生效
source /etc/profile
这样全局环境变量也配置好了.
安装 conda 环境
主要是为了省事, 一并安装上 python3 和 jupyter. 用原生的话不是太好操作.
也是从官网下载, https://www.anaconda.com/download/success
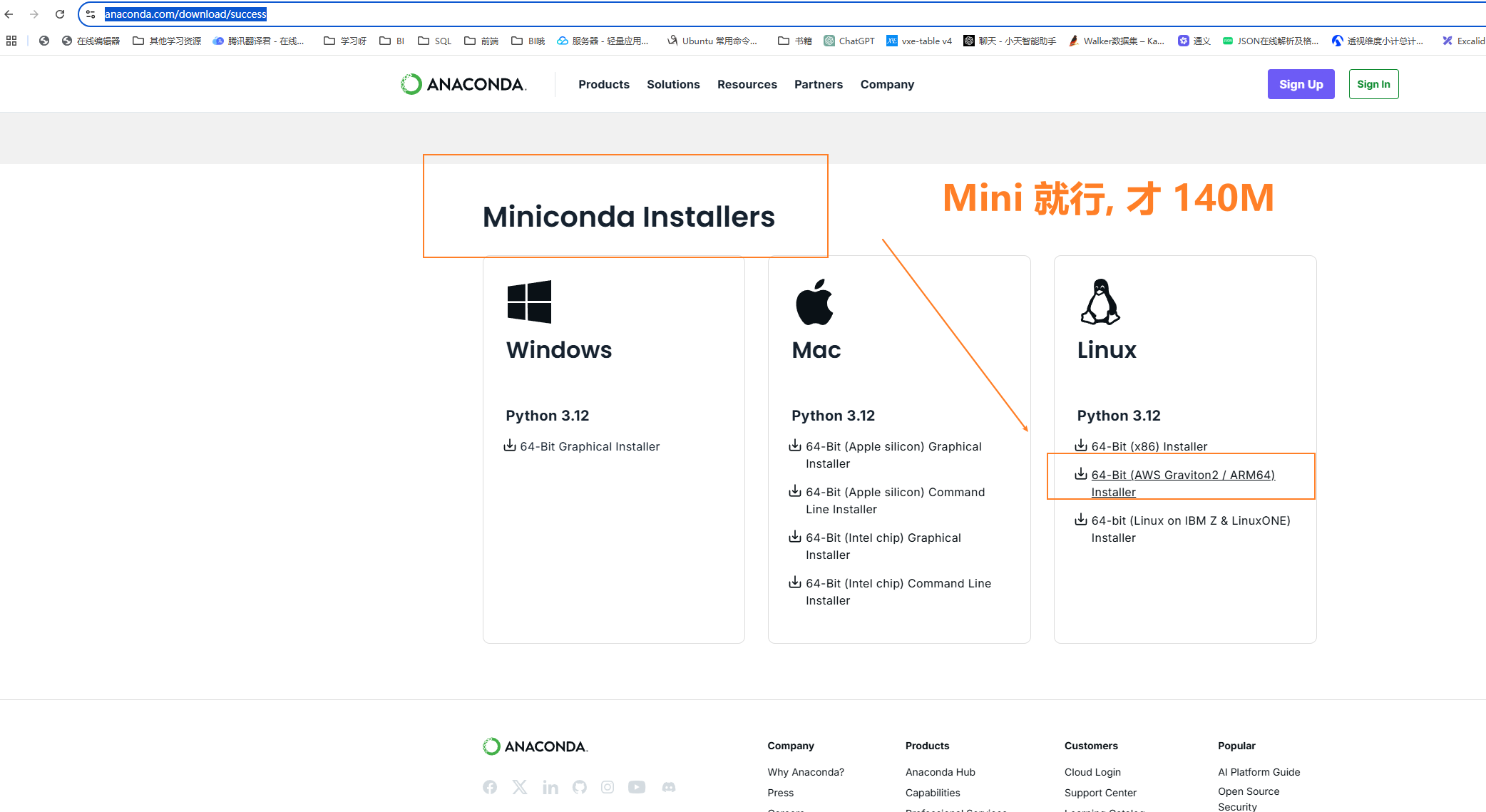
注意这里我们选择 Linux 版的 Miniconda 它就只包含了 python3 + conda 只有 140M 就很好, 全套的话有 1GB. 没有必要全下, 后面要用的话, 用 conda install xxx 就行了.
将下载的文件 Miniconda3-latest-Linux-x86_64.sh 也放到 data/soft 目录下, 其实放哪都行, 然后执行文件一直回车就安装好了.
bash Miniconda3-latest-Linux-x86_64.sh
如果不指定的话, 它就默认安装在 /root/miniconda3 这里.
进入 conda 的默认虚拟环境 base
conda activate
然后来创建一个名为 py38 的虚拟环境, 就安装一个 python3.8 嘛, 当然 3.9, 3.10 都是可以滴.
conda create -n py38 python=3.8
等待之后,验证一下就行了.
conda activate py38
python --version
显示:
Python 3.8.20
这样虚拟环境也就成功啦. 然后是几个常用的 conda 命令
创建是虚拟环境: conda create -n py38 python=3.8
查看虚拟环境: conda env list删除虚拟环境: conda env remove --name env_name进入虚拟环境: conda activate py38
退出虚拟环境: conda deactivate查看安装的包: conda list
安装新的包: conda install xxx
最后是来寻找一下虚拟环境中 python 的位置, 等下配置需要用.
conda activate py38
which python
可以看到, python 的执行目录在
/root/miniconda3/envs/py38/bin/python
配置 pyspark
- 在虚拟环境中, 配置上 Jdk, Spark, Hadoop 的环境变量
- 将Spark 里面的 pyspark 包直接 copy 到 python 的 site-packages 下, 这样等同于
pip install
先在虚拟环境下配置上 spark 等路径 (当前用户)
vi ~/.bashrc
在尾部追加, 和之前在 /etc/profile 的配置一样的, 主要是为了在虚拟环境中能找到 spark
export JAVA_HOME=/data/soft/jdk1.8
export SPARK_HOME=/data/soft/spark3
export PYSPARK_PYTHON=/root/miniconda3/envs/py38/bin/pythonexport HADOOP_HOME=/data/soft/hadoop-3.2.0
export HADOOP_CONF_DIR=/data/soft/hadoop-3.2.0/etc/hadoopexport PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_CONF_DIR:$SPARK_HOME/bin:$PYSPARK_PYTHON:$PATH
然后是本篇最关键的一步, 安装 pyspark 注意这里不要去 conda install pyspark , 这有2个坑
- 如果版本不兼容或者少什么东西的话, 就很难搞
- pyspark 特别大, 200多M, 就镜像源也不是很靠谱
解决这个问题的核心是理解 python 中通过 pip 或者 conda install 的本质是将别人的安装包下载下来,
解压安装到 python 安装包目录lib/site-packages 目录下, 就能进行 import xxx .
pip /conda insatall A => Dowload A -> python's lib/site-packages
那既然是这样, 直接将 Spark 目录下的 python/pyspark 复制到 python 对应的 site-packages 即可, 这样还绝对兼容和适配 !
对比 Java 中的 Maven 也是一样的操作.
先下载一个 maven 安装包到本地, 然后构建 maven 项目, 在 pom.xml 中, 找到远程仓库的 jdk 链接.
然后就会自动下载对应的 JDK 到本地目录了, 这样就可以直接引用.
后面进行编译, 打包啥的, 其实和 Python 是一样的思路. 或者说几乎所有的都是这样, 掌握了原理就很简单.
这里比较麻烦的就是找这个 conda 下的 python 的虚拟环境, 刚建的 py38 的 site-package 在这里.
/root/miniconda3/envs/py38/lib/python3.8/site-packages/
最后就简单了, 直接 spark 中将对应的文件 copy 过去即可.
cp -r /data/spark/python/lib/py4j-*.zip /root/miniconda3/envs/py38/libpython3.8/site-packages/cp -r /data/soft/spark3/python/pyspark /root/miniconda3/envs/py38/lib/python3.8/site-packages/大功搞成!
安装 Jupyter 环境
也是先进入虚拟环境:
conda activate py38
然后直接安装 jupyter
conda install jupyter
等待安装好后, 对 jupyter 进行一些配置, 先生成一个配置文件
jupyter notebook --generate-config
然后打开文件
vi ~/.jupyter/jupyter_notebook_config.py
配置上一些基础设置, 主要是 允许远程访问, 设置远程端口 和禁止用浏览器自动打开等.
# 允许远程访问
c.NotebookApp.ip = '0.0.0.0'# 设置端口
c.NotebookApp.port = 8888# 禁用浏览器自动打开
c.NotebookApp.open_browser = False# 设置基础 URL(可选)
# c.NotebookApp.base_url = '/jupyter/'# 禁用 token 认证(注意:这会使 Jupyter Notebook 更容易被未授权访问)
c.NotebookApp.token = ''
然后直接启动 jupyter 服务即可, 注意这里我用的 root , 可能会被禁止, 这里配置允许即可.
不配置启动路径的话, 就当前在哪个路径, 等下就会以当前路径作为服务根节点, 我一般是 cd ~
jupyter notebook --allow-root
I 2024-11-06 23:04:38.622 ServerApp] jupyterlab | extension was successfully loaded.
[I 2024-11-06 23:04:38.626 ServerApp] notebook | extension was successfully loaded.
[I 2024-11-06 23:04:38.627 ServerApp] Serving notebooks from local directory: /root
[I 2024-11-06 23:04:38.627 ServerApp] Jupyter Server 2.14.1 is running at:[I 2024-11-06 23:04:38.627 ServerApp] http://192.168.15.3:8888/tree
[I 2024-11-06 23:04:38.627 ServerApp] http://127.0.0.1:8888/tree[I 2024-11-06 23:04:38.627 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[W 2024-11-06 23:04:38.631 ServerApp] No web browser found: Error('could not locate runnable browser').
成功启动后, 可以在 windows 中进行远程访问啦!
http://192.168.15.3/tree
环境验证
主要是在 windos 下能通过 jupyte notebook 进行远程连接 saprk 并启动任务就行啦.
这里我们用 Local 模式测试一下就行, 后面用 Yarn 也是类似的配置
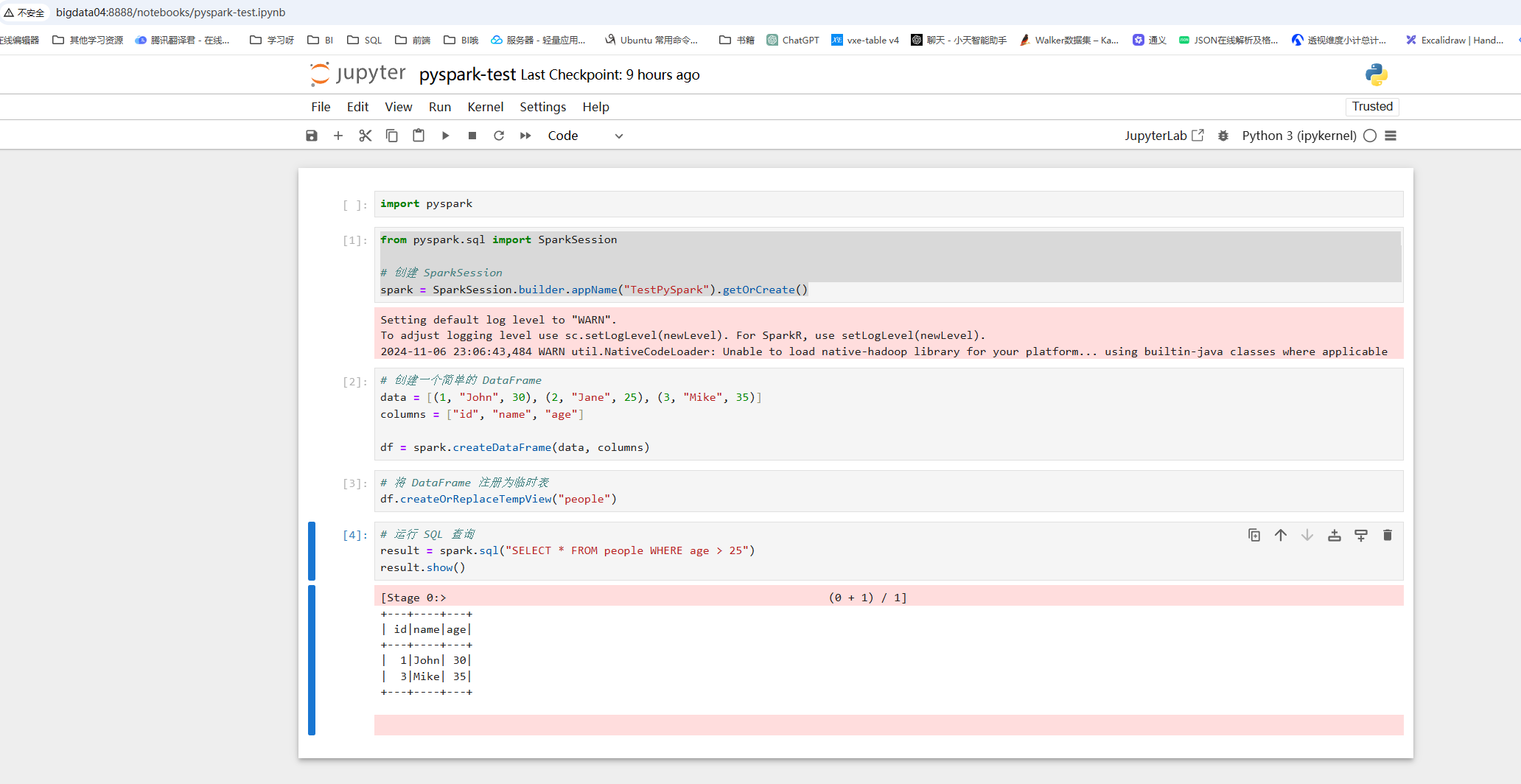
1. 启动一个任务环境
from pyspark.sql import SparkSession# 创建 SparkSession
spark = SparkSession.builder.appName("TestPySpark").getOrCreate()
会有一些警告日志不用管它
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
2024-11-06 23:06:43,484 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2. 创建一个简单的 DataFrame
data = [(1, "John", 30), (2, "Jane", 25), (3, "Mike", 35)]
columns = ["id", "name", "age"]df = spark.createDataFrame(data, columns)
3. 将 DataFram 注册为临时表 lazy 不耗时的, 随便搞
df.createOrReplaceTempView("people")
5. 进行SQL查询
result = spark.sql("SELECT * FROM people WHERE age > 25")
result.show()
5. 结果输出
+---+----+---+
| id|name|age|
+---+----+---+
| 1|John| 30|
| 3|Mike| 35|
+---+----+---+
6. 可以通过 web 来查看 spark 任务, 本地模式下默认是 4040 端口
http://192.168.15.103:4040/jobs/
至此, 就可以愉快的玩一波 spark 啦, 用 jupyter notebook , 当然后面可以对比 scala 来更深刻理解一波.
![LeetCode3264[K次乘运算后的最终数组I]](https://img2024.cnblogs.com/blog/3512406/202411/3512406-20241106162122694-346588470.png)