在开始本章之前,我们得了解一个概念,那就是我们怎么知道这个对象是"垃圾"?所以如何定义垃圾就成为我们第一个需要探讨的重要的点之一。
垃圾标记算法
常见的垃圾标记算法有:引用计数算法和可达性分析算法。
引用计数算法
实现思路
每个对象去额外存储一个引用计数器,这个计数器统计了对象被引用的次数,当被引用的次数为0时,就可以认为它是垃圾了。
优点
实现简单,垃圾对象便于识别;判定效率高,回收没有延迟性。
缺点
它有一个致命的缺陷,导致了它这个算法没有被采用。那就是它解决不了循环依赖(或者说解决的成本太高了)。
这个问题导致的直接问题就是--内存泄漏。

可达性分析算法
GC Roots
GC Roots的对象包含以下几种:
-
虚拟机栈(栈帧中的本地变量表)中引用的对象。(可以理解为:引用栈帧中的本地变量表的所有对象)
-
方法区中静态属性引用的对象(可以理解为:引用方法区该静态属性的所有对象)
-
方法区中常量引用的对象(可以理解为:引用方法区中常量的所有对象)
-
本地方法栈中(Native方法)引用的对象(可以理解为:引用Native方法的所有对象)
当然随着用户选用的垃圾回收器以及当前区域的不同,也可能有其他对象"临时性"地加入GC Roots。
谈谈引用
-
强引用:我们平常用new创建的对象所获得的引用就是强引用。被强引用引用的对象,无论发生什么都不会垃圾回收。
-
软引用:软引用主要用来描述一些还有用,但非必须的对象。只被软引用关联的对象,在系统即将要发生OOM时,会被垃圾回收。
-
弱引用:弱引用主要用来描述一些非必须对象。所有被弱引用关联的对象,只能生存到下一次垃圾回收发生为止。
-
虚引用:虚引用不会影响对象的存活时间,也无法通过虚引用来获取对象实例。唯一作用就是能在这个对象被收集器回收时收到一个系统通知。
生与死 & finalize()
如果在可达性分析算法中被认定为不可达对象,也不是"非死不可",他们处于缓刑状态,这时候会调用finalize()方法(如果对象重写了该方法那么执行重写方法),这个是他活路的唯一时机。如果在finalize()还没有重新建立引用,那么下一次标记为不可达时,那它必定会死。
要真正宣告一个对象的死亡,至少要经历两次标记。
实现思路
-
可达性分析算法是以根对象集合(GC Roots)为起始点,按照从上到下的方式搜索被根对象集合所连接的目标对象是否可达。
-
使用可达性分析算法后,内存中存活的对象都会直接或间接跟根对象集合连接,搜索所走过的路径称为引用链。
-
如果目标对象没有任何引用链相连,则是不可达的,意味着目标对象已死亡,可以标记为垃圾对象。
-
只有被根对象集合直接或间接连接的对象才是存活对象。

并发的可达性分析--三色标记法
思想
将对象根据状态标记为黑、灰、白三种颜色。
白:该对象没有被标记过,为垃圾。(当然最开始都是白色的)
灰:该对象已经标记过了,但是该对象下的引用还没有标记完。
黑:该对象已经标记过了,且该对象下的引用也被标记过了。
算法流程
1、初始状态:先把所有对象都标记为白色。
2、遍历根对象:从根对象(GC Root)开始遍历,遍历对象时,将其标为灰色并放在专门的灰色集合中。
3、遍历灰色集合中的对象:从灰色集合中取出对象,并遍历该对象的引用对象,如果引用对象是白色的,把其标记为灰色,并放入灰色集合中;反之,则不做处理。
4、上述3操作遍历完引用对象后的灰色对象会被标记为黑色,并放在专门的黑色集合中。
5、反复进行3的操作直到灰色集合为空,最后仍然为白色的对象就表明其为垃圾。
问题
主要会出现两种问题:漏标和浮动垃圾。
浮动垃圾的问题还能容忍,因为在下一次GC就能够把浮动垃圾给收集了,主要影响的是下一次GC的时间。
但是漏标的问题就很大了,它会导致"对象消失"。
-
发生的条件
-
1、赋值器插入了一条或多条从黑色对象到白色对象的引用。
-
2、赋值器删除了全部从灰色对象到该白色对象的直接或间接引用。
-
漏标的手绘图




这样白色对象就会成为消失的对象。
解决漏标问题
有两种解决方案:增量更新和原始快照。
增量更新
主要破坏的是:赋值器插入了一条或多条从黑色对象到白色对象的引用。
实现思路:当黑色对象引用一个白色对象时,需要记录该黑色对象,等并发扫描结束后,再以他为根去重新扫描一次。
原始快照
主要破坏的是:赋值器删除了全部从灰色对象到该白色对象的直接或间接引用。
实现思路:当灰色都想要删除白色对象的引用关系时,就要将这个白色对象记录下来。并发扫描结束后,会将记录下来的白色对象标记为灰色,然后以他们为根,重新扫描一次。
两者比较
两者相比:原始快照用产生浮动垃圾的可能性,减少了需要重新扫描的时间。(空间换时间)
垃圾收集算法
上述我们已经成功把垃圾给标出来了,那么我们应该重点去思考我们应该怎样优雅的收集垃圾。
分代收集理论
这个理论是基于三个重要的假说上的:
1、弱分代假说:绝大多数的对象都是朝生夕死的。
2、强分代假说:熬过多次越多次垃圾收集的对象越难以消亡。
3、跨代引用假说:跨代引用的对象相对于同代引用来说仅占少数。
基于上述三个假说,我们把堆分成两个区域:年轻代(Eden、Survivor1区、Survivor2区)、老年代。
记忆集(卡表)
为了解决对象跨代引用所带来的问题,垃圾回收器在新生代中建立了名为记忆集的数据结构,用以避免把整个老年代加进GC Root扫描范围。
记忆集(卡表):只需要记录非收集区域是否存在有指向收集区域的指针即可。
卡表
卡表是记忆集的一种实现形式。
标记-清除算法
第一个算法闪亮登场,不过这哥们被用得比较少。
思想
它的做法是当堆中的有效内存空间(available memory)被耗尽的时候,就会停止整个程序(也被成为stop the world),然后进行两项工作,第一项则是标记,第二项则是清除。
标记:标记的过程其实就是,遍历所有的GC Roots,然后将所有GC Roots可达的对象标记为存活的对象。
清除:清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
标记/清除算法,就是当程序运行期间,若可以使用的内存被耗尽的时候,GC线程就会被触发并将程序暂停,随后将依旧存活的对象标记一遍,最终再将堆中所有没被标记的对象全部清除掉,接下来便让程序恢复运行。
实例流程

这张图代表的是程序运行期间所有对象的状态,它们的标志位全部是0(也就是未标记,以下默认0就是未标记,1为已标记),假设这会儿有效内存空间耗尽了,JVM将会停止应用程序的运行并开启GC线程,然后开始进行标记工作,按照根搜索算法,标记完以后,对象的状态如下图。
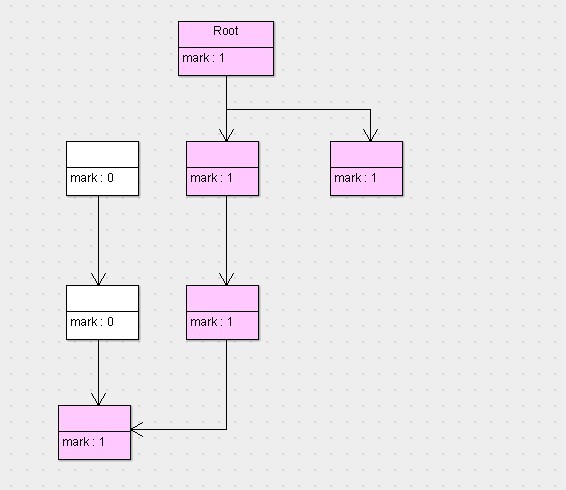
可以看到,按照根搜索算法,所有从root对象可达的对象就被标记为了存活的对象,此时已经完成了第一阶段标记。接下来,就要执行第二阶段清除了,那么清除完以后,剩下的对象以及对象的状态如下图所示。
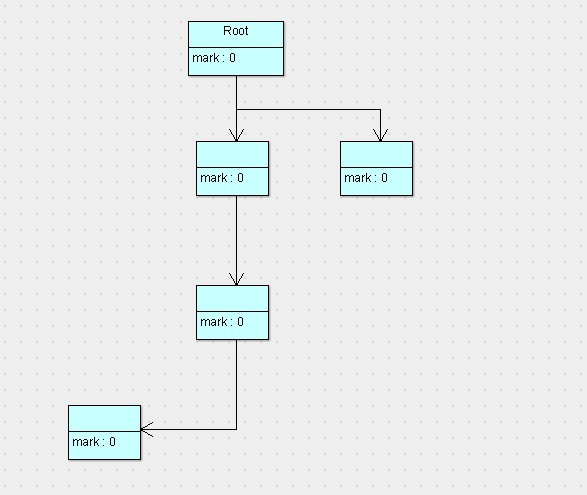
可以看到,没有被标记的对象将会回收清除掉,而被标记的对象将会留下,并且会将标记位重新归0。接下来就不用说了,唤醒停止的程序线程,让程序继续运行即可。
缺点
1、执行效率不稳定:当Java堆中有大量的对象,且其中大部分是需要被回收的;导致标记和清除两个过程的执行效率都随着对象数量增长而降低。
2、会产生大量不连续的内存碎片。
标记-复制算法(复制算法)
思想
复制算法将内存划分为两个区间,在任意时间点,所有动态分配的对象都只能分配在其中一个区间(称为活动区间),而另外一个区间(称为空闲区间)则是空闲的。
当有效内存空间耗尽时,JVM将暂停程序运行,开启复制算法GC线程。接下来GC线程会将活动区间内的存活对象,全部复制到空闲区间,且严格按照内存地址依次排列,与此同时,GC线程将更新存活对象的内存引用地址指向新的内存地址。
此时,空闲区间已经与活动区间交换,而垃圾对象现在已经全部留在了原来的活动区间,也就是现在的空闲区间。事实上,在活动区间转换为空间区间的同时,垃圾对象已经被一次性全部回收。
实例流程

当复制算法的GC线程处理之后,两个区域会变成什么样子,如下所示。

可以看到,1和4号对象被清除了,而2、3、5、6号对象则是规则的排列在刚才的空闲区间,也就是现在的活动区间之内。此时左半部分已经变成了空闲区间,不难想象,在下一次GC之后,左边将会再次变成活动区间。
优点
不会产生内存碎片
缺点
-
浪费了一半的内存
-
复制这一工作所花费的时间,在对象存活率比较高时,将会变的不可忽视
标记-整理算法
标记-清除算法与标记-整理算法的本质差异在于前者是一种非移动式的回收算法,后者是移动式的。
标记-整理算法通常使用在老年代:因为标记-清除算法会产生内存碎片(只有CMS用了标记-清除),复制算法需要损耗一般的空间且老年代的存活对象一般比较多,需要频繁进行复制,效率不高。而比较合适的就是标记整理算法了。
思想
标记:它的第一个阶段与标记/清除算法是一模一样的,均是遍历GC Roots,然后将存活的对象标记。
整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段。
它GC前后的图示与复制算法的图非常相似,只不过没有了活动区间和空闲区间的区别,而过程又与标记/清除算法非常相似
实例流程

这张图其实与标记/清楚算法一模一样,只是LZ为了方便表示内存规则的连续排列,加了一个矩形表示内存区域。倘若此时GC线程开始工作,那么紧接着开始的就是标记阶段了。此阶段与标记/清除算法的标记阶段是一样一样的,我们看标记阶段过后对象的状态,如下图。

没什么可解释的,接下来,便应该是整理阶段了。我们来看当整理阶段处理完以后,内存的布局是如何的,如下图。

可以看到,标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,当我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销。
不难看出,标记/整理算法不仅可以弥补标记/清除算法当中,内存区域分散的缺点,也消除了复制算法当中,内存减半的高额代价。
不过任何算法都会有其缺点,标记/整理算法唯一的缺点就是效率也不高,不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记/整理算法要低于复制算法。
优点
-
消除了标记-清除算法中内存区域分散的缺点
-
消除了复制算法中内存减半的代价
缺点
-
执行效率低于复制算法
-
需要整理所有对象的引用地址
-
对象移动操作必须STW。