 本文章为Hadoop与Spark环境配置及Hadoop环境下使用mapreduce进行wordcount、Spark环境下使用KMeans进行鸢尾花数据集聚类实例运行实验记录。
本文章为Hadoop与Spark环境配置及Hadoop环境下使用mapreduce进行wordcount、Spark环境下使用KMeans进行鸢尾花数据集聚类实例运行实验记录。一、参考资料重要说明
- 本文章为大数据分析课程实验之Hadoop与Spark平台配置记录及示例演示,其中Hadoop配置部分绝大多数内容源自参考资料:华为云:Hadoop安装教程(单机/伪分布式配置)、CSDN:Hadoop安装教程(单机/伪分布式配置)(两文章内容相同且均为同一作者:@华东设计之美);Spark配置部分绝大多数内容源自参考资料:厦门大学数据库实验室:Spark2.1.0入门:Spark的安装和使用;
- 顺序按照上述参考资料文章可顺利完成环境配置,参考资料文章内容逻辑清晰,如果有环境配置需求,强烈推荐大家前往学习!
- 本文章内容均进行过复现,若跟随本文章配置过程中产生错误,请具体问题具体分析,也欢迎咨询本文作者。
二、安装虚拟机与设置管理员
- 我们使用VMware新建Ubuntu虚拟机。
- 注意!!创建的用户名称为“hadoop”
- 如果忘记创建hadoop管理员,可通过如下命令添加管理员
sudo useradd -m hadoop -s /bin/bash #创建一个新用户,这条命令创建了名为“hadoop”的用户,并使用 /bin/bash 作为 shell。
sudo passwd hadoop # 接着使用该命令设置密码,按提示输入两次密码。
sudo adduser hadoop sudo # 为 hadoop 用户增加管理员权限,方便部署。
- 最后注销当前用户,返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
三、可设置VMware共享文件夹用于实现主机与虚拟机间的文件传输
- 虚拟机 -> 设置 -> 选项 -> 共享文件夹,选择“总是启动”,然后再添加一个和主机windows共享的路径。
- 设置完毕后,点击确定再次回到ubuntu,共享文件夹在ubuntu中的路径是:
/mnt/hgfs/winshare(注意:我们要想进入mnt文件夹,必须确保当前用户有管理员权限)
四、安装SSH、配置SSH无密码登陆
- SSH全称secure shell安全外壳协议(安全的shell),这是一个计算机网络协议(默认端口号为22)。通过ssh协议可以在客户端安全(提供身份认证、信息加密)的远程连接Linux服务器或其他设备。我们在使用Hadoop时,集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server。
sudo apt-get install openssh-server
ssh localhost # 安装后,可以使用该命令登陆本机:
- 此时会有如下提示(SSH首次登陆提示),输入yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

- 但这样使用SSH登陆是需要每次输入密码的,因此为了方便,我们需要配置成SSH无密码登陆。
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 利用 ssh-keygen 生成密钥,并将密钥加入到授权中,该过程中会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 此命令为“将密钥加入授权”,加入授权后,此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了。
- 经过以上过程,我们便成功完成了“安装SSH、配置SSH无密码登陆”的工作。
五、JAVA的安装与配置
- 从虚拟机中下载或在主机上下载再通过虚拟机的
/mnt/hgfs/winshare访问下载文件均可。 - 把下载下来的jdk压缩包复制到“/home/hadoop/Downloads/”目录下,然后在桌面打开终端并执行以下命令:
cd /usr/lib #进入/usr/lib目录
sudo mkdir jvm #在/usr/lib目录下创建jvm文件夹
cd /home/hadoop/Downloads/ # 进入jdk压缩包所在目录
sudo tar -zxvf ./jdk-8u202-linux-x64.tar.gz -C /usr/lib/jvm #注意:jdk-8u202-linux-x64.tar.gz为下载的jdk压缩文件名,您的下载安装包可能与我的示例有所不同
# 该命令将下载的jdk压缩文件解压至/usr/lib/jvm目录下
- 接下来配置JAVA的环境变量
cd ~ #进入主目录
vim ~/.bashrc #使用vim编辑器打开环境变量设置
- 如果显示如下图所示信息,表明需要安装vim,因此可使用
sudo apt install vim下载vim编辑器。
- 下载完成后重新运行
vim ~/.bashrc。 - 在文件开头添加如下内容(注意,如果对vim不熟悉,建议先找资源查看vim编辑器的简易使用教程,如“如何进入vim、如何开始输入、如何保存输入、如何显示行号等”)
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_202 #一定要注意“=”的两边不要习惯性加上空格,这样会报错的@~@
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
- 保存并退出vim,首先输入
source ~/.bashrc使bashrc的配置立即生效,接着输入java -version,若输出java版本信息,则配置成功,反之,具体问题具体分析~
六、Hadoop3.3.6的下载和安装
- 下载和上传步骤同jdk压缩文件。
- 我们目标将Hadoop安装在/usr/local中,先将Hadoop压缩包下载至/home/hadoop/Downloads/中或将共享文件夹中的压缩包复制到/home/hadoop/Downloads/中,然后在/home/hadoop/Downloads/目录下执行下面的命令:
sudo tar -zxf ~/Doenloads/hadoop-3.3.6.tar.gz -C /usr/local #解压到/usr/local
cd /usr/local
sudo mv ./hadoop-3.3.6/ ./hadoop #将文件夹名称改为hadoop
sudo chown -R 当前登录用户的名字 ./hadoop #修改文件权限cd /usr/local/hadoop
./bin/hadoop version #检查hadoop是否成功安装
七、Hadoop3单机配置(非分布式)
- Hadoop默认模式为非分布式模式(本地模式),即无需进行其他配置便可直接运行,非分布式模式即单Java进程,方便进行hadoop调试。接下来我们运行一个grep文本搜索工具的例子。
- grep缩写来自Globally search a Regular Expression and Print,是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本。
- 我们将创建一个 input 文件夹,并计划将文件夹内的所有文件作为grep工具的输入,筛选文件当中符合正则表达式
dfs[a-z.]+的单词并统计出现的次数,最后输出结果到创建的 output 文件夹中。注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要使用rm -r ./output先将 ./output 删除。
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为grep输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+' #进行文本搜索
cat ./output/* # 查看运行结果即可看到符合正则表达式“dfs[a-z.]+”的单词dfsadmin出现了1次。
八、Hadoop伪分布式配置
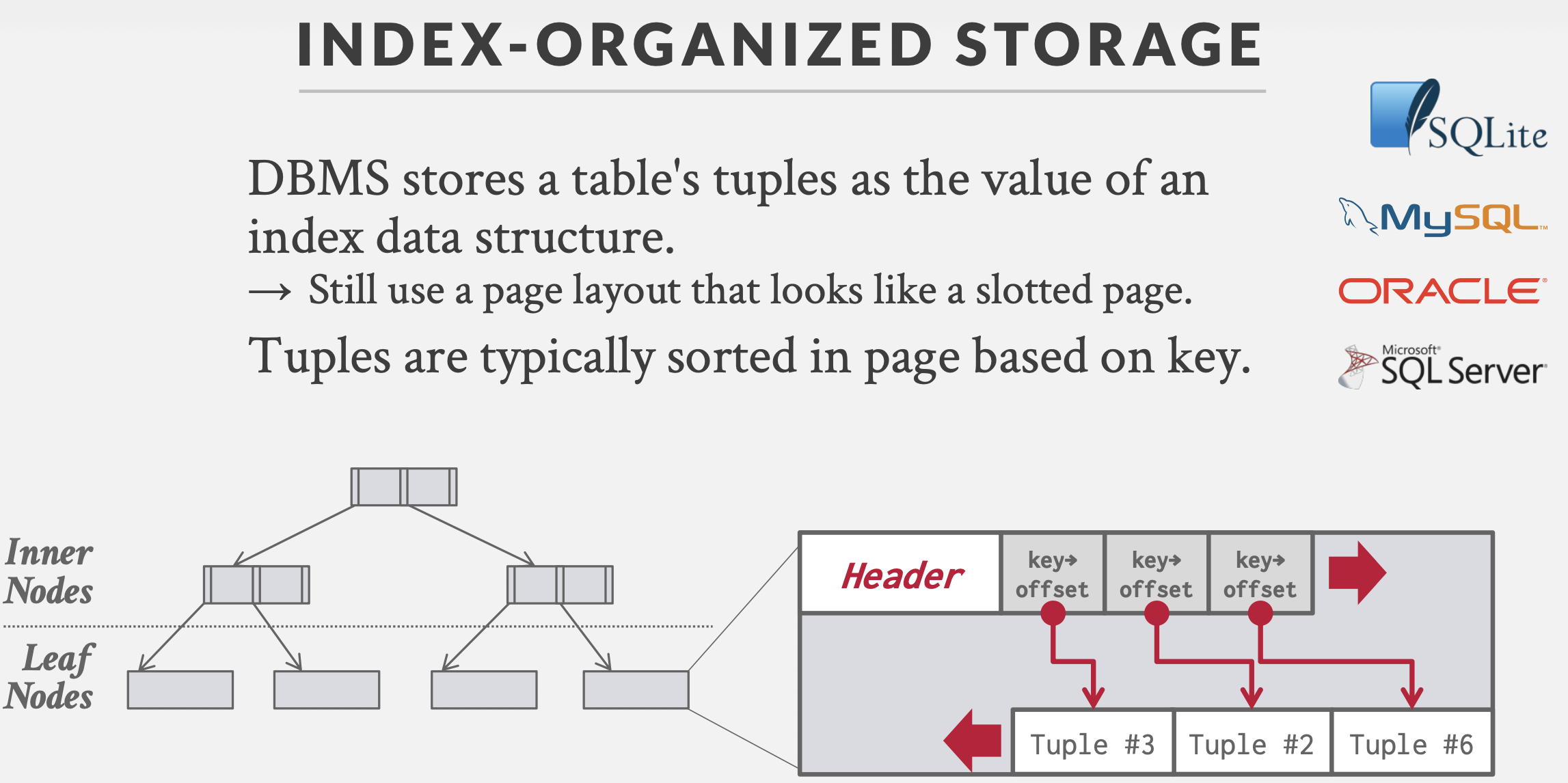
- HDFS的整体架构如下图所示:其中NameNode类似于GFS的主控服务器, DataNode类似于GFS的Chunk服务器;Secondary NameNode是个提供检查点功能服务的服务器。
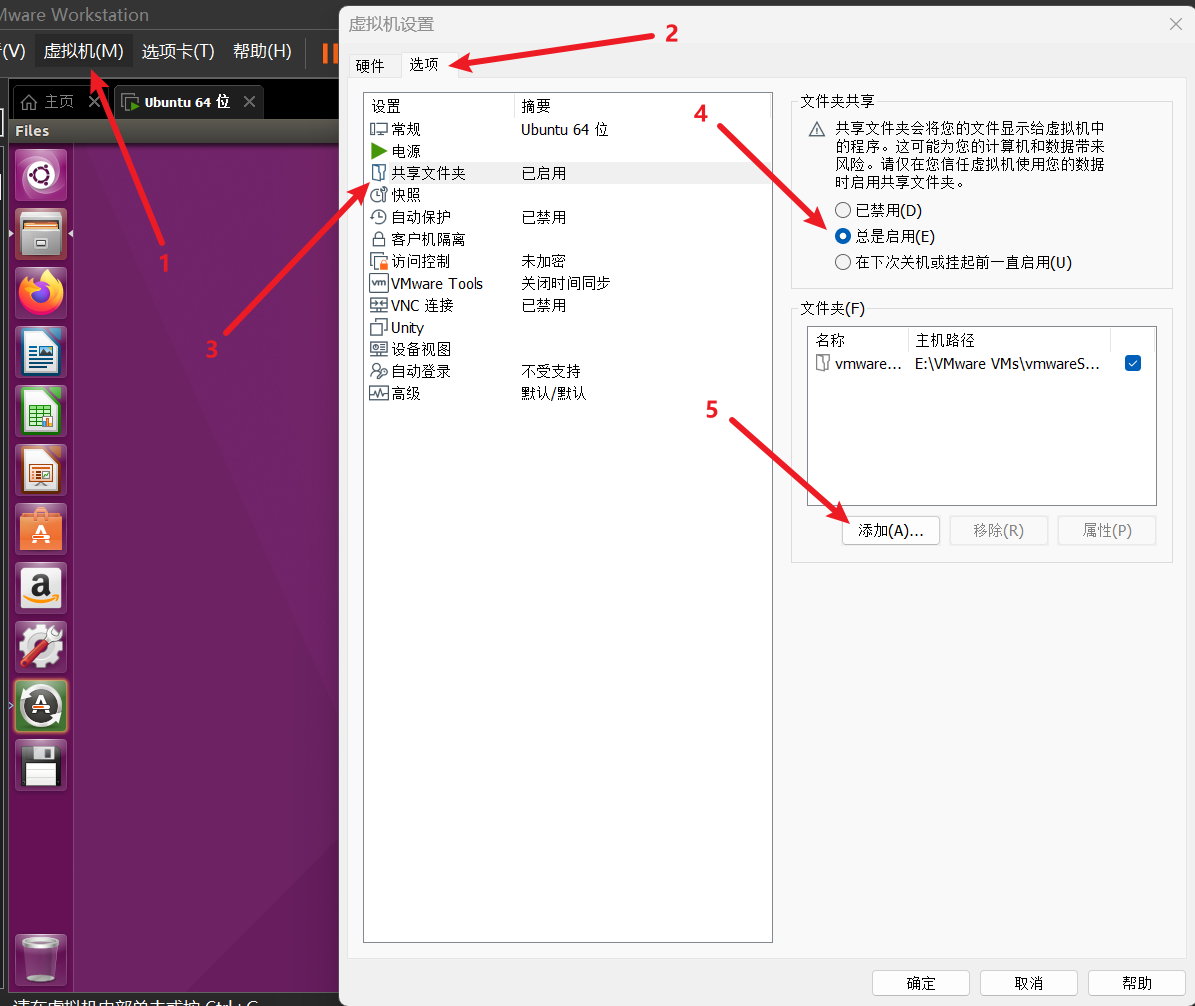
- Hadoop可以在单节点上以伪分布式的方式运行,Hadoop进程以分离的Java进程来运行,节点既作为NameNode也作为DataNode,同时,读取的是HDFS中的文件。
- Hadoop的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是xml格式,每个配置以声明property的name和value的方式来实现。
- 使用命令
gedit ./etc/hadoop/core-site.xml修改配置文件core-site.xml (通过 gedit 编辑会比较方便(gedit可直接打开一个编辑器窗口,vim则是在terminal中进入vim编辑器))
- 使用命令
# Hadoop配置文件说明
**Hadoop的运行方式是由配置文件决定的(运行Hadoop时会读取配置文件),**
因此,如果需要从伪分布式模式切换回非分布式模式,需要删除core-site.xml文件中的配置项。
此外,伪分布式虽然只需要配置fs.defaultFS和dfs.replication就可以运行(**官方教程如此**),
不过若没有配置hadoop.tmp.dir参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,
导致必须重新执行format才行。
所以我们进行了设置,同时也指定dfs.namenode.name.dir和dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
*/
<configuration> #core-site.xml文件待修改状态
</configuration>
<configuration> #core-site.xml文件修改后状态<property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>
# 同样的,使用命令`gedit ./etc/hadoop/hdfs-site.xml`修改配置文件hdfs-site.xml,下面为该文件修改后状态
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property>
</configuration>
# 配置完成后,退出编辑器执行NameNode的格式化
cd /usr/local/hadoop
./bin/hdfs namenode -format
# 接着开启 NameNode 和 DataNode 守护进程。
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
- 启动完成后,运行
jps命令判断是否成功启动,若成功启动则会列出进程,如果SecondaryNameNode没有启动,可运行sbin/stop-dfs.sh关闭进程,接着再次尝试启动。如果没有NameNode或者DataNode,说明配置不成功,通过检查之前步骤进行查错。 - 成功启动后,可以访问Web界面 http://localhost:9870查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
- 注意,localhost端口50070是Hadoop2版本的端口
- 本实验使用的Hadoop版本为Hadoop3.3.6,因此localhost端口为9870,具体可查看Hadoop官方网站
九、运行Hadoop伪分布式实例
- 上面的单机模式使用grep工具的例子读取的是本地数据,伪分布式读取的则是HDFS上的数据。要使用HDFS,首先需要在HDFS中使用命令
./bin/hdfs dfs -mkdir -p /user/hadoop创建hadoop用户的目录。 - 接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的/user/hadoop/input中。使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input。
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input # 使用的是相对路径input
- 复制完成后,可以通过命令
./bin/hdfs dfs -ls input查看文件列表。 - 伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地input 文件夹,输出结果 output 文件夹都删掉来验证这一点)。
# 运行Mapreduce的wordcount功能
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'./bin/hdfs dfs -cat output/* # 查看运行结果的命令(查看的是位于 HDFS 中的输出结果)
- 运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录(如 output)不能存在,否则会提示错误,因此运行前需要先删除input目录。
- 若要关闭 Hadoop,则运行
./sbin/stop-dfs.sh。 - 下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行
./sbin/start-dfs.sh即可。
十、Hadoop安装过程中的错误处理
- Warning: Permanently added 'ubuntu' (ECDSA) to the list of known hosts.
- 使用命令
sbin/stop-dfs.sh关闭进程 - 再次运行
./sbin/start-dfs.sh启动
- 使用命令
- 无法访问http://localhost:50070
- 本教程使用的hadoop版本是3.3.6,Hadoop默认端口从3.0开始改成了9870,修改后即可访问。
十一、Spark环境配置
- 访问官网http://spark.apache.org/downloads.html,下载Spark2。由于我们已经自己安装了Hadoop,所以,在“Choose a package type”后面需要选择“Pre-build with user-provided Hadoop”,然后,点击“Download Spark”后面的“spark-2.1.0-bin-without-hadoop.tgz”下载即可。下载的文件,默认会被浏览器保存在“/home/hadoop/下载”目录下。需要说明的是,Pre-build with user-provided Hadoop: 属于“Hadoop free”版,这样,下载到的Spark,可应用到任意Hadoop 版本。
- Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器)。这里介绍Local模式(单机模式)的 Spark安装。我们选择Spark 3.5.3版本,并且假设当前使用用户名hadoop登录了Linux操作系统。进入/home/hadoop/Downloads目录,使用如下命令对Spark安装包进行解压,指定安装路径为/usr/local/。
sudo tar -zxf spark-3.5.3-bin-without-hadoop.tgz -C /usr/local/ # 将压缩包解压至/usr/local/目录下
cd /usr/local
sudo mv ./spark-2.1.0-bin-without-hadoop/ ./spark #修改解压后的文件夹名称
sudo chown -R hadoop:hadoop ./spark # 修改文件权限,此处的hadoop为当前用户名
- 安装后,还需要修改Spark的配置文件spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh # 对配置文件做一个临时备份
vim ./conf/spark-env.sh # 编辑spark-env.sh文件
- vim编辑界面中,在第一行添加以下配置信息
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) # 注意,是圆括号而不是花括号
- 有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。配置完成后就可以直接使用,不需要像Hadoop运行启动命令。通过运行Spark自带的示例,验证Spark是否安装成功。
cd /usr/local/spark
bin/run-example SparkPi # 在本安装实验中,运行该命令后直接输出了π的5位小数近似值,具体原因有待分析
- 如果执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
bin/run-example SparkPi 2>&1 | grep "Pi is" # 过滤后的运行结果可以得到π的5位小数近似值
十二、在 Spark Shell 中运行代码
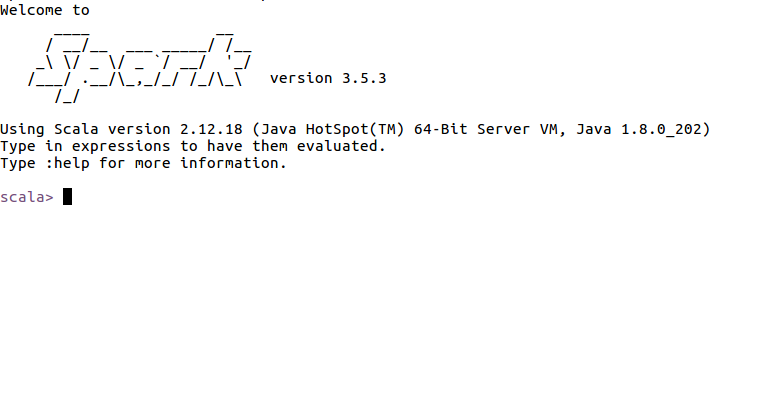
- 使用
bin/spark-shell进入Spark Shell,该命令省略了参数,这时系统默认是“bin/spark-shell --master local[*]”,也就是说,是采用本地模式运行,并且使用本地所有的CPU核心。启动spark-shell后,就会进入“scala>”命令提示符状态。若想退出命令行模式,可以直接使用“Ctrl+D”组合键,退出Spark Shell。 - Scala简要介绍
- Scala 是 Scalable Language 的简写,意味着这种语言设计上支持大规模软件开发,是一门多范式的编程语言,Scala 与 Java 语言类似,两者最大的区别是:Scala 语句末尾的分号“;”是可选的。
- Scala可以使用交互式编程(类似Python命令行),也可以使用脚本形式,即使用scalac命令编译scale文件并使用Scala执行。
十三、Spark+Mllib的机器学习demo(使用Scala)
- 在/usr/local/spark目录下使用命令
bin/spark-shell运行Scala,在交互式命令行中输入程序 - 导入spark的机器学习库Mllib
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
- 假定测试数据放在hadoop用户的桌面上,文件名为iris.txt,开始读取iris.txt鸢尾花数据集,使用textFile读取文件并形成RDD。从本地读取文件的URL格式为“file:// + 文件位置 ”,如果不加 “file://” 则默认从hdfs中读取
- RDD:弹性分布式数据集(resilient distributed dataset)是Spark的核心数据模型,RDD是Spark中待处理的数据的抽象,它是逻辑中的实体

- RDD:弹性分布式数据集(resilient distributed dataset)是Spark的核心数据模型,RDD是Spark中待处理的数据的抽象,它是逻辑中的实体
- 因为K-means属于无监督学习,所以我们在此处去掉标签数据来测试模型,因此首先对原始数据进行处理,通过filter算子过滤掉源文件中的分类结果;其中正则表达式\ \d(\ \ .?)\ \d 可以用于匹配实数类型的数字,\ \d* 使用了“ * ”限定符,表示匹配 0 次或多次的数字字符,\ \ .?使用了?限定符,表示匹配0次或1次的小数点

- 查看原始数据和去除标签之后的数据

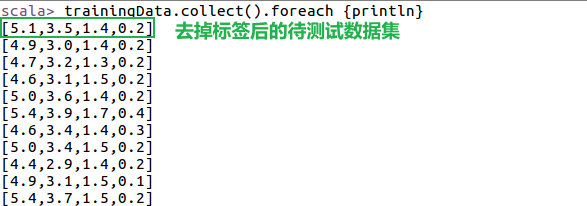
- 设定KMeans算法的超参数并开始测试KMeans算法模型,此处设定聚类结果中类的个数为2,迭代次数为5,输入到KMeans的train方法中进行训练,模型参数保存在model中。

- 查看测试完成后的模型中每个群簇的群簇中心

- 接下来对数据集中每一个数据分类
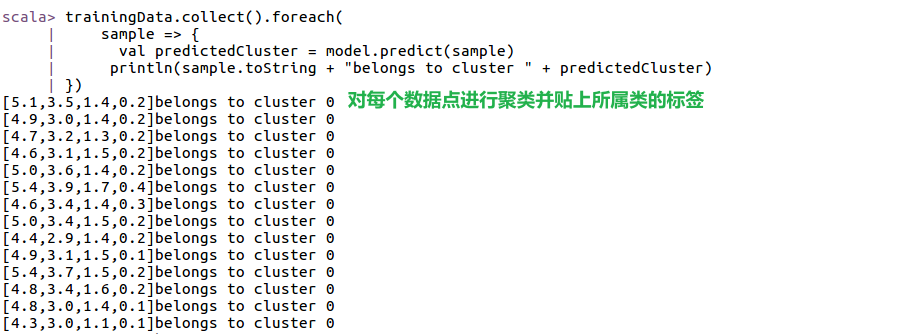
- 对新输入的点进行分类,可使用Vector.dense创建新的向量,输入到模型的predict方法中进行分类

十四、参考资料
- CSDN:windows主机和ubuntu互传文件的4种方法
- CSDN:Ubuntu 报错:无法获得锁 /var/lib/dpkg/lock解决办法
- 华为云:Hadoop安装教程(单机/伪分布式配置)
- CSDN:ssh详解–让你彻底学会ssh
- 在Ubuntu系统中安装hadoop无法打开localhost:50070
- 厦门大学数据库实验室:Spark2.1.0入门:Spark的安装和使用
- 基于Spark MLib的鸢尾花数据聚类项目实战案例