数据缩放(Data Scaling)是数据预处理的一种重要方法,用于将不同取值范围的特征值调整到统一的范围,从而提高机器学习模型的性能和稳定性。本文将总结常见的数据缩放方法,并分析它们的优缺点及适用场景。
1. 均值归一化(Mean Normalization):将数据缩放到[-1,1]的范围内,使数据的均值为0。具体计算方法为:$x_{scaled} = \frac{x - \text{mean}(x)}{\text{max}(x) - \text{min}(x)}$。即:
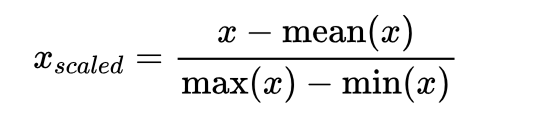
均值归一化除了将数据缩放到一个固定范围内,还能保持数据的分布形态。
2. 方差归一化(Standardization):通过将数据缩放到均值为0,方差为1的范围内,消除不同特征之间的量纲问题。具体计算方法为:$x_{scaled} = \frac{x - \text{mean}(x)}{\text{std}(x)}$。
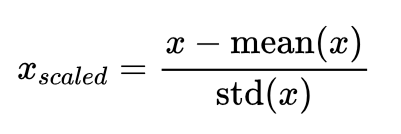
方差归一化将所有特征值分布在均值附近,使得数据具有相似的尺度。
3. 最大最小归一化(Min-Max Scaling):将数据缩放到[0,1]的范围内。具体计算方法为:$x_{scaled} = \frac{x - \text{min}(x)}{\text{max}(x) - \text{min}(x)}$。
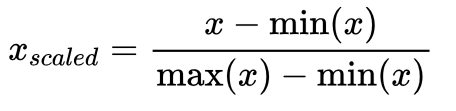
最大最小归一化保留了原始数据的分布形态和相对关系。
4. 归一化(Normalization):将每个样本的特征向量缩放到单位范数(长度为1)。具体计算方法为:$x_{scaled} = \frac{x}{\,x\,_2}$。归一化使得样本的特征向量具有统一的长度,可以消除不同特征之间的重要性差异。
5. 对数变换(Log Transformation):通过对数据取对数,使得数据具有更均匀的分布。对数变换适用于数据具有指数增长或衰减的情况,可以使得数据更符合线性模型的要求。
6. 幂变换(Power Transformation):通过对数据进行幂次变换,改变数据的分布形态。常用的幂次变换包括平方根、立方根、平方和倒数等。
7. 区间缩放(Interval Scaling):将数据缩放到指定的区间内。具体计算方法为:$x_{scaled} = a + \frac{(x - \min(x))(b - a)}{\max(x) - \min(x)}$,其中$a$和$b$为目标区间的上下限。
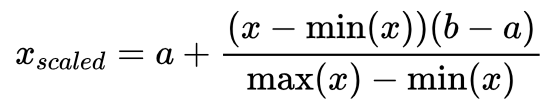
区间缩放是一种非线性变换方法,可以将数据分布到指定的区间范围内。