学期2024-2025- 学号20241317 《计算机基础与程序设计》第七周学习总结
作业信息
| 这个作业属于哪个课程 | <班级的链接>(如2024-2025-1-计算机基础与程序设计) |
|---|---|
| 这个作业要求在哪里 | <作业要求的链接>(如2024-2025-1计算机基础与程序设计第一周作业) |
| 这个作业的目标 | <写上具体方面> |
| 作业正文 | https://www.cnblogs.com/manurios/p/18537875 |
教材学习内容总结
《计算机科学概论》第 7 版第六章主要内容如下:
1. 低级程序设计语言:
- 机器语言:计算机硬件能够直接理解和执行的语言,由一系列二进制代码组成。每条机器语言指令只能执行一个非常低级的任务,直接与硬件交互,这是最底层的语言。其编写和理解对人类来说非常困难且容易出错,但对计算机硬件的控制最为直接。
- 汇编语言:是对机器语言的改进,用助记符表示机器指令,比机器语言更易于编写和理解。不过,它仍然与硬件紧密相关,需要通过汇编器将其转换为机器语言才能被计算机执行。
- pep/9 虚拟机:是一种为模拟真实机器的重要特征而设计的假想机器。其内存单元由 65536 字节的存储空间构成,机器指令一共 8 位,前四位是操作码,后四位是地址码。
2. 汇编语言的组成部分: - 指令集:是 CPU 支持的所有指令的集合。
- 寄存器:用于存储数据和地址的小型存储区域,CPU 中的算术逻辑单元可直接对寄存器中的数据进行操作,能加快数据的处理速度。
- 寻址模式:确定操作数位置的方法,如直接寻址(操作数的地址直接包含在指令中)、间接寻址(指令中的地址是操作数地址的存储位置)等。
- 指令格式:操作码和操作数的组合方式,不同的计算机体系结构和指令集有不同的指令格式要求。
3. 汇编语言编程: - 编写汇编程序:涉及数据定义、指令编写以及控制结构的使用等方面。例如定义数据的存储类型和初始值,使用各种指令对数据进行操作,以及通过条件判断、循环等控制结构实现程序的逻辑流程。
- 汇编和链接过程:汇编过程是将汇编语言程序转换为机器语言的过程,由汇编器完成。链接过程则是将多个目标文件(包括汇编生成的目标文件和其他库文件)组合成一个可执行程序的过程。
4. 伪代码: - 定义:一种非正式的、介于自然语言和编程语言之间的语言,用于描述算法而不依赖于特定编程语言的语法。
- 用途:可在编程之前用于规划算法,作为程序的文档,方便其他程序员理解程序的逻辑和功能,也可作为教学工具,帮助初学者理解算法的设计思路。
5. 从伪代码到编程语言: - 转换过程:将伪代码转换为特定编程语言的代码时,需要根据编程语言的语法规则和特性对伪代码进行翻译和细化。例如,将伪代码中的条件判断、循环等控制结构转换为编程语言中的相应语句。
- 代码优化:在转换过程中,可以根据程序的性能需求和编程语言的特点进行优化,如提高代码的执行效率、增强代码的可读性等。
6. 低级语言与高级语言的比较: - 抽象级别:低级语言接近计算机硬件,抽象级别低,程序员需要对硬件细节有较多了解;高级语言抽象级别高,更贴近人类的思维方式,程序员可以更关注问题的逻辑解决,而不必过多关注硬件实现。
- 性能:低级语言由于直接操作硬件,在性能上可能更有优势,特别是对于一些对性能要求极高的应用场景,如嵌入式系统、实时控制系统等。但高级语言在开发效率和代码的可维护性方面更胜一筹。
- 可读性和可维护性:高级语言的语法更接近自然语言,代码的可读性和可维护性更好,便于程序员之间的交流和代码的后期维护。低级语言的代码相对较为晦涩难懂,维护难度较大。
7. 实际应用: - 嵌入式系统:在嵌入式系统中,由于对硬件的控制要求较高,且系统资源有限,低级语言和伪代码常用于编写底层的驱动程序和控制系统程序,以实现对硬件的精确控制。
- 性能关键型应用:在一些对性能要求非常严格的应用场景,如游戏开发、高性能计算等,低级语言可以帮助程序员实现对硬件的精细控制,提高程序的性能。
教材学习中的问题和解决过程(先问 AI)
(一个模板:我看了这一段文字 (引用文字),有这个问题 (提出问题)。 我查了资料,有这些说法(引用说法),根据我的实践,我得到这些经验(描述自己的经验)。 但是我还是不太懂,我的困惑是(说明困惑)。【或者】我反对作者的观点(提出作者的观点,自己的观点,以及理由)。 )
- 问题1:汇编语言为何与硬件交互
- 问题1解决方案:
1. 贴近硬件底层:汇编语言是一种低级程序设计语言,相比高级语言,它更接近计算机硬件的底层操作。它的指令直接对应着计算机硬件能执行的基本操作,如数据的传送、算术运算、逻辑运算等,这些操作是通过对硬件中的寄存器、内存单元等进行具体的读写和控制来实现的。
2. 寄存器操作:汇编语言可以直接对CPU中的寄存器进行操作。寄存器是CPU内部用于暂存数据和指令的高速存储单元,不同的寄存器有不同的用途,比如存放操作数、运算结果、指令地址等。通过汇编指令能精确地设置寄存器的值,从而控制硬件完成相应任务,实现与硬件的紧密交互。
3. 寻址模式:汇编语言具备多种寻址模式,像直接寻址、间接寻址等。这些寻址模式能准确地定位数据在内存中的存储位置,使得可以按照硬件的存储架构去访问和处理数据,进而实现与硬件存储系统等的交互。
4. 指令集对应硬件功能:汇编语言基于特定计算机的指令集,而指令集是该计算机硬件所能执行的所有操作的集合。每条汇编指令都对应着指令集中的一个具体操作,这些操作是为了驱动硬件完成诸如输入输出、数据处理等各项功能而设计的,所以能通过编写汇编指令来让硬件执行相应动作,达成与硬件的交互。
- 问题2:链接过程具体是什么
- 问题2解决方案:
- 目标文件生成
首先,经过汇编等步骤会生成目标文件(.obj文件等,不同系统可能有不同后缀)。这些目标文件包含了汇编语言程序转换而来的机器语言代码,但它们还不能直接运行,因为可能存在对外部符号(比如其他模块中的函数、变量等)的引用等情况。
- 链接器工作原理
接着由链接器来处理这些目标文件,其主要任务是将多个目标文件以及可能需要的库文件组合成一个完整的可执行程序。
- 符号解析
在链接过程中,链接器会进行符号解析。它要确定各个目标文件中引用的外部符号(如函数名、变量名等)的实际地址。比如一个目标文件中调用了另一个目标文件里定义的函数,链接器就要找到那个函数在其所在目标文件中的具体位置(也就是地址),以便在程序运行时能正确跳转过去执行该函数。
- 地址重定位
当把多个目标文件整合到一起时,每个目标文件原本内部的相对地址可能会发生变化。链接器要对这些地址进行重定位操作,确保程序中的指令和数据在最终的可执行程序里能有正确的绝对地址,使得程序在运行时能按照正确的地址去访问指令和数据。
- 库文件处理
如果程序还依赖一些库文件(如标准库等),链接器也会把相关的库文件内容整合进来。库文件里包含了很多常用的函数、数据结构等资源,通过链接将其融入可执行程序,让程序可以使用这些库中的功能。
- 生成可执行程序
经过上述一系列的符号解析、地址重定位以及库文件整合等操作后,链接器最终生成一个完整的可执行程序,这个程序就可以在相应的计算机系统上运行了。
- ...
基于AI的学习
问题1:库文件有哪些
解答:库文件种类繁多,常见的有以下几类:
标准库文件
- C标准库:如stdio.h(用于输入输出操作,像printf、scanf函数就在此库中定义)、stdlib.h(包含内存分配、随机数生成等函数)、string.h(提供字符串处理函数)等。几乎所有C语言程序都会用到这些标准库来完成基本的功能操作。
- C++标准库:除了兼容C标准库部分功能外,还有像iostream(用于输入输出流操作,可替代C的stdio.h实现更方便的输入输出)、vector(动态数组容器)、string(对字符串进行更高级处理)等,为C++程序开发提供丰富功能。
数学库文件
- 例如在很多编程语言中都有的math库,用于实现各种数学运算功能,像三角函数(sin、cos等)、对数函数(log、ln等)、幂运算函数(pow)等的计算。
图形库文件
- OpenGL:广泛应用于图形处理和游戏开发等领域,可实现二维和三维图形的绘制、渲染,如创建三角形、四边形等几何图形,设置光照效果、材质等。
- DirectX:主要用于Windows平台下的游戏开发和多媒体应用,提供了图形、声音、输入等多方面的功能模块,能实现高质量的图形显示和交互。
数据库连接库文件
- ODBC(Open Database Connectivity):是一种标准的数据库连接接口,通过它可以连接到多种不同类型的数据库,如MySQL、Oracle、SQL Server等,实现数据的查询、插入、更新、删除等操作。
- JDBC(Java Database Connectivity):是Java语言用于连接数据库的标准库,同样可用于连接各类数据库,在Java应用程序开发中,若涉及数据库交互,经常会用到它。
网络库文件
- Socket库:在网络编程中常用,可实现基于TCP/IP协议的网络连接、数据传输等操作。不同编程语言一般都有自己对应的Socket实现,比如Python的socket库,通过它可以创建服务器端和客户端,进行网络通信。
操作系统相关库文件
- 在Windows系统下有Win32 API相关库,包含大量用于实现Windows特色功能的函数,如窗口创建、消息处理、文件管理等。
- 在Linux系统下有glibc库,它是Linux系统中最基本的标准库,提供了很多如内存管理、线程操作、文件系统访问等基本功能函数。
问题2:寻址模式有哪些:
常见的寻址模式有以下几种:
直接寻址
指令中直接包含操作数的真实地址,处理器根据这个地址就能直接从内存中获取操作数。例如在一条指令中明确给出了内存地址1000H,那么执行该指令时就会从内存地址1000H处读取操作数。
间接寻址
指令中给出的是操作数地址的存放地址。也就是说,指令中的地址指向的是另一个内存单元,而真正的操作数存放在这个被指向的内存单元中。比如指令中的地址是2000H,而内存地址2000H处存放的内容是3000H,那么真正的操作数就在3000H这个地址处。
寄存器寻址
操作数存放在CPU的寄存器中,指令通过指定寄存器名来获取操作数。例如在寄存器AX中存放了一个数据,指令通过指明AX就能直接使用该寄存器中的数据进行运算等操作。
寄存器间接寻址
操作数的地址存放在寄存器中,先从寄存器中取出地址,再根据这个地址从内存中获取操作数。比如寄存器BX中存放着内存地址4000H,那么先从BX中取出4000H,再从内存地址4000H处获取操作数。
基址寻址
以基址寄存器(如BX、BP等)的内容为基准,加上一个偏移量来确定操作数的地址。例如基址寄存器BX的值为5000H,偏移量为100H,那么操作数的地址就是5000H + 100H = 5100H,就从这个地址处获取操作数。
变址寻址
通常利用变址寄存器(如SI、DI等)的内容,再加上一个固定的偏移量来确定操作数的地址。例如变址寄存器SI的值为6000H,偏移量为200H,那么操作数的地址就是6000H + 200H = 6200H,进而获取操作数。
相对寻址
常用于程序跳转指令等情况,它是以当前指令的地址(程序计数器PC的值)为基准,加上一个相对偏移量来确定目标指令的地址。比如当前指令地址为7000H,相对偏移量为300H,那么目标指令的地址就是7000H + 300H = 7300H,程序就会跳转到这个地址处的指令继续执行。
三个原则:
- 切勿原封不动地接受生成式人工智能工具的输出;确保对其进行评估、完善和修改(或提示),以适应您的目标。
- 切勿将任何个人数据(自己、同学、老师等)或版权材料纳入到你的提示词中。这个可以说是保护个人隐私的最起码的举措。
- 所有人工智能生成工具都容易产生幻觉,因此会生成不准确或误导性的信息,要学会甄别信息真假
选择至少2个知识点利用chatgpt等工具进行苏格拉底挑战,并提交过程截图,提示过程参考下面内容
“我在学***X知识点,请你以苏格拉底的方式对我进行提问,一次一个问题”
核心是要求GPT:“请你以苏格拉底的方式对我进行提问”
然后GPT就会给你提问,如果不知道问题的答案,可以反问AI:“你的理解(回答)是什么?”
如果你觉得差不多了,可以先问问GPT:“针对我XXX知识点,我理解了吗?”
GPT会给出它的判断,如果你也觉得自己想清楚了,可以最后问GPT:“我的回答结束了,请对我的回答进行评价总结”,让它帮你总结一下。
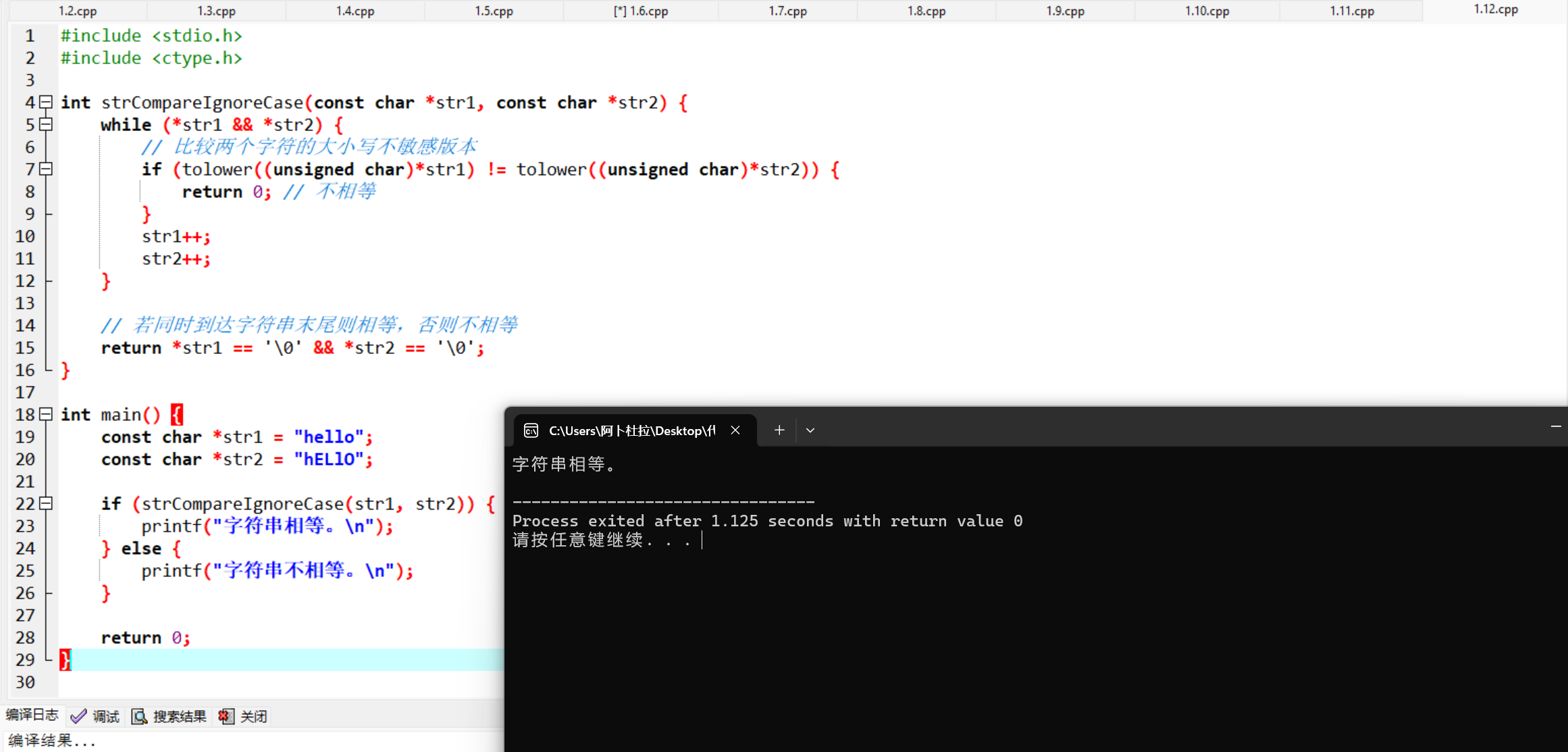
代码调试中的问题和解决过程
- 问题1:XXXXXX
- 问题1解决方案:XXXXXX
- 问题2:XXXXXX
- 问题2解决方案:XXXXXX
- ...
代码托管
(statistics.sh脚本的运行结果截图)
上周考试错题总结
- 错题1及原因,理解情况
- 错题2及原因,理解情况
- ...
其他(感悟、思考等,可选)
xxx
xxx
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
参考:软件工程软件的估计为什么这么难,软件工程 估计方法
-
计划学习时间:XX小时
-
实际学习时间:XX小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)
参考资料
- 《计算机科学概论(第七版)》
- ...