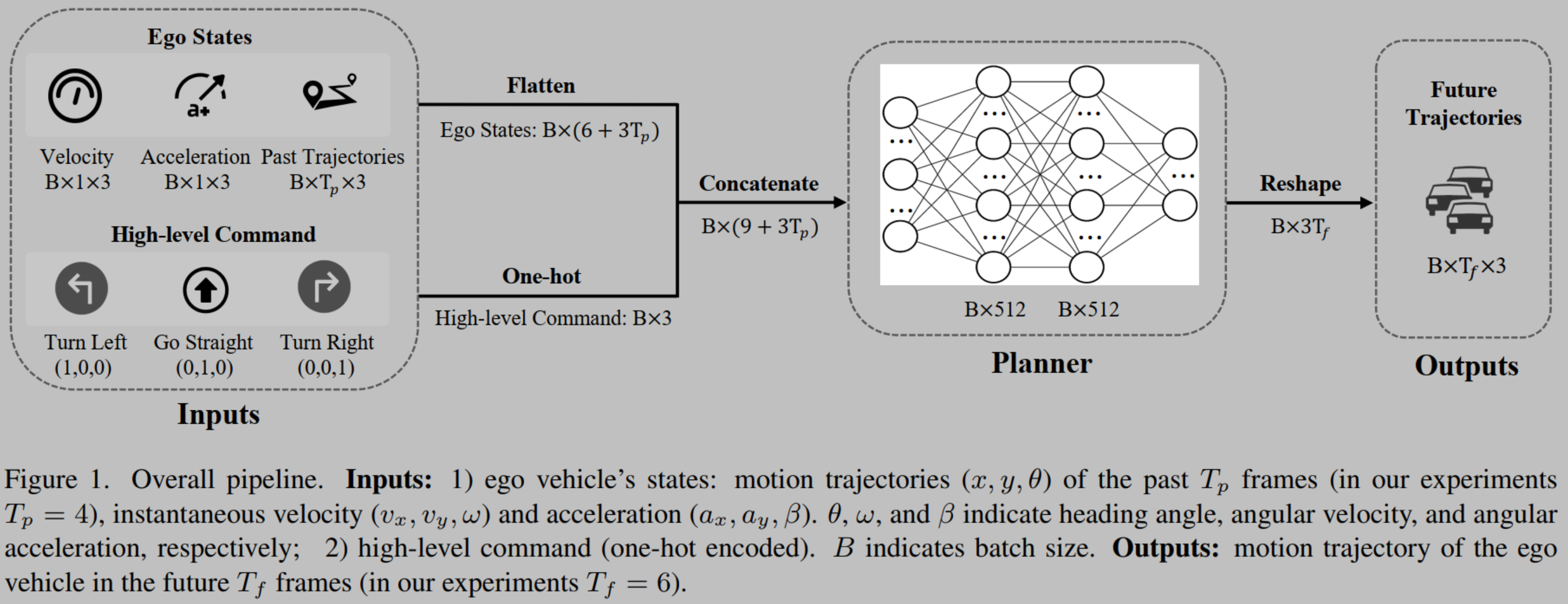
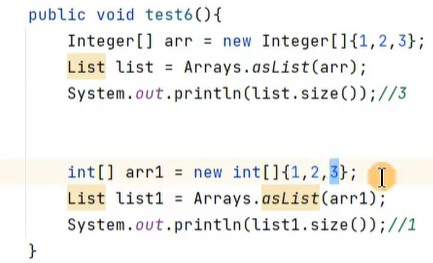
算法的性能测试是一个综合评估算法在不同条件下的表现和效率的过程。在进行算法性能测试时,需要关注多个关键指标,以确保全面、准确地评估算法的性能。以下是对算法性能测试的详细解释和需要关注的指标的归纳:
一、算法性能测试概述
算法性能测试的目的是验证算法在各种输入情况下的正确性、性能、稳定性等。通过性能测试,可以了解算法在不同数据集、不同计算环境下的表现,从而为其在实际应用中的选择和优化提供依据。
二、需要关注的指标
- 准确性(Accuracy):
- 准确性是指算法正确预测的比例,是评估分类或回归任务中最常用的指标之一。
- 在性能测试中,需要计算算法在不同数据集上的准确率,以评估其预测性能。
- 召回率(Recall):
- 召回率是指算法正确识别正类的能力,用于评估算法对正类别的识别能力。
- 在某些应用场景中,如医疗诊断领域,召回率可能比精确度更为重要。
- 精确度(Precision):
- 精确度是指算法正确预测正类的比例,与召回率密切相关。
- 精确度越高,表示算法预测为正类的样本中实际为正类的比例越高。
- F1分数(F1 Score):
- F1分数是精确度和召回率的调和平均数,用于综合评估算法的性能。
- F1分数越高,表示算法在精确度和召回率方面表现越均衡。
- 执行时间:
- 执行时间是指算法完成任务所需的时间,是评估算法性能的重要指标之一。
- 在性能测试中,需要记录算法在不同数据集上的执行时间,以评估其计算效率。
- 内存消耗:
- 内存消耗是指算法在运行时使用的内存量,反映了算法的空间复杂度。
- 在性能测试中,需要关注算法在不同数据集上的内存使用情况,以避免内存泄漏或内存不足等问题。
- 稳定性:
- 稳定性是指算法在长时间运行或频繁调用时的性能表现是否稳定。
- 在性能测试中,可以通过压力测试等方法来验证算法的稳定性。
- 可扩展性:
- 可扩展性是指算法在处理更大规模数据集时的性能表现是否仍然良好。
- 在性能测试中,可以通过逐步增加数据集规模来评估算法的可扩展性。
三、性能测试方法
- 边界测试:
- 测试算法在边界条件(如最小值、最大值、零值等)下的表现,确保算法能够正确处理极端输入。
- 随机测试:
- 生成随机输入,验证算法的输出是否符合预期。这种方法可以模拟实际应用中的多样化输入情况。
- 交叉验证:
- 交叉验证是一种评估模型泛化能力的方法,通过将数据集分为多个子集,轮流采用其中一部分作为验证集,其余部分作为训练集。这种方法可以更有效地利用有限的数据集来评估算法的性能。
- 学习曲线:
- 学习曲线展示了模型在不同训练集大小下的性能变化,有助于判断模型是否存在过拟合或欠拟合的问题。
- 可视化:
- 使用可视化工具和图表来呈现性能结果,使得结果更容易理解和传达。这有助于团队成员之间的沟通和协作。
四、总结
算法的性能测试是一个复杂而细致的过程,需要关注多个关键指标和方法。通过全面、准确地评估算法的性能,可以为实际应用中的算法选择和优化提供有力的支持。同时,性能测试也是算法开发和优化过程中不可或缺的一环,有助于不断改进和提升算法的性能。