CLIP(Contrastive Language-Image Pre-Training)
从名字显而易见:语言-图像,预训练,主要用于学习图像
该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系
CLIP模型有两个模态,一个是文本模态,一个是视觉模态,包括两个主要部分
内容
该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系。CLIP模型有两个模态,一个是文本模态,一个是视觉模态,包括两个主要部分:
- Text Encoder:用于将文本转换为低维向量表示-Embeding。
- Image Encoder:用于将图像转换为类似的向量表示-Embedding。
在预测阶段,CLIP模型通过计算文本和图像向量之间的余弦相似度来生成预测。这种模型特别适用于零样本学习任务,即模型不需要看到新的图像或文本的训练示例就能进行预测。CLIP模型在多个领域表现出色,如图像文本检索、图文生成等。
CLIP基本的结构构成
对于图像编码器部分
Image Encoder
主要进行了以下的内容:
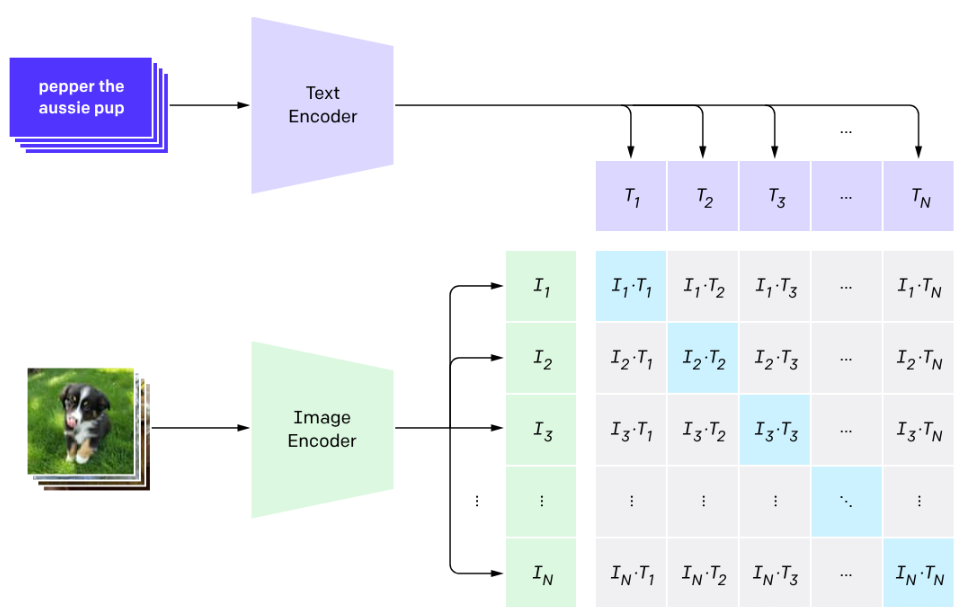
注意看里面的Image Encoder,那么他是什么意思呢?我们来看看。。
首先将图像进行分割,以便于进行后续的图像处理操作
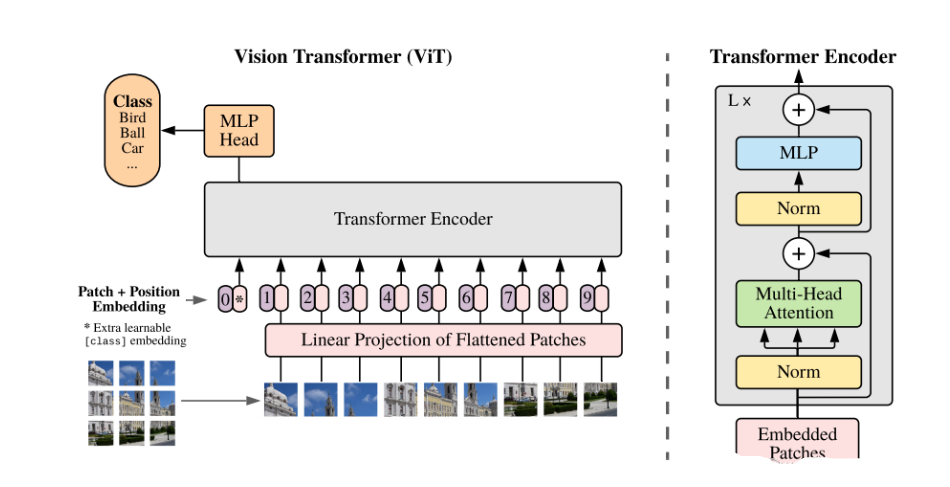
对于文本编码器部分
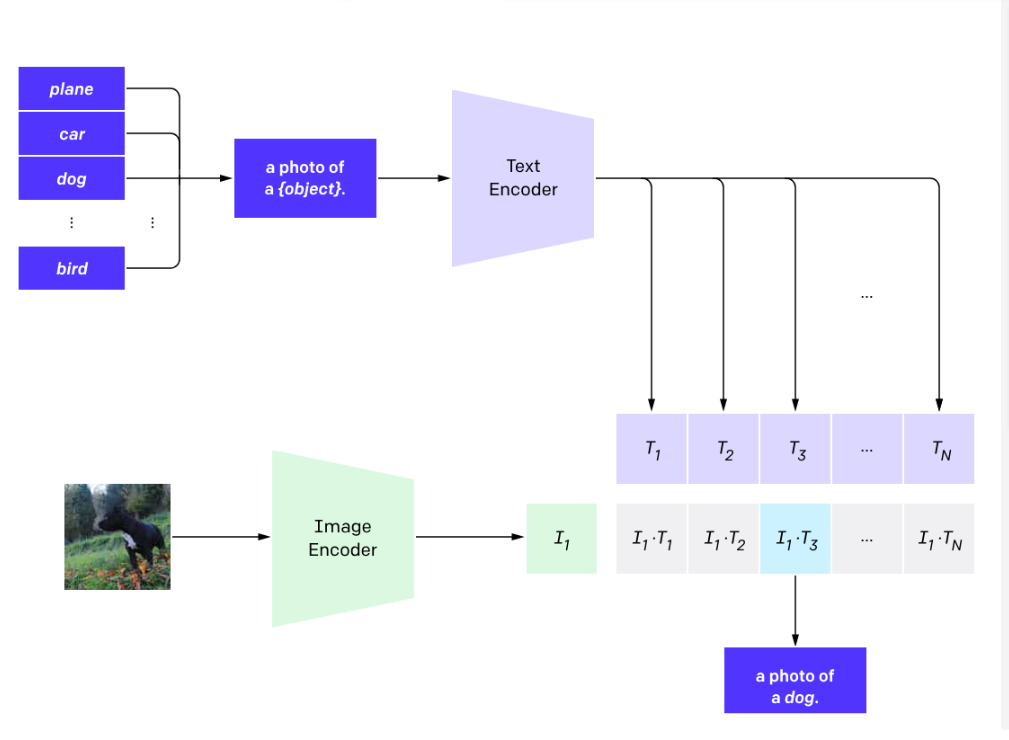
主要进行文本的训练过程
![[极客大挑战 2019]Havefun](https://img2024.cnblogs.com/blog/3215892/202411/3215892-20241111121104541-973946983.png)