Plotly常见可视化方案:以鸢尾花数据为例
简单介绍:
- Ploty库也有大量统计可视化方案,并且这些可视化方案具有交互化属性。
- 主要对鸢尾花数据进行处理与可视化。
- 所展示的结果为交互界面的截图情况,这里不能进行交互。
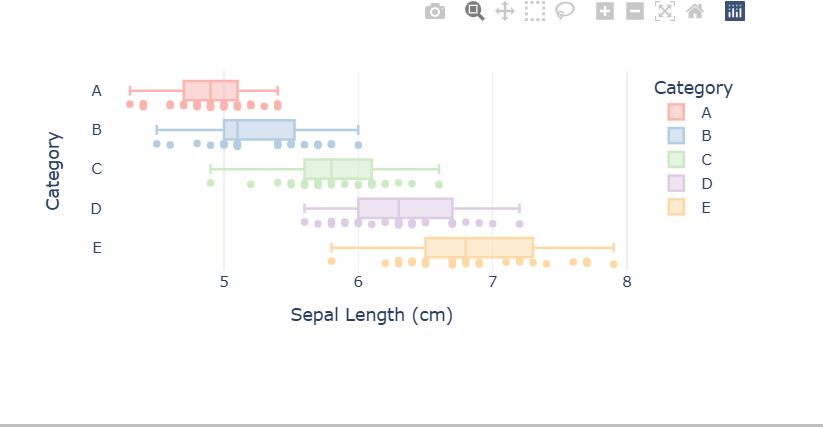
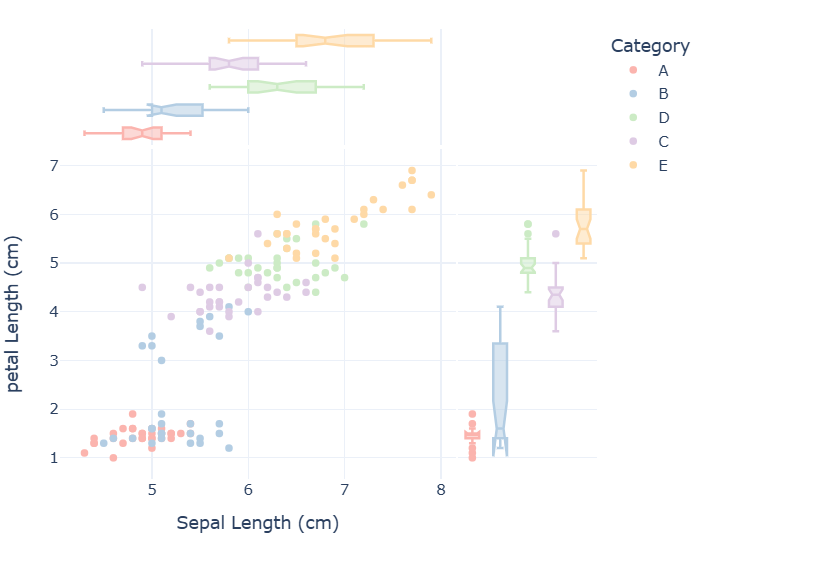
使用Plotly绘制散点图与箱型图,分类展示“花萼宽度”
说明:
- 类似'species'这个分类标签,使用'Category'分析原始特征数据,如花萼宽带
import seaborn as sns
import pandas as pd
import plotly.express as pxdf=sns.load_dataset("iris")
df['area']=df['sepal_length']*df['petal_width']
#计算”面积”,其中‘area'为新产生的一列
df['Category']=pd.qcut(df['area'],5,labels=['A','B','C','D','E'])
#pandas.qcut()方法根据’area'大小将数据大致分成5分=份且编号。list_stats=['min','max','mean','median','std']
stats_by_area=df.groupby('Category')['area'].agg(list_stats)
#这里以Category为参照进行分组,之后对area进行计算统计量
stats_by_area['Range']=stats_by_area['max']-stats_by_area['min']
stats_by_area['Nunber']=df['Category'].value_counts()
#通过个方法相应的数值#---画出箱型图----
fig = px.box(df,x = 'sepal_length',y = 'Category',color = 'Category',points='all',#color指定以什么来区分颜色,points来指明是否画点template="plotly_white",width=600,height=300,category_orders={"Category":["A","B","C","D","E"]},color_discrete_sequence=px.colors.qualitative.Pastel1,#指定颜色映射的调色板labels={"sepal_length":"Sepal Length (cm)"})
fig.show()#---画出散点图-----
fig=px.scatter(df,x='sepal_length',y='petal_length',color='Category',marginal_x='box', marginal_y='box',#分别在x,y轴的边缘加上箱型图template="plotly_white",width=600,height=500,color_discrete_sequence=px.colors.qualitative.Pastel1,labels={"sepal_length":"Sepal Length (cm)","petal_length":"petal Length (cm)"})
fig.show()
结果:
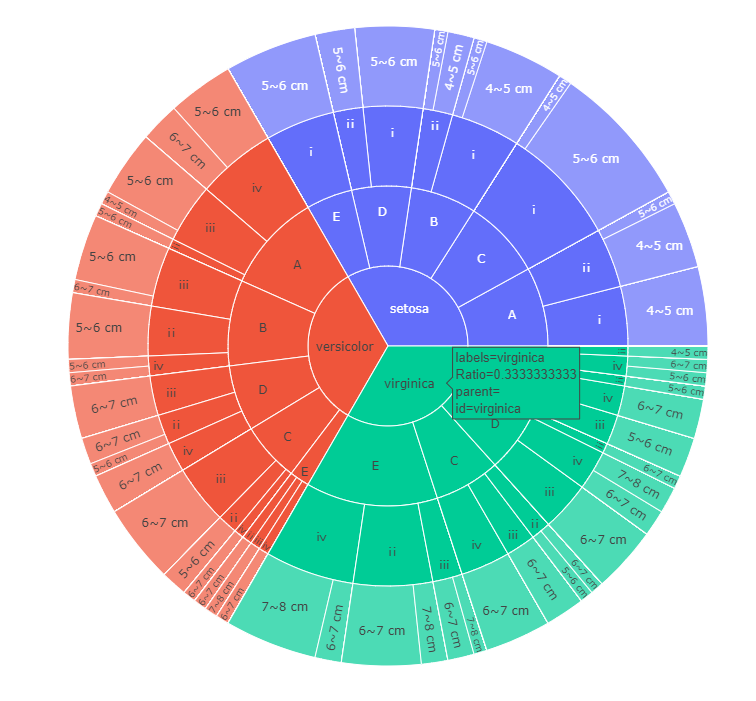
以鸢尾花种类,面积,长度范围,长宽比值为四个维度,并用太阳爆炸,冰柱图,矩形树状图可视化钻取
说明:
- 因原始数据没有相关的维度,故需要添加相关的维度
- 确定一下钻取顺序情况
- 对其进行可视化
import pandas as pd
import seaborn as sns
import plotly.express as px
#---传入数据并对数据进行加工----
df=sns.load_dataset("iris")
df['area']=df['sepal_length']*df['sepal_width']
df['Category']=pd.qcut(df['area'],5,labels=['A','B','C','D','E'])
#上面得到面积,这里根据面积来将数据划分成五等分labels=["{0}~{1} cm".format(i,i+1) for i in range(4,8)]
#这里将长度也分成四分,为4~5,5~6,下面的right表明右开。
df["sepal_length_bins"]=pd.cut(df.sepal_length,range(4,9),right=False,labels=labels)df['bi']=df['sepal_length']/df['sepal_width']
#以长宽作为依据划分label为每一区域的标签
df['Category1']=pd.qcut(df['bi'],4,labels=['ⅰ','ⅱ','ⅲ','ⅳ'])dims=['species','Category','Category1','sepal_length_bins']#钻取顺序,为日冕图做准备
#下面以sepal_length为数值来源得到概率
prob_matrix_by_4=df.groupby(dims)['sepal_length'].apply(lambda x:x.count()/len(df))
prob_matrix_by_4=prob_matrix_by_4.reset_index()
prob_matrix_by_4.rename(columns={'sepal_length':'Ratio'},inplace=True)
#画出日冕图像
fig=px.sunburst(prob_matrix_by_4,path=dims,values='Ratio',width=800,height=800)
fig.show()
#通过pd.crosstab方法进行交叉计数,这里列最好为一层,方便后面转化长格式后对count的计数
count_matrix=pd.crosstab(index=[df.species,df.Category,df.Category1],columns=df.sepal_length_bins,values=df.petal_length,aggfunc='count')
count_matrix=count_matrix.stack().reset_index()
count_matrix.rename(columns={0:'count'},inplace=True)
count_matrix=count_matrix[count_matrix['count']!=0]
#只保留不为0的,冰柱图面对0会报错。
fig=px.icicle(count_matrix,path=[px.Constant("all"),#在最左侧加入all.'species','Category','Category1','sepal_length_bins'],values='count',color_continuous_scale='Blues',color='count',width=800,height=800)
fig.show()#---画出矩形树状图----
fig=px.treemap(count_matrix,path=[px.Constant("all"),'species','Category','Category1','sepal_length_bins'],values='count',color_continuous_scale='Blues',color='count',width=800,height=800)
fig.show()
结果:
日冕图:
冰柱图:
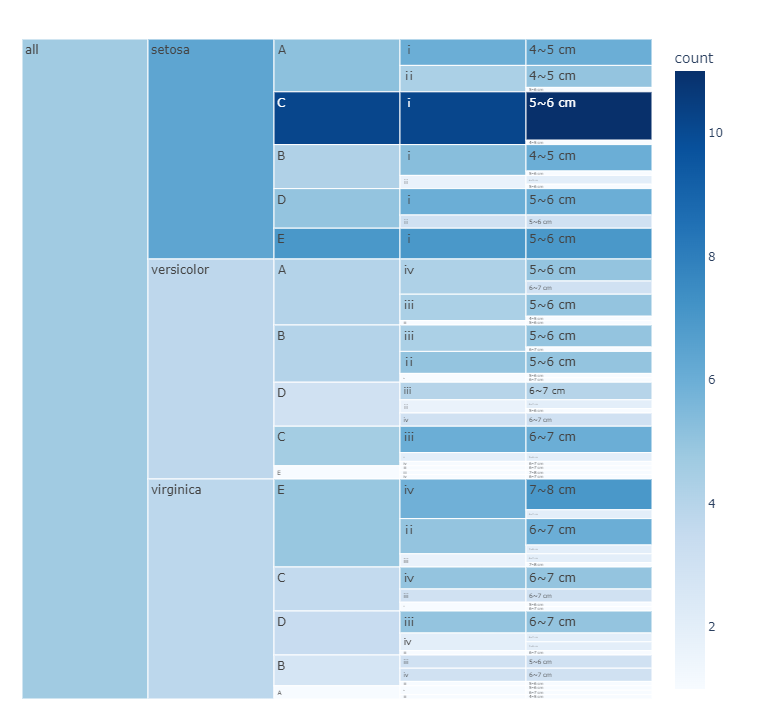
矩形树状图:






![[豪の学习笔记] CI/CD相关 - Docker](https://img2024.cnblogs.com/blog/3555868/202411/3555868-20241111152921024-1952162656.png)