双十一购物狂欢节即将到来,作为程序员,利用爬虫技术查询商品的历史价格趋势,似乎是一个合理的需求,毕竟这只是为了自己参考,不涉及商业用途。然而,小伙伴们在进行爬虫操作时一定要谨慎小心,尤其是在数据采集和使用的过程中,务必遵守相关法律法规与平台的使用规范。
每次和大家讲解爬虫时,我总是提醒一句:“谨慎、谨慎、再谨慎!”不仅要避免触犯法律,也要避免对网站的正常运营造成影响,保持理性和合规。
商品获取
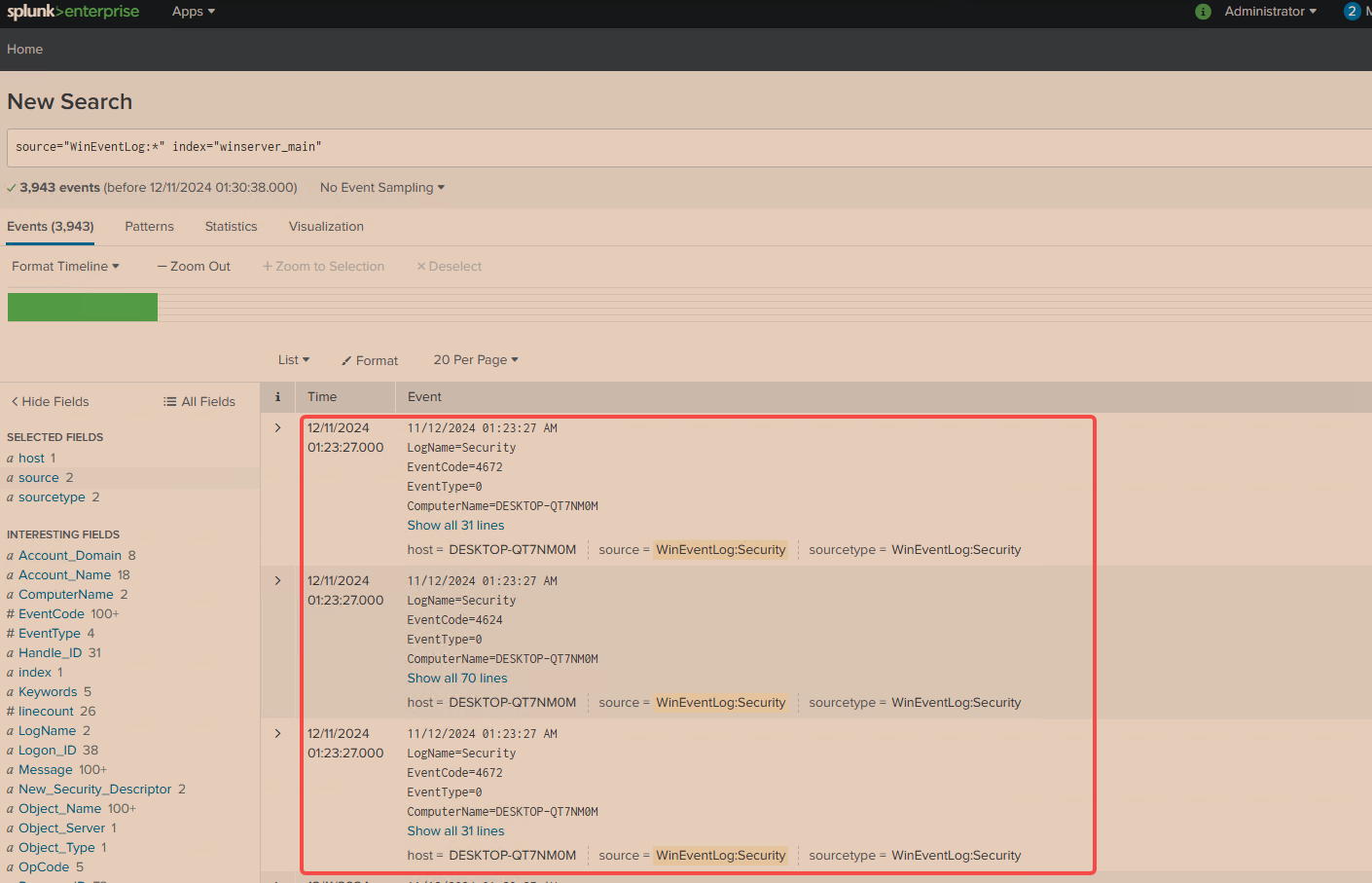
好的,我们的第一步是进入京东的查询页面,找到并打开我们关注的商品页面。例如,假设我最关注的是显卡的价格和相关数据,那么接下来我就会去查询显卡的具体信息。通过这种方式,我们能够获取到显卡的相关商品数据。如图:

你要做的工作是找到我们的商品信息请求连接。这个连接可能不好找,所以你需要耐心地逐个查看相关页面。我已经帮你找到这个连接了,现在我们可以直接根据它开始编写爬虫脚本,目标是从中提取商品链接。你可以通过右键点击请求,选择“复制请求为Python代码”来直接获取Python代码。
至于在线工具,市场上有很多类似的工具可以帮助你转换请求,但我就不一一列举了,你可以根据需求自行选择合适的工具。
代码部分你可以自己编写,我这里只会提供一些关键部分的示例代码,帮助你更好地理解如何实现。以下是我为你整理的关键代码片段:
response = requests.get('https://api.m.jd.com/', params=params, cookies=cookies, headers=headers)# 使用BeautifulSoup解析HTMLsoup = BeautifulSoup(response.text, 'html.parser')# 查找所有符合条件的div标签div_tags = soup.find_all('div', class_='p-name p-name-type-2')# 循环遍历每个div标签,提取信息for div_tag in div_tags:# 查找 span 标签中是否有 "自营" 标识self_operated_tag = div_tag.find('span', class_='p-tag')if self_operated_tag and '自营' in self_operated_tag.text:# 提取显卡名称和链接a_tag = div_tag.find('a', href=True)product_name = a_tag.find('em').text.strip()# 处理相对路径,拼接为完整的URLlink = 'https:' + a_tag['href'] if a_tag['href'].startswith('//') else a_tag['href']store.append({'name': product_name,'link': link})# 打印结果print("名称:", product_name)print("链接:", link)else:print("没有找到自营标识或没有相关信息。")sort_data(store,keyword)def sort_data(data,name):with open(name+'.csv','a',newline='',encoding='utf8')as f:writer=csv.writer(f)for i in data:writer.writerow((i['name'],i['link']))
这里我们只关注自营商品,因为自营商品的品质相对有保障。为了避免频繁爬取导致封号的风险,我将爬取到的数据存储到了CSV文件中,便于后续使用。毕竟,不建议频繁地向同一网站发起请求,这样很容易被封禁。
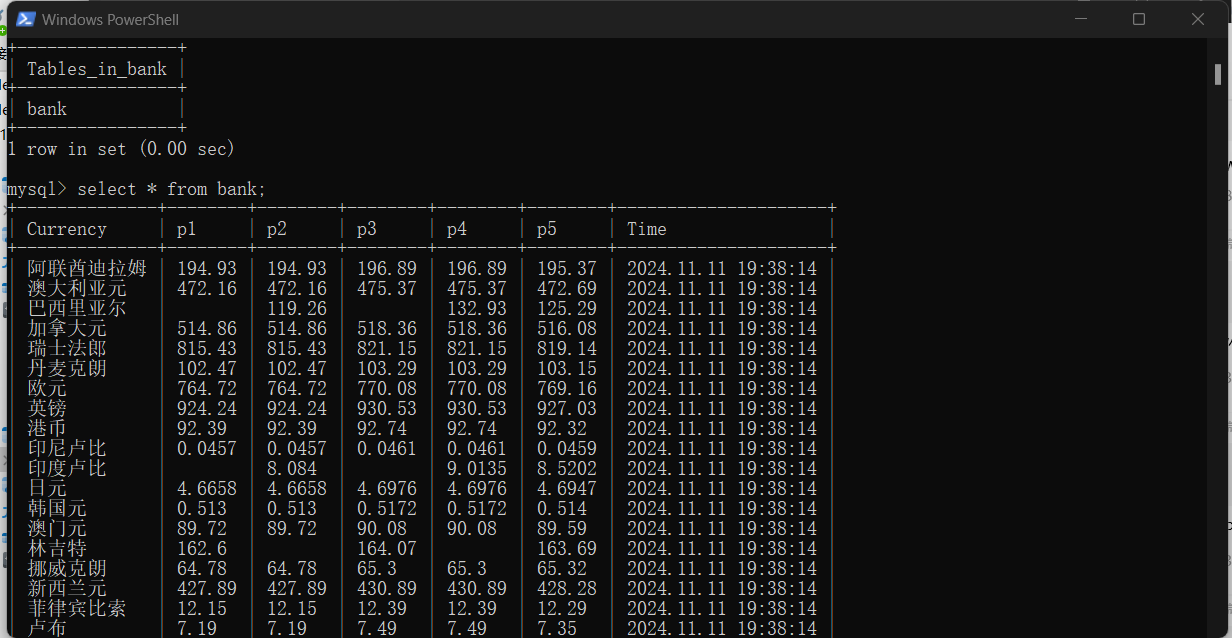
以下是我爬取的某一页的数据示例。如果你需要获取多个页面的数据,只需调整相关参数即可,确保分页功能正常工作。爬取的示例数据如下所示:

没错,我并没有爬取商品的实时价格,因为我们这次的主要目标是获取历史价格数据。不过,在抓取历史价格的同时,顺便也爬取了商品的最新价格,这样既能满足需求,又不会浪费额外的爬取时间。因此,当前的代码已经覆盖了这两方面的内容。
接下来,我们可以转到另一个网站,看看它的数据结构和爬取方式,以便进行比较和优化。
历史价格爬取
在成功获取完当前网站的数据后,我们将转向爬取另一个网站的数据。首先,为了确保能够顺利抓取到所需的历史价格信息,我们需要在Web端进行一些初步的测试。通过手动操作和分析网络请求,我确认了能够获取历史价格数据的请求接口。
经过一番测试和调试后,我成功找到了正确的请求连接。接下来,我将展示这个连接,供大家参考。如下所示:

我们计划逐步抓取每一个商品链接的历史价格信息,以确保数据的全面性和准确性。然而,在抓取过程中,我注意到请求的内容中包含了一个加密部分,这使得我们无法直接获取到完整的价格数据。这一加密内容需要解密或进一步处理,才能确保我们能够成功提取出历史价格。
因此,在继续抓取之前,我们需要先分析并处理这个加密机制。以下是加密部分的内容,供参考:

在这个请求过程中,使用的并不是商品的直接链接,而是一个经过加密处理的“code”参数。实际上,商品链接在上面的请求中已经经历了一定的转换处理,因此我们无需过于担心这个转换步骤,它只是多了一道处理环节而已,对数据获取本身没有实质性影响。
我们只需要按照指定的方式获取这个“code”参数,并在后续请求中正确使用它即可。经过一系列分析和处理,最终的代码实现如下所示:
def get_history(itemid):#此处省略一堆代码params = {'ud': 'EAONJNRXWXSMTBKNNYL_1730899204','reqid': '46db0db9f67129f31d1fca1f96ed4239','checkCode': 'ada35e4f5d7c1c55403289ec49df69e3P9f1','con': itemid,}data = {'checkCode': 'ada35e4f5d7c1c55403289ec49df69e3P9f1','con': itemid,}response = requests.post('http://www.tool168.cn/dm/ptinfo.php', params=params, cookies=cookies, headers=headers, data=data, verify=False)#此处省略一堆代码code = json.loads(response.text)params = {'code': code['code'],'t': '','ud': 'EAONJNRXWXSMTBKNNYL_1730899204','reqid': '46db0db9f67129f31d1fca1f96ed4239',}response = requests.post('http://www.tool168.cn/dm/history.php', params=params, cookies=cookies, headers=headers, verify=False)# 正则表达式匹配Date.UTC中的日期和价格pattern = r"Date.UTC\((\d{4}),(\d{1,2}),(\d{1,2})\),([\d\.]+)"matches = re.findall(pattern, response.text)# 解析日期和价格prices = []for match in matches:year, month, day, price = matchdate = datetime(int(year), int(month) + 1, int(day)) # 月份是从0开始的,需要加1prices.append((date, float(price)))# 找出最低价格、最高价格和最新价格min_price = min(prices, key=lambda x: x[1])max_price = max(prices, key=lambda x: x[1])latest_price = prices[-1]# 打印结果print(f"最低价格: {min_price[1]},日期: {min_price[0].strftime('%Y-%m-%d')}")print(f"最高价格: {max_price[1]},日期: {max_price[0].strftime('%Y-%m-%d')}")print(f"最新价格: {latest_price[1]},日期: {latest_price[0].strftime('%Y-%m-%d')}")get_history("https://item.jd.com/100061261651.html")
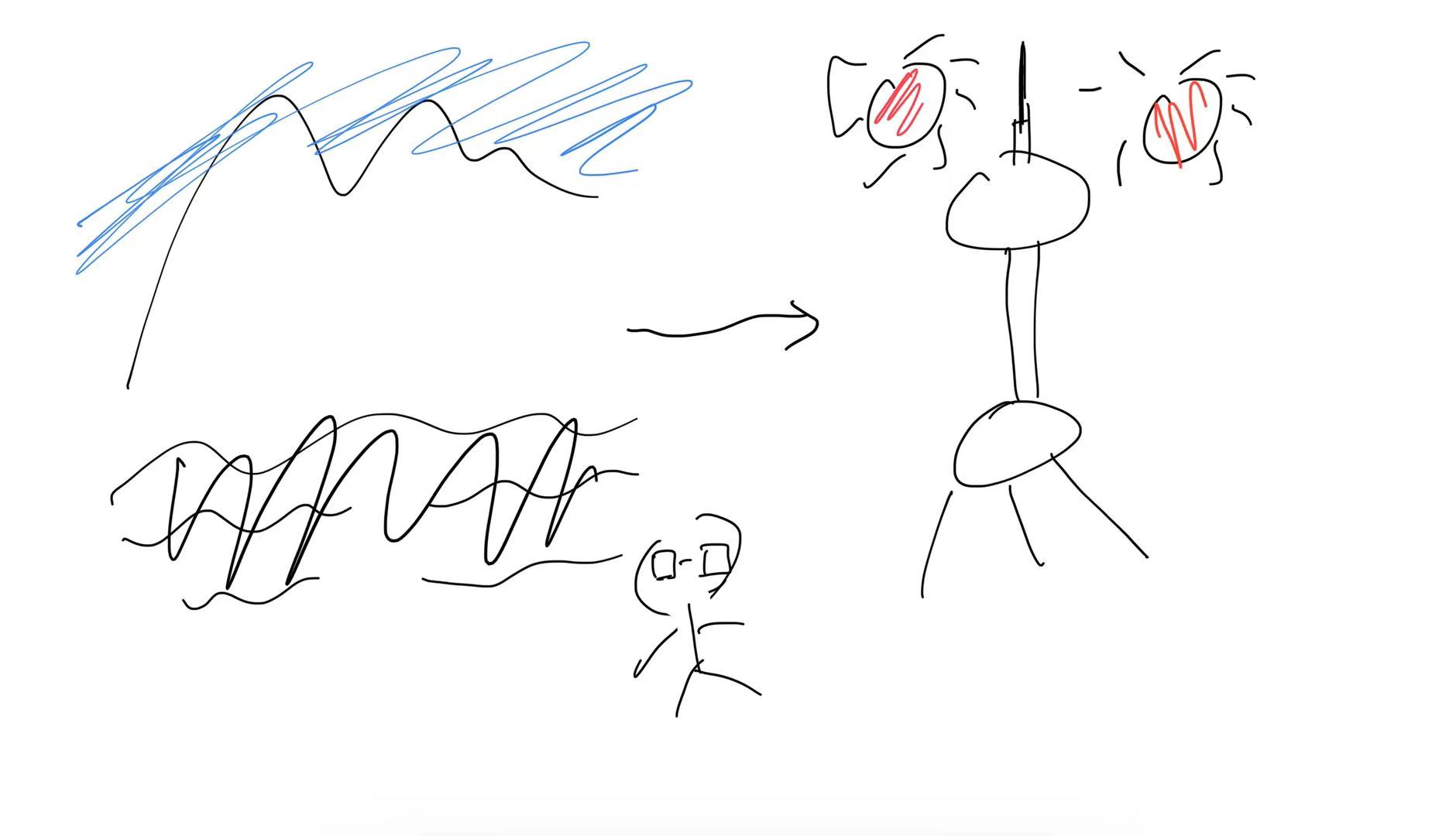
最后,通过对获取到的历史价格数据进行分析,我们可以基于价格的波动趋势做出合理的购买判断!看下最终的效果:

剩下的工作就是对代码进行优化的过程了。在这个阶段,我们的主要目标是展示一个基本的实现思路,并且验证相关功能是否有效。实际上,我们并不打算爬取所有商品的详细信息,因为这不仅不符合我们的实际需求,而且在实际操作中也没有必要。
总结
总的来说,爬虫技术为我们提供了丰富的数据资源,但在使用过程中,谨慎行事,理性操作,才能真正让爬虫技术为我们的生活带来便利,而不是带来麻烦。希望大家在即将到来的双十一购物狂欢节中,既能抓住机会购买心仪的商品,又能遵守道德与法律的底线,做一个负责任的技术使用者。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟