- 1. 参考
- 2. 介绍
- 3. 权重的切分
- 3.1 按行切分权重
- 3.2 按列切分权重
- 4. MLP层
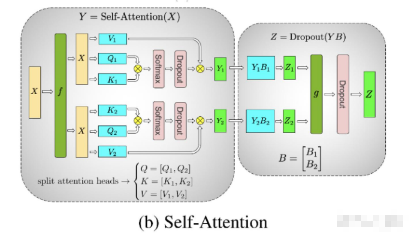
- 5. Self-Attention层
- 6. Embedding层
- 7. Cross-entropy层
- 8. 张量模型并行 + 数据并行
1. 参考
https://zhuanlan.zhihu.com/p/622212228
2. 介绍
流水线并行
数据并行(DP,DDP和ZeRO)
介绍最重要,也是目前基于Transformer做大模型预训练最基本的并行范式:来自NVIDIA的张量模型并行(TP)。
基本思想就是把模型的参数纵向切开,放到不同的GPU上进行独立计算,然后再做聚合。
之前的将的都是 模型 按照层 进行切割。
全文结构如下:
一、切分权重的两种方法
二、MLP层
三、self-attention层
四、Embedding层
五、Cross-entropy层
六、经典并行:TP + DP (Megatron + ZeRO)
七、实验效果与GPU利用率
八、参考
3. 权重的切分
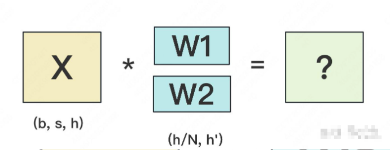
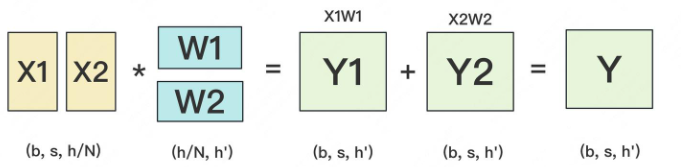
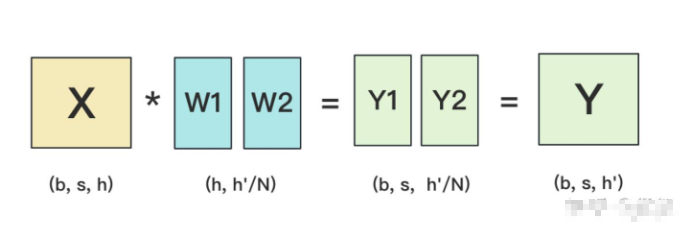
设输入数据为X,参数为W。X的维度 = (b, s, h),W的维度 = (h, h')。其中:
- b:batch_size,表示批量大小
- s:sequence_length,表示输入序列的长度
- h:hidden_size,表示每个token向量的维度。
- h':参数W的hidden_size。
orward的过程如下:
图中所绘是b=1时的情况。
假设现在W太大,导致单卡装不下。我们需要把W切开放到不同的卡上,则我们面临三个主要问题:
- 怎么切分W。
- 切完W后,怎么做forward。
- 做完forward后,怎么做backward,进而求出梯度,更新权重。
一般来说,我们可以沿着W的行(h维度),或者列(h'维度)切分W。下面我们分别介绍这两种切割办法,并说明它们是如何做forward和backward的。
3.1 按行切分权重
forward
我们用N来表示GPU的数量。有几块GPU,就把W按行维度切成几份。下图展示了N=2时的切割方式:
W按照行维度切开后,X的维度和它不对齐了,这可怎么做矩阵乘法呢?很简单,再把X“按列切开”就行了,如下图所示:
backward
做完forward,取得预测值Y,进而可计算出损失L,接下来就能做backward了。我们重画一下forward的过程,并在其中加入backward的部分,整体流程图如下:
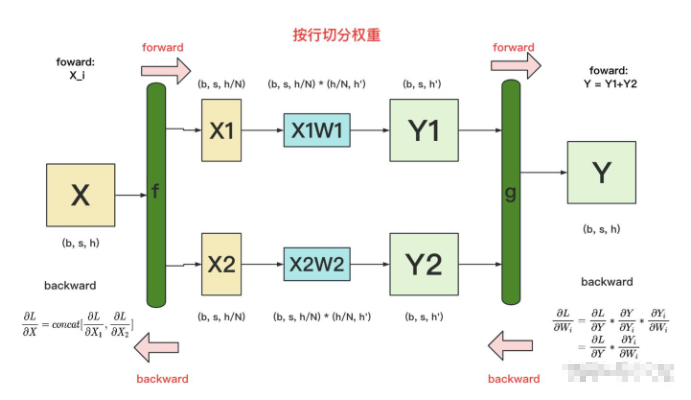
f 和 g:分别表示两个算子,每个算子都包含一组forward + backward操作。
其中 forward:
f算子:X 竖直方向切割成x1 x2即可
g算子:y1 + y2 即可
图中的每一行,表示单独在一块GPU上计算的过程
f 和 g算子的backward
g 的backward:
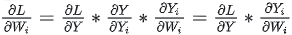
需要把 同时广播到两块GPU上,两块GPU就可以独立计算各自权重的梯度了。
同时广播到两块GPU上,两块GPU就可以独立计算各自权重的梯度了。
f 的backward: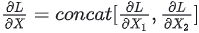
3.2 按列切分权重
按列切分权重后,forward计算图如下:
这个forward还是比较简单的直接切分别计算 再接到一起 即可
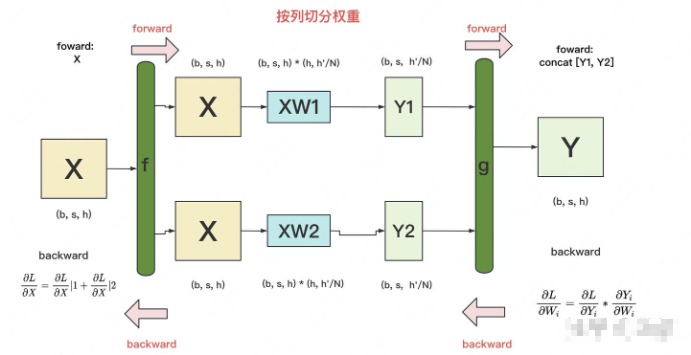
g的backward: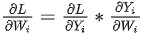
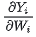 貌似都等于X
貌似都等于X
因此只要计算各自GPU上的 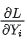
f 的backward:因为对于损失L,X既参与了XW1的计算,也参与了XW2的计算,因此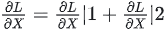 ,其中
,其中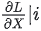 表示第i块GPU上计算到X时的梯度。
表示第i块GPU上计算到X时的梯度。
已分别介绍完了“按行”和“按列”切分权重的方法。在Megatron-LM中,权重的切分操作就是由这两个基础算子组合而成的。接下来,针对Transformer模型,我们依次来看在不同的部分里,Megatron-LM是怎么做切分的。
4. MLP层
MLP层构造最简单,所以我们先来看它。MLP层计算过程如下图:
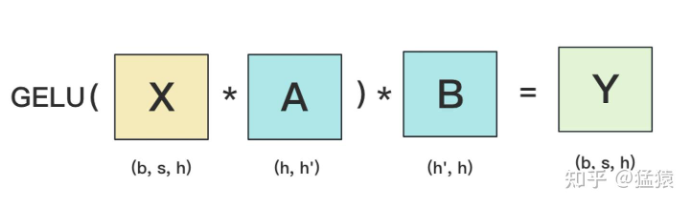
GELU是激活函数,A和B分别为两个线性层。在Transformer里,一般设h' = 4h。
h为embedding的维度
h'为隐藏层的维度
也就是会将embedding的维度 升维到4h的一个更高的维度。
假设现在有N块GPU,我们要把MLP层的权重拆到上面做计算,要怎么拆分呢?Megatron提供的拆分办法如下:
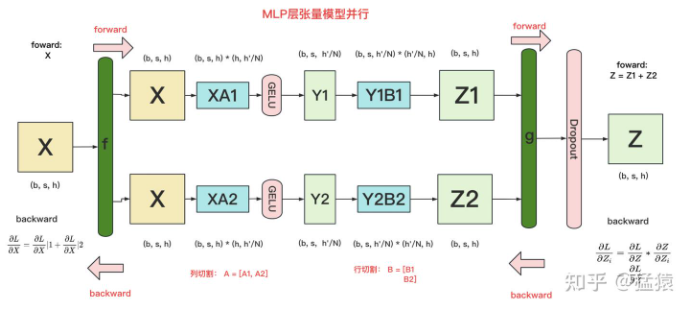
在MLP层中,对A采用“列切割”,对B采用“行切割”。
f 的forward计算:把输入X拷贝到两块GPU上,每块GPU即可独立做forward计算。
g 的forward计算:每块GPU上的forward的计算完毕,取得Z1和Z2后,GPU间做一次AllReduce,相加结果产生Z。
g 的backward计算:只需要把 拷贝到两块GPU上,两块GPU就能各自独立做梯度计算。
拷贝到两块GPU上,两块GPU就能各自独立做梯度计算。
f 的backward计算:当当前层的梯度计算完毕,需要传递到下一层继续做梯度计算时,我们需要求得 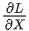 则此时两块GPU做一次AllReduce,把各自的梯度
则此时两块GPU做一次AllReduce,把各自的梯度 相加即可。
相加即可。
为什么我们对A采用列切割,对B采用行切割呢?
这样设计的原因是,我们尽量保证各GPU上的计算相互独立,减少通讯量。
对A来说,需要做一次GELU的计算,而GELU函数是非线形的,它的性质如下:
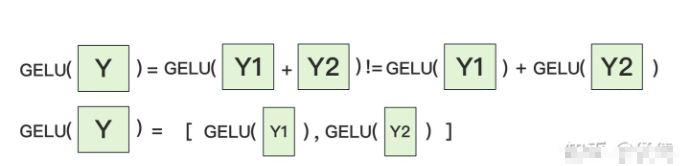
也就意味着,如果对A采用行切割,我们必须在做GELU前,做一次AllReduce,这样就会产生额外通讯量。但是如果对A采用列切割,那每块GPU就可以继续独立计算了。一旦确认好A做列切割,那么也就相应定好B需要做行切割了。
MLP层的通讯量分析:
MLP层做forward时产生一次AllReduce,做backward时产生一次AllReduce。
AllReduce的过程分为两个阶段,Reduce-Scatter和All-Gather,每个阶段的通讯量都相等。
现在我们设每个阶段的通讯量为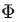 ,
,
则一次AllReduce产生的通讯量为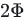 ,MLP层的总通讯量为
,MLP层的总通讯量为 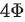
根据上面的计算图 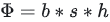
5. Self-Attention层
看稍微复杂一点的self-attention层切割方式(Transformer中Encode和Decoder之间还有做cross-attention,但计算逻辑和self-attention一致,因此这里只拿self-attention举例)。
当head数量为1时,self-attention层的计算方法如下:
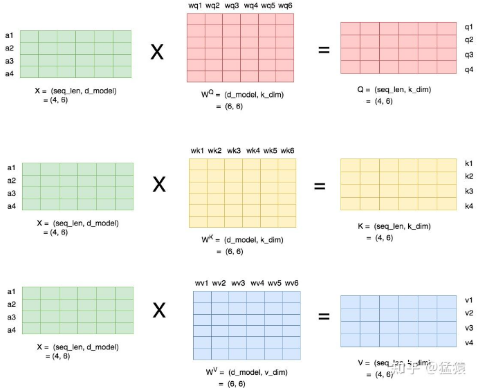
seq_len,d_model分别为本文维度说明中的s和h,也即序列长度和每个token的向量维度
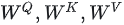 attention层需要做训练的三块权重。
attention层需要做训练的三块权重。
理清了单头,我们来看多头的情况,下图展示了当num_heads = 2时attention层的计算方法。
即对每一块权重,我们都沿着列方向(k_dim)维度切割一刀。
此时每个head上的  的维度都变成(d_model, k_dim//2)
的维度都变成(d_model, k_dim//2)
每个head上单独做矩阵计算,最后将计算结果concat起来即可。整个流程如下:

这不就是竖直切割的方式吗?
可以发现,attention的多头计算简直是为张量模型并行量身定做的,因为每个头上都可以独立计算,最后再将结果concat起来。也就是说,可以把每个头的参数放到一块GPU上。则整个过程可以画成:
对三个参数矩阵Q,K,V,按照“列切割”,每个头放到一块GPU上,做并行计算。对线性层B,按照“行切割”。切割的方式和MLP层基本一致,其forward与backward原理也一致,这里不再赘述。
最后,在实际应用中,并不一定按照一个head占用一块GPU来切割权重,我们也可以一个多个head占用一块GPU,这依然不会改变单块GPU上独立计算的目的。所以实际设计时,我们尽量保证head总数能被GPU个数整除。
Self-Attention层的通讯量分析
self-attention层在forward中做一次AllReduce,在backward中做一次AllReduce。总通讯量也是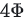 ,其中
,其中 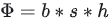
self-attention层拼接起来看整体的计算逻辑和通讯量:
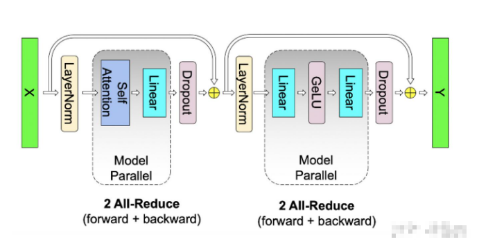
6. Embedding层
输入层Embedding,
word embedding:维度(v, h),其中v表示词表大小。
positional embedding:维度(max_s, h),其中max_s表示模型允许的最大序列长度。
对positional embedding来说,max_s本身不会太长,因此每个GPU上都拷贝一份,对显存的压力也不会太大。
但是对word embedding来说,词表的大小就很客观了,因此需要把word embedding拆分到各个GPU上,具体的做法如下:
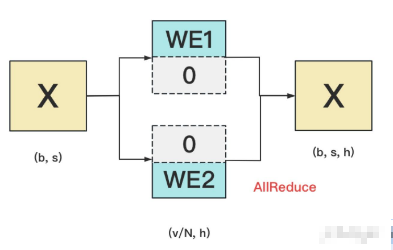
对于输入X,过word embedding的过程,就是等于用token的序号去word embedding中查找对应词向量的过程。
例如,输入数据为[0, 212, 7, 9],数据中的每一个元素代表词序号,我们要做的就是去word embedding中的0,212,7,9行去把相应的词向量找出来。
假设词表中有300个词,现在我们将word embedding拆分到两块GPU上,第一块GPU维护词表[0, 150),第二块GPU维护词表[150, 299)。
当输入X去GPU上查找时,能找到的词,就正常返回词向量,找到不到就把词向量中的全部全素都置0。按此方式查找完毕后,每块GPU上的数据做一次AllReduce,就能得到最终的输入。
例如例子中,第一块GPU的查找结果为[ok, 0, ok, ok],第二块为[0, ok, 0, 0],两个向量一相加,变为[ok, ok, ok, ok]
输出层Embedding
输出层中,同样有一个word embedding,把输出再映射回词表里,得到每一个位置的词。一般来说,输入层和输出层共用一个word embeding。其计算过程如下:
需要注意的是,必须时刻保证输入层和输出层共用一套word embedding。
而在backward的过程中,我们在输出层时会对word embedding计算一次梯度,在输入层中还会对word embedding计算一次梯度。在用梯度做word embedding权重更新时,我们必须保证用两次梯度的总和进行更新。
当模型的输入层到输入层都在一块GPU上时(即流水线并行深度=1),我们不必担心这点(实践中大部分用Megatron做并行的项目也是这么做的)。但若模型输入层和输出层在不同的GPU上时,我们就要保证在权重更新前,两块GPU上的word embedding梯度做了一次AllReduce。
7. Cross-entropy层
终于来到了计算损失函数的一层回顾一下4.2中,输出层过完embedding后的样子:
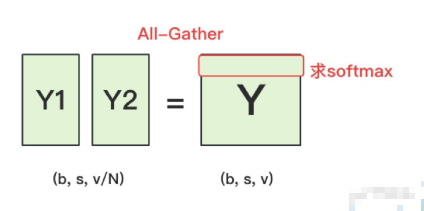
正常来说,我们需要对Y1和Y2做一次All-Gather,把它们concat起来形成Y,然后对Y的每一行做softmax,就可得到对于当前位置来说,每个词出现的概率。接着,再用此概率和真值组做cross-entropy即可。
但是All-Gather会产生额外的通讯量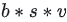 ,当词表v很大时,这个通讯开销也不容忽视。针对这种情况,可以做如下优化:
,当词表v很大时,这个通讯开销也不容忽视。针对这种情况,可以做如下优化:
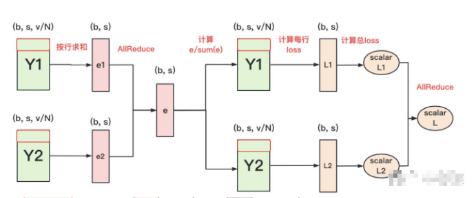
- 每块GPU上,我们可以先按行求和,得到各自GPU上的GPU_sum(e)
- 将每块GPU上结果做AllReduce,得到每行最终的sum(e),也就softmax中的分母。此时的通讯量为
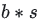 ,
, - 在每块GPU上,即可计算各自维护部分的e/sum(e),将其与真值做cross-entropy,得到每行的loss,按行加总起来以后得到GPU上scalar Loss。
- 将GPU上的scalar Loss做AllReduce,得到总Loss。此时通讯量为N。
这样,我们把原先的通讯量从 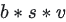 大大降至
大大降至 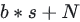 。
。
8. 张量模型并行 + 数据并行
基本把张量模型并行的计算架构说完,对Transformer类的模型,采用最经典方法是张量模型并行 + 数据并行,并在数据并行中引入ZeRO做显存优化。具体的架构如下:
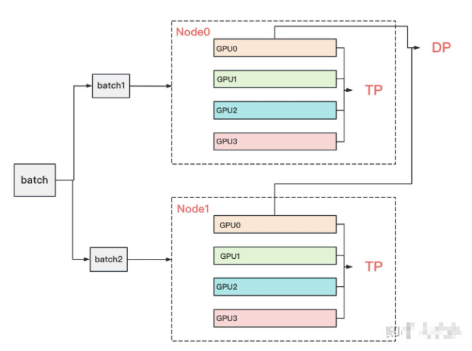
node表示一台机器,一般我们在同一台机器的GPU间做张量模型并行。在不同的机器上做数据并行。图中颜色相同的部分,为一个数据并行组。