在过往的编程过程中,常常会因为碰到字符集问题而头痛,而每次在进行字符集转换的时候,各种搜索网上文档,想找字符集转换的示例程序,但是都不尽人意,本篇文章的目的就是彻底解决之前编程过程中对字符集认识以及字符集转换之间似懂非懂、云里雾里的状态,并在文章结尾附上 ANSI、UNICODE 和 UTF-8 之间互转的代码。
一、ANSI 与 UNICODE
为了弄清楚编码之间的关系,我们首先来弄清楚编码的两个大类别:
ANSI:多字节字符集(MBCS),使用多个字节来表示一个字符,通常用于表示 ASCll 字符集之外的字符。在 MBCS 中, ASCll 字符(0-127)通常用一个字符表示,而其他字符则可能用两个字节或更多字节表示。MBCS 可以处理多种语言,但每种语言可能需要不同的编码页(code page)。常用的多字节字符集包括:GB2312、GBK、GB18030 和 Big5 等。
UNICODE:使用固定长度的字节序列(通常是两个字节(UTF-16)或四个字节(UTF-32))来表示字符。Unicode 旨在提供一个统一的字符编码系统,可以表示世界上几乎所有的书写系统。常用的 Unicode 字符集包括:UTF-8、UTF-16LE、UTF-16BE 和 UTF-32 等。
二、常见的 ANSI 编码
1 GB2312
1980 年,中国发布了第一个汉字编码标准,即 GB2312,全称《信息交换用汉字编码字符集·基本集》,通常简称 GB(“国标”汉语拼音首字母),共收录了 6763 个汉字和 682 个其他符号,包括拉丁字母、日文假名等,此标准于次年 5 月实施,满足了日常 99% 汉字的使用需求。
2 GBK
由于有些汉字是在 GB2312 标准发布后才简化的,还有一些人名、繁体字、日语和朝鲜语中的汉字也没有包括在内,所以在 GB2312 的基础上添加了这部分字符,就形成了 GBK,全称《汉字内码扩展规范》,包含 21003 个汉字和图形符号,包括繁体中文、日文假名、韩文等,完全兼容 GB2312,该字符集于 1995 年发布,支持简繁体中文,不过它只是“技术规范指导性文件”,并不属于国家标准。
3 GB18030
GB18030 全称《信息技术中文编码字符集》,它在 GBK 的基础上增加了中日韩语中的汉字和少数民族的文字及字符,完全兼容 GB2312 和 GBK,包括 70244 个汉字和图形符号,几乎覆盖了所有 Unicode 中收录的汉字,支持简繁体中文,并且与 Unicode 编码相兼容。
4 Big5
Big5 编码全称为大五码,是台湾地区广泛使用的中文编码标准,于 1984 年发布,最初包含 13053 个汉字,后来扩展到 21003 个,主要包含繁体中文字符,不包含简体中文字符,所以不兼容 GB2312 和 GBK。
三、常见的 UNICODE 编码
UTF(Unicode Transformation Format)是 Unicode 的编码方式,用于将 Unicode 字符编码成字节序列。
1 UTF-8
UTF-8 是一种变长编码方式,使用 1 到 4 个字节表示一个字符,UTF-8 编码与 ASCll 编码兼容(即 ASCll 字符在 UTF-8 中的编码与 ASCll 相同),所以对于英文字符,UTF-8 只需要一个字节,对于常用的汉字需要 3 个字节,对于较少使用的字符则需要 4 个字节,由于 UTF-8 的兼容性和对英文字符的高效编码,所以 UTF-8 在互联网上被广泛使用。
2 UTF-16LE
UTF-16LE(UTF-16 Little Endian)是一种固定长度的编码方式,使用 2 个字节表示基本多文种平面(BMP)中的字符,对于超出 BMP 的字符则需要 4 个字节,值得注意的是,UTF-16LE 为 UTF-16 的小端序编码,即低位字节在前,高位字节在后。现代大多数个人计算机和服务器使用的 x86 架构及其衍生体系多采用小端字节序,方便 CPU 进行计算,较为常用。
3 UTF-16BE
UTF-16BE(UTF-16 Big Endian)与 UTF-16LE 类似,区别在于 UTF-16BE 为 UTF-16 的大端序编码,即高位字节在前,低位字节在后,不怎么常用。
4 UTF-32
UTF-32 是一种固定长度的编码方式,使用 4 个字节表示任何 Unicode 字符,因此 UTF-32 在存储和处理上不如 UTF-8 和 UTF-16 高效,尤其对于 ASCll 和常用汉字。UTF-32 的编码也较为简单,每个 Unocde 码点直接对应一个 UTF-32 编码,不存在字节序问题,这种编码一般只在特定的场合和系统中使用。
四、常用编码之间的关系
上面讲了这么多编码,是不是感觉都要搞混乱了,其实我们只要区分好 GB2312、GBK、GB18030 和 UTF-8 即可,其他编码比较容易分清楚。
它们四个的关系如下:

我们可以看到,ASCll 码其实是兼容性最高的,不管处于哪种编码下,英文字符都能够正常的显示,而对于中文字符,我们最常用的编码其实是 GBK,而 UTF-8 编码则最为通用,尤其在与网络相关的领域,比如浏览器中。
那到这里,可能有朋友可能会有疑问,我们平常用的编译器一般是用什么编码的呢?我们以 Visual Studio 2019 为例,一起来探究一下。
五、VS 编译器中的编码问题
VS2019 编译器中有两个地方经常涉及到编码问题,有的朋友可能没有弄得很清楚。第一个是在我们的项目属性中,里面有一个字符集设置。第二个是我们在写程序的时候,代码编辑区涉及到字符采用的编码形式。
1 项目属性中的字符集
右键项目属性 -> 配置属性 -> 高级 -> 字符集设置:
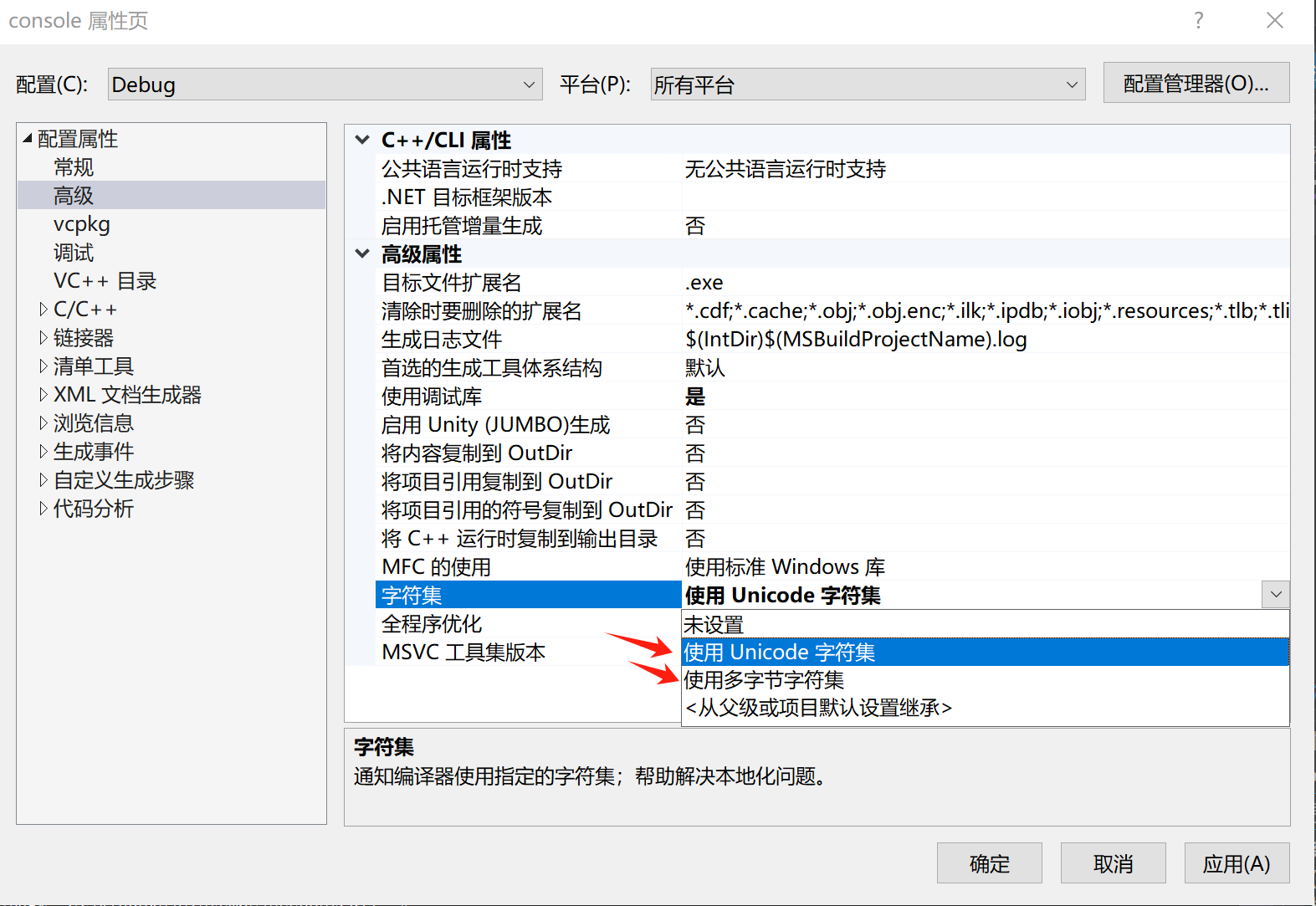
这里的字符集设置一般默认设置是使用 Unicode 字符集,这是什么意思呢?
我们在平常编写代码的过程中,会碰到需要以字符串作为参数传入的函数,比如 MessageBox,那么它就分为两个版本,分别为 MessageBoxA 和 MessageBoxW,分别对应多字节字符集和 Unicode 字符集,当我们将此处的字符集设置为使用 Unicode 字符集时,MessageBox 这个宏会调用 MessageBoxW 这个版本:

2 代码编辑区中的字符集
除了上述可以设置字符集外,其实我们在编译器的代码编辑区也涉及到了字符集设置,不过一般编译器都是默认设置好了,不需要我们进行更改,而且随意进行更改很容易导致乱码问题,出于研究的目的,我们来看一下如何设置这个代码编辑区的字符集编码。
首先我们点击 VS 菜单栏中的 工具 -> 自定义 -> 命令 -> 菜单栏下拉框选择“文件” -> 点击添加命令 -> 类别 -> 点击文件 -> 添加高级保存选项 -> 点击确认:

接下来我们再点击 文件 -> 高级保存选项:

我们可以看到我们常用的字符集编码和对应的代码页都在里面,而默认的字符集编码是 GB2312,其实代码页 936 对应的是 GBK,因此其实我们的 VS2019 编译器使用的是 GBK 编码,这里的 GB2312-80 才是简版的 GB2312,下面是常用的字符集编码和对应的代码页,供大家参考:
| 字符集 | 代码页 |
|---|---|
| GBK | 936 |
| Unicode(UTF-16LE) | 1200 |
| UTF-8 | 65001 |
| GB18030 | 54936 |
| GB2312 | 20936 |
| Unicode(UTF-16BE) | 1201 |
| Big5 | 950 |
好了,现在我们搞清楚了编译器的默认编码,那这个有什么用呢?我们来看如下代码:
std::string test = "编码转换测试Test";
那我相信大家此刻就知道了 test 中存储的是 GBK 编码的字符串了,那 std::string 能不能存储其他字符集编码的字符串呢?答案是可以的,其实 std::string 可以存储任何编码类型的字符串,也就是它其实和字符串编码是完全独立的两个东西,只是平时我们编译器帮我们设置的默认字符集编码为 GBK,所以我们大家都会忽略 std::string 中存的到底是什么编码类型的字符串,在搞不清楚的情况下涉及到字符串编码转换的问题就会出现各种莫名其妙的乱码问题。
六、字符集编码测试
上面说了这么多理论知识,下面我们来测试一下,到底是不是这样的,我们以字符串“编码转换测试Test”为例进行测试,我们首先去下面的网址得到该字符串对应的不同字符集编码下的内存字节:
https://www.toolhelper.cn/EncodeDecode/EncodeDecode
然后开始我们的实验,代码如下:
// UTF-8:编码转换测试Testconst char utf8_string[] = "\xE7\xBC\x96\xE7\xA0\x81\xE8\xBD\xAC\xE6\x8D\xA2\xE6\xB5\x8B\xE8\xAF\x95\x54\x65\x73\x74";// UTF-16LE(UTF-16 Little Endian):编码转换测试Test(尾部需要多添加一个 \x00 字节)const char utf16LE_string[] = "\x16\x7F\x01\x78\x6C\x8F\x62\x63\x4B\x6D\xD5\x8B\x54\x00\x65\x00\x73\x00\x74\x00\x00";// UTF-16BE(UTF-16 Big Endian):编码转换测试Test(尾部需要多添加一个 \x00 字节)const char utf16BE_string[] = "\x7F\x16\x78\x01\x8F\x6C\x63\x62\x6D\x4B\x8B\xD5\x00\x54\x00\x65\x00\x73\x00\x74\x00";// GBK(简繁体):编码转换测试Testconst char gbk_string[] = "\xB1\xE0\xC2\xEB\xD7\xAA\xBB\xBB\xB2\xE2\xCA\xD4\x54\x65\x73\x74";// GB18030(中日韩):编码转换测试Testconst char gb18030_string[] = "\xB1\xE0\xC2\xEB\xD7\xAA\xBB\xBB\xB2\xE2\xCA\xD4\x54\x65\x73\x74";// Big5(台湾繁体中文):編碼轉換測試Testconst char big5_string[] = "\xBD\x73\xBD\x58\xC2\xE0\xB4\xAB\xB4\xFA\xB8\xD5\x54\x65\x73\x74";/*控制台输出测试*/// 控制台输出 UTF-8 编码的字符std::system("chcp 65001"); // 设置特定的代码页,否则控制台无法显示std::cout << utf8_string << std::endl;// 控制台输出 UTF-16LE(UNICODE,小端序,Little-Endian) 编码的字符setlocale(LC_ALL, "chs"); // 设置为输出简体中文的 Unicodestd::wcout << (wchar_t*)utf16LE_string << std::endl;//windows 控制台无法直接输出 UTF-16BE(UNICODE,大端序,Big-Endian,) 编码的字符//大端先要转换成小端才能在控制台输出,因 x86 架构常用小端序,此处不再演示大端序字符打印// 控制台输出 GBK(简繁体) 编码的字符std::system("chcp 936");std::cout << gbk_string << std::endl;// 控制台输出 GB18030(中日韩) 编码的字符std::system("chcp 936");std::cout << gb18030_string << std::endl;// 控制台输出 Big5(台湾繁体中文) 编码的字符std::system("chcp 950");std::cout << big5_string << std::endl;/* 常见字符串数据类型的的字符默认存储形式 */// const char* 默认采用 GBK(简繁体) 编码char test1[] = "编码转换测试Test";std::cout << test1 << std::endl;// const wchar_t* 默认采用 UTF-16LE(UTF-16 Little Endian) 编码wchar_t test2[] = L"编码转换测试Test";setlocale(LC_ALL, "chs"); // 将程序的区域设置为简体中文,否则无法正确显示std::wcout << test2 << std::endl;// std::string 默认采用 GBK(简繁体) 编码std::string test3 = "编码转换测试Test";std::cout << test3 << std::endl;// std::wstring 默认采用 UTF-16LE(UTF-16 Little Endian) 编码std::wstring test4 = L"编码转换测试Test";setlocale(LC_ALL, "chs");std::wcout << test4 << std::endl;

我们可以看到,以上的字符串都能够以正常的格式输出,且 std::string 中默认为 GBK 编码。
有一个地方需要注意:
UTF-16LE(UTF-16 Little Endian),由于我们定义的类型为const char*,而Unicode一般以两个字节来表示一个中文字符,即使是最后的结尾null也是以两个字节\00\00来表示结尾的,而const char*只会在结尾添加一个结尾字符\0,因此我们需要在定义的字符串后面多加上一个\0,这样才不会出现乱码问题。
七、ANSI、UNICODE 和 UTF-8 编码互转
由于我们现在常用的编码为 GBK、Unicode(UTF-16LE) 和 UTF-8,因此我们可以近似的认为 ANSI 表示 GBK,Unicode(UTF-16LE) 表示 UNICODE,下面提供这三种最常用字符集编码的两两互转函数供大家参考!
1 GBK(ANSI) 转 UTF-16LE(UNICODE)
// GBK(ANSI) 转 UTF-16LE(UNICODE)
bool gbk_to_utf16LE(const std::string& gbk_str, std::wstring& utf16le_str) {try {// 计算 GBK 转换后的宽字符数并为其分配内存空间int len = MultiByteToWideChar(CP_ACP, 0, gbk_str.c_str(), -1, NULL, 0);if (len == 0) {return false;}wchar_t* wstr = new wchar_t[len + 1];memset(wstr, 0, (len + 1) * sizeof(wchar_t));// 进行 utf16LE(UNICODE) 编码转换if (MultiByteToWideChar(CP_ACP, 0, gbk_str.c_str(), -1, wstr, len) == 0) {delete[] wstr;return false;}// 将 utf16LE(UNICODE) 编码的字符串赋值给输出参数utf16le_str = wstr;delete[] wstr;return true;}catch (const std::exception& e) {// 捕获并处理任何标准异常std::cerr << "gbk_to_utf16LE() Exception occurred: " << e.what() << std::endl;return false;}catch (...) {// 捕获任何非标准异常std::cerr << "gbk_to_utf16LE() Unknown exception occurred." << std::endl;return false;}
}
2 UTF-16LE(UNICODE) 转 GBK(ANSI)
// UTF-16LE(UNICODE) 转 GBK(ANSI)
bool utf16LE_to_gbk(const std::wstring& utf16LE_str, std::string& gbk_str) {try {// 计算 UNICODE 转换后的多字节字符数并为其分配内存空间int len = WideCharToMultiByte(CP_ACP, 0, utf16LE_str.c_str(), -1, NULL, 0, NULL, NULL);if (len == 0) {return false;}char* gbk_chars = new char[len + 1];memset(gbk_chars, 0, len + 1);// 进行 GBK 编码转换if (WideCharToMultiByte(CP_ACP, 0, utf16LE_str.c_str(), -1, gbk_chars, len, NULL, NULL) == 0) {delete[] gbk_chars;return false;}// 将 GBK 编码的字符串赋值给输出参数gbk_str = gbk_chars;delete[] gbk_chars;return true;}catch (const std::exception& e) {// 捕获并处理任何标准异常std::cerr << "utf16LE_to_gbk() Exception occurred: " << e.what() << std::endl;return false;}catch (...) {// 捕获任何非标准异常std::cerr << "utf16LE_to_gbk() Unknown exception occurred." << std::endl;return false;}
}
3 GBK(ANSI) 转 UTF-8
// GBK(ANSI) 转 UTF-8
bool gbk_to_utf8(const std::string& gbk_str, std::string& utf8_str) {try {// 计算 GBK 转换后的宽字符数并为其分配内存空间int len = MultiByteToWideChar(CP_ACP, 0, gbk_str.c_str(), -1, NULL, 0);if (len == 0) {return false;}wchar_t* wstr = new wchar_t[len + 1];memset(wstr, 0, (len + 1) * sizeof(wchar_t));// 将 GBK 转换为宽字符if (MultiByteToWideChar(CP_ACP, 0, gbk_str.c_str(), -1, wstr, len) == 0) {delete[] wstr;return false;}// 计算宽字符转换后的 UTF-8 编码字符数并为其分配内存空间len = WideCharToMultiByte(CP_UTF8, 0, wstr, -1, NULL, 0, NULL, NULL);if (len == 0) {delete[] wstr;return false;}char* utf8_chars = new char[len + 1];memset(utf8_chars, 0, len + 1);// 将宽字符转换为 UTF-8 编码if (WideCharToMultiByte(CP_UTF8, 0, wstr, -1, utf8_chars, len, NULL, NULL) == 0) {delete[] wstr;delete[] utf8_chars;return false;}// 将 UTF-8 编码的字符串赋值给输出参数utf8_str = utf8_chars;delete[] wstr;delete[] utf8_chars;return true;}catch (const std::exception& e) {// 捕获并处理任何标准异常std::cerr << "gbk_to_utf8() Exception occurred: " << e.what() << std::endl;return false;}catch (...) {// 捕获任何非标准异常std::cerr << "gbk_to_utf8() Unknown exception occurred." << std::endl;return false;}
}
4 UTF-8 转 GBK(ANSI)
// UTF-8 转 GBK(ANSI)
bool utf8_to_gbk(const std::string& utf8_str, std::string& gbk_str) {try {// 计算 UTF-8 转换后的宽字符数并为其分配内存空间int len = MultiByteToWideChar(CP_UTF8, 0, utf8_str.c_str(), -1, NULL, 0);if (len == 0) {return false;}wchar_t* wstr = new wchar_t[len + 1];memset(wstr, 0, (len + 1) * sizeof(wchar_t));// 将 UTF-8 转换为宽字符if (MultiByteToWideChar(CP_UTF8, 0, utf8_str.c_str(), -1, wstr, len) == 0) {delete[] wstr;return false;}// 计算宽字符转换后的 GBK 编码字符数并为其分配内存空间len = WideCharToMultiByte(CP_ACP, 0, wstr, -1, NULL, 0, NULL, NULL);if (len == 0) {delete[] wstr;return false;}char* gbk_chars = new char[len + 1];memset(gbk_chars, 0, len + 1);// 将宽字符转换为 GBK 编码if (WideCharToMultiByte(CP_ACP, 0, wstr, -1, gbk_chars, len, NULL, NULL) == 0) {delete[] wstr;delete[] gbk_chars;return false;}// 将GBK编码的字符串赋值给输出参数gbk_str = gbk_chars;delete[] wstr;delete[] gbk_chars;return true;}catch (const std::exception& e) {// 捕获并处理任何标准异常std::cerr << "utf8_to_gbk() Exception occurred: " << e.what() << std::endl;return false;}catch (...) {// 捕获任何非标准异常std::cerr << "utf8_to_gbk() Unknown exception occurred." << std::endl;return false;}
}
5 UTF-16LE(UNICODE)转 UTF-8
// UTF-16LE(UNICODE)转 UTF-8
bool utf16LE_to_utf8(const std::wstring& utf16LE_str, std::string& utf8_str) {try {// 计算宽字符转换后的 UTF-8 编码字符数并为其分配内存空间int len = WideCharToMultiByte(CP_UTF8, 0, utf16LE_str.c_str(), -1, NULL, 0, NULL, NULL);if (len == 0) {return false;}char* utf8_chars = new char[len + 1];memset(utf8_chars, 0, len + 1);// 将宽字符转换为 UTF-8 编码if (WideCharToMultiByte(CP_UTF8, 0, utf16LE_str.c_str(), -1, utf8_chars, len, NULL, NULL) == 0) {delete[] utf8_chars;return false;}// 将 UTF-8 编码的字符串赋值给输出参数utf8_str = utf8_chars;delete[] utf8_chars;return true;}catch (const std::exception& e) {// 捕获并处理任何标准异常std::cerr << "unicode_to_utf8() Exception occurred: " << e.what() << std::endl;return false;}catch (...) {// 捕获任何非标准异常std::cerr << "unicode_to_utf8() Unknown exception occurred." << std::endl;return false;}
}
6 UTF-8 转 UTF-16LE(UNICODE)
// UTF-8 转 UTF-16LE(UNICODE)
bool utf8_to_utf16LE(const std::string& utf8_str, std::wstring& utf16LE_str) {try {// 计算 UTF-8 转换后的宽字符数并为其分配内存空间int len = MultiByteToWideChar(CP_UTF8, 0, utf8_str.c_str(), -1, NULL, 0);if (len == 0) {return false;}wchar_t* wstr = new wchar_t[len + 1];memset(wstr, 0, (len + 1) * sizeof(wchar_t));// 将 UTF-8 转换为宽字符if (MultiByteToWideChar(CP_UTF8, 0, utf8_str.c_str(), -1, wstr, len) == 0) {delete[] wstr;return false;}// 将宽字符赋值给输出参数utf16LE_str = wstr;delete[] wstr;return true;}catch (const std::exception& e) {// 捕获并处理任何标准异常std::cerr << "utf8_to_unicode() Exception occurred: " << e.what() << std::endl;return false;}catch (...) {// 捕获任何非标准异常std::cerr << "utf8_to_unicode() Unknown exception occurred." << std::endl;return false;}
}
7 调用示例
int main()
{///* ANSI、UNICODE 和 UTF-8 编码互转 */std::string gbk_str;std::string utf8_str;std::wstring utf16LE_wstr;// GBK(ANSI) 转 UTF-16LE(UNICODE)gbk_to_utf16LE(gbk_string, utf16LE_wstr);setlocale(LC_ALL, "chs");std::wcout << utf16LE_wstr << std::endl;// UTF-16LE(UNICODE) 转 GBK(ANSI)utf16LE_to_gbk((wchar_t*)utf16LE_string, gbk_str);std::cout << gbk_str << std::endl;// GBK(ANSI) 转 UTF-8gbk_to_utf8(gbk_string, utf8_str);std::system("chcp 65001");std::cout << utf8_str << std::endl;// UTF-8 转 GBK(ANSI)utf8_to_gbk(utf8_string, gbk_str);std::cout << gbk_str << std::endl;// UTF-16LE(UNICODE)转 UTF-8utf16LE_to_utf8((wchar_t*)utf16LE_string, utf8_str);std::system("chcp 65001");std::cout << utf8_str << std::endl;// UTF-8 转 UTF-16LE(UNICODE)utf8_to_utf16LE(utf8_string, utf16LE_wstr);setlocale(LC_ALL, "chs");std::wcout << utf16LE_wstr << std::endl;return 0;
}
![[Paper Reading] Fusing Monocular Images and Sparse IMU Signals for Real-time Human Motion Capture](https://img2024.cnblogs.com/blog/1067530/202411/1067530-20241112154402566-173245872.png)