一、Hive的分区(十分重要)
1、分区是什么
答:我们可以把一个大的文件分隔成一个个小的文件,这样每次操作一个小文件就很方便了
2、为什么要进行分区
答:通过分区,当我们查询的时候,可以只扫描与条件相关的分区,这样做,避免了全局扫描,加快查询速度
1、静态分区(SP)
静态分区指的是,在我们将数据上传到hdfs上的时候,进行手动分区,例如
静态分区(单分区)
创建表时:
CREATE TABLE IF NOT EXISTS t_student (
sno int,
sname string
) partitioned by(grade int)
row format delimited fields terminated by ',';
与平常建表不同,在静态分区建表的时候需要指定字段,但是这个字段不能和表字段相同
将数据放到hdfs上的时候,需要指定分区
load data local inpath '/usr/local/soft/bigdata32/data/stu1.txt' into table t_student partition(grade=1);
load data local inpath '/usr/local/soft/bigdata32/data/stu2.txt' into table t_student partition(grade=2);
load data local inpath '/usr/local/soft/bigdata32/data/stu3.txt' into table t_student partition(grade=3);
load data local inpath '/usr/local/soft/bigdata32/data/stu4.txt' into table t_student partition(grade=5);
将stud1的数据放到grade1这个分区中去...
2、静态分区(多分区)
create table if not exists t_teacher (
tno int,
tname string
) partitioned by(grade int,clazz int)
row format delimited fields terminated by ',';
指定多个分区字段
向hdfs上载入数据
load data local inpath '/usr/local/soft/bigdata32/data/t1.txt' into table t_teacher partition(grade=1,clazz=1);
load data local inpath '/usr/local/soft/bigdata32/data/t2.txt' into table t_teacher partition(grade=1,clazz=2);
load data local inpath '/usr/local/soft/bigdata32/data/t3.txt' into table t_teacher partition(grade=1,clazz=3);
load data local inpath '/usr/local/soft/bigdata32/data/t4.txt' into table t_teacher partition(grade=2,clazz=1);
load data local inpath '/usr/local/soft/bigdata32/data/t5.txt' into table t_teacher partition(grade=2,clazz=2);
需要指定两个分区编号,相当于嵌套关系
3、查询语句
select count(*) from t_student where grade=1
查看分区
show partition t_teacher;
2、动态分区(DP)
什么是动态分区?
答:动态分区通过数据来进行判断,并且动态分区只有在sql执行时才能决定
1、开启动态分区
设置能够进行动态分区
set hive.exec.dynamic.partition=true;
将分区改为不严格的
set hive.exec.dynamic.partition.mode=nonstrict;
2、构建动态分区
--创建分区表
CREATE TABLE IF NOT EXISTS t_student_d (
sno int,
sname string
) partitioned by (grade int,clazz int)
row format delimited fields terminated by ',';
--创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS t_student_e (
sno int,
sname string,
grade int,
clazz int
)
row format delimited fields terminated by ','
location "/bigdata29/teachers";
数据:
1,xiaohu01,1,1
2,xiaohu02,1,1
3,xiaohu03,1,1
4,xiaohu04,1,2
5,xiaohu05,1,2
6,xiaohu06,2,3
7,xiaohu07,2,3
8,xiaohu08,2,3
9,xiaohu09,3,3
10,xiaohu10,3,3
11,xiaohu11,3,3
12,xiaohu12,3,4
13,xiaohu13,3,4
14,xiaohu14,3,4
15,xiaohu15,3,4
16,xiaohu16,4,4
17,xiaohu17,4,4
18,xiaohu18,4,5
19,xiaohu19,4,5
20,xiaohu20,4,5
21,xiaohu21,4,5
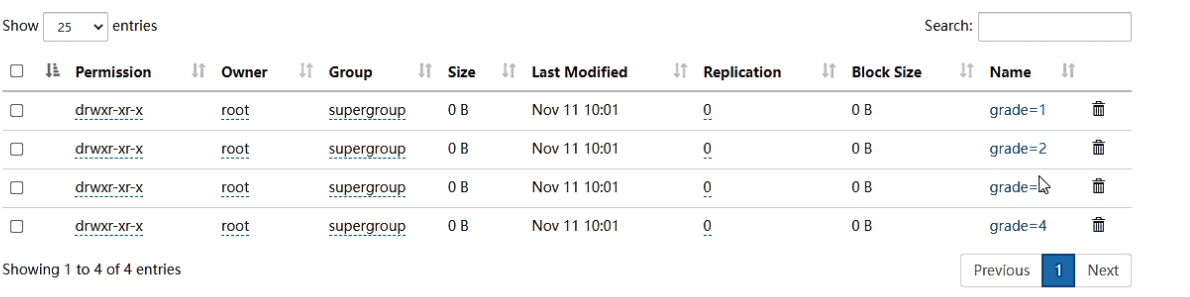
指定分区字段
insert overwrite table t_student_d partition (grade,clazz) select * from t_student_e;
结果会将数据自动的进行分区
3、动态分区的优缺点
优点:不用手动指定了,自动的会对数据进行分区
缺点:可能会发生数据倾斜
二、Hive的分桶
1、什么是分桶
答:分桶是将一个大的文件分成一个个小的文件进行存储
2、分桶的原理
答:对列进行哈希,然后除以桶的个数进行取余,这样就决定了数据该放在哪个桶里
3、进行分桶的操作
1、先开启分桶的支持
set hive.enforce.bucketing=ture;
2、创建一个表
create table person
(
id int,
name string,
age int
)
row format delimited
fields terminated by ',';
3、将数据导到这张表中去
load data local inpath '/usr/loacl/soft/bigdata32/data/1.txt' into table person;
4、创建分桶表
create table psn_bucket
(
id int,
name string,
age int
)
clustered by(age) into 4 buckets
row format delimited fields terminated by ',';
5、将数据insert到分桶表中去
insert into psn_bucket select * from person;
三、Hive JDBC
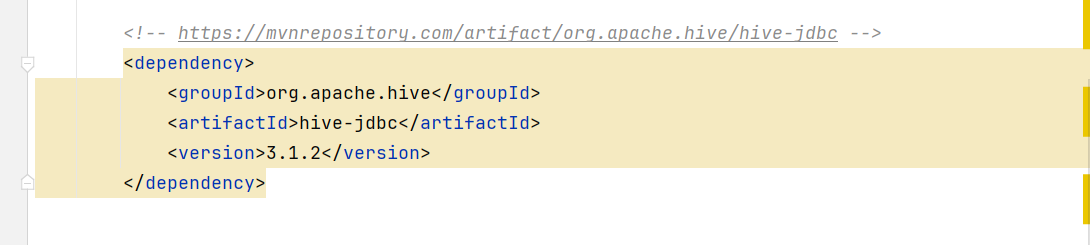
1、新建maven项目并导入依赖
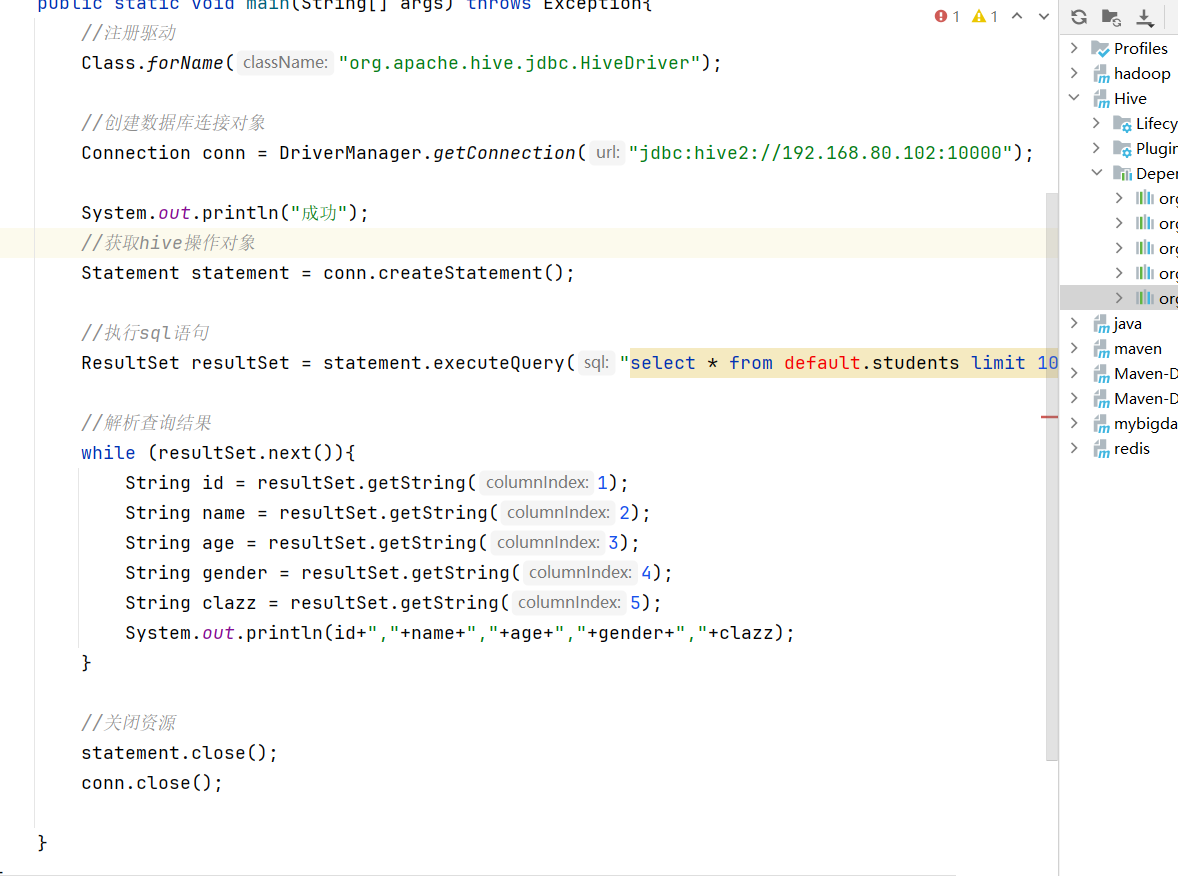
2、编写JDBC
四、Hive查询语句
1、全局排序
order by 就是全局排序,因此只有一个reduce,会导致当数据规模较大的时候,查询结果过慢
order by 后面可以跟 参数,如果不跟就默认为升序,如果加上desc就表示降序
2、局部排序
sort by 是在数据进入reduce之前进行排序,他只能保证数据局部有序
设置reduce的个数
set mapreduce.job.reduces=3;
查看reduce的个数
set mapreduce.job.reduce;
分区排序
distribute by
根据指定的字段将数据分到不同的reducer
一般结合sort by使用,但是要在sort by之前
分区并排序
cluster by 只能默认升序,不能使用倒序
能确保将指定列具有相同值的行分组在一起
五、Hive的内置函数
进多出一
select *,concat_ws(':',collect_set(列名))as 别名 from 表名 group by id;
进一出多
需要对一个数据进行拆分
select explode(split(列名,“数据分隔符”)) from 表名
lateral view 表生成函数,可以将explode的数据生成一个列表
数据:
1,这个杀手不太冷,剧情-动作-犯罪
2,七武士,动作-冒险-剧情
3,勇敢的心,动作-传记-剧情-历史-战争
4,东邪西毒,剧情-动作-爱情-武侠-古装
5,霍比特人,动作-奇幻-冒险
通过如下sql将数据变成下面的形式(将一列变成多行)
select id,name from t_movie1 lateral view explode(split(types,"-")) typetable as type;
1,这个杀手不太冷,剧情
1,这个杀手不太冷,动作
1,这个杀手不太冷,犯罪
2,七武士,动作
2,七武士,冒险
2,七武士,剧情
3,勇敢的心,动作
3,勇敢的心,传记
3,勇敢的心,剧情
3,勇敢的心,历史
3,勇敢的心,战争
4,东邪西毒,剧情
4,东邪西毒,动作
4,东邪西毒,爱情
4,东邪西毒,武侠
4,东邪西毒,古装
5,霍比特人,动作
5,霍比特人,奇幻
5,霍比特人,冒险
就是这在id,name字段后面再加上拆分出来的数据