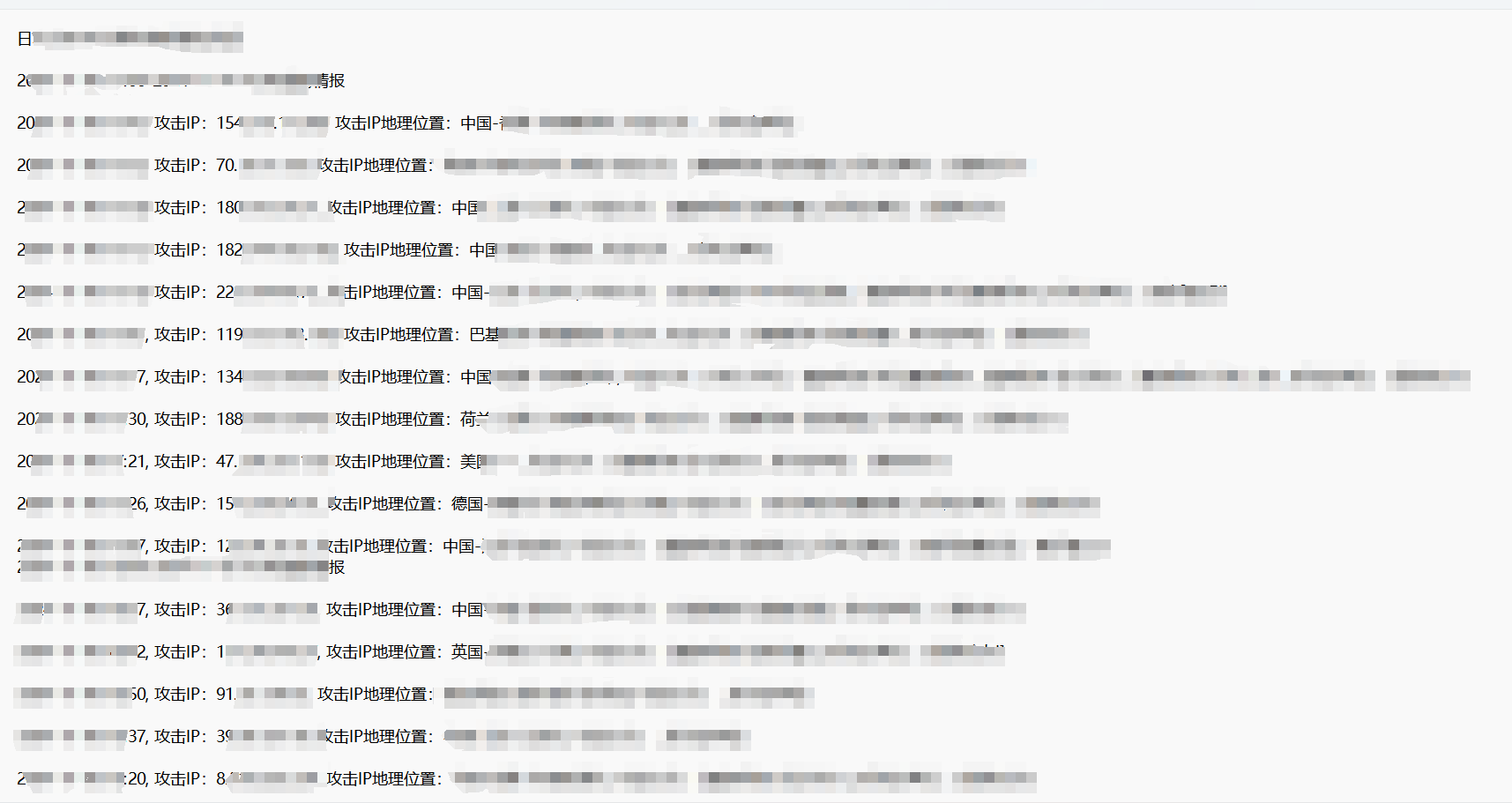
题目:我有一个日志文件如图所示,我要取出文件中所有的IP地址,以方便我将其加入到防火墙的黑名单中
代码中所用到的正则表达式介绍:
python使用的正则表达式是:
对该正则表达式的解释:
\b(?:\d{1,3}\.){3}\d{1,3}\b
\b:单词边界。确保IP地址前后不与其他字符连接。(?:\d{1,3}\.):非捕获型分组。匹配1到3个数字,后跟一个点号。{3}:前面的非捕获型分组重复3次,即匹配3个数字和3个点号。\d{1,3}:匹配1到3个数字。\b:单词边界。确保IP地址前后不与其他字符连接。
shell命令行的awk命令使用的正则表达式是:
对该正则表达式的解释:
[0-9]{1,3}+\.[0-9]{1,3}+\.[0-9]{1,3}+\.[0-9]{1,3}+
[0-9]:表示匹配数字0到9之间的任意一个字符。{1,3}:表示前面的字符可以重复出现1到3次。这里用于匹配每个数字段(每个IP地址由四个数字段组成)。\.:表示匹配点号字符".",需要使用转义符"\"。+:表示前面的字符可以重复出现1次或更多次。
python代码(其中涉及三种文件输入方式)
1 #处理文件并提取其中的IP地址,将结果输入到test1.txt文件中 2 import re 3 import sys 4 file_name = sys.argv[1] 5 f = open (file_name,"r",encoding='utf-8') 6 #使用方法:在命令行中使用python 1.py test.txt 7 #test.txt是需要处理的文件;1.py为我要操作的文件
8 9 #2、获取需要输入的文件名,并对输入的文件名进行处理。 10 #file_name = input("请输入需要处理的文件名:") 11 #f = open (file_name,"r",encoding='utf-8') 12 13 #3、直接在代码中输入文件名。 14 #f = open("test.txt", "r", encoding='utf-8') 15 16 data = f.readlines() 17 f.close() 18 f1 = open("test1.txt", "w", encoding='utf-8') 19 20 21 for line in data: 22 results = re.findall(r"\b(?:\d{1,3}\.){3}\d{1,3}\b", line) 23 for t in results: 24 25 26 27 #将结果写入到f1的文件中 28 f1.write(t + '\n') 29 f1.close()
处理结果,如图所示:
Linux 终端中使用 awk命令:
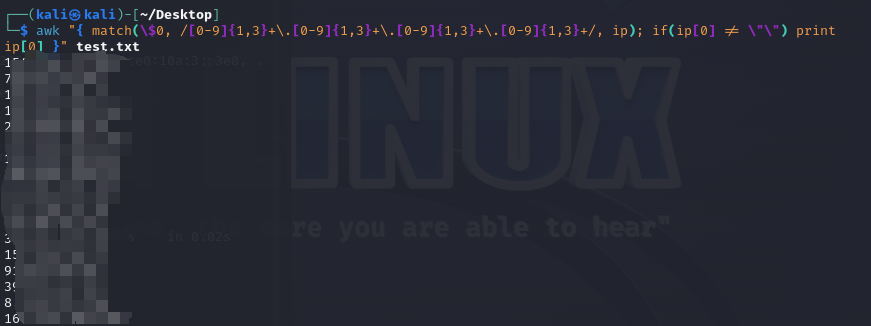
awk "{ match(\$0, /[0-9]{1,3}+\.[0-9]{1,3}+\.[0-9]{1,3}+\.[0-9]{1,3}+/, ip); if(ip[0] != \"\") print ip[0] }" test.txt
处理结果,如图所示: