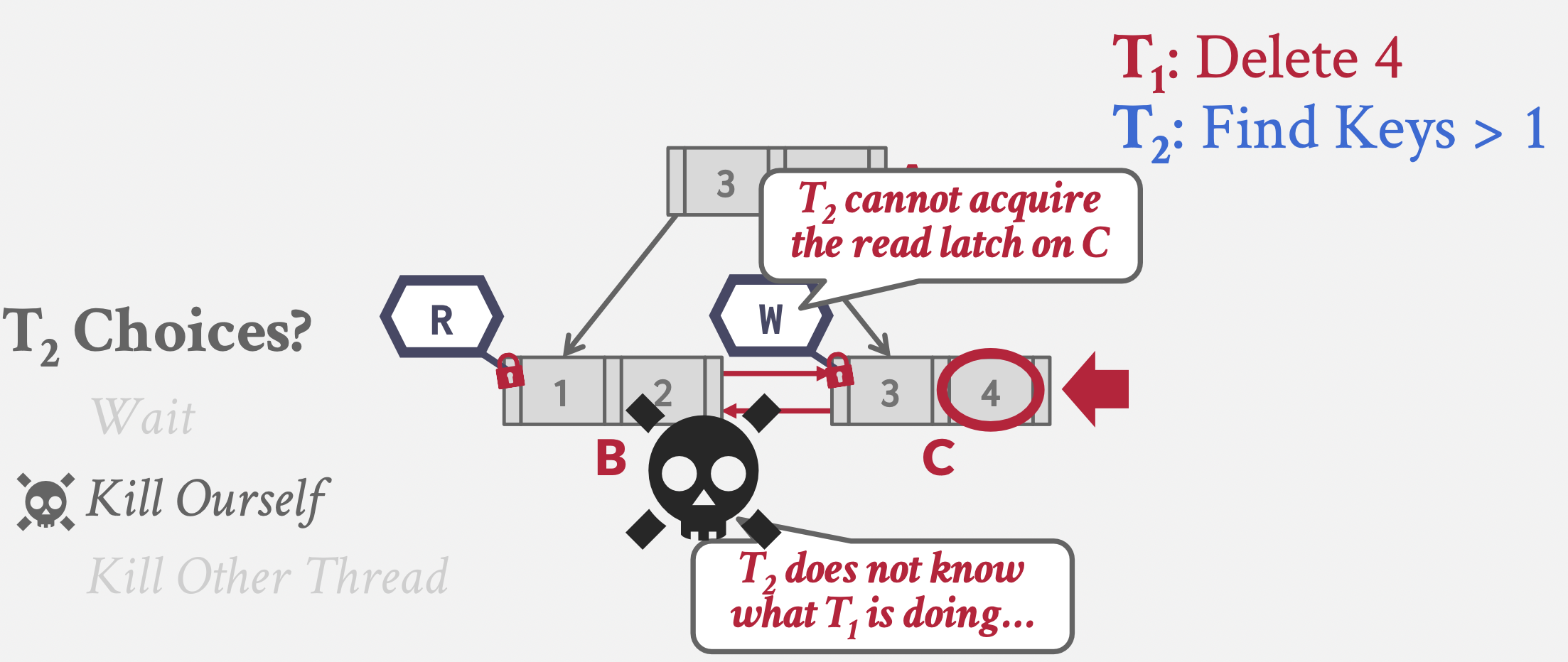
- 0 上节课回顾
- 0.1 闭包函数
- 0.2 装饰器
- 1 迭代器
- 2 三元表达式和列表推导式
- 2.1 三元表达式(三目表达式)
- 2.2 列表推导式
- 3 字典生成式
- 4 生成器
- 4.1 yield关键字
- 5 递归
0 上节课回顾
0.1 闭包函数
函数内部的变量无法被全局的相同名字的变量修改,局部变量和全局变量不是同一种东西
def f1():x = 1def f2():print(1,x)
x = 10f1()
print(2,x)
0.2 装饰器
user_dict = {'username':None}
def deco(func):def wrapper(*args,**kwargs):if not user_dice.get('username'):username = input('请输入用户名>>>')pwd = input('请输入密码>>>')if username == 'nick' and pwd == '123':print('登陆成功')user_dict['username'] = usernameres = func(*args,**kwargs)return resres = func(*args,**kwargs)return resreturn wrapper@deco
def shopping():print('please shopping!')
def withdraw():print('please withdraw!')
shopping()
withdraw()
1 迭代器
python中一切皆对象 学过的对象:
-
整形:height = 180 无
__iter__ -
浮点型:salary = 3.2 无
__iter__ -
字符串:name = 'nick' 有
name.__iter__() -
列表:hobby_list = ['run','read'] 有
hobby_list.__iter__() -
元组:hobby_tuple = ('run','read') 有
hobbu_tuple.__iter__() -
字典:info_dict = {'name':'nick','weight':140} 有
info_dict.__iter__() -
集合:hobby_set = {'read','run','sleep'} 有
hobby_set.__iter__() -
函数: 无
__iter__def func():pass -
文件:
f = open('text.txt','w',encoding = 'utf8') #w和a都会自动生成文件有f.__iter__()
只要有__iter__内置方法的对象就是可迭代对象,。。。
字符串/列表/元组/字典/集合/文件 均为可迭代对象
__next__就是在遍历可迭代对象,当遍历完就会报错
可迭代对象:拥有__iter__方法的对象 可迭代对象不一定是迭代器对象
迭代器对象:拥有__iter__方法,可迭代对象拥有__next__方法才是迭代器对象,迭代器对象一定是可迭代对象,文件本身就是迭代器对象
文件既是可迭代对象,又是迭代器对象
迭代器对象使用__iter__方法后是迭代器对象本身
2 三元表达式和列表推导式
2.1 三元表达式(三目表达式)
dog_name = 'fenggou'
if dog_name == 'fenggou':print('远离它')
else:print('盘它')
# 等价于 (但不推荐使用,不容易看懂)
print('远离它') if dog_name == 'fenggou' else print('盘它')
2.2 列表推导式
list = list()
for i in range(100):list.append(i)
print(list)
# 等价于 记住:傻逼采用的玩意
lis = [i for i in range(100)]
print(lis)lis = [i*2 if i>50 else i for i in range(100)]
3 字典生成式
dic = {i:i**2 for i in range(10)}
for i in dic.items():print(i)res = zip('abcd',[1,2,3,4])
for k,v in res:print(k,v)
# 终极版 字典生成式 + zip拉链函数
res = zip('abcd',[1,2,3,4])
dic = {k:v for k,v in res}
print(dic) #输出结果:{'a': 1, 'b': 2, 'c': 3, 'd': 4}
#区别于fromkeys
dic = dict.fromkeys('abcd',[1,2,3,4])
print(dic) #输出结果:{'a': [1, 2, 3, 4], 'b': [1, 2, 3, 4], 'c': [1, 2, 3, 4], 'd': [1, 2, 3, 4]}
4 生成器
生成器:自定义的迭代器
4.1 yield关键字
接收值,但不会结束函数,二十继续运行下一行代码,出现yield后不会再返回值,全被接受了,举个例子
def func():print(1)print(2)print(2)
func() #会输出 1 2 2
#但若变成
def func():print(1)yield 1,2,4print(2)yieldprint(2)
func() #就不会再输出值了,而是变成了一个迭代器,即直接用__next__来进行迭代,可进行下面操作
g = func()
for i in g:print(i) #输出1 (1, 2, 4) 2 None 2# 注意 :此时yield后面是可以接收值得,默认为None,也可以接收多个值以元组形式储存
注意:函数本身不是可迭代对象,但在调用之后就成了迭代器
yield:接收值,但不会结束函数,然后继续下一行代码,直到return
return:返回值,直接结束函数,其他特性和yield一摸一样
5 递归
递归:函数调用函数自己 (重复 函数嵌套)
def f1():print('from f1')f1()
f1()
def guess_age(count):count -= 1if count == 1:return 26return guess_age(count) + 2
res = guess_age(5)
print(res) # 32