在科技蓬勃发展的时代浪潮中,人工智能领域的每一次突破都离不开持续的科研投入和对前沿技术的不懈探索。2023 年,网易伏羲与中国计算机学会(CCF)共同发起了 “CCF - 网易雷火联合基金”,致力于发挥和利用多方资源优势,加强与海内外青年学者的科研合作,促进中国人工智能等领域尖端技术产业的进步,并加快校企合作、技术成果转化落地。
自成立以来,CCF-网易雷火联合基金始终致力于推动科研成果的转化与应用,受到了学者们的广泛关注与支持。在 2024 中国计算机大会(CNCC2024)上,CCF - 网易雷火联合基金首批优秀成果重磅发布。浙江大学软件学院百人计划研究员王皓波老师作为基金优秀代表,现场分享了其在基金资助下的课题成果《基于大小模型协同的低资源标注技术》,该技术通过整合大模型与小模型的优势,为解决数据标注中的低资源困境提供了全新思路,有望在提升标注效率和质量方面带来显著突破,助力人工智能产业实现更高效的数据驱动发展。
以下为王皓波老师的演讲实录:
大家好!非常荣幸能够在这里,作为CCF - 网易雷火基金资助项目的成果代表,与大家分享我们在基于大小模型协同的低资源数据标注技术领域的研究成果。我是浙江大学的王皓波。
如果将AI算法比作“火箭”,那么数据标注就是推动AI的“燃料”,对训练模型、提高准确率至关重要。在当前竞争激烈的AI市场,数据标注的效率和质量将直接影响企业和组织的AI应用效果和竞争力。
另一方面,OpenAI发布的ChatGPT等大模型掀起了一轮研究热潮。结合了超大规模的模型、数据和算力,大模型初步涌现了通用智能,对众多行业形成广泛的应用潜力。随着大模型的发展,数据标注也有了新机遇。首先,大模型在垂直领域的应用更需要大量的标注数据,以实现大模型的领域微调。其次,大模型内蕴的通用知识,能够以低成本构建高质量数据,在数据标注领域将会带来新的可能性和突破口。
在国内外,以网易有灵众包平台为代表的多款产品已将大模型融入标注的过程中。然而,面对垂直领域的产业需求时,通用大模型往往难以直接输出标注结果,这些标注产品仍需大量借助人类知识进行数据的标签、校验和修复。
在这样的背景下,我们的研究聚焦于如何利用大模型的强大能力,结合小模型的优势,实现低资源条件下高效、精准的数据标注。我们的研究得到了CCF - 网易雷火联合基金的大力支持,这为我们在该领域的探索提供了坚实的保障。
我们在数据标注技术方面的研究是一个逐步深入、演进的过程,下面将与大家具体分享。
阶段一:鲁棒噪声标签学习(IJCAI 2023)
首先,我们在鲁棒噪声标签学习方面开展了工作。
在机器学习中,噪声标签问题无处不在,其来源广泛,如机器生成标注数据时的不准确性以及众包标注者经验不足等。经典的噪声标签学习算法存在一定局限性,例如样本选择 - 自训练算法虽能通过特定方式筛选样本并进行半监督学习,但仅利用少量正确样本难以达到理想效果。
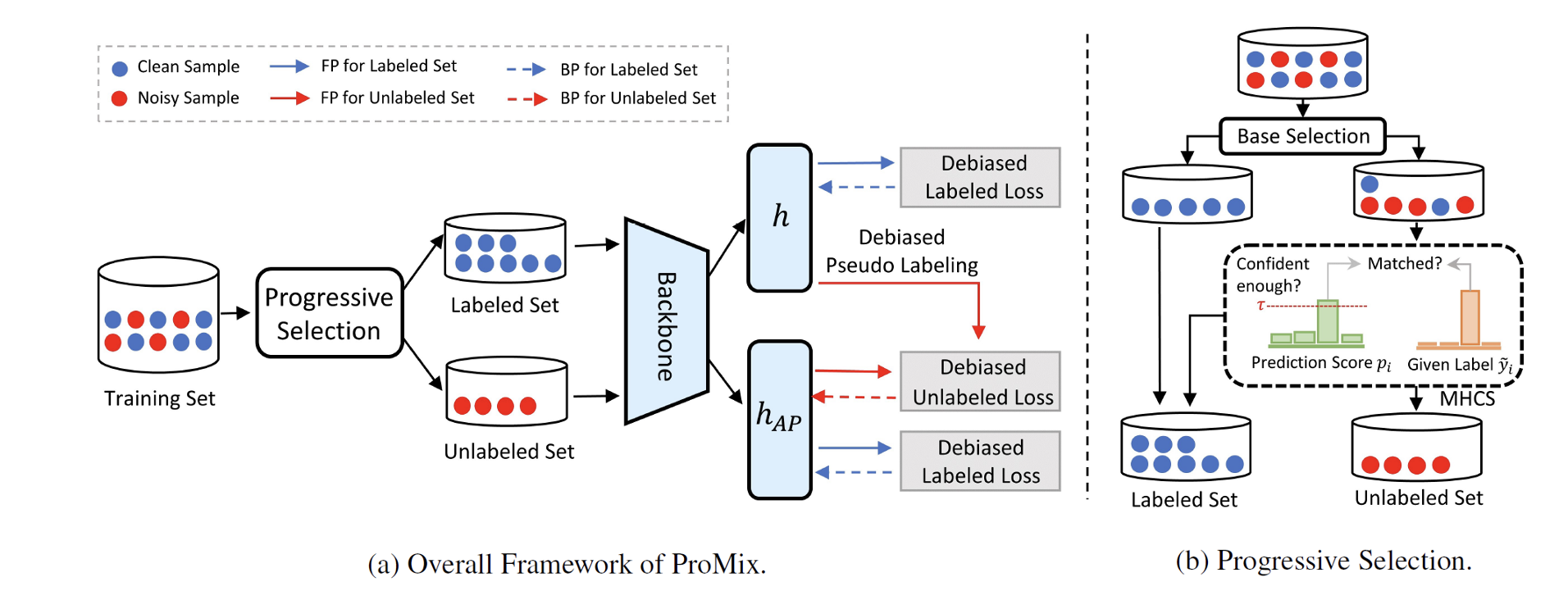
基于此,我们在IJCAI 2023上提出了ProMix算法,该算法通过创新的progressive selection方式,充分利用干净样本,在样本选择过程中先选择平衡子集,再依据置信度逐步扩大样本集。同时,算法中的样本选择和半监督学习模块有效解决了样本不平衡问题,在合成数据集和不平衡噪声样本数据集上都取得了卓越成绩,成功夺得首届IJCAI - 噪声标签学习挑战赛全赛道冠军。
阶段二:大小模型协同数据标注(EMNLP 2023)
随着大模型时代的到来,我们进一步思考如何将大模型与小模型协同应用于数据标注领域。这促使我们开展了FreeAL框架的研究,并发表于EMNLP 2023。
在这个阶段,我们发现传统弱标签学习存在诸多局限,如人工成本难以降低、机器标注精度不足以及小样本学习领域泛化能力较差等问题。FreeAL框架旨在实现无人工主动学习,其核心原理是充分发挥大模型(LLM)和小模型(SLM)各自的优势。大模型具有丰富知识储备,虽难以独立激活任务相关能力,但可通过生成样例进行初始标注,利用其强大的生成能力构造上下文学习样例,从而提高初始标注准确率。随后,小模型进行鲁棒蒸馏,挑选出弱监督训练中损失较小的样本,通过半监督学习进一步筛选出干净样本和噪声样本,并将其反馈给大模型。大小模型通过协同训练,不断迭代优化标注结果,直至性能收敛。
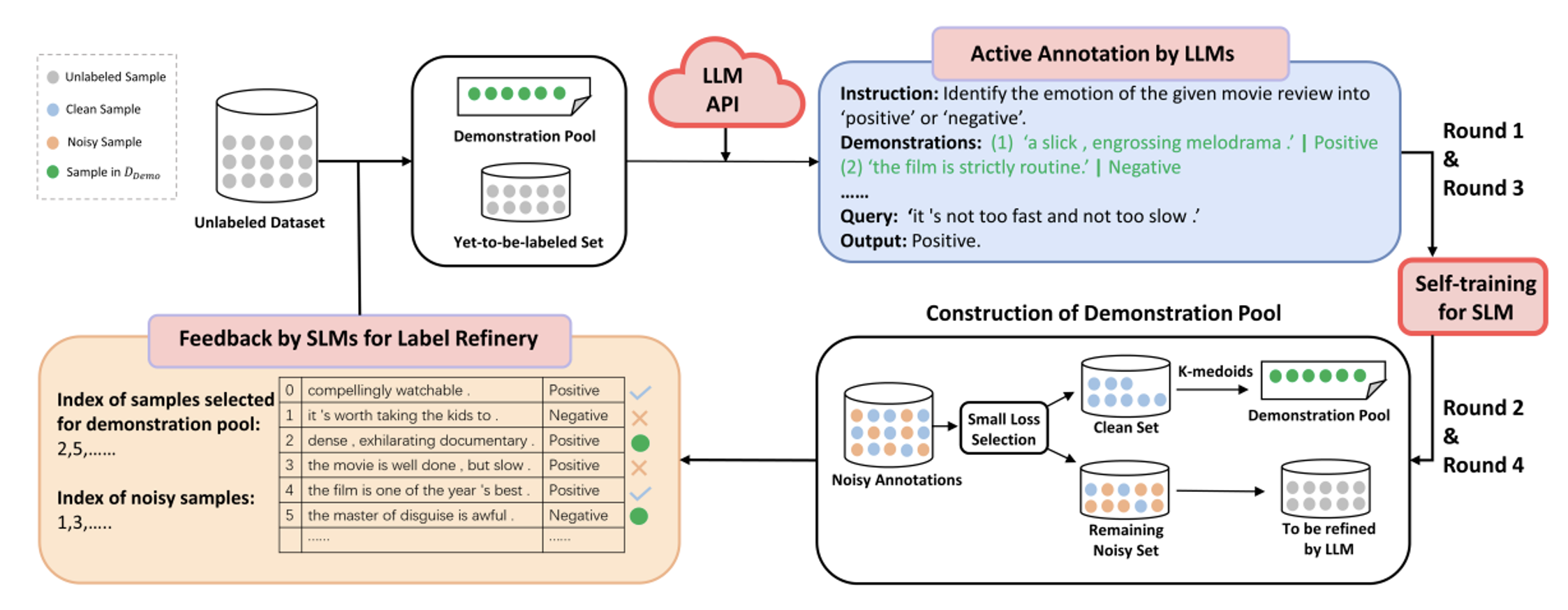
FreeAL 总体框架
1.大模型标注
在提升大模型的少样本学习(few - shot)性能方面,关键在于获取充足的示例样本。因为此次研究设定为完全不依赖人类标注(Human - Free),在初始标注轮次,获取有效示例样本并非易事。为此,我们采用一种策略,即引导大模型自行生成演示(demo)样本。具体操作流程为,向 ChatGPT 明确告知标签的定义,并提供若干未标注样本作为参考示例,使大模型得以学习未标注文本的风格特征,进而生成与标签信息相符的样本。通过这种方式,我们成功构建了初始的上下文学习(ICL)示例集合,经实验发现,在部分数据集(如 SUBJ 数据集)中,该方法可使准确率显著提升 28 个百分点。在后续的标注轮次中,我们将依据小模型筛选后的结果来开展 ICL 操作,从而进一步优化标注效果。
2.小模型蒸馏
在小模型蒸馏阶段,我们运用了小损失选择(Small - Loss Selection)策略来挑选干净样本,并结合半监督学习技术开展噪声标记学习任务。对于熟悉弱监督学习领域的研究者而言,这种方法并不陌生。在小模型训练过程中,即便筛选出的 “干净样本” 集合中存在少量错误样本,对模型性能提升的影响也较为有限。然而,为了确保在上下文学习(ICL)过程中能够获得更为精准的演示样本集,我们基于损失值对样本进行逐类精心筛选,此操作旨在充分考虑样本的多样性,以增强样本集的代表性。最终,将筛选所得的样本反馈至大模型,以便对其进行修复与优化。鉴于我们在前期已实施了全量标注,经过两个轮次的迭代,模型基本能够收敛至理想状态,从而实现高效且准确的数据标注。
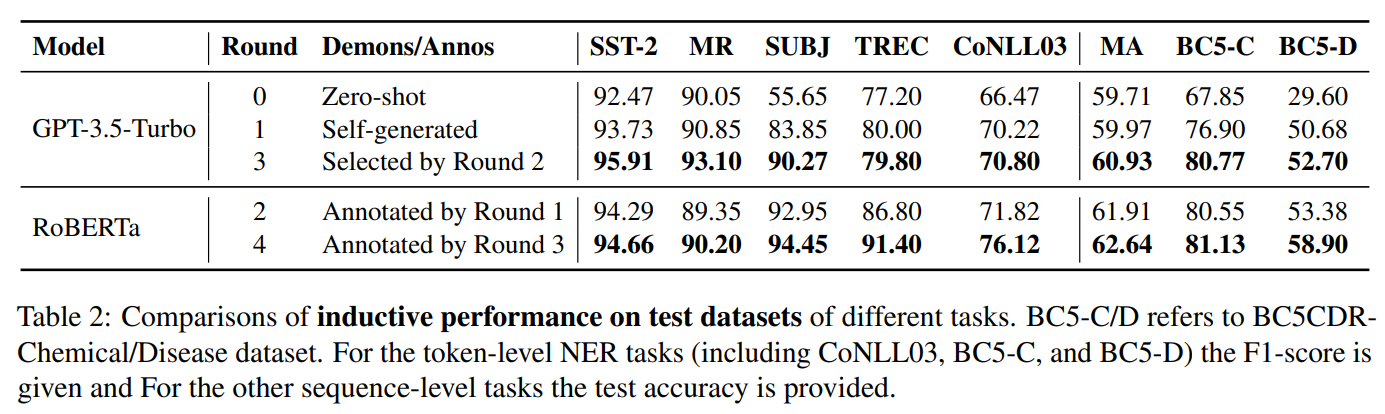
实验结果表明,FreeAL在多个任务上表现优异,其中一个引人注目的实验结果是,在涉及弱监督蒸馏得到的 RoBERTa 模型的实验中,仅当数据集为样本数量极少的 SST - 2 和 MR 时,ChatGPT 的表现优于 RoBERTa;而一旦数据集规模稍有增大,RoBERTa 执行上下文学习(ICL)的效果便超越了 ChatGPT。
进一步将 FreeAL 与传统的主动学习(AL)方法进行对比,发现在特定的一些数据集上,FreeAL 能够取得超越人类标注结果的卓越成绩。
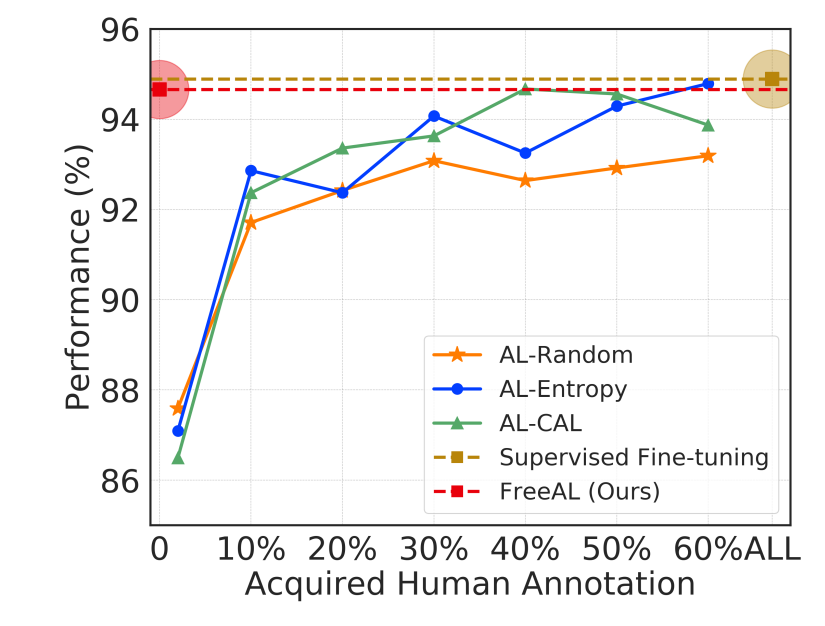
然而,我们也认识到,在实际生产环境中,仅依靠机器标注是不够的,标注过程离不开人类领域知识的支撑。
阶段三:基于大语言模型的协作式自动标注系统 CORAL(VLDB 2024)
基于FreeAL框架,我们进一步研发了CORAL框架,相关成果《CORAL: Collaborative Automatic Labeling System based on Large Language Models》成功入选VLDB 2024(文末扫码入群即可获取论文)。
CORAL框架提供了一种协作式自动标注原型系统,旨在减少人工参与并确保高质量的数据标注。通过结合大模型(LLM)和小模型(SLM)的协同工作,CORAL实现了初步的自动化标注流程,并以低成本提供可靠的标签数据,极大地降低了数据标注的时间和人工成本。
CORAL框架的工作流程包含大小模型协同标注体系、手动精炼模块和迭代过程控制器。其大小模型协同标注体系继承了FreeAL的优势,能够自动形成大量数据标注。手动精炼模块是CORAL的一大特色,它引入了人机协同的标注范式。通过网易有灵众包平台的用户界面,用户可以对标注结果进行审查,针对低置信度样本进行人工校正。这一模块使得用户能够专注于处理最具挑战性的样本,从而在有限的人工参与下有效提升标注数据的质量。迭代过程控制器则进一步增强了CORAL系统的有效性,它通过采集高置信度样本,不断优化大模型(LLM)和小模型(SLM)的标注精度,实现标签质量的持续改进。
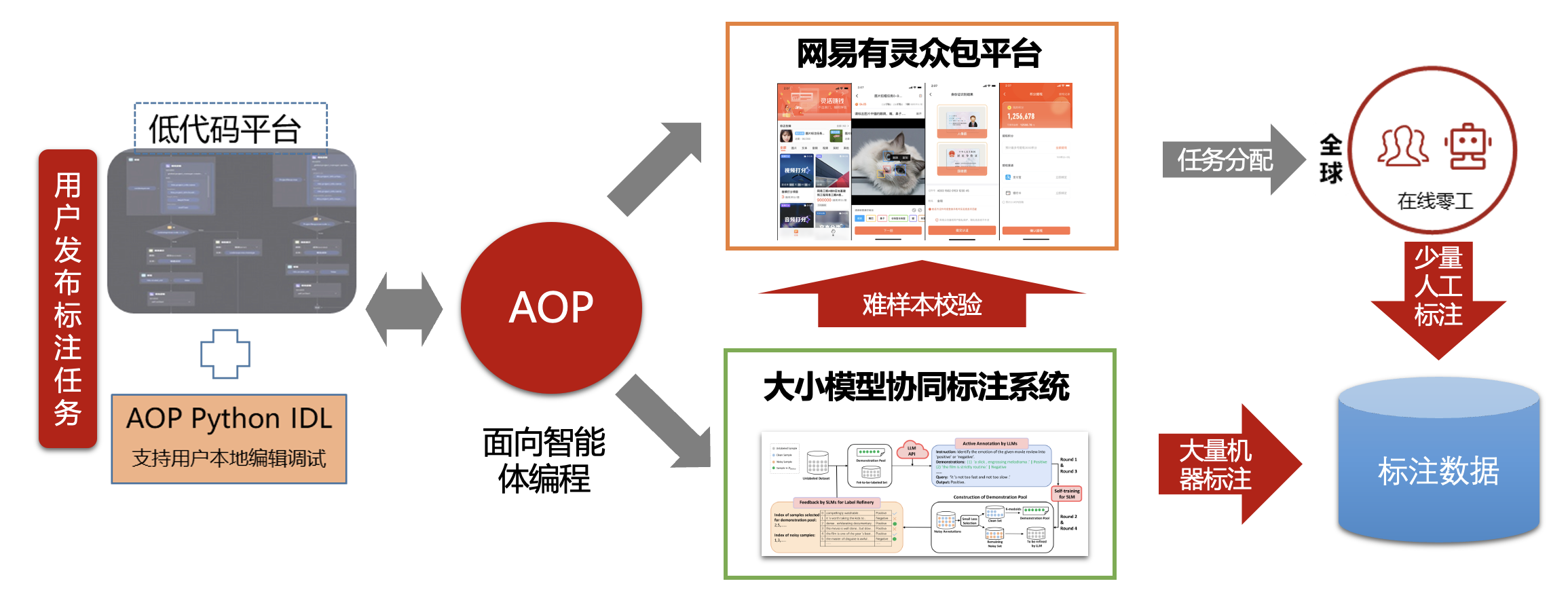
目前,我们正在探索将大小模型协同标注系统与网易有灵平台的AOP体系深度集成。在当前的标注环境中,尽管大模型和小模型的协同已经能够处理大部分简单的数据标注任务,但复杂样本仍需要人类的专业知识和精准判断。通过这种集成,我们期望构建一个更加高效、智能的人机协同Agent调度体系。在这个体系中,大小模型协同标注系统能够精准定位那些尚未得到妥善解决的样本,然后由网易有灵众包平台引入人工干预,进行人机协同标注。人类标注员凭借其专业知识和经验,对复杂样本进行处理,从而实现最佳标注结果。这不仅将提高数据标注的准确性和可靠性,还将推动数据标注技术在更广泛领域的应用,为人工智能技术的发展提供更强大的数据支持。
最后,再次感谢CCF - 网易雷火联合基金的支持,感谢网易伏羲提供的平台与合作机会,感谢团队成员的辛勤付出,也感谢各位嘉宾的聆听!希望我们的研究成果能够为数据标注领域的发展贡献一份力量,共同推动人工智能技术迈向新的高度。

扫码入群,获取《CORAL: Collaborative Automatic Labeling System based on Large Language Models》论文