- 概述
- 排序
- 堆排序
- 外部归并排序
- 使用索引
- 聚合操作
- 排序聚合
- 哈希聚合
概述

本节和下一节讨论具体的操作算子,包括排序,聚合,Join等。
排序
为什么需要排序操作:
关系型数据库是无序的,但是使用时往往需要顺序数据(Ordered By,G roup By,Distinct)。
主要矛盾:
- 磁盘很大:要排序的数据集很大,内存空间很小,所有数据不能一次装入内存,需要保留中间结果。
- 磁盘很慢:不能只看时间复杂度,要充分利用顺序IO。
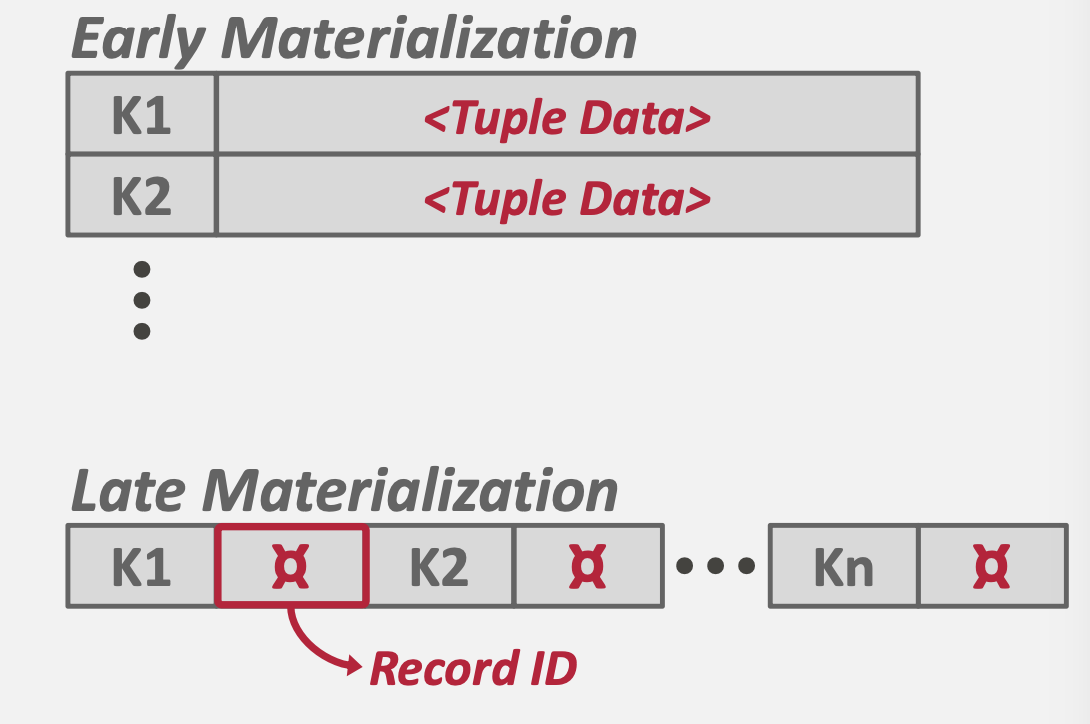
物化顺序:操作时是直接用具体数据,还是RecordID。
堆排序
如果排序时带有Limit参数,直接用堆排序即可。

外部归并排序
\(N\):总页数
\(B\):缓冲区容纳的页数
下图演示的是N=8,B=3的二路归并排序。
为了演示方便,Pass #0是指对一个页进行排序,得到8个分组,但是实际上可以一次对3个组排序,得到⌈8 / 3⌉ = 3组。
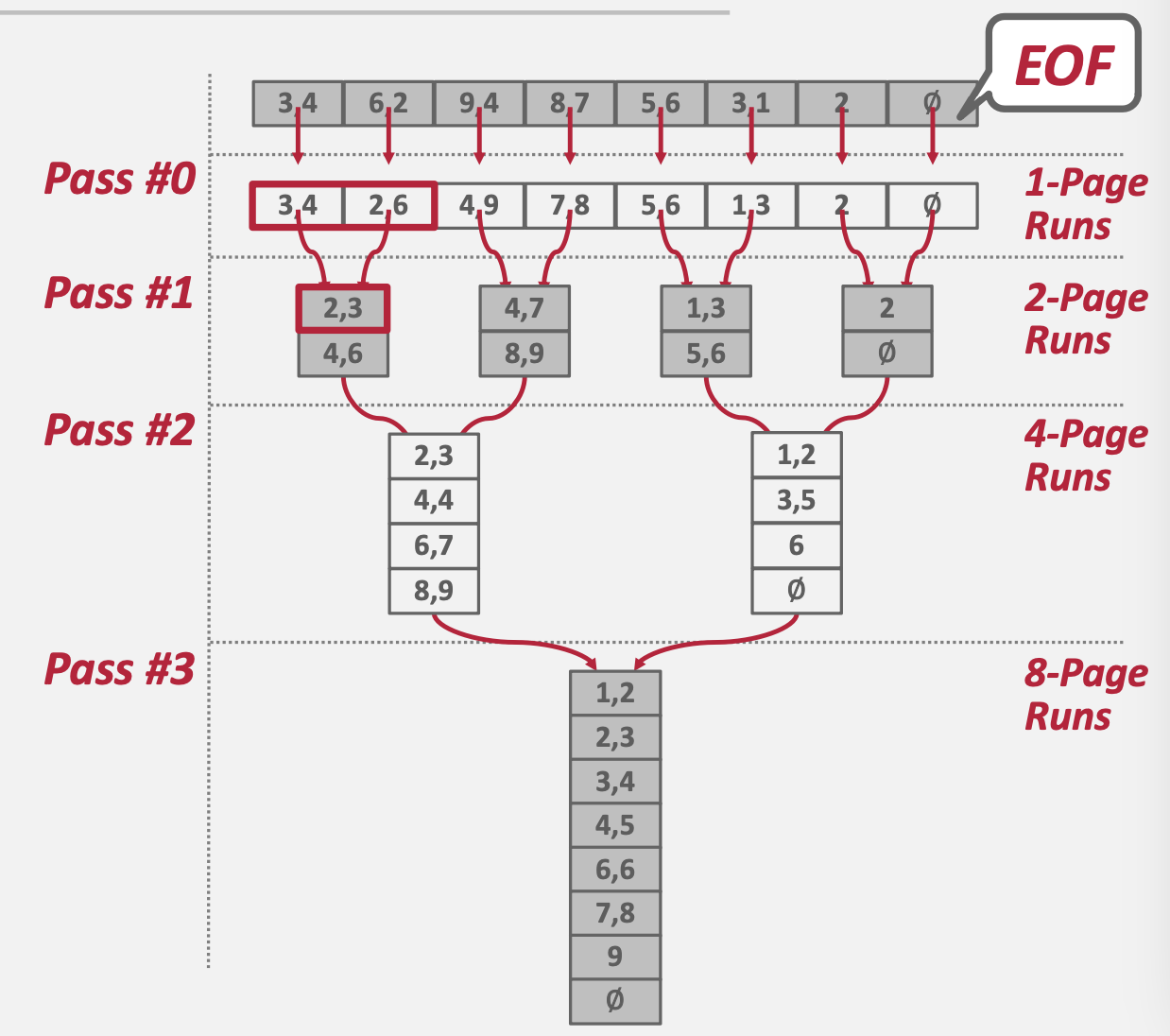
一般地,对于总页数为N,缓冲区为B的外部归并排序有:
-
分组数(Number of Runs):$⌈N / B⌉ $
-
轮数(Number of Passes): \(1 + ⌈ log_{B-1} ⌈N / B⌉ ⌉\)
-
总IO次数(Total IO Cost):\(2N · (\#\ of\ passes)\)
使用索引
上述的排序是基于没有索引时,直接扫描全表进行排序。
如果有索引,数据在索引上天然有序,可以利用索引。
- 聚簇索引:效果比上述的排序好
- 非聚簇索引:永远不是个好选择
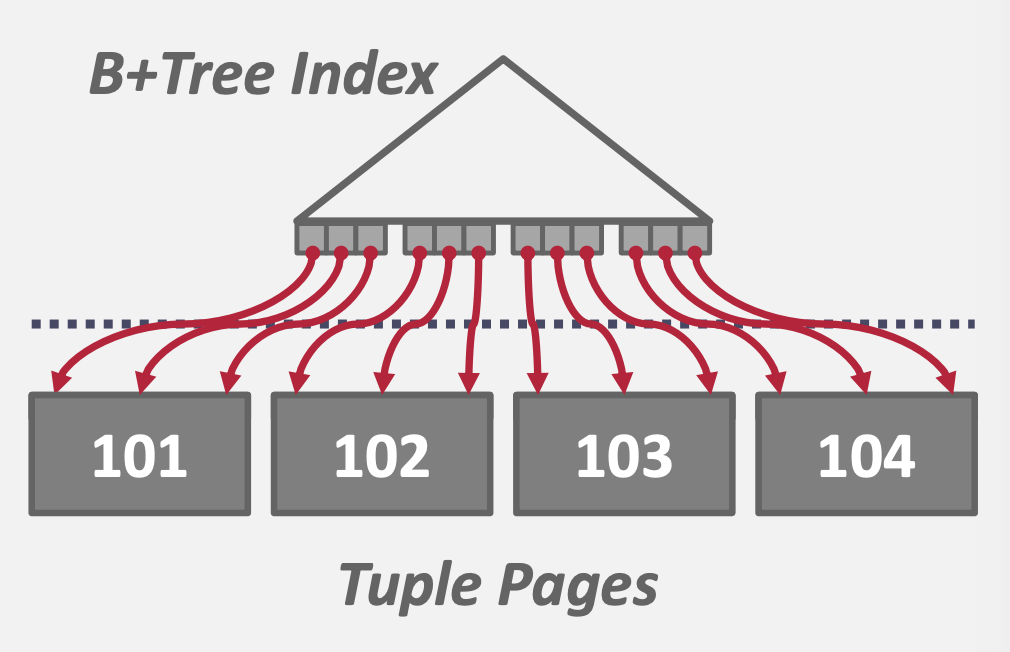
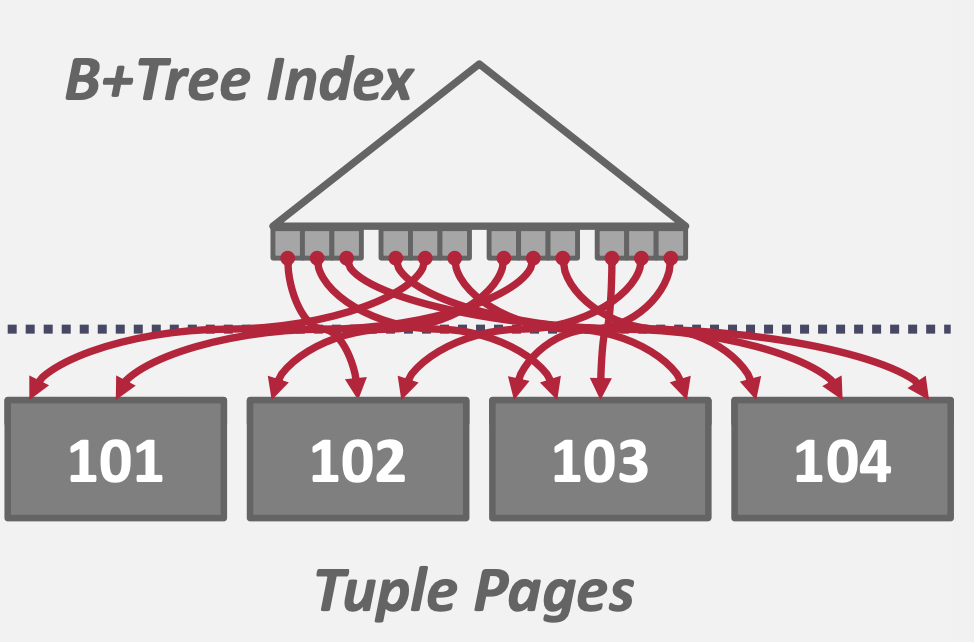
非聚簇索引虽然已经对数据排好序了,但是读取数据是随机IO,顺序读取全表然后进行排序的时间开销与之相比显得不那么沉重了。
聚合操作
怎么选择:如果SQL中有算子需要进行排序操作,如Group By,Distinct,可以采用排序聚合,否则采用哈希聚合。
排序聚合

哈希聚合
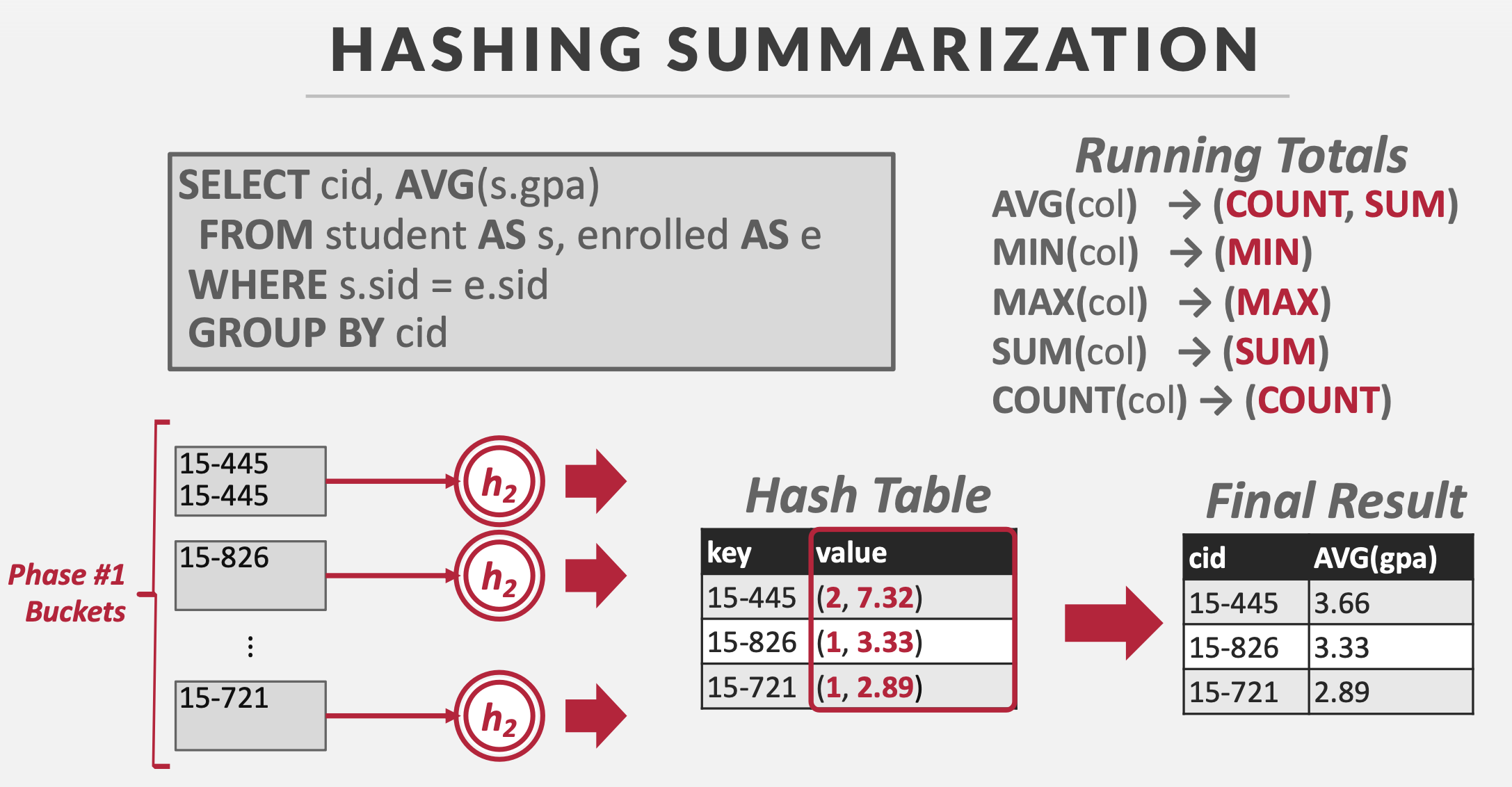
思路类似于Map-Reduce。
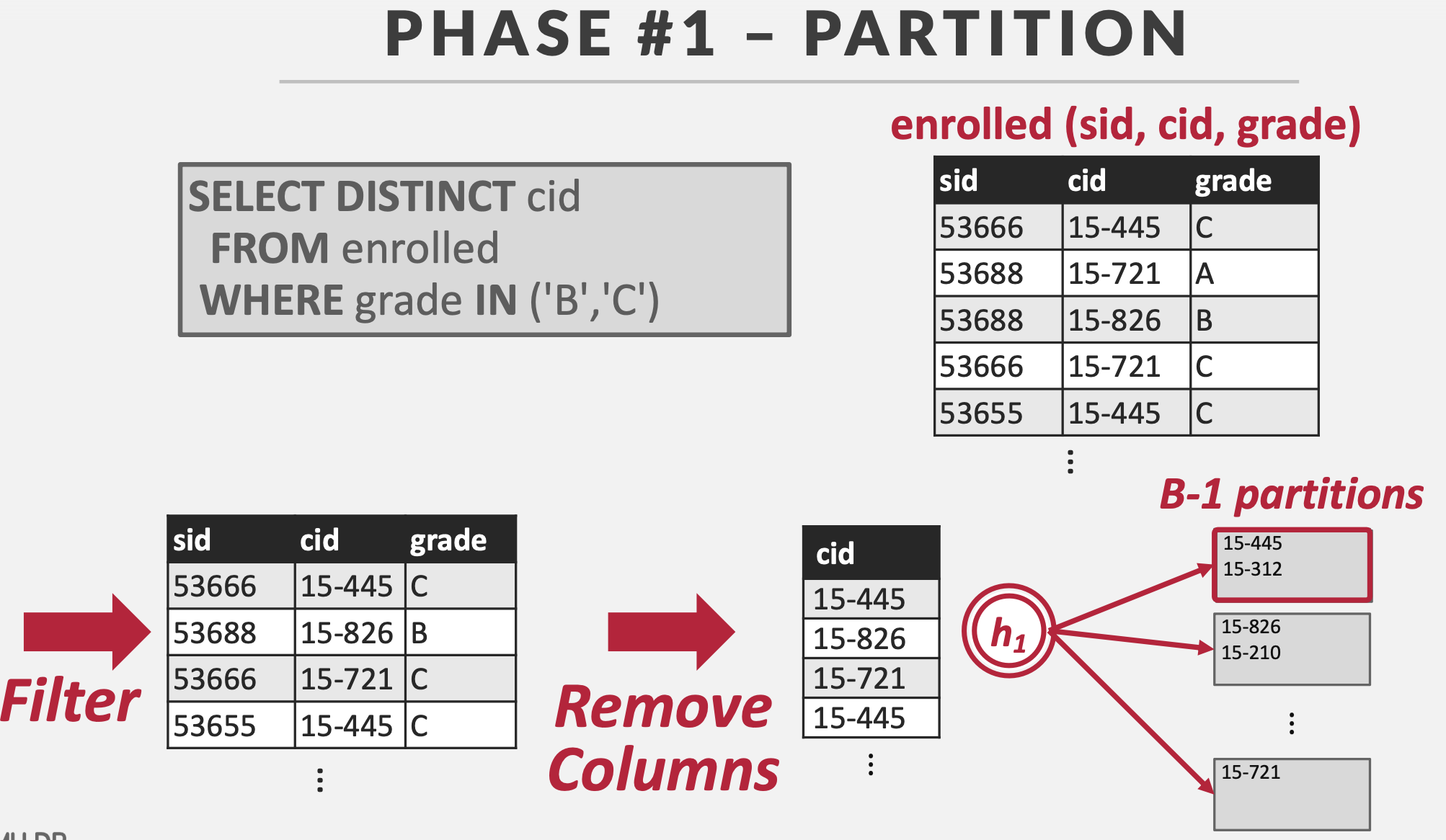
步骤1:分区
用哈希函数\(h_1\)将数据进行哈希,根据哈希key,将数据划分到不同的哈希桶(bucket),哈希桶是一个输出缓冲区。
在这个过程中,如果某个哈希桶写满了就落盘并刷新。
注意:同一个哈希桶中包含有相同哈希值的数据以及哈希碰撞数据。
如果缓冲区可以容纳\(B\)个页,1个页作为输入缓冲区,\(B-1\)个页作为哈希桶。
步骤2:ReHash
将每一个哈希桶读入内存
- 对桶中的数据用哈希函数\(h_2\)再进行一次哈希,得到的结果存放在Hash Table中
- 将Hash Table中的结果追加到结果集(Final Result)中
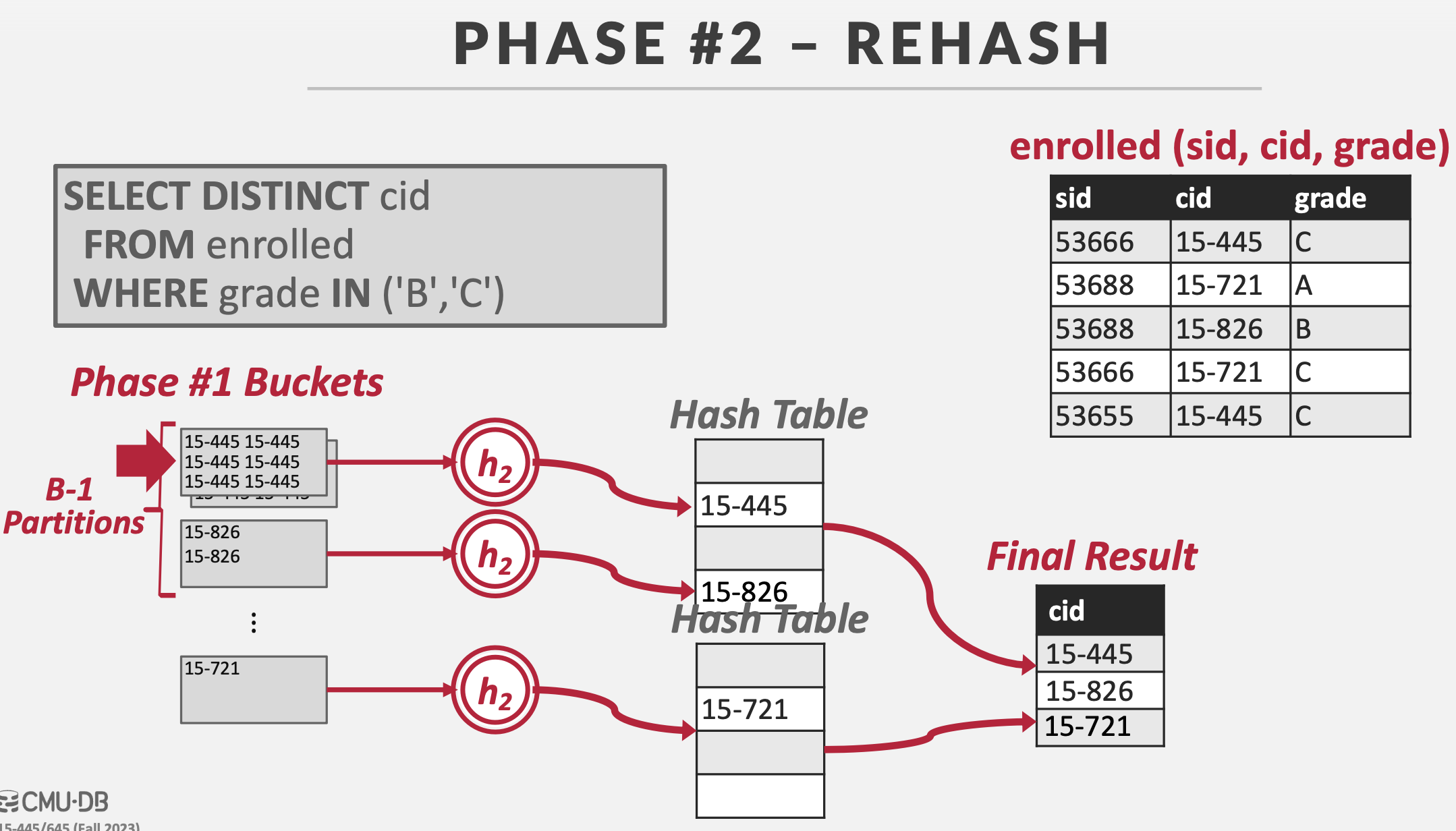
在ReHash的过程中,会维护一些运行时数据,操作的并不是一个哈希key,而是<GroupKey,RunningVal>操作对。
当要插入一个结果到Hash Table时:
- GroupKey已存在,更新GroupKey对应的RunningVal
- GroupKey不存在,添加<GroupKey, RunningVal>