1 并行编程简介
首先,我们将讨论允许在新计算机上并行执行的硬件组件,如 CPU 和内核,然后讨论操作系统中真正推动并行的实体:进程和线程。随后,将详细说明并行编程模型,介绍并发性、同步性和异步性等基本概念。
介绍完这些一般概念后,我们将讨论全局解释器锁(GIL)及其带来的问题,从而了解 Python 在这方面的特殊性,尤其是在线程方面。我们将提到标准的 Python 库模块,如线程和多处理,我们将在接下来的章节中更深入地介绍这些模块。最后,我们将通过讨论并行程序的评估方法(如加速和缩放)来结束本章,并讨论并行编程可能带来的问题(竞赛条件、死锁等)。
在本章结束时,你将理解并行编程背后的所有基本概念和术语。您将在脑海中构建一个总体方案,其中将包含并行执行的所有主角,以及他们是如何实现并行执行的。然后,您就可以着手处理后续章节中涉及的编程实践部分了。
内容:
- CPU 和内核
- 进程和线程
- 并行和并发编程
- 使用 Python 的 GIL 和线程
- 加速和扩展
1.1 并行编程
新硬件技术的出现让我们有机会在电脑上同时运行多个程序。事实上,我们的电脑,即使是最简单的电脑,都有一个多核系统,允许程序并行运行。那为什么不利用这种架构呢?
你经常会发现自己正在开发一个 Python 程序来执行一系列操作。在科学领域,经常需要实现一系列算法来进行非常费力的计算。但在工作结束后,在计算机上运行程序时,你会失望地发现,它并没有你希望的那么快,而且随着处理问题的规模增大,执行时间也变得过长。但这不仅仅是速度问题。如今,我们需要处理的数据量越来越大,与之相关的计算也越来越多,程序需要的内存资源也越来越大,而我们的计算机尽管功能强大,却无法处理这些数据。
并行编程可以同时执行一个程序的部分代码,从而大大提高性能。因此,并行编程意味着缩短程序的执行时间,更有效地利用资源,并能执行以前无法完成的更复杂的操作。
1.2 计算机和并行技术的发展
并行概念是随着计算机内部硬件的发展而逐步形成的。在 20 世纪 80 年代之前,计算机的功能非常有限:它们以严格的顺序方式,一条指令接一条指令地运行一个程序。显然,在这样的技术环境中,并行的概念甚至连想都不敢想。

随着英特尔 80386 处理器的问世,计算机有了中断一个程序的执行以执行另一个程序的可能性。因此,抢占式编程和时间分割等概念应运而生。这一技术进步带来了伪并行效果,因为用户可以看到多个程序同时运行。在随后的英特尔 80486 处理器中,通过引入基于将程序细分为子任务的流水线系统,情况得到了进一步改善。这些子任务在不同程序之间交替独立执行。此外,内部架构首次实现了将多个不同指令(甚至来自不同程序的指令)组合在一起,并同时(但不是同时)执行。这就是并发编程的真正发展。不同子任务的指令部分都已完成,以便尽快执行:
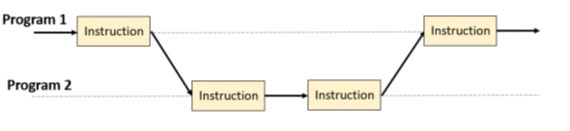
这种情况持续了十多年,功能越来越强大的处理器型号相继问世,工作频率比以前更高。但由于一系列问题和物理限制,这种情况很快就陷入了危机。提高执行频率意味着同时增加发热量和随之而来的能耗。显然,频率的提升很快就会达到极限。
就这样,处理器实现了创新的飞跃,在系统中引入了内核。这些内核也被称为逻辑处理器,可以在单个 CPU 中模拟多个处理器的存在,从而形成多核 CPU。实际上,多处理器计算机可以同时并行执行不同程序的指令。因此,在本世纪初,并行编程技术应运而生,为开发人员同时执行同一程序的不同部分提供了可能。
1.3 CPU、内核、线程和进程
Windows 中的任务管理器可以实时监控各种资源的消耗情况,如 CPU、内存和 Wi-Fi 网络:
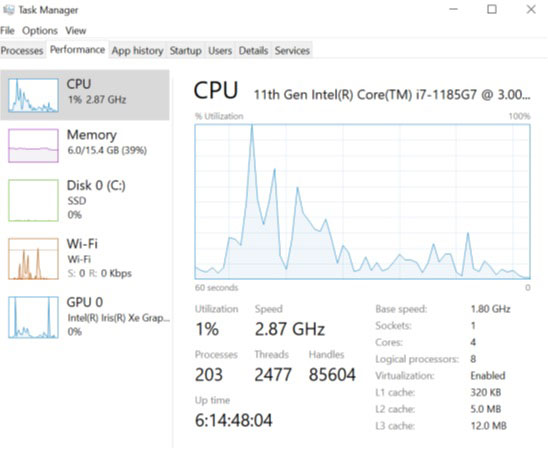
此外,任务管理器还显示了各种信息,如进程数和当前运行的线程数。右侧则列出了我们正在运行的系统的一些特征,如内核数。
如果你使用的是 Ubuntu 等 Linux 系统,则可使用top:
Linux 系统更灵活、更强大,特别是由于有大量的 shell 命令,我们还可以监控与每个命令相关的所有线程。为此,我们将使用更具体的命令来监控进程: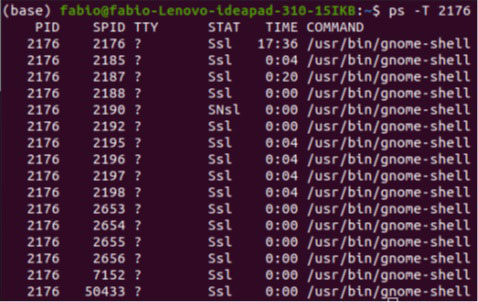
-T选项用于表示将显示与进程相关的线程。
中央处理器(CPU Central Processing Unit)是计算机的真正大脑,基本上是处理代码的地方。中央处理器以周期为特征,即中央处理器在处理器上执行操作所使用的时间单位。通常,我们用每秒周期频率来表示 CPU 的功率。
CPU 内部可以有一个内核(单核 CPU)或多个内核(多核 CPU)。内核是 CPU 中的数据执行单元。每个内核可运行多个进程。进程本质上是在机器上运行的程序,并为其预留部分内存。此外,每个进程还可以反过来启动其他进程(子进程),或在其中运行一个(主线程)或多个线程。
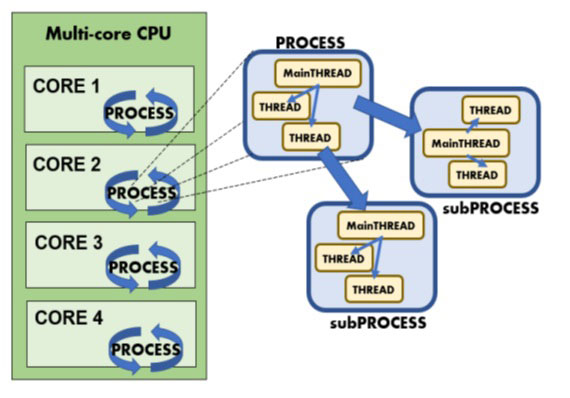
反过来,线程也可视为在单个处理器中并发运行的子进程。与进程一样,线程也有一系列类似的机制来管理它们的同步、数据交换和执行过程中的状态转换(就绪、运行和阻塞)。
这就是我们必须牢记的总体框架,以便更好地理解机器中的进程和线程是如何运行的,从而以最佳方式建立并行编程模型。
1.4 并发和并行编程
并发和并行经常被混淆,这两个术语被互换使用的情况并不少见,但这是不正确的。这两个概念虽然密切相关,但在并行编程中却有所不同,了解其中的区别非常重要。
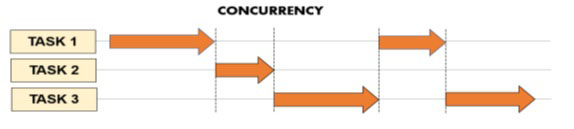
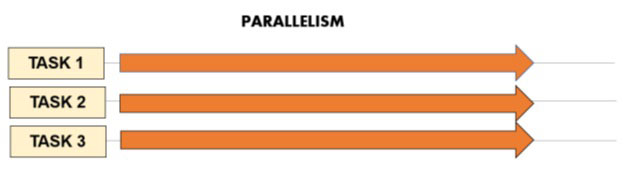
我们先来看看这两个概念的共同点。当我们的程序必须同时执行多个任务时,就会出现并发和并行。但这正是并发的含义。
并发意味着同时管理(而非执行)多个任务,但它们并不一定同时运行。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
1.5 Python 中用于并发和并行模型的线程和进程
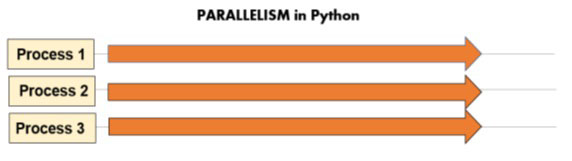
在了解了并发编程和并行编程的区别之后,让我们再进一步。在许多编程语言中,通常的做法是将线程与并发、进程与并行联系起来。事实上,操作系统的这两个实体包含了并发和并行这两种不同的功能。
然而,就 Python 而言,将这些情况分为两种不同的编程模型是不错的选择。事实上,Python 中的线程并不像操作系统中的线程那样表现完美。Python 中的线程不能并发运行,因此不能并行操作。在 Python 中使用线程就像是在使用单核 CPU,尽管事实并非如此。
1.5.1 Python 线程问题:GIL
与其他编程语言不同,Python 中的线程不能在两个不同的内核上同时执行,这与 Python 解释器本身密切相关。事实上,Python 代码一直运行的解释器是在 CPython 中实现的,在实现过程中,人们发现它并不是完全线程安全的。也就是说,越多的线程试图共同访问某个对象(线程之间共享内存),往往就会由于竞赛条件现象而陷入不一致的状态。为了避免这个大问题,解释器中加入了全局解释器锁 (GIL)。因此,Python 设计者选择在一个进程中,一次只能执行一个线程,从而消除了这种实体的并行性(无多线程)。
但情况并没有那么糟糕。事实上,稍后我们将看到如何在并行编程模型中调整 Python 语言线程的这一特性。此外,许多外部库并不依赖于 GIL,因为它们是用其他语言(如 C 和 Fortran)实现的,因此可以利用使用多线程的内部机制。NumPy 正是这些库中的一个,它是 Python 数值计算的基础库。
1.5.2 取消 GIL 以实现多线程计算
Python 3.13引入了一个名为"free-threaded"的实验性功能,允许在一定条件下选择性地关闭GIL。这为未来完全解除GIL奠定了基础。 即使启用了"free-threaded"功能,也并非所有场景下都能完全发挥多核CPU的性能。一些复杂的情况可能仍受到GIL的影响。
对于CPU密集型任务,使用多进程可以绕过GIL的限制,充分利用多核CPU。
将Python代码中的性能瓶颈部分用Cython编写,可以获得接近C语言的执行效率,同时又能享受Python的便利性。
如Jython、PyPy等,它们对GIL的处理方式不同,可能更适合某些特定的应用场景。
1.5.3 Python 中的线程与进程
| 特点 | 进程 | 线程 |
|---|---|---|
| 独立性 | 独立性高,一个进程崩溃不会影响其他进程 | 独立性较低,一个线程崩溃可能导致整个进程崩溃 |
| 资源开销 | 创建和销毁进程开销较大,资源消耗相对较高 | 创建和销毁线程开销较小,资源消耗较低 |
| 通信 | 进程间通信相对复杂,通常需要使用IPC机制 | 线程间通信相对简单,可以直接共享进程内存空间 |
| 切换开销 | 进程切换开销较大 | 线程切换开销较小 |
| 适用场景 | CPU密集型任务,独立的子任务,需要隔离的程序 | I/O密集型任务,需要共享数据的并发任务 |
1.5.4 Python 中的并发与并行
在 Python 中使用线程进行并发编程,这些线程各自独立执行任务,并相互竞争执行。
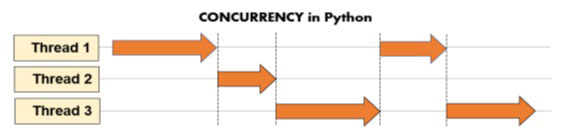
进程非常适合同时执行任务,即并行执行。
1.5.5 greenlet的轻并发(Coroutine 协程)
除了线程,Python 还提供了另一种可能的选择:greenlet。从竞争的角度来看,使用greenlet和线程是等价的,因为在 Python 中,线程从来都不是并行执行的,因此使用这种编程语言,两者都能完美地进行并发编程。但创建和管理小绿点所需的资源要比线程少得多。这就是为什么在编程中使用它们被定义为轻并发的原因。因此,当你需要管理大量简单的 I/O 功能(如网络服务器中的功能)时,通常会使用greenlet。我们将在本书后面通过几个简单的例子来了解如何创建和管理 greenlet。
| 特点 | 线程 | 协程 |
|---|---|---|
| 上下文切换 | 操作系统内核调度,开销较大 | 用户态调度,开销较小 |
| 创建开销 | 较高 | 较低 |
| 并发模型 | 多线程 | 协作式多任务 |
| 应用场景 | CPU密集型任务、并行计算 | I/O密集型任务、异步编程 |
1.5.6 使用 Python 进行并行编程
了解线程和进程在 Python 中的作用。我们可以深入研究与 Python 语言密切相关的并行编程。
因此,在这种语言中,并行编程完全是在进程上表现出来的。一个程序被划分为多个可并行的子任务,每个子任务分配给不同的进程。在每个子任务中,我们可以选择是同步执行还是异步执行各个步骤。
1.5.7 同步和异步编程
在本书和许多有关并行编程的在线文档中,经常会提到同步或异步这两个术语,有时也称为sync和async。在所有这些情况下,我们指的是两种不同的编程模型。
在不知不觉中,当我们在多个进程或线程之间并行或竞争地执行一个程序时,我们会自然而然地将其结构化为同步。这是因为一般来说,我们都是串行编程出身,倾向于这样思考问题。也就是说,在存在两个或多个进程(但它们可以是线程,也可以是程序中的简单函数)的情况下,一个进程继续执行,直到执行外部调用,将执行传递给另一个进程以获取服务、计算或任何其他操作。另一个进程将被执行以完成其任务,然后将服务结果返回给同时待处理的初始进程。一旦获得必要的结果,初始进程将恢复执行。
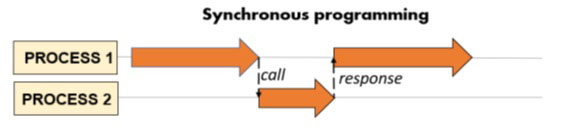
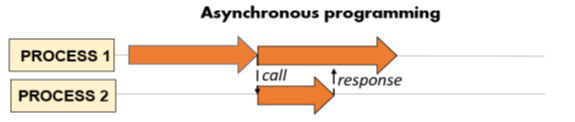
正如我们所猜测的那样,异步编程可以让我们在很多情况下发挥优势,在这些情况下,我们会浪费大量时间等待需要外部响应或较长的执行时间的操作。因此,如果想充分利用并行编程的所有潜力,就必须对这两种模式了如指掌。
至于它的实际应用,虽然对我们来说还不完全直观,但它是完全可行的。所有编程语言都有内部机制来实现它们。我们将在第 6 章 “使用 CUDA 实现 GPU 编程性能最大化 ”中深入介绍异步编程。
1.5.8 Map和reduce
并行编程中广泛使用的一种方案是 Map-Reduce,它主要基于两个阶段:
- Map
- Reduce
第一个阶段,即映射阶段,是将程序要执行的任务细分为几个部分(任务),然后将它们分配给不同的进程,由这些进程同时执行,即并行执行。通常情况下,每个进程的执行都会产生一个结果。因此,除了与并行执行严格相关的阶段外,还会有一个后续阶段,即必须将所有结果重新组合在一起的还原阶段。
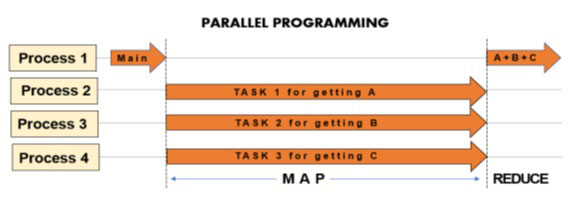
1.5.9 CPU 绑定和 I/O 绑定操作
不过,在并行程序的设计阶段,必须关注各个任务,评估其中是否有一些任务需要太长的执行时间。如果出现这种情况,就会导致性能下降,因为所有其他进程都在等待完成映射阶段。事实上,要进入还原阶段,就需要每个进程得到的所有结果。
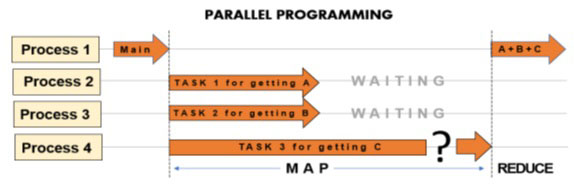
因此,在这些情况下,我们必须考虑在每个进程(任务)中执行的各种操作。这些任务可能包括读取文件或调用外部网络服务等内部操作。在这种情况下,进程必须等待外部设备的响应,因此执行时间可能无法预测。这类操作被称为 I/O 约束。而只涉及 CPU 内部计算的操作则称为 CPU 绑定。
在并行编程中,当处理子任务或 CPU 绑定操作时,使用多个进程并行执行指令可提高程序的效率。但在 I/O 绑定的情况下,我们必须采用不同的工作方式。
在这种情况下,最合适的编程方式就是并发编程,这就是线程发挥作用的地方。在进程中,我们可以创建多个线程。其中一个线程将继续处理 CPU 绑定操作,而其他线程将处理各种 I/O 绑定操作。当其中一个包含绑定 I/O 操作的线程等待数据或来自外部的响应时,其他线程将继续执行其操作。
在这种情况下,通过并发运行线程,我们可以节省执行时间:
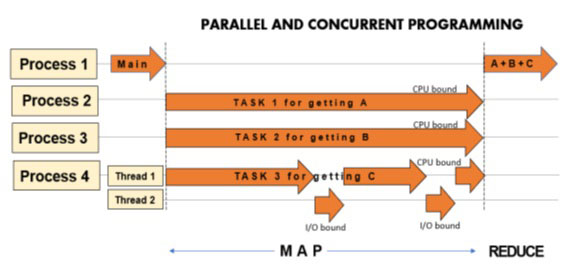
上图除了主线程(在进程中始终存在)外,创建一个额外的线程可以单独管理(异步或同步)I/O 绑定操作,同时允许主线程继续进行数据处理。
1.5.10 并行编程中的其他注意事项
在处理并行编程时,使用线程时仍须特别注意共享数据的管理。如图 1.17 所示,事实上,进程中的线程既有自己的独立内存(其他线程无法访问),也有共享内存空间,其中的对象可供所有线程访问:
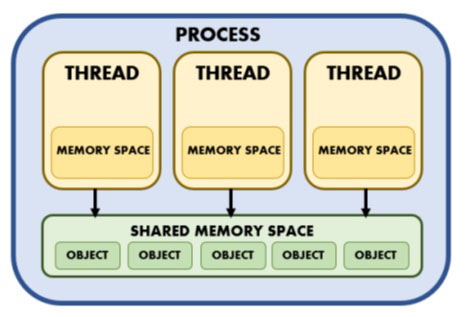
尽管在使用多线程的 Python 解释器中存在 GIL,但如果不想陷入数据不一致的问题,仍有必要锁定共享内存空间中的全局对象。但是,如果 GIL 保证在一个进程中一次只执行一个线程,这怎么可能呢?
事实上,解释器只负责 Python 的内部对象,至于我们在程序执行过程中定义和创建的对象,将不会有控制或锁,而是独立管理。我们需要管理我们创建的全局对象的锁,以确保我们不会得到意想不到的结果。
在这方面,我们很快就会看到,Python 标准库中有一些模块,除了实现进程,特别是线程外,还提供了一系列工具,让我们也能管理全局对象的锁。
1.5.11 Threading和multiprocessing 模块
在实际执行过程中,我们可以使用标准库提供的两个模块:threading和multiprocessing。这些模块在 Python 中提供了一组函数,用于与操作系统接口,用 Python 创建、执行和管理进程和线程。
注意:Python 没有专门的多线程模块,它不像进程那样被称为多线程,因为 Python 实际上不是多线程的,而是一次只能执行一个线程。
threading模块为 _thread 模块提供了一个抽象层,而 _thread 模块是一个底层模块,它提供了处理多个线程的原语。此外,它还提供了一系列工具,帮助程序员完成管理线程等并发系统的艰巨任务:锁、条件和 Semaphores。下一章 “构建多线程程序 ”将深入介绍该模块的功能和这些工具,并提供一系列示例代码,帮助你了解如何以及何时使用这些工具。
另一方面,多处理模块提供了一个有效的应用程序接口,用于实现基于进程的并行性。除了创建和管理进程外,该模块还提供了大量有助于管理程序中多个进程共存的功能。例如,队列(Queue)和管道(Pipe)是允许在不同进程间交换信息(对象)的对象,或者是简化同时管理多个进程的池。此外,该模块及其功能将在第 3 章 “使用多进程和 mpi4py 库 ”中进行广泛讨论。