想要更优的Inference Time Scaling曲线,前提是模型本身是一个很强的Generator,已经拥有足够的生成合理推理过程的能力,同时还拥有很强的Verifier模型来对推理节点进行打分决策,并且二者可以在少人类监督的条件下不断迭代优化。这一章我们先聊聊如何让大模型"自学"推理思考,从而得到思考推理能力更强的Generator。
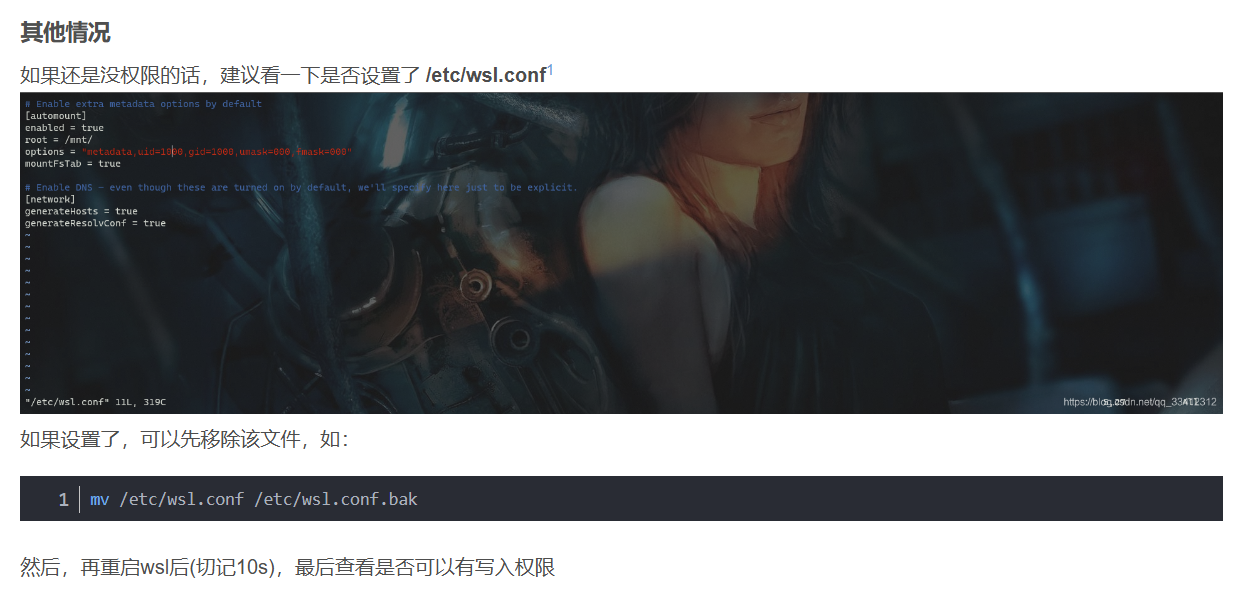
想要更优的Inference Time Scaling曲线,前提是模型本身是一个很强的Generator,已经拥有足够的生成合理推理过程的能力,同时还拥有很强的Verifier模型来对推理节点进行打分决策,并且二者可以在少人类监督的条件下不断迭代优化。这一章我们先聊聊如何让大模型"自学"推理思考,从而得到思考推理能力更强的Generator。最近大家都在探讨和尝试复现OpenAI O1的思考效果,解码出的关键技术方向,包括之前已经探讨过的Inference Time Scaling在推理过程中进行路径决策和选择。但想要更优的Inference Time Scaling曲线,前提是模型本身是一个很强的Generator,已经拥有足够的生成合理推理过程的能力,同时还拥有很强的Verifier模型来对推理节点进行打分决策,并且二者可以在少人类监督的条件下不断迭代优化。
这一章我们先聊聊如何让大模型"自学"推理思考,从而得到思考推理能力更强的Generator。本章会以STaR论文为基础,介绍生成复杂动态思维链背后可能的技术方案
STaR
- STaR: Self-Taught Reasoner Bootstrapping ReasoningWith Reasoning
STaR是这一系列论文的第一篇,思路就是妥妥的Bootstrap,生成推理过程->训练模型->生成更优的推理过程->训练更强的模型。
STaR的流程很直观
- Pretrain模型,通过指令+fewshot,引导模型对QA数据集生成推理过程
- 对以上推理过程进行过滤,只保留回答正确的
- 对推理答案错误的,通过Hint(在上文中告诉模型正确答案),引导模型生成正确的推理过程,对这部分样本也进行过滤,只保留回答正确的
- 使用以上样本进行SFT,教模型如何思考
- 再使用SFT后的模型重复以上样本生成的过程,直到评估指标不再提升
STaR的优缺点都非常明显,优点就是不需要大量人工标注的思维链样本,也不依赖更强大的模型提供合成样本(其他模型提供的合成样本本身也可能存在分布漂移会影响模型效果),实现了一定程度的模型自我优化提升。缺点有
- 可用场景有限:STaR依赖正确答案作为过滤条件,因此只适用于问答,数学计算等有限领域,对于更广泛的开放领域无法适用。这个限制其实也是因为STaR并未引入Verifier,因此只能依赖答案本身作为评估基准。
- SFT本身的泛化性有限:通过SFT把生成的推理过程注入模型,很难让模型学到推理过程中的奖励信号,更多还是在做Behaviour Cloning。达不到"Don't Teach, Incentive"的效果
- STaR对样本的使用率不足,只使用了唯一的一条正确样本,丢弃了通往正确答案的更多正确路径,也丢弃了更大量级的错误思考过程
- 思考链路是静态,既针对任何问题模型都默认上来就进行思考,这种形式在单一场景中适用,在更灵活广泛的实际场景中思考应该动态存在
下面我们看下针对以上问题,其他论文给出了哪些优化方案,以下论文更多会关注和STaR的对比~
RFT
- Scaling relationship on learning mathematical reasoning with large language models
RFT也是模型自我合成数据进行优化的方案,它没有使用STaR的多轮Bootstrap来持续优化合成数据,只用了一轮优化,但RFT给出了在一轮迭代内,更充分利用正样本的方案。
RFT会使用SFT后的模型,针对每个问题随机采样100条推理路径,筛选所有答案正确的推理路径,并使用编辑距离对不同的推理路径进行消重,只保留差异化的正确推理路径。这样对比以上STaR每个问题只有1条正确样本,RFT对每个问题会保留多样性的正确推理路径,然后使用该合成数据集对模型进行训练。对比后发现使用更多推理路径效果会有提升,同时去重也会带来明显的效果提升。大概率因为不去重,会导致部分重复样本的过度拟合,影响泛化性。
RFT这种使用模型自我合成数据再微调基座的方案,在后面Google Deepmind的论文中也进一步论证了它的有效性要超过使用更强大的模型直接合成数据的效果。部分因为多个正确推理路径的提供,能给模型提供一些哪些推理节点是核心节点的有效信息,降低模型模仿率,提高模型泛化性。

V-STaR
- V-STaR: Training Verifiers for Self-Taught Reasoners
V-STaR沿用了STaR的多轮Bootstrap样本迭代的方案,并给出了一种简单的利用负样本的方案,在以上STaR的基础上,每一轮模型生成推理答案时,正确和错误的推理链路都会被保留,其中正确的样本用来训练微调Generator,而正确和错误的样本会合并用于训练Verifier。
以及和STaR每一轮都只使用新训练的Generator合成的样本不同,这里训练Verifier的样本是每一轮收集样本的并集。因为RM模型需要广泛学习不同分布的推理结果,而每一轮随着Generator不断增强,其实都在拓宽RM模型学习的样本范围,提升Verifier的泛化性。
最后论文用收集好的正负样本,构建了针对问题的对比样本对(x, y+,y-) ,然后使用DPO在最后一轮微调得到的最优的Generator上来训练Verifier。并在推理过程中使用该Verifier,来实现best-of-n策略,从N个随机采样的推理结果中选择RM得分最高的推理链路。

效果上加入Verifier的STaR效果会有进一步提升,并且多轮Bootstrap也能有效提高V-STaR的效果。
Incorrect Synthetic Data
- RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold
GDM这篇论文对正负合成思维链样本都做了更加全面的讨论,基本结论如下
- 正样本:论文论证了前面RFT,也就是使用微调模型自我生成推理链路的方案,要优于使用更强模型直接生成样本进行SFT。但是只使用合成正样本做SFT,因为无法保证链路的完全正确,会让模型学到一些混淆的错误思考模式。
- 负样本:对比V-STaR只在Verifier中简单利用了负样本,论文给出了在优化Generator中使用负样本的训练方案
下面我们分正负样本来分别说下~
正样本:为何自我生成的正样本效果更好?
论文分别采用两种方案来合成数据
- SFT:使用更强大的模型合成数据,例如GPT4来生成带有思维链的推理样本,经过简单的消重,过滤错误答案后,使用正确样本直接微调模型
- RFT:模型自我合成数据,使用以上微调后的模型,针对每个问题再生成N个推理结果,经过过滤后使用正确的样本微调模型,也就是使用基座微调模型自我生成的样本再回来微调基座
论文发现在Deepseek和Llama2上,随着合成数据集的数量变大,RFT显著优于SFT,并且优势并不随数据集变大而缩小。具体到数据使用效率,相同的Test Error下,使用RFT策略训练的效果相当于使用2倍的合成数据进行SFT

这个结论会有一些反直觉,因为之前很多优化小模型的思路都是去蒸馏GPT4的回答。当然后面也有一些研究认为拟合另一个模型的回答,因为预训练的差异,导致微调过程中模型很难直接学习新的推理回答只能强行记忆,影响模型泛化效果。 类似的问题其实在早期我们也用GPT3.5,GPT4的回答去构建样本,然后微调一些小模型的时候就发现了,当回答风格差异巨大的时候,直接微调,会影响基座本身的知识存储和指令理解。其实就是小模型为了去强行改变自己的输出风格,负向影响了模型本身的参数分布。
论文使用RFT生成的样本,相比SFT样本,在基座模型上有更高的log likelihood来论证之所以使用RFT的样本微调效果更好,就是因为RFT样本是基座模型自我合成的,因此和基座模型本身的推理分布更加接近,模型更好学习,会降低模型去强行记忆的概率,对泛化性的损失更小,更加“easy-to-fit”。
但不论是SFT还是RFT,论文提出都需要关注正确样本中错误的推理链路,因为样本过滤只使用了答案,并未对中间推理链路的正确性进行校验,而这些错误的步骤,会导致模型学到一些混淆的因果关系。而虚假步骤带来的推理问题,并无法通过简单的增加合成数据的方法来解决。
下面我们接着看论文如何通过引入负样本和per-step DPO来优化合成样本中错误步骤带来的问题。
负样本:呦呵你没想到我也这么有用吧
既然同一个问题生成多条正向的推理链路的合成样本可以提升效果,那如何更有效的利用比正样本占比更高的负样本呢?前面V-STaR是选择利用负样本去训练Verifier,而GDM的论文给出了通过正负样本对比学习来充分利用负样本的方案。论文设计的RL目标函数如下,通过正负样本分别和基准(微调后的基座模型)模型对比,来进行对齐。

并且论文给出了从“关键步骤”这个概念出发构建正负样本对的方案,那啥叫关键步骤嘞?
可以从熵值的视角去看,如果生成步骤A后,模型得到正确答案,或者错误答案的概率显著更高,那步骤A就是关键步骤。其中通往错误的核心步骤需要模型遗忘,通过正确的核心步骤需要学习。
那如果生成步骤A后,模型得到正确和错误答案的概率一半一半,那步骤A就不是关键步骤。想要获得每个步骤通往正确、错误答案的概率,其实只需要通过蒙特卡洛模拟采样足够多的链路,然后做个概率统计就行嘞
以上的关键价值,论文用以下的公式来计算,每个步骤(i)的价值(Q value),都是给定(1i-1)的步骤,计算步骤模型在未来(i+1L)步内获得正确答案的期望概率。以上价值其实是步骤(1~i)的累计价值,而每个步骤的增量价值,就是和截止前一步Q value的差值。


所以构建正负推理链路的步骤,就是基于每个问题,使用微调后的基准模型采样N条推理链路,基于答案是否正确,先初步分成正负样本。然后在负样本内,寻找每个推理链路中关键价值最低的第一个步骤(大概率导致模型失败的第一个核心节点)作为\(-y_{1:c}\)。在正样本内,寻找每个推理链路中关键价值的第一个步骤作为\(+y_{1:c}\),然后基于这些正负样本对,使用以上对比RL损失函数进行训练。
效果上对比SFT,per-step DPO训练的效果,会发现相同Test-Error下,使用per-step DPO训练,相当于使用8倍的合成数据进行SFT, 也就是per-step DPO的合成数据使用效率比SFT要高8倍 对比前面RFT,利用负样本,识别关键步骤进行对比学习,对合成数据有更高的利用率~

Quiet-STaR
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
- THINK BEFORE YOU SPEAK: TRAINING LANGUAGE MODELS WITH PAUSE TOKENS
- https://github.com/ezelikman/quiet-star?tab=readme-ov-file
Quiet-STaR拓展了以上STaR们的应用范围,针对开放世界的各类问题,给出了让模型先给出多条思考路径,再在推理时动态决策多大程度上依赖前置思考来回答问题的新方案。

Quiet-STaR的实现包括3步,我们对照的着下面的代码来说
- N路平行思考生成:针对每个输入token,生成N个推理链路,每个推理链路的长度都是固定的,并且在推理链路的开始和结束,分别插入新的Special token <startofthought>,<endofthought>。 这些推理链路就是模型的隐藏思考步骤。对应以下代码中continuation迭代生成的部分。
- 混合权重头:论文在原生LLM的基础上添加了一个分类头,就是简单一层或多层MLP。分类头用于进行权重混合,也就是在预测真实的下一个token的时候,根据分类头的权重,决定多少信息来自上一个输入token,多少信息来自新生成的隐藏思考步骤。对应以下代码中的mixing_weight和mixed_hidden_states。
- RL训练优化思考生成:最后通过强化学习,在训练以上<startofthought>,<endofthought>,MLP分类层的基础上,让模型生成的隐藏思考步骤更加有用,可以提高模型推理效果。
# Append the start thought token to the input sequence
start_thought_token_id = self.tokenizer.convert_tokens_to_ids("<|startthought|>")
input_ids = torch.cat([input_ids, torch.tensor([[start_thought_token_id]] * batch_size).to(input_ids.device)], dim=-1)
seq_len += 1# Update the attention mask
if attention_mask is not None:attention_mask = torch.cat([attention_mask, torch.ones((batch_size, 1)).to(attention_mask.device)], dim=-1)# Generate the continuation
continuation_length = self.n_ahead - 2
new_key_values = past_key_valuesstart_time = time.time()
for continuation_idx in range(continuation_length):outputs = self.model(input_ids=input_ids if continuation_idx == 0 else next_token_id.unsqueeze(-1).to(input_ids.device),attention_mask=attention_mask,position_ids=position_ids,past_key_values=new_key_values,inputs_embeds=inputs_embeds,use_cache=True,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,)new_key_values = outputs.past_key_valueshidden_states = outputs[0]logits = self.lm_head(hidden_states)logits = logits[:, -1, :] # Only consider the last token# Apply Gumbel-Softmax to the logitsnext_token_logits = F.gumbel_softmax(logits, tau=self.gumbel_temperature, hard=True, dim=-1)next_token_id = torch.argmax(next_token_logits, dim=-1)# Append the generated token to the input sequenceinput_ids = torch.cat([input_ids, next_token_id.unsqueeze(-1).to(input_ids.device)], dim=-1)seq_len += 1# Update the attention maskif attention_mask is not None:attention_mask = torch.cat([attention_mask, torch.ones((batch_size, 1)).to(attention_mask.device)], dim=-1)# Append the end thought token to the input sequence
end_thought_token_id = self.tokenizer.convert_tokens_to_ids("<|endthought|>")
input_ids = torch.cat([input_ids, torch.tensor([[end_thought_token_id]] * batch_size).to(input_ids.device)], dim=-1)
seq_len += 1# Update the attention mask
if attention_mask is not None:attention_mask = torch.cat([attention_mask, torch.ones((batch_size, 1)).to(attention_mask.device)], dim=-1)# Get the hidden states before and after the thought
outputs_before = self.model(input_ids=original_input_ids,attention_mask=original_attention_mask,position_ids=position_ids,past_key_values=past_key_values,inputs_embeds=inputs_embeds,use_cache=use_cache,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,
)
hidden_states_before = outputs_before[0][:, -1:, :]# two new tokens: last continuation token and end thought token
outputs_after = self.model(input_ids=torch.cat([next_token_id.unsqueeze(-1).to(input_ids.device), torch.tensor(end_thought_token_id).unsqueeze(-1).unsqueeze(-1).to(input_ids.device)], dim=-1),attention_mask=attention_mask,position_ids=position_ids,past_key_values=new_key_values,inputs_embeds=inputs_embeds,use_cache=use_cache,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,
)
hidden_states_after = outputs_after[0][:, -1:, :]# Apply the talk head to get the mixing weight
mixing_weight = self.talk_head[0](torch.cat([hidden_states_before, hidden_states_after], dim=-1))# Apply the mixing weight to the hidden states
mixed_hidden_states = (1 - mixing_weight) * hidden_states_before + mixing_weight * hidden_states_after# Apply the language model head to get the final logits
logits = self.lm_head(mixed_hidden_states)
按照以上的步骤,我们来举个例子,输入是“今天天气“:
1. 平行思考生成(N=5)- 思考1:<startofthought>是否下雨、下雪等异常天气<endofthought>- 思考2:<startofthought>温度、湿度情况<endofthought>- 思考3:<startofthought>湿度情况<endofthought>- 思考4:<startofthought>对人们生活活动的影响<endofthought>- 思考5:<startofthought>穿衣建议<endofthought>
2. 权重混合(思考1举例)- 无思考时输入的next-token:很(0.4)+ 真(0.6)- 思考1后面的next-token:晴朗(0.2) + 下雨(0.2) + ....各种天气情况- 思考1混合后(混合权重0.5):很(0.2) + 真(0.3)+晴朗(0.1) +下雨(0.1)+ ....各种天气情况*0.5
3. RL训练(如果原始文本后面是“晴朗”)- RL给予“思考1”以正向梯度更新,在天气后面思考温度有助于模型推理
论文给出的一个实际的推理效果如下

再来说下训练的部分,论文采用了强化学习来训练新加入的MLP混合头,思考开始和结束的token,以及基座模型本身。因为前面再每个位置生成了N个不同的思考路径,论文选择的RL训练目标是优化每个token位置生成正确思考路径,相对其他思考路径对推理下一个token带来的增量信息。

然后鼓励模型去生成对推理下一个token有帮助作用的思考路径(Tj)

同时还会增加一个NLI Loss,来训练用于混合思考和推理权重的MLP头。训练对比前面STaR等策略都是使用QA等特定领域指令样本,Quiet-STaR选择OpenWebMath(技术网站爬虫数据)进行训练,考虑技术类文本依赖思考的情况更多,模型训练得到的正向信号会更加密集。因为训练本身是预训练的Next-Token-Prediction,因此对比STaR具有更好的泛化效果,可以不限领域,不限任务进行训练。
Quiet-STaR还有待进一步优化的问题包括
- 动态思考位置的选择:Quiet-STaR是在每个位置都生成N个思考链路后,再使用mix-head来对每个位置的思维链和原始推理进行权重融合,属于后选择方案,推理成本较高,如果能根据输入本身进行前置的思考位置选择,只在最优的一个或几个位置上进行内生思考推理(MCTS)就更完美了
- 模型内容思考可能本身不可解释,因为Quiet-STaR只在HighLevel层面去优化加入内生思考后,模型推理效果的提升,并未对思考本身的next-token prediction进行对齐,导致生成的思考本身甚至可能并不在语言上通顺。当然因为本身是在训练后的基座模型上推理,所以肯定保留了部分的语言逻辑性
- 模型内生思考可能存在各种3H(helpful,harmless,honesty)问题。同样是对齐问题,模型生成的思考链路不仅未在语言模型角度对齐,也未在人类偏好角度对齐,这可能也是OpenAI在O1中考虑对用户隐藏内在思考链路的原因之一。而对齐本身是否会影响内生思考的效果需要额外的实验验证。
Quiet-STaR和OpenAI O1在生成模型内生思考上的技术栈是很像的。OpenAI在O1的使用说明Link中也指出,O1是通过动态插入思考token,来生成内生思考,并基于内生思考进行推理回答,思考对用户不可见(OpenAI在Learning to Reason with LLMs中也说明隐藏思维链的部分是未对齐的),只展示回答部分。而多轮对话的上文也只会使用输入输出不会使用内生回答。使用感受上在金融场景下,一些强数字,强逻辑的问题例如表格问答,财务问题分析上O1有比较显著的效果提升。

想看更全的大模型论文·微调预训练数据·开源框架·AIGC应用 >> DecryPrompt
OpenAI O1技术路线解析的一些好文推荐~
- OpenAI Learning to Reason with LLMs
- 北大对齐团队独家解读:OpenAI o1开启「后训练」时代强化学习新范式
- Reverse engineering OpenAI’s o1
- OpenAI’s Strawberry, LM self-talk, inference scaling laws, and spending more on inference
- OpenAI o1 self-play RL 技术路线推演
- 让 LLM 下一盘大棋:RL 范式探讨


2024/11/14 模拟赛 A~B](https://img2024.cnblogs.com/blog/3322276/202411/3322276-20241114192729323-2036727298.png)

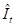


.assets/image-20241115003008761.png)