1. 概述
基于给定的Prompt,大语言模型生成的Reponse可能不是最好的(这一点我认为当前的LLM大部分都是Decoder架构,基于已生成的结果产生下一个Token,一旦之前生成结果出错,也不容易及时改正。)。
本文为原始的生成添加了额外的反思重写步骤,过程如下:
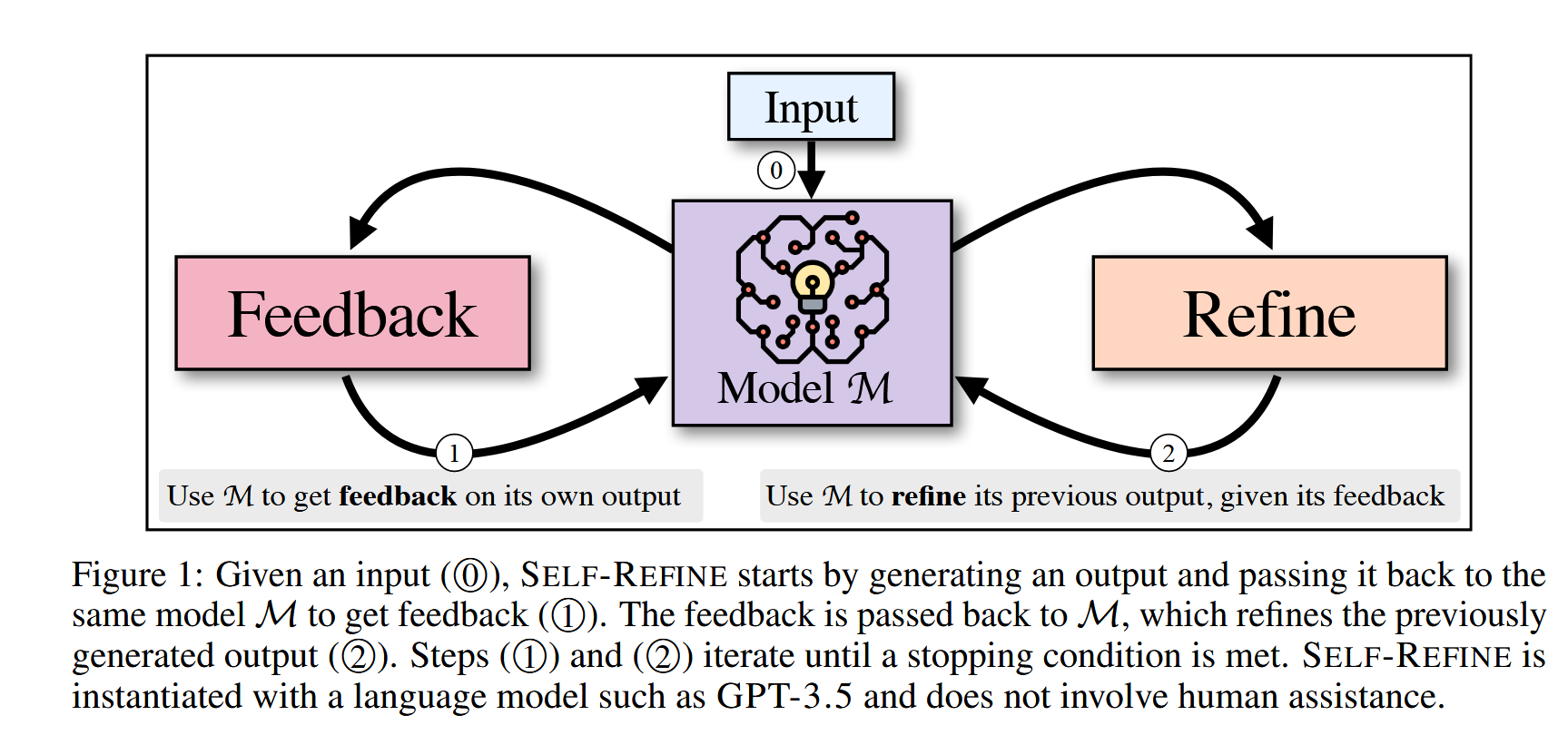
- 对于给定的\(Input\),先交给LLM生成第一个版本的\(Output_n\),n表示生成的第n轮回复,初始值为1,
- 然后将\(Input\)、\(Output_n\)交给LLM,让其提出\(Feedback_n\)。
- 将\(Feedback_1\)到\(Feedback_n\)、\(Input\)、\(Output_n\)交给LLM,使其反思重写得到\(Output_(n+1)\)
重复2-3步骤,直到满足停止条件(轮数条件 or 数据质量条件)
作者用7类任务以及3个闭源模型(GPT-3.5、ChatGPT、GPT-4)进行验证,任务如下:
- 段落情绪反转(输入一段文字和一个情绪,把这段文字改写成输入的情绪)
- 对话生成
- 代码优化
- 代码可读性提升
- 数学推理
- 首字母缩略词生成
- Constrained Generation(根据给定条件进行结果生成)
除数学推理任务以外,反思重写基本都有大幅度的效果提升。
2. 方法细节

其中
- \(P_(gen)\)是当前任务的Prompt。
- \(x\)表示任务输入,\(y_n\)则是每一次LLM输出的结果。\(||\)为串联符号。
- \(stop()\)函数为任务特定的停止函数,返回true表示不再需要进一步的生成反馈。
- \(P_(fb)\)是用于生成反馈的Prompt,\(fb_t\)则为生成的反馈信息。注意,不同任务使用了不同的\(P_(fb)\)。
- \(P_(refine)\)为重写原始Response的Prompt
3. 实验
实验过程中使用的LLM包括:
- GPT-3.5
- ChatGPT
- GPT-4
- CODEX(代码任务额外使用了这个模型)
3.1 评估方式
- 任务metric:对于不同任务,评估标准采用和Baseline相同的metric。
- 人工评估(GSB)
- GPT-4评估
3.2 结果
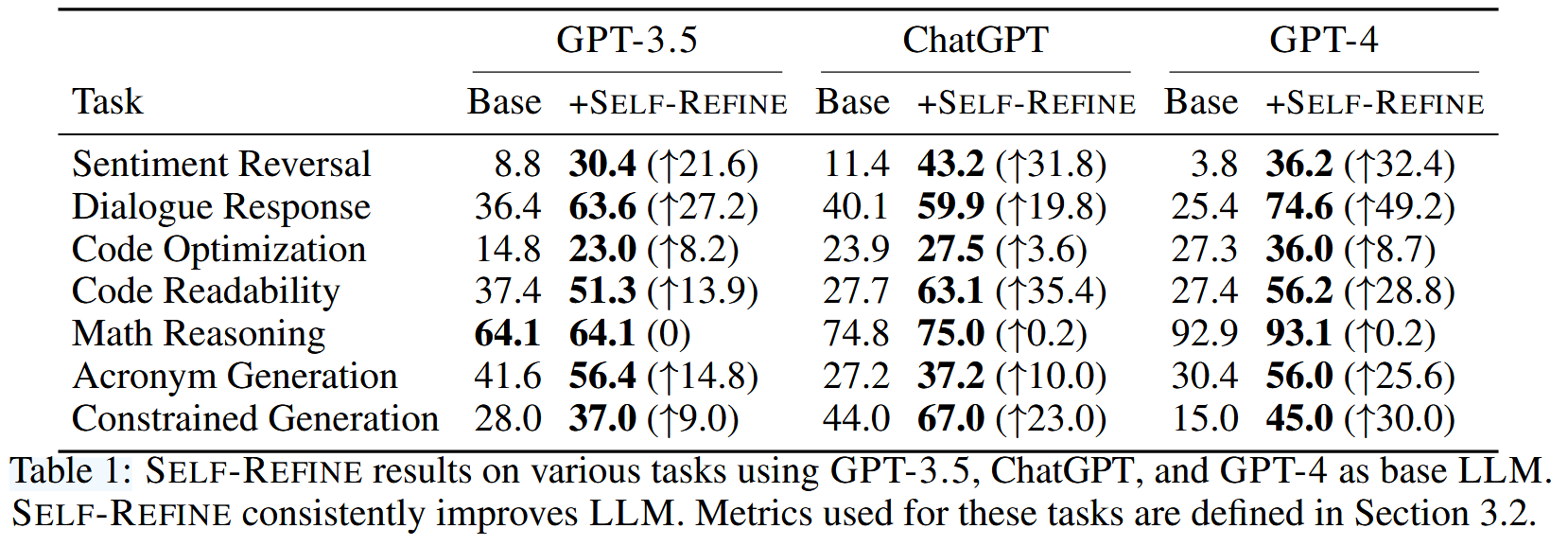
- 除了数学推理任务,其他任务都有较大提升。
- 对于Constrained Generation任务,纠错现象极其频繁。
- 数学推理任务,由于错误过于细节,导致LLM无法纠错(会回答"everything looks good")。但是如果外部信息告知Response是否正确,反思重写能带来5%左右的提升。基于Oracle feedback进行Response正确性反馈的情况下,反思重写效果如下:

- Self-Refine的提升与模型规模相关联。 可以看到Self-Refine对于GPT-4的提升是大于GPT-3.5的,尽管有些情况下GPT-4的效果不如GPT3.5,例如Acronym Generation任务,仅使用GPT-4和GPT-3.5处理该问题,前者弱于后者11个点左右,但Self-Refine对GPT-4的提升却远超GPT-3.5
3.3 分析
3.3.1 反馈质量的影响
作者通过对3个任务(代码优化、情绪反转、首字母缩略词生成),采用不同的Feedback生成方式进行实验,包括:
- Self-Refine feedback
- Generic feedback:LLM生成的Feedback更加通用,而非精细的策略。例如,优化代码的策略可能会是Improve the efficiency of the code而不是Avoid repeated calculations in the for loop。
- No feedback:去掉LLM生成Feedback这一步,单纯的将上一步的输出交给LLM,让其重写。

实验证明:精细化的Feedback > 通用Feedback > 无Feedback
3.3.2 迭代Refine的影响
作者对3个任务(代码优化、情绪反转、Constrained Generation),统计Self-Refine进行不同轮次的Refine,效果变化。
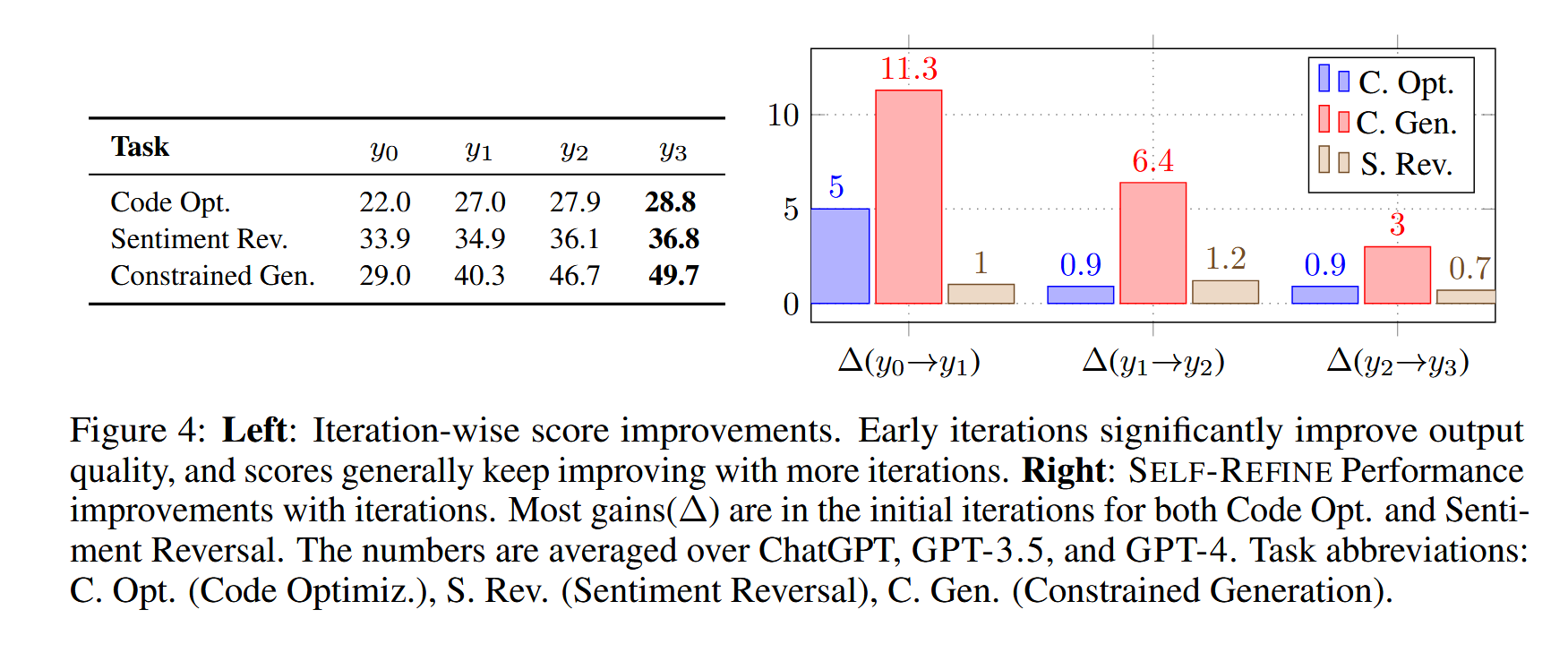
\(y_n\)中的n代表迭代轮次。上图显示随着迭代轮次的增加,生成Response的效果会提升,但提升幅度会逐渐降低。
注意:作者发现,Feedback带来的提升是多方向的提升,可能存在单方向的降低,而别的方向更加优秀。
3.3.3 Self-Refine是否适用于弱模型
作者采用Vicuna-13B验证Self-Refine,但是它无法很好的完成refine工作,主要表现在无法很好的生成feedback。
错误分析
作者对70条数据(30条有正向提升,30条负向)进行分析,发现Self-Refine表现差主要由于Feedback生成较差(94%),而不是Refine过程出现问题(6%)。