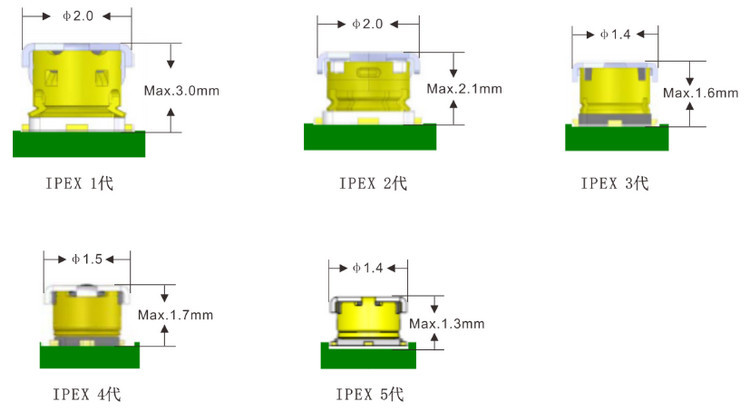
书生大模型全链路开源开放体系笔记
一、背景概述
随着人工智能技术的快速发展,大规模预训练模型(如GPT、BERT等)在各类应用场景中展现出了强大的潜力。尤其是在自然语言处理、计算机视觉、语音识别等领域,大模型的成功推动了各行业的数字化转型和技术革新。书生大模型(ShuSheng AI)作为国内领先的人工智能公司之一,其全链路开源开放体系的提出,旨在推动人工智能技术的普及、共享与创新,为学术界、产业界以及开发者社区提供更为开放、协作的研发平台。
二、全链路开源开放体系的核心思想
书生大模型的全链路开源开放体系不仅关注模型的开放和共享,更加注重从数据、模型训练、优化到应用的全流程开源。这一体系通过以下几个核心要素实现:
-
数据开放:书生大模型提供高质量、海量的标注数据集,支持包括文本、语音、图像等多模态数据的处理。数据的开放不仅降低了数据获取的门槛,还通过数据的公开透明促进了不同模型开发者之间的交流与合作。
-
模型开放:书生大模型通过开源代码和预训练模型,使得研究者和开发者能够在原有模型基础上进行迁移学习和自定义优化。模型的开放不仅降低了技术壁垒,也能为不同领域的创新提供源源不断的动力。
-
训练工具开放:书生大模型提供了一整套从数据预处理到模型训练、调优的开源工具和框架。这些工具能够大幅简化开发者的操作流程,使得高效的模型训练成为可能,促进了学术研究和产业应用之间的紧密结合。
-
应用开放:书生大模型不仅聚焦于基础技术的开源,还提供了多种行业应用的开源模块,包括文本生成、情感分析、图像识别等。这些模块的开放使得企业能够快速将大模型应用到实际业务中,从而提升工作效率,推动数字化转型。
-
社区支持:书生大模型注重构建强大的开发者社区,定期举办技术交流、竞赛和培训活动,鼓励更多的开发者贡献自己的力量,推动开源技术的普及与进步。
三、书生大模型的优势与挑战
-
优势
- 降低开发门槛:通过提供全链路开源,书生大模型帮助开发者无需从零开始构建模型,节省了大量的时间与成本。
- 加速创新:开放的技术框架和模型为创新提供了更大的空间,开发者能够根据需求定制与优化模型,推动不同领域的应用发展。
- 促进学术交流:开源的代码与数据为学术界提供了更广泛的研究材料和工具,学者们可以在此基础上展开更多的探索与实验。
- 推动产业应用:企业可以在开源平台上快速找到适合自身需求的解决方案,加速从技术研发到应用落地的转化。
-
挑战
- 数据隐私与安全问题:开放的高质量数据集需要对用户隐私与数据安全做出更多的保障,避免滥用或不当使用。
- 技术难度高:虽然开源降低了入门门槛,但模型训练和优化的技术深度要求依然较高,需要开发者具备一定的人工智能技术背景。
- 模型复杂性管理:随着开源项目的扩大,如何有效管理和维护大量的模型版本、工具和框架,确保它们的稳定性与可靠性,将是未来的重要挑战。
四、书生大模型全链路开源开放体系的未来展望
随着人工智能技术的不断发展和应用场景的扩展,书生大模型的全链路开源体系可能会进一步发展并持续创新。未来可能出现以下几个趋势:
-
多模态融合发展:随着自然语言、图像、语音等多模态技术的不断进步,书生大模型有望在全链路体系中融合更多类型的数据和任务,实现跨领域的智能协作。
-
自适应与个性化服务:基于开源的技术平台,未来可能会更加关注模型的自适应和个性化优化,为不同行业、不同用户提供定制化的人工智能解决方案。
-
合作与共建:随着开源社区的逐步壮大,更多的企业、研究机构和个人开发者将参与到模型的优化和创新过程中,书生大模型的开放平台将成为协作与共建的重要驱动力。
-
全生命周期管理:书生大模型有望在未来加入更多的模型监控、调优和更新机制,实现对模型的全生命周期管理,确保开放平台的长期稳定与持续进化。
五、总结
书生大模型全链路开源开放体系在推动人工智能技术普及和创新方面发挥了重要作用。通过数据、模型、工具和应用的全面开放,书生大模型不仅降低了技术门槛,也加速了科研和产业界的合作与创新。尽管面临数据隐私、安全和技术难度等挑战,但随着技术的发展和社区的不断壮大,书生大模型的开放体系将在人工智能领域产生深远的影响,推动人工智能技术走向更广泛的应用场景,促进社会的智能化发展。