本文快速复习了基于统计的语言模型的基本玩法,然后介绍了语言模型发展过程中的三个重要里程碑:神经概率语言模型、词向量模型 和 预训练模型。基于这几个里程碑的发展,开启了NLP处理的新纪元,我们可以基于经过预训练的大模型进行微调,进而处理我们自己业务领域的实际问题。
本文快速复习了基于统计的语言模型的基本玩法,然后介绍了语言模型发展过程中的三个重要里程碑:神经概率语言模型、词向量模型 和 预训练模型。基于这几个里程碑的发展,开启了NLP处理的新纪元,我们可以基于经过预训练的大模型进行微调,进而处理我们自己业务领域的实际问题。大家好,我是Edison。
最近温习了ChatGPT的基本原理和语言模型的发展脉络,受益匪浅。老规矩,必须把自己学到的整理一下,才算学过。
本篇我们快速复习一下上一篇的内容再次理解基于统计的语言模型,然后再了解下语言模型发展的重要里程碑。
基于统计的NLP基本玩法
上一篇我们了解到,在基于统计学和数学的方法论下,NLP技术主要是通过分析大量的语言数据,来推断和预测语言现象,为自然语言上下文的相关性来建立数学模型。在具体的实现上,就是猜下一个词的概率“游戏”,我们可以通过下面这个例子来复习一下。
假设有这么一句话“The best thing about AI is its ability to”(中文:AI最棒的地方在于它能),这是一句未完成的句子,我们把它交给语言模型来处理,它会怎么做?以GPT为例,当它已经浏览过人类数十亿的网页资料之后,它肯能就会列出随后可能出现的词及其出现的概率(按概率从高到低排列),如下图所示:

当有了这个带有概率的词列表之后,我们就可以从这些选项中选择一个词,类似于我们在GitHub Copilot中选择一个AI生成的代码点击Accpet,它就填充到了我们的IDE中。然后,语言模型会将这个词附加到之前的句子中,再次进行下一个词的概率推断,如此循环往复,如下图所示,我们可以清晰地看到这个句子文本不断生成的全过程。

画外音:这里虽然通常我们说的是添加一个词,但严格意义上,每次新添加的实际上是一个Token。这个Token并不是我们在应用开发中所说的用于Authentication和Authorization的Token,而是大模型中的一个重要概念,它可能是我们理解上的一个完整的单词,也可能是一个单词组合,还可能只是一个单词的一部分(也叫作单词的词根)。
此外,为了得到较为丰富的答案,而不老是“平平淡淡”的文本,GPT还引入了随机性的概念,我们把它叫做Temperature,这是一个重要的参数值。通过调节这个参数值(比如范围从0.1~1.0),参数越小确定性越强,参数越大则随机性越强,从而达到让语言模型更加活跃 或 更加固定 的效果。如下图所示,对于同样的提示词,由于Temperature值的不同,产生了不同的生成文本。

至此,我们已经复习了上一篇中提到的语言模型的关键思路跃迁:从基于规则 转向 基于统计 的方法论。
语言模型的发展里程碑
上一篇中提到,语言模型大概经历了如下图所示的四个阶段,从起源、基于规则 到 基于统计 再到 目前主流的深度学习,语言模型的进化驱动着NLP技术的发展。
而在语言模型发展的里程碑方法中,经历了下面一些关键方法:
-
(1948)N-gram Model:基于前n-1个词来预测序列中的下一个词
-
(1954)Bag-of-words:将一个句子或文档表示为其单词的集合
-
(1986)Distributed Representation:以分布式激活的形式表示词
-
(2003)Neural Probabilistic Language Model:神经概率语言模型,提出通过神经网络学习用于语言建模的单词分布表示
-
(2013)Word2Vec:词向量模型,一种简单高效的分布式单词表示方法
-
(2018)Pre-Trained Language Model:预训练语言模型,采用上下文单词表示,通过更大的语料库和更深的神经网络体系结构来进行预训练和微调。自此,NLP技术主流工具就变成了Transformer。
在神经概率语言模型提出之前,N-gram、Bag-of-words等方法虽然足够简单,但是由于忽略了单词之间的关系和语义信息,所以效果不是很好。
这里我们重点了解下神经概率语言模型、Word2Vec词向量模型 和 Pre-Trained预训练模型,它们是语言模型发展历史中最重要的里程碑了。
神经概率语言模型
早在20多年前,计算机科学家Yoshua Bengio等提出了神经概率语言模型,第一次画出了一个神经网络,这个方法提出应该通过神经网络来计算给定单词序列的概率。
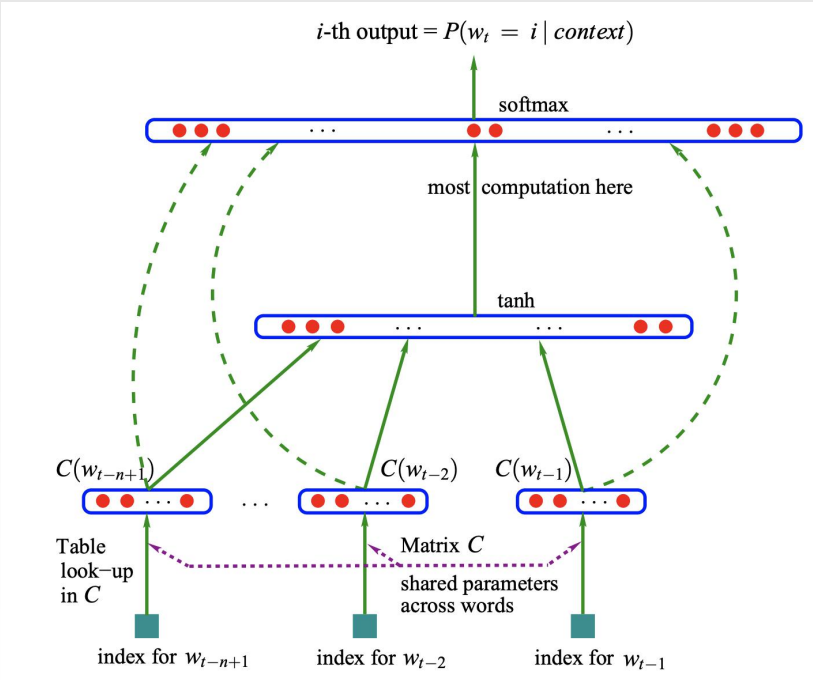
通过神经网络来学习单词之间的复杂语义关系,相较传统的N-gram等模型而言,就大大提高了准确性。
从此之后,模型就能够在大型语料库中通过训练自行地捕捉学习单词的向量表示 和 单词之间的语义和语法关系。人类也无需再去手工地去指定什么特征和标签等,所以它是NLP研究领域的一个重要里程碑,为后续基于神经网络模型的发展(如循环神经网络RNN/LSTM方法)都奠定了基础。
Word2Vec
Word2Vec是NLP技术的另一个重要里程碑。顾名思义,这是一个将单词转换成向量形式的方法。通过转换,可以把对文本内容的处理简化为向量空间中的多维度向量表示,如下图所示。
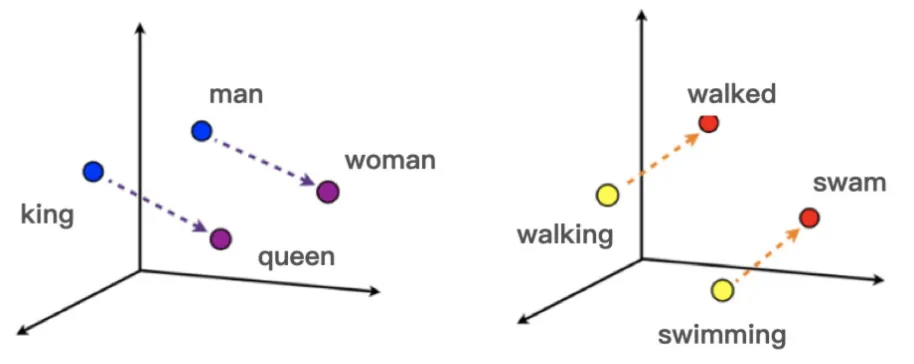
后续当要比较单词与单词时,只要计算出向量空间上的相似度,就可以来表示两个单词之间语义上的相似度。换句话说,语义相关的词,在向量空间中的距离也应该越近。比如,国王 和 男人 这两个词在向量空间中的某个维度就应该相似,类推,王后 和 女人 也在向量空间中某个维度也应该相似。
综上所述,词向量方法就是通过这些算法的设计去捕捉单词在语言中的语义和上下文信息,它给出的词向量就应该是相似的单词在向量空间中应该越近。在Word2Vec方法中,它其实包括了像N-gram, bag-of-word、skip-gram等方法的精髓,整合了这些方法的核心思想。
在Word2Vec提出之后,陆续涌现出了更多地词向量方法如GloVe等,至此,我们就可以将生成的词向量丢到神经网络中去进一步训练。
Pre-Trained Model
在2018年语言模型的发展来到一统江湖的重要环节,即以BERT为代表的预训练模型(Pre-Trained Model),它成功地取代了其他各种各样的语言模型,成为了NLP技术发展史上的一个最最最重要的里程碑,开启了NLP技术的新纪元。
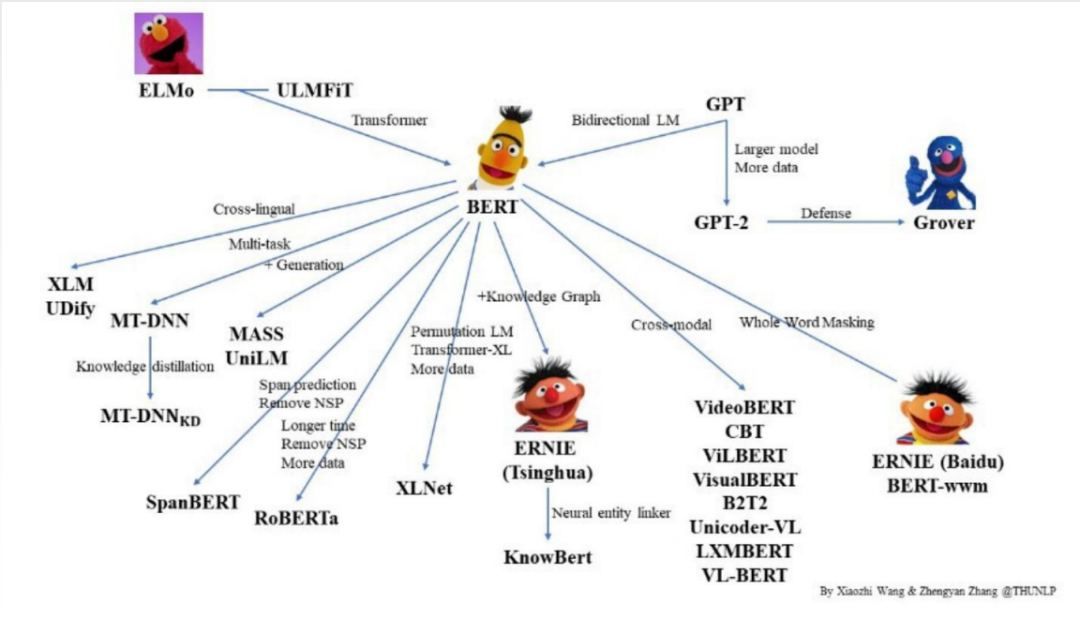
以BERT为代表的预训练模型,它采取的实无监督学习的方法,所谓无监督学习即不需要人工去标注数据进行训练。与此同时,人类互联网经过了几十年的发展,互联网上的语料库可谓是应有尽有了,比如说维基百科等。而这恰好给了预训练模型足够大的训练素材,它就自己在那儿训练,然后变得越来越强大。
这里说下BERT,它就是采用的掩码语言模型(Mask Language Model),比如说它把维基百科数据全部down下来,然后分段落地故意蒙上一些词让模型来猜测。打个比方,盖住20%的词不断让模型来猜,猜对了就奖励,猜错了就惩罚,逐渐地这个模型就变得越来越懂人类的套路越来越会猜词了。因此,模型就是用这种方法,它学到了人类广泛的语言知识。
此外,不得不说的是,GPT是比BERT要晚出现的,而在GPT发展的早期其影响力也没有BERT那么大。在BERT之后,出现了大量的类似的基于无监督学习的在大规模无标注的语料库中进行预训练,学习到丰富的语料表示,然后我们就可以拿着这些经过预训练过的模型去做微调,以适应各种各样不同需求的下游NLP任务。
Fine-Tuning
从此,这就开启了NLP处理的新时代,为NLP处理提供了强大的知识迁移能力。语言模型曾经在大量的数据中进行了预训练,有大量的知识存储,存储在预训练模型的海量参数之中。换句话说,它就像是一个博览群书的大佬,具有很强的举一反三的能力。而现在假设你是一个专注象棋教学的公司,你就可以基于象棋教学领域开发一个chatbot客服来协助你完成业务。
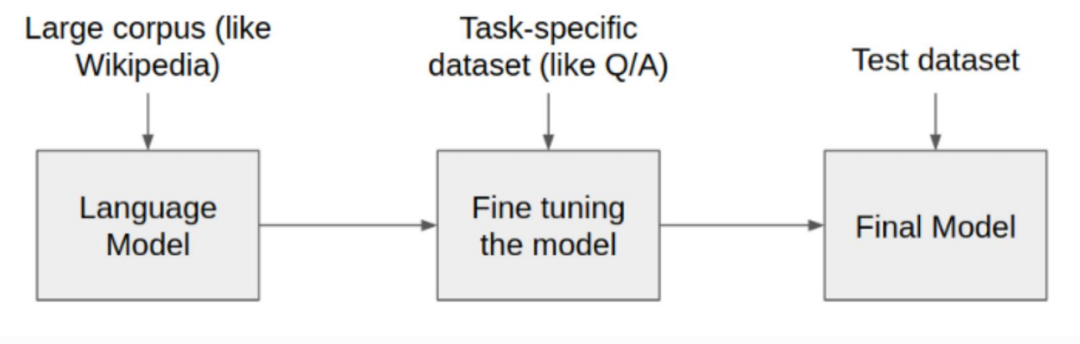
那么,怎么做呢?
首先,你先下载一个预训练的大模型,比如开源的Qwen系列。
其次,你再给它提供一个比较小的语料库(专注于象棋教学领域的),就可以在大模型的基础之上进行微调。
注意:这里不会涉及微调的细节内容,仅做科普。
最后,经过你微调后的大模型它就既可以处理它见过的各种各样的问题的回答,也可以处理你微调过的象棋领域的问题的回答。
回过头来,可以看到,我们不再需要自己去用海量的计算资源去做模型的预训练了,即不再需要从0开始,只需要拿过来一个大概能用的模型,经过微调,就可以为你所用解决你的业务领域的实际问题。
小结
本文快速复习了基于统计的语言模型的基本玩法,然后介绍了语言模型发展过程中的三个重要里程碑:神经概率语言模型、词向量模型 和 预训练模型。基于这几个里程碑的发展,开启了NLP处理的新纪元,我们可以基于经过预训练的大模型进行微调,进而处理我们自己业务领域的实际问题。
最后,说到预训练模型,就不得不提到它的核心内容:Transformer架构,这个内容就留到下一篇介绍吧!
推荐学习
黄佳,《ChatGPT和预训练模型实战课》(公开课,免费)
黄佳,《动手做AI Agent》(图书)
郑晔,《程序员的AI开发第一课》(课程)
产品二姐,《成为AGI产品经理》(课程)

作者:周旭龙
出处:https://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。