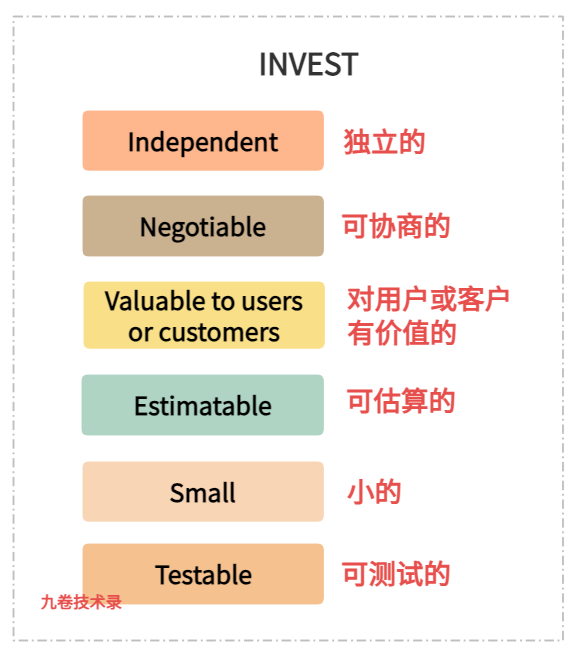
【模型部署】vLLM 部署 Qwen2-VL 踩坑记 02 - 推理加速
NLP Github 项目:
-
NLP 项目实践:fasterai/nlp-project-practice
介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验
-
AI 藏经阁:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
AI 算法面经:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
NLP 剑指Offer:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题
重新安装
环境配置
# 根据官网配置特定版本的transformer和vllm
pip install git+https://github.com/huggingface/transformers@21fac7abba2a37fae86106f87fcf9974fd1e3830
pip install accelerate
pip install qwen-vl-utils
# Change to your CUDA version
CUDA_VERSION=cu121
pip install 'vllm==0.6.1' --extra-index-url https://download.pytorch.org/whl/${CUDA_VERSION}
启动服务
python -m vllm.entrypoints.openai.api_server --served-model-name Qwen2-VL-7B-Instruct --model Qwen/Qwen2-VL-7B-Instruct


模型服务启动成功,占用显存67G

模型测试
curl http://localhost:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen2-VL-7B-Instruct","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": [{"type": "image_url", "image_url": {"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/qwen.png"}},{"type": "text", "text": "What is the text in the illustrate?"}]}]}'
测试成功:

推理加速
使用 FlashAttention 进行加速
pip install flash-attn
后台运行,并记录日志
nohup python -m vllm.entrypoints.openai.api_server --served-model-name Qwen2-VL-7B-Instruct --model Qwen/Qwen2-VL-7B-Instruct > ./logs/output.log 2>&1 &

系列文章:
- 【模型部署】vLLM 部署 Qwen2-VL 踩坑记 01 - 环境安装
- 【模型部署】vLLM 部署 Qwen2-VL 踩坑记 02 - 推理加速
- 【模型部署】vLLM 部署 Qwen2-VL 踩坑记 03 - 多图支持和输入格式问题
本文由mdnice多平台发布




![# [团队项目Scrum冲刺-day7]](https://img2024.cnblogs.com/blog/3304685/202411/3304685-20241117190038601-1974336661.png)