数据采集作业四
gitee链接:https://gitee.com/wangzm7511/shu-ju/tree/master/作业4
1.使用 Selenium 爬取股票数据的实战
需求:
- 熟练掌握 Selenium 查找 HTML 元素,爬取 Ajax 网页数据,等待 HTML 元素等内容。
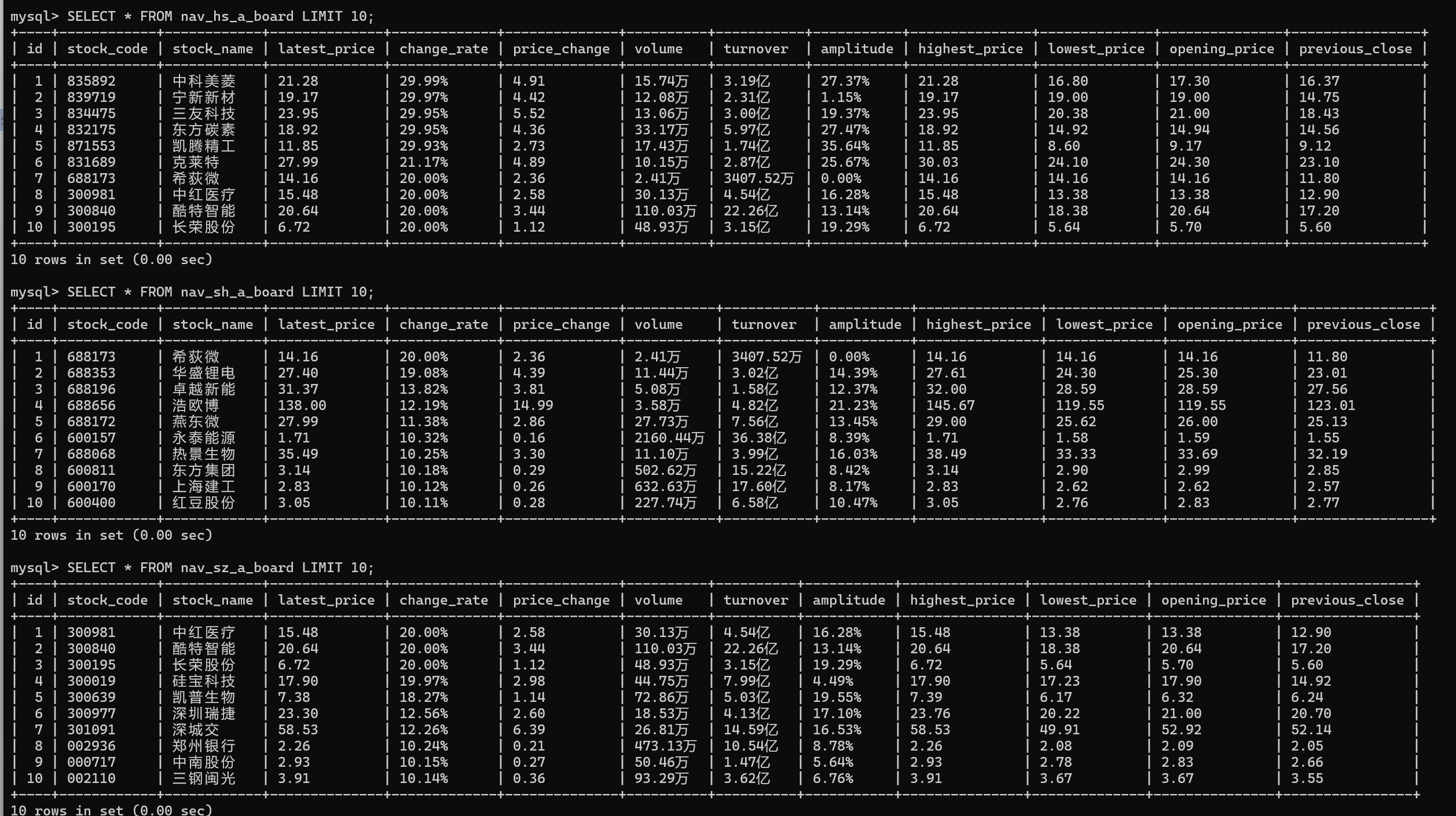
- 使用 Selenium 框架 + MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据。
- 数据来源网站:东方财富网 网址。
数据存储格式:
- 输出信息:MYSQL 数据库存储和输出格式如下表,表头应是英文命名,例如:
- 序号:id
- 股票代码:bStockNo
- 股票名称:bStockName
- 最新报价:bLatestPrice
数据格式示例如下:
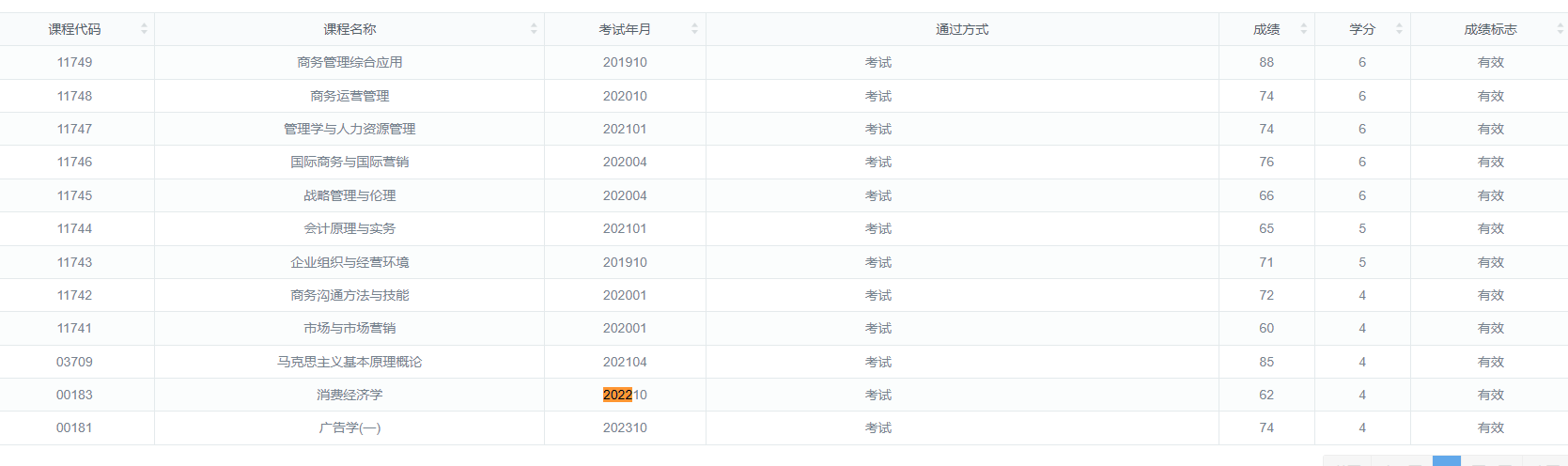
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N 世华 | 28.47 | 62.22% | 10.92 | 26.13 万 | 7 亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2 | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
过程:
1. 爬虫开发概述
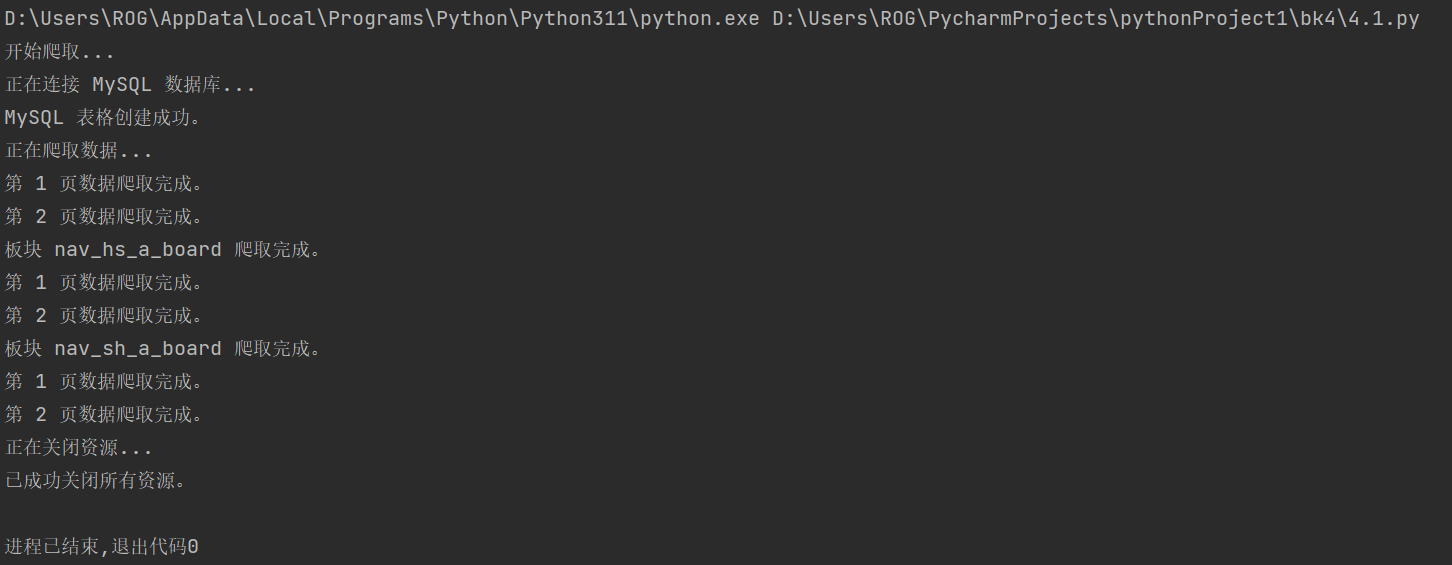
在此次实战中,我们通过 Selenium 模拟浏览器操作,爬取东方财富网的股票数据。目标是提取“沪深 A 股”、“上证 A 股”、“深证 A 股”三个板块的股票信息,并将数据存入 MySQL 数据库。使用 Selenium,可以通过模拟用户在网页上的操作,如点击、滚动等,自动化完成数据抓取。此外,MySQL 数据库用于存储从网页上爬取到的数据,方便后续的数据分析与展示。
2. 数据爬取的具体步骤
-
确定爬取内容与结构
- 在开始爬取之前,我们通过分析网页结构,确定需要的数据和元素位置。通过浏览器的开发者工具(通常按
F12键)查看 HTML 代码结构,找到了相关数据所在的<tbody>标签,且每个股票的数据位于<tr>元素中,每个字段在不同的<td>中。
- 在开始爬取之前,我们通过分析网页结构,确定需要的数据和元素位置。通过浏览器的开发者工具(通常按
-
使用 Selenium 进行元素定位与数据提取
- 使用 Selenium 框架控制 Chrome 浏览器,并配置为无头模式(即不显示浏览器窗口)。使用 Selenium 的方法(如
find_element()、find_elements())定位到每个股票的行数据,并获取每一列的数据。
- 使用 Selenium 框架控制 Chrome 浏览器,并配置为无头模式(即不显示浏览器窗口)。使用 Selenium 的方法(如
-
爬取多个板块的数据
- 我们设置了一个循环,分别爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”三个板块。通过点击不同的导航选项卡,切换到对应的板块,并对每个页面的数据进行爬取。
-
翻页处理
- 由于每个板块的数据量较大,通常需要翻页才能爬取所有数据。因此,爬虫脚本中添加了翻页功能,通过定位“下一页”按钮并进行点击,完成多页的数据抓取。
3. 数据存储
爬取到的数据需要存入 MySQL 数据库。首先创建了一个名为 stocks 的数据库,并根据不同的板块创建了三张表。每张表的字段与爬取的数据字段一一对应,以便于将爬取的数据存储进去。
MySQL 表结构示例
```sql CREATE TABLE nav_hs_a_board (id INT PRIMARY KEY,stock_code VARCHAR(16),stock_name VARCHAR(32),latest_price VARCHAR(32),change_rate VARCHAR(32),price_change VARCHAR(32),volume VARCHAR(32),turnover VARCHAR(32),amplitude VARCHAR(32),highest_price VARCHAR(32),lowest_price VARCHAR(32),opening_price VARCHAR(32),previous_close VARCHAR(32) ); ```4. 遇到的挑战和解决方案
- 页面加载等待:有些数据在页面加载时需要一些时间才能显示出来,因此我们使用 Selenium 的显式等待功能 (
WebDriverWait) 来确保页面元素加载完毕后再进行数据抓取。
5. 爬虫代码实现
代码主要包含以下几部分:
- 初始化 Selenium 浏览器驱动。
- 连接 MySQL 数据库,并创建数据表。
- 通过 Selenium 爬取东方财富网的股票数据。
- 将数据插入到 MySQL 数据库中。
以下是简化版代码的片段,展示了如何使用 Selenium 进行数据爬取并存储到 MySQL:
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 初始化 Chrome 浏览器配置
chrome_options = Options()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(options=chrome_options)# 连接 MySQL 数据库
connection = pymysql.connect(host="localhost", user="root", passwd="密码", db="stocks", charset="utf8mb4")
cursor = connection.cursor()# 打开目标网页
browser.get("http://quote.eastmoney.com/center/gridlist.html#hs_a_board")# 爬取股票数据
wait = WebDriverWait(browser, 10)
rows = browser.find_elements(By.XPATH, "//table[@id='table_wrapper-table']/tbody/tr")
for row in rows:stock_code = row.find_element(By.XPATH, "./td[2]/a").textstock_name = row.find_element(By.XPATH, "./td[3]/a").textlatest_price = row.find_element(By.XPATH, "./td[5]/span").text# 插入数据到 MySQLcursor.execute("INSERT INTO nav_hs_a_board (stock_code, stock_name, latest_price) VALUES (%s, %s, %s)",(stock_code, stock_name, latest_price))
connection.commit()
connection.close()
运行截图
总结
通过此次实战,我们使用 Selenium 成功地从东方财富网抓取了股票数据,并将数据存储到了 MySQL 数据库中。整个过程涉及了网页结构分析、元素定位、翻页、数据存储等多个环节,是对爬虫技术的一个全面练习。通过这种方式,我们可以实现对股票市场数据的自动化采集,为进一步的数据分析奠定基础。希望本次分享对你有所帮助!
2.使用 Selenium 爬取中国 mooc 网站的课程数据
需求:
-
熟练掌握 Selenium 查找 HTML 元素,模拟用户登录,爬取 Ajax 网页数据,等待 HTML 元素等内容。
-
使用 Selenium 框架 + MySQL 数据库存储技术路线爬取中国 mooc 网站课程资源信息(课程编号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)。
-
候选网站:中国 mooc 网:网址
-
输出信息:将数据存储到 MySQL 中,表结构如下:
- 课程编号:
id - 课程名称:
cCourse - 学校名称:
cCollege - 主讲教师:
cTeacher - 团队成员:
cTeam - 参加人数:
cCount - 课程进度:
cProcess - 课程简介:
cBrief
- 课程编号:
过程:
1. 项目目标和需求概述
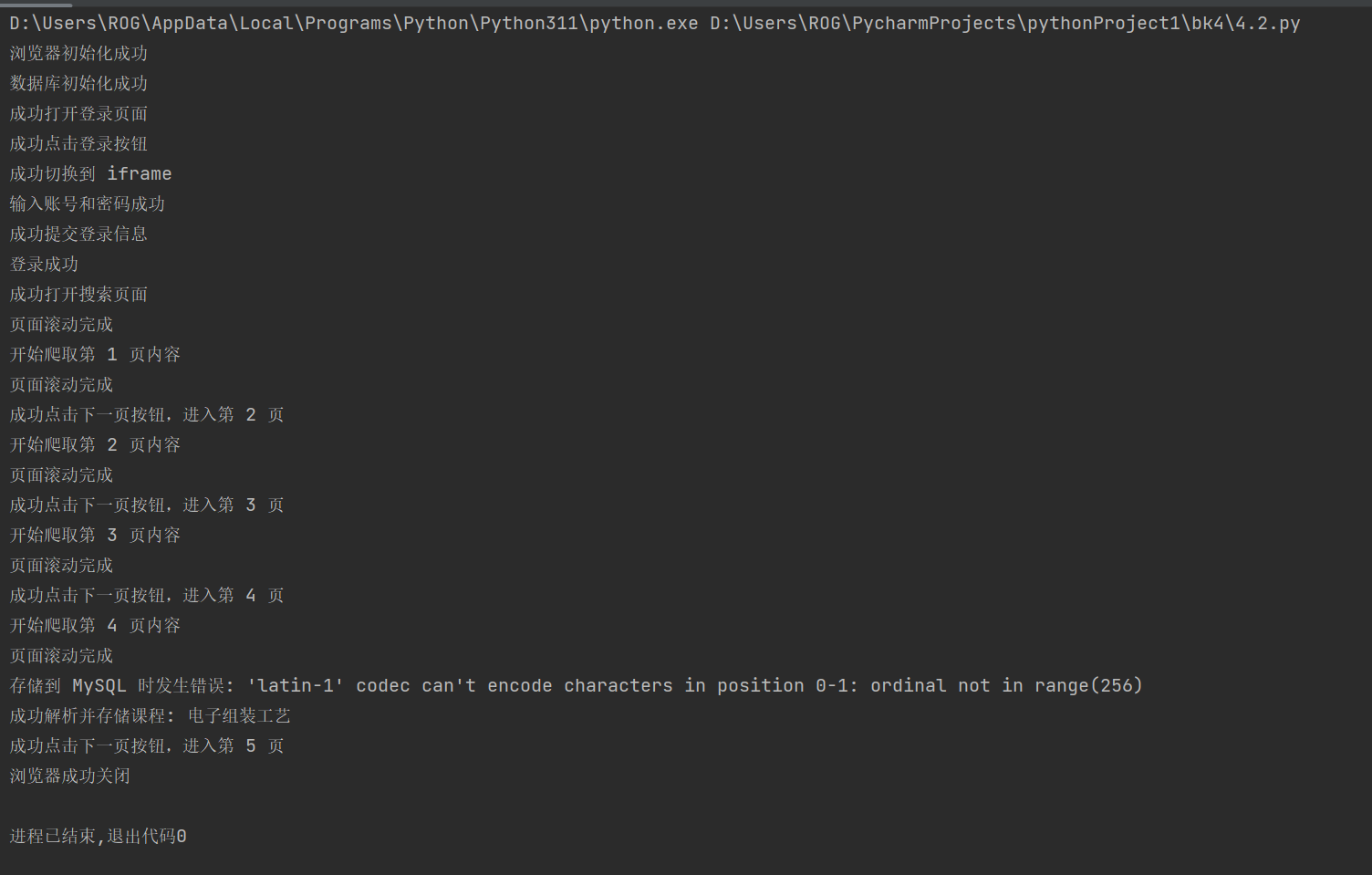
在这次实战中,我们使用 Selenium 模拟浏览器操作来爬取中国 mooc 网站上的课程信息,包括课程名称、学校名称、主讲教师等信息。爬取到的数据存储到 MySQL 数据库中,便于后续的数据分析与展示。为了实现这些功能,我们编写了一个自动化脚本,包含以下几个主要部分:
- 模拟用户登录过程
- 爬取课程信息页面
- 分页翻页爬取更多课程
- 将爬取到的数据存入 MySQL 数据库
2. 数据爬取的具体步骤
1 模拟用户登录
- 登录页面分析
我们首先使用浏览器的开发者工具(通常按F12键)分析登录页面的结构,找到登录按钮、账号输入框、密码输入框等位置。通过 Selenium,我们可以模拟点击登录按钮,输入账号和密码,完成用户登录。 - Selenium 实现自动化登录
使用 Selenium 定位登录按钮并点击,随后切换到iframe,完成账号密码的输入,最后点击登录按钮提交登录信息。
2 课程信息爬取
- 打开搜索页面
登录成功后,我们导航到课程搜索页面,通过分析网页结构,找到包含课程信息的元素。 - 爬取多个页面的数据
我们实现了翻页爬取功能,通过点击“下一页”按钮,自动获取每一页的课程信息。
3 页面滚动加载
- 由于页面中的部分课程信息需要滚动加载,因此在每页爬取之前,我们使用 Selenium 进行模拟滚动,使得所有课程信息加载出来,以便完整爬取。
4 数据存储
- MySQL 数据库创建和连接
爬取的数据需要存储到 MySQL 数据库中。我们首先创建了一个名为stocks的数据库,并创建了一张名为mooc的表,用于保存课程的相关信息。 - 数据表结构示例
CREATE TABLE mooc (id INT AUTO_INCREMENT PRIMARY KEY,cCourse VARCHAR(255),cCollege VARCHAR(255),cTeacher VARCHAR(255),cTeam VARCHAR(255),cCount VARCHAR(50),cProcess VARCHAR(100),cBrief TEXT ); - 每当成功爬取到一条课程信息,就将其插入到数据库中。
代码实现
以下是代码的主要部分,展示了如何使用 Selenium 进行数据爬取并将其存储到 MySQL 中:
import pymysql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from lxml import etree
import timeclass MoocScraper:def __init__(self):# 初始化浏览器配置try:chrome_options = Options()chrome_options.add_argument('--headless')self.driver = webdriver.Chrome(options=chrome_options)print("浏览器初始化成功")except Exception as e:print(f"浏览器初始化失败: {e}")self.initialize_db()def initialize_db(self):# 初始化数据库并创建表格try:mydb = pymysql.connect(host="localhost",user="root",password="密码",charset='utf8mb4')with mydb.cursor() as cursor:cursor.execute("CREATE DATABASE IF NOT EXISTS stocks CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci")cursor.execute("USE stocks")cursor.execute("""CREATE TABLE IF NOT EXISTS mooc (id INT AUTO_INCREMENT PRIMARY KEY,cCourse VARCHAR(255),cCollege VARCHAR(255),cTeacher VARCHAR(255),cTeam VARCHAR(255),cCount VARCHAR(50),cProcess VARCHAR(100),cBrief TEXT)""")mydb.commit()print("数据库初始化成功")except Exception as e:print(f"初始化数据库时发生错误: {e}")finally:if 'mydb' in locals():mydb.close()def login(self, url, phone, password):# 模拟登录过程...def scrape_courses(self, search_url):# 爬取课程信息...def parse_and_store(self, html):# 解析页面并存储到数据库...if __name__ == "__main__":scraper = MoocScraper()login_url = "https://www.icourse163.org/"search_url = "https://www.icourse163.org/search.htm?search=%20#/"scraper.login(login_url, '手机号', '密码')scraper.scrape_courses(search_url)scraper.close()
遇到的挑战和解决方案
- 页面加载等待:有些页面中的元素加载较慢,为了保证爬虫能够稳定地抓取到所有数据,我们使用了 Selenium 的显式等待和
time.sleep()来确保元素完全加载。
运行截图

总结
通过此次实战,我们利用 Selenium 成功地从中国 mooc 网站抓取了课程数据,并将其存储到了 MySQL 数据库中。整个过程涉及了网页结构分析、元素定位、翻页、数据存储等多个环节,是对 Selenium 爬虫技术的一个全面练习。通过这种方式,我们可以实现对在线课程信息的自动化采集,为后续的教育数据分析奠定基础。
如果你对代码实现有任何疑问,或者想了解更多关于 Selenium 的使用,欢迎在评论区与我交流!
3.华为云_大数据实时分析处理实验手册-Flume日志采集实验
1 Flume日志采集
1.1 任务一:Python脚本生成测试数据
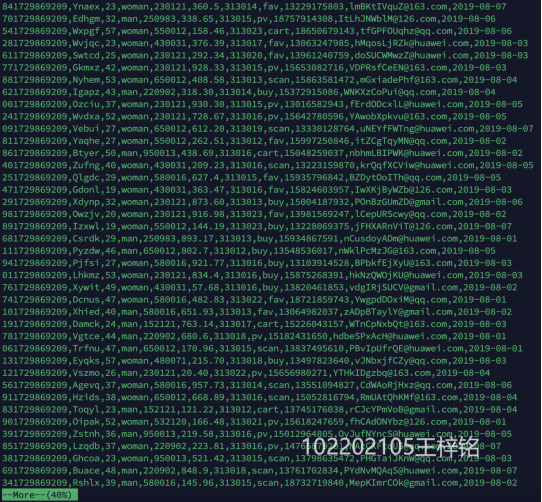
1.2 任务二:配置Kafka

1.3 任务三:安装Flume客户端
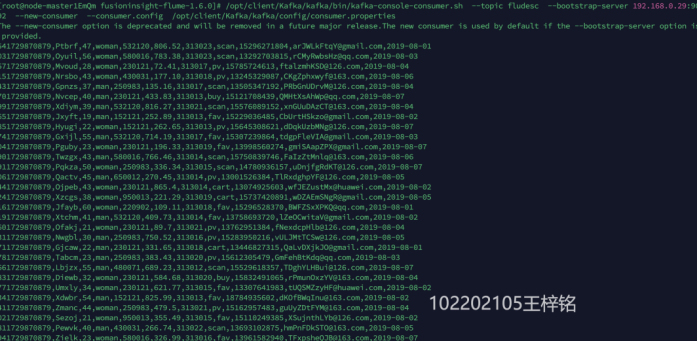
1.4 任务四:配置Flume采集数据