背景
由于Java字节码的抽象级别较高,因此它们较容易被反编译。本文介绍了几种常用的方法,用于保护Java字节码不被反编译。
通常,这些方法不能够绝对防止程序被反编译,而是加大反编译的难度而已,因为这些方法都有自己的使用环境和弱点。
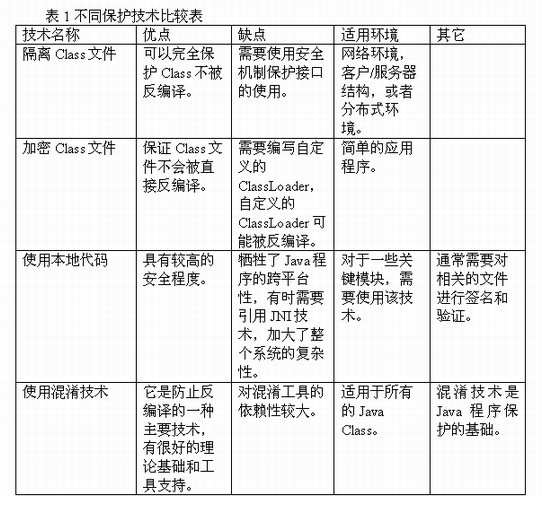
不同保护技术比较表
以下几种技术都有不同的应用环境,各自都有自己的弱点,表1是相关特点的比较。
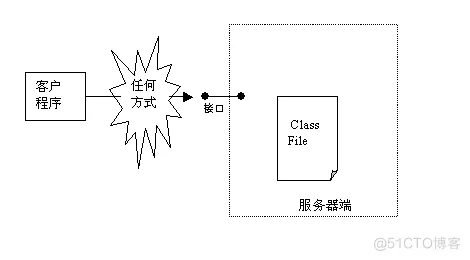
隔离Java程序
最简单的方法就是让用户不能够访问到Java Class程序,这种方法是最根本的方法,具体实现有多种方式。例如,开发人员可以将关键的Java Class放在服务器端,客户端通过访问服务器的相关接口来获得服务,而不是直接访问Class文件。
这样黑客就没有办法反编译Class文件。目前,通过接口提供服务的标准和协议也越来越多,例如 HTTP、Web Service、RPC等。但是有很多应用都不适合这种保护方式,例如对于单机运行的程序就无法隔离Java程序。这种保护方式见图1所示。
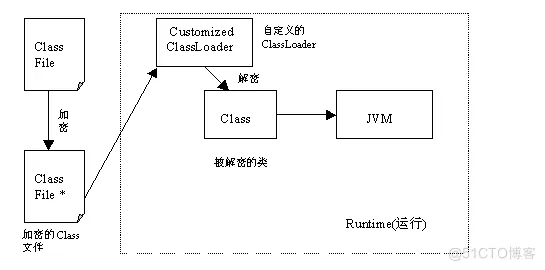
对Class文件进行加密
为了防止Class文件被直接反编译,许多开发人员将一些关键的Class文件进行加密,例如对注册码、序列号管理相关的类等。在使用这些被加密的类之前,程序首先需要对这些类进行解密,而后再将这些类装载到JVM当中。这些类的解密可以由硬件完成,也可以使用软件完成。
在实现时,开发人员往往通过自定义ClassLoader类来完成加密类的装载(注意由于安全性的原因,Applet不能够支持自定义的 ClassLoader)。自定义的ClassLoader首先找到加密的类,而后进行解密,最后将解密后的类装载到JVM当中。
在这种保护方式中,自定义的ClassLoader是非常关键的类。由于它本身不是被加密的,因此它可能成为黑客最先攻击的目标。如果相关的解密密钥和算法被攻克,那么被加密的类也很容易被解密。这种保护方式示意图见图2。
转换成本地代码
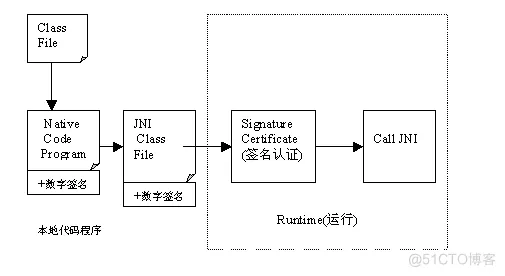
将程序转换成本地代码也是一种防止反编译的有效方法。因为本地代码往往难以被反编译。开发人员可以选择将整个应用程序转换成本地代码,也可以选择关键模块转换。如果仅仅转换关键部分模块,Java程序在使用这些模块时,需要使用JNI技术进行调用。
当然,在使用这种技术保护Java程序的同时,也牺牲了Java的跨平台特性。对于不同的平台,我们需要维护不同版本的本地代码,这将加重软件支持和维护的工作。不过对于一些关键的模块,有时这种方案往往是必要的。
为了保证这些本地代码不被修改和替代,通常需要对这些代码进行数字签名。在使用这些本地代码之前,往往需要对这些本地代码进行认证,确保这些代码没有被黑客更改。如果签名检查通过,则调用相关JNI方法。这种保护方式示意图见图3。
代码混淆
代码混淆是对Class文件进行重新组织和处理,使得处理后的代码与处理前代码完成相同的功能(语义)。但是混淆后的代码很难被反编译,即反编译后得出的代码是非常难懂、晦涩的,因此反编译人员很难得出程序的真正语义。
从理论上来说,黑客如果有足够的时间,被混淆的代码仍然可能被破解,甚至目前有些人正在研制反混淆的工具。但是从实际情况来看,由于混淆技术的多元化发展,混淆理论的成熟,经过混淆的Java代码还是能够很好地防止反编译。下面我们会详细介绍混淆技术,因为混淆是一种保护Java程序的重要技术。

混淆技术介绍
到目前为止,对于Java程序的保护,混淆技术还是最基本的保护方法。Java混淆工具也非常多,包括商业的、免费的、开放源代码的。Sun公司也提供了自己的混淆工具。它们大多都是对Class文件进行混淆处理,也有少量工具首先对源代码进行处理,然后再对Class进行处理,这样加大了混淆处理的力度。
目前,商业上比较成功的混淆工具包括JProof公司的1stBarrier系列、Eastridge公司的JShrink和 4thpass.com的SourceGuard等。主要的混淆技术按照混淆目标可以进行如下分类,它们分别为符号混淆(Lexical Obfuscation)、数据混淆(Data Obfuscation)、控制混淆(Control Obfuscation)、预防性混淆(Prevent Transformation)。
符号混淆
在Class中存在许多与程序执行本身无关的信息,例如方法名称、变量名称,这些符号的名称往往带有一定的含义。例如某个方法名为 getKeyLength(),那么这个方法很可能就是用来返回Key的长度。
符号混淆就是将这些信息打乱,把这些信息变成无任何意义的表示,例如将所有的变量从vairant_001开始编号;对于所有的方法从method_001开始编号。
这将对反编译带来一定的困难。对于私有函数、局部变量,通常可以改变它们的符号,而不影响程序的运行。但是对于一些接口名称、公有函数、成员变量,如果有其它外部模块需要引用这些符号,我们往往需要保留这些名称,否则外部模块找不到这些名称的方法和变量。因此,多数的混淆工具对于符号混淆,都提供了丰富的选项,让用户选择是否、如何进行符号混淆。
数据混淆
数据混淆是对程序使用的数据进行混淆。混淆的方法也有多种,主要可以分为改变数据存储及编码(Store and Encode Transform)、改变数据访问(Access Transform)。
改变数据存储和编码可以打乱程序使用的数据存储方式。例如将一个有10个成员的数组,拆开为10个变量,并且打乱这些变量的名字;将一个两维数组转化为一个一维数组等。对于一些复杂的数据结构,我们将打乱它的数据结构,例如用多个类代替一个复杂的类等。
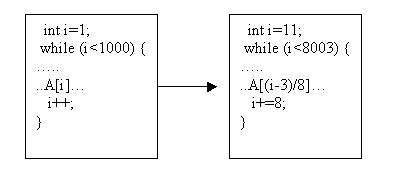
另外一种方式是改变数据访问。例如访问数组的下标时,我们可以进行一定的计算,图5就是一个例子。
在实践混淆处理中,这两种方法通常是综合使用的,在打乱数据存储的同时,也打乱数据访问的方式。经过对数据混淆,程序的语义变得复杂了,这样增大了反编译的难度。
控制混淆
控制混淆就是对程序的控制流进行混淆,使得程序的控制流更加难以反编译,通常控制流的改变需要增加一些额外的计算和控制流,因此在性能上会给程序带来一定的负面影响。有时,需要在程序的性能和混淆程度之间进行权衡。控制混淆的技术最为复杂,技巧也最多。这些技术可以分为如下几类:
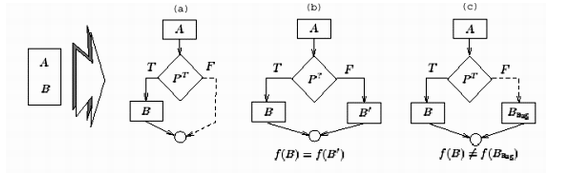
增加混淆控制通过增加额外的、复杂的控制流,可以将程序原来的语义隐藏起来。例如,对于按次序执行的两个语句A、B,我们可以增加一个控制条件,以决定B的执行。通过这种方式加大反汇编的难度。但是所有的干扰控制都不应该影响B的执行。
图6就给出三种方式,为这个例子增加混淆控制。
控制流重组重组控制流也是重要的混淆方法。例如,程序调用一个方法,在混淆后,可以将该方法代码嵌入到调用程序当中。反过来,程序中的一段代码也可以转变为一个函数调用。另外,对于一个循环的控制流,为可以拆分多个循环的控制流,或者将循环转化成一个递归过程。这种方法最为复杂,研究的人员也非常多。
预防性混淆
这种混淆通常是针对一些专用的反编译器而设计的,一般来说,这些技术利用反编译器的弱点或者Bug来设计混淆方案。例如,有些反编译器对于 Return后面的指令不进行反编译,而有些混淆方案恰恰将代码放在Return语句后面。这种混淆的有效性对于不同反编译器的作用也不太相同的。一个好的混淆工具,通常会综合使用这些混淆技术。

![LeetCode 1290[二进制链表转整数]](https://img2024.cnblogs.com/blog/3512406/202411/3512406-20241119142723024-564898353.png)