https://blog.csdn.net/qq_45922256/article/details/132917883
计算机三级等级考试笔记,是博主通过计算机三级数据库技术考试的相关笔记,此篇博客,不仅适合需要考计算机三级考试的各位考生,也适合在职场处理关于数据库的部分操作,个人认为算是一篇使用性比较强的文档,我个人认为,我目前所在开发岗位,在回顾去看这篇文档,我都会再次有收获。
第1章 数据库应用系统开发方法
一、系统规划与定义:
1、任务陈述。
2、确定任务目标。
3、确定系统范围和边界。
4、确定用户视图
二、可行性分区:
1、经济可行性。
2、技术可行性。
3、操作可行性。(各种人员资源,常考选择题)
4、开发方案选择。
三、数据字典:
1、数据项。
2、数据结构。
3、数据流。
4、数据存储。
5、处理过程。
四、数据处理需求(事务规范):
1、事务名称。
2、事务描述。
3、事务所访问的数据项。
4、事务用户。 注意:事务隔离级别不属于事务规范。(选择题)
五、性能指标:
1、数据操作响应时间。
2、系统吞吐量。
3、允许并发访问的最大用户数。
4、每TPS代价值。用于衡量系统性价比 的指标。
六、系统设计:
1、概念设计。(ER图)
2、逻辑设计。(ER图转关系模式) 包括:数据库逻辑结构设计、应用程序概要设计、数据库事务概要设计。
3、物理设计。(具体实现)
七、实现与部署:
1、建立数据库结构。
2、数据加载。
3、事务和应用程序的编码及测试。
4、系统集成、测试与试运行。
5、系统部署。
第2章 需求分析
一、获取需求的方法:
1、面谈。
2、实地观察。
3、问卷调查。
4、查阅资料。
二、软件需求说明书:
1、需求概述。
2、功能需求。(常考区分功能需求与非功能需求)
3、信息需求。
4、性能需求。
5、环境需求。(运行环境)
6、其他需求。
三、三种需求分析方法:DFD、IDEF0、UML。
DFD建模方法: 过程建模和功能建模方法都是结构化分析思路。
DFD(自顶向下逐步细化)
IDEF0
UNM
数据流(核心)、处理 、数据存储、外部项。 箭头(强调数据约束)、矩形框(活动) 系统、角色、
第3章、数据库结构设计
一、数据库概念设计:
两种数据建模方法: ER建模方法、IDEF1X建模方法
1、ER建模方法:第一大题
2、IDEF1X 建模方法:
a. 实体集:独立实体集(矩形框)、从属实体集(加圆角矩形框)。
b、联系:
①、标定型联系:两个实例确定第三个实例。(实线连接)
②、非标定型联系:唯一实例确定。(虚线连接) ③、分类联系:如学生可以是大学生、高中生、初中生。 ④、分确定联系:多对多关系
二、数据库逻辑设计(ER图转关系模式)
这个还好,就是将E-R图转换为数据库的名称描述
规范:
某个表(主键,列名。。。) 主键一般有下划线,外键可以是波浪线,一般可以来个描述,某个列是主键,某个列是外键。
三、数据库物理设计:
1、索引:
两大类:==有序索引、散列索引 ==
a、有序索引又可以分为: ①、聚集索引与非聚集索引:排列顺序相一致或不一致。 ②、稠密索引与稀疏索引:每个查找码都对应一个索引记录 或 只是一部分对应。 ③、主索引与辅索引:建立在主键上 或 非主键上。 ④、唯一索引:确保索引列不包含重复的值。 ⑤、单层索引与多层索引:没刷到过题。
2、物理设计内容:
a、数据库逻辑模式描述。(关系模式转换成基本表)
b、文件组织与存取设计。
c、数据分布设计。
d、确定系统配置。
e、物理模式评估。
基本表选择合适的文件结构原则:
①堆文件:数据量少,更新频繁。 ②顺序文件:查询条件在查找码上。 ③散列文件:访问顺序随机,
并且没有以下情况:
a、基于散列域值的非精确查询(模糊查询、范围查询)。
b、基于非散列域进行的查询。
④B-树和B+树文件:大数据量的基本表、等值查询、范围查询、模糊查询、部分查询。
⑤聚集文件:频繁执行且进行多表连接操作的查询。
适合建立索引原则:
①、表的主键。
②、在where查询子句中引用率较高的属性。
③、参与连接的属性。
④、group by 与 order by子句中的属性。
⑤、对于经常需要进行查询、连接、统计操作,且数据量大的基本表。
第4章 数据库应用系统设计与实施
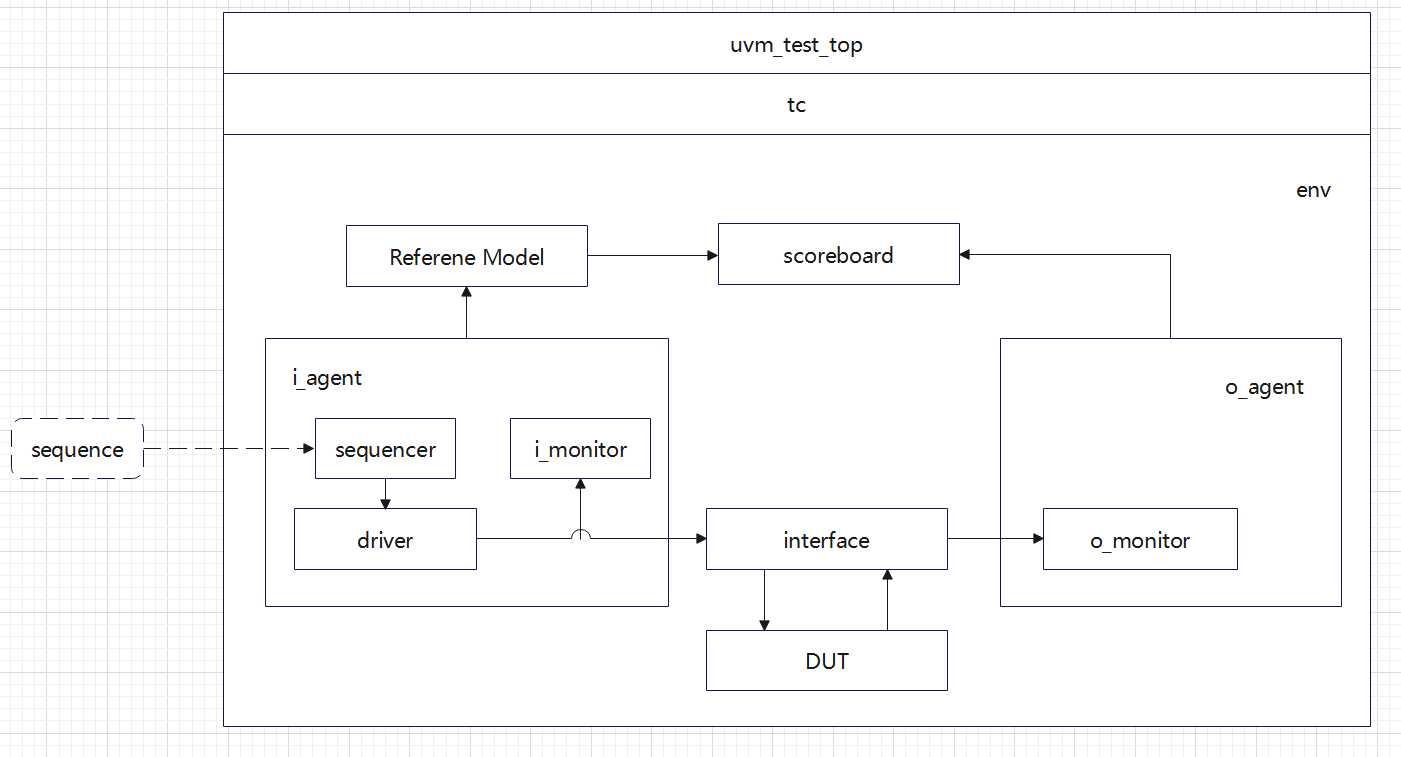
一、DBAS体系结构设计
1、客户 / 服务器体系结构(两层 C / S)
2、浏览器 / 服务器结构 (三层 B / S)
表示层:位于客户端。
功能层:位于Web应用服务器。
数据层:位于数据库服务器。
二、DBAS功能概要设计
从功能角度划分
1、表示层:进行人机界面设计。
2、数据逻辑层:梳理DBAS的各项业务活动,减去表示为各种系统架构。传输数据的作用。
3、数据访问层:设计操作数据库的事务。负责与DBMS系统进行交互。
4、数据持久层:进行应用系统的存储结构设计。保存和管理应用系统数据。
高内聚,松耦合原则:
a、单一责任原则。
b、各个构件均应具有独立的功能。
c、构件之间的接口应尽量简单明确。
d、构件间关系比较复杂,进一步模块划分。
e、构件间关系过于复杂,细分。
事务设计:
1、事务规范(数据处理需求):事务名称、事务描述、事务所访问的数据项、事务用户等。
2、两个元操作:read、write
3、事务隔离性级别越高,安全性越高,性能越低,同时事务的隔离级别和数据库并发性是对立的。
4数据库的一致性:事务执行成功则全部提交,如果一个事务提交失败,则做过的所有更新则全部撤销。
三、安全架构设计
安全可靠性是应用系统的重要衡量指标。
1、数据安全设计
数据库的安全性保护:
a、用户身份鉴别。 b、权限控制。 c、视图机制。
数据库的完整性保护: 完整性:是指数据库中数据的正确性、一致性、相容性。 方法:设置完整性检查。 检查数据表时(select等)不会检查数据的完整性约束。
两段锁协议: 指所有事务必须分两个阶段对数据项加锁和解锁。
1、在对任何数据进行读、写操作之前,要申请并获得对该数据的封锁。
2、在释放一个封锁之后,事务不再申请和获得其他任何封锁。 可以证明,若并发执行的素有事务均遵守两段锁协议。则对这些事务的任何并发调度策略都是可串行化的。 也可能发生死锁。 加锁协议事务可以申请获得任何数据项的任何类型的锁,但不允许释放任何锁。 一次封锁法: 要求每个事务必须一次将所有要使用的数据全部加锁。一次封锁法遵守两段锁协议,但两段锁协议并不要求一次全加锁。
三级加锁协议:保证数据的一致性。 检测死锁:检测事务等待图 是否出现回路。
数据库并发控制: 封锁技术:排它锁(x锁)、共享锁(s锁)
避免死锁的方法:
a、按同一顺序访问资源。
b、避免事务中的用户交互。
c、采用小事务模式,尽量缩短事务的长度,减少占有锁的时间。
d、尽量使用记录级别的锁(行锁),少用表级别的锁。
e、使用绑定连接,使同一应用程序锁打开的两个或多个连接可以相互合作。
数据库的备份与恢复:
a、双机热备。 b、数据转储。 c、数据加密存储。
数据加密传输:
a、数字安全证书。 b、对称密钥加密。 c、数字签名。 d、数字信封。
2、环境安全设计
漏洞与补丁
计算机病毒保护: a、安装杀毒软件,定期查杀病毒。 b、计算机实时监控。
网络环境安全: a、防火墙。 b、入侵检测系统。 c、网络隔离。
物理环境安全
四、DBAS实施
1、创建数据库: a、初始空间大小。 b、数据库增量大小。 c、访问性能。
2、数据装载: a、筛选数据。 b、转换数据格式。 c、输入数据。 d、校验数据。 3、编写与调试应用程序 4、数据库系统试运行: a、功能测试。 b、性能测试。
第5章 UML与数据库应用系统
UML四层建模概念框架 1、元元模型层。 2、元模型层。 3、模型层。 4、用户模型层。
13种图 结构图(静态)6种:类图、对象图、复合结构图、包图、组件图、部署图。 简记:类对复包组部
行为图(动态)7种:用例图、顺序图、通信图、交互概述图、时间图、状态图、活动图。 简记:用顺通交时状活
一、类图:
类图关系:
泛化:——▷ 父类
实现:------▷ 接口(被实现类)
关联:——> 被拥有者
聚合:——◇ 整体
组合:——◆ 整体
依赖:------> 被使用者
二、对象图:
系统某个时间的所有对象的快照。
三、复合结构图:
最主要元素:部件。
四、包图:
用于表达系统中不同的包、命名空间或不同的项目间彼此关系的图。 包与包之间不能共享一个相同的模型元素。
五、组件图:
表示系统的静态实现视图,展现一组组件之间的组织和依赖。
六、部署图:
描述系统运行时的结构,展现硬件的配置及其软件如何部署。只有一个部署图,帮助理解分布式系统。
七、用例图:
主要组成: 用例、角色、系统。用例之间的关系:扩展、使用、组合
八、顺序图:
强调时间。 用于描述系统内部的动态结构,主要用于描述系统内对象之前的消息发送与接收序列。
九、通信图(协作图):
强调空间。表达对象之前的联系以及对象间发送和接收消息的图。
十、交互概述图:
活动图为基础。
十一、时间图:
作为状态图的辅助说明工具。
十二、状态图:
描述一个对象在其生存期内的动态行为。状态间的转移。状态之间的转移是由事件 驱动的。
十三、活动图:
描述系统、用例、程序模块中逻辑流程的先后执行次序。
第6章 高级数据查询
一、一般数据查询功能扩展
1、使用TOP 限制结果集
【distinct】 TOP n 【percent】【with ties】
1
distinct :不重复的
percent:使用%显示
whit ties:取并列结果 通常TOP与order by 排序一起使用
2、case 函数
简单case函数:
case 测试表达式 when 简单表达式1 then 结果表达式 … [ else 结果表达式 ] end
搜索case函数 与简单case函数形式的区别是 case 后面不跟有测试表达式
3、将查询结果保存到新表中(into语句)
select 列名 into 新表名 from …
新表可以是永久表,也可以是临时表。 临时表区别: 局部临时表(#table)、全局临时表(##table)
二、查询结果的并、交、差运算
并运算(UNION):将两表进行垂直连接。
交运算 (INTERSECT):取两表相交部分。
差运算 (EXCEPT):表1 - 表2
并交差运算与 join 连接不同的是join是水平合并数据,而并交差则是垂直合并数据。 常考:选择填空题。
三、子查询
运算符 IN 与NOT IN :将表达式与子查询返回的结果集进行比较。 比较运算符:子查询返回的必须是单值。 以上两者都是不相关子查询,即先执行内层查询,在执行外层查询,子查询的查询条件不依赖外层循环。 使用子查询进行存在性测试
关键字:EXISTS 与 NOT EXISTS 子查询返回的结果为 真值或假值。 区别 : 带EXISTS谓词的查询是先执行外层查询,然后在执行内层查询。相关子查询。
四、聚合函数与开窗函数
聚合函数 :SUM、COUNT、AVG、MIN、MAX count(*)返回表中的行数,不会过滤null和重复的行,但count(列名)会过滤 null
开窗函数 :OVER(【partition by】,【order by】)
1、聚合开窗函数 聚合函数与开窗函数的结合 如: SUM OVER (PARTITON BY 列名) …
2、排序开窗函数
RANK() :有重复,但不连续的排名。
DENSE_RANK():有重复,但连续的排名。
NTILE():用于将分组数据按照顺序切分成n片,返回当前切片值。将一个有序的数据集划分为多个桶(bucket),并为每行分配一个适当的桶数(切片值,第几个切片,第几个分区等概念)。它可用于将数据划分为相等的小切片,为每一行分配该小切片的数字序号。
ROW_NUMBER(): row_number() OVER (PARTITION BY COL1 ORDER BY COL2)
表示根据COL1分组,在分组内部根据COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)。
聚合函数与开窗函数都是位于select 【】 from
五、派生表与公用表
1、派生表(内联视图) 如:(select * form table) AS 别名
2、公用表 如 WITH 公用表名(列名) AS (select * from table)
需要死记得关键字: distinct(不重复的)、percent(百分比)、with ties (取相同)、UNION(并)、INTERSECT(交)、EXCEPT(差)、EXISTS(存在)。
第7章 数据库及数据库对象
一、创建及维护数据库
1、两大类:
系统数据库 (自动创建和维护的):
master:最重要的数据库,记录所有系统级信息,主要的信息都是存放在这。
msdb:保存报警、作业、操作员等信息。(考的不多,选择判断题)
model:所有创建数据库的模板。
tempdb:临时数据库,每次启动SQL都会重新创建,因此不需要备份。 用户创建的局部和全局临时表均被自动放置在改数据库中。
Resource:只读数据库。(没见过考)
用户数据库(用户创建和维护)
经常考选择题:系统数据库如何备份?(未完成)
2、数据库文件分类
数据文件:
主要数据文件:每个数据库中只有一个,第一个数据文件,推荐扩展名:mdf。
次要数据文件:可以有0~n个,推荐扩展名:ndf.
总结:主要数据文件有且只有一个,而次要数据文件可以有0或多个,可以建立在多个磁盘上。两者对用户来说没有区别,在多个不同的磁盘中建立多个数据文件,有利于利用存储空间,以及提高数据的存取效率。
日志文件 每个数据库至少有一个日志文件(创建数据库时,如果没有创建日志文件,系统自动创建日志文件),推荐扩展名:ldf。
3、数据库存储空间的分配
数据库的存储分配单位是数据页,其中一数据页的大小是 8k ,一行数据不能存储在不同的数据页中(行不能跨页存储)。
经常考填空题:一个数据表中 n 行数据,每行 m 字节,则需要多少MB的存储空间,以及空间利用率为多少? 解法:n 行数据需要 a
页数据页,则需要 8a MB的存储空间。空间利用率等于:每页数据页实际使用的空间 除以 一页数据页总共的空间。
4、文件组
主文件组:一个数据库只有一个默认文件组,一般默认为Paimary,存放主要数据文件和未明确分配文件组的次要数据文件。
特别: 1、日志文件不存放在文件组中,日志空间与数据空间是分开管理的。 2、一个文件不可是多个文件组的成员。
经常考点:主要数据文件、次要数据文件、日志文件可以有多少个?可以存放的位置等问题。
5、创建数据库
create database db_name on [指定的文件组]
1
( name = db_data, //逻辑名 filename = ‘F:\Data\db_data.mdf’, //物理名 size = 2mb, //初始大小 maxsize = 10mb, //最大大小 filegrowth = 2 //自动增长 ) log on ( … )
6、修改数据库
扩大数据库两种方法:
一:add 添加数据文件 alter database db add file( …与创建数据库时相同 )
添加日志文件 alter database db add log file( … )
添加文件组 alter database db add filegroup group_name
二:modify alter database db modify file( name = 逻辑名, …修改内容 size = filegrowth = )
收缩数据库空间的两种方法 文件收缩都是从末尾开始的
一:收缩整个数据库大小 DBCC shrinkdatabase (database_name, 大小 )
二:收缩数据库中某个文件的大小 DBCC shrinkfile (file_name,大小)
删除数据库文件
alter database db remove file file_name
1
7、分离和附加数据库
分离:从SQL server 实例中删除,但不删除数据库中的数据文件和日志文件。 EXEC sp_detach_db ‘db_name’,‘true’
附加:创建一个新的数据库。。。
经常考点选择题:分离数据库是否需要停止数据库。
1、在分离数据库之前,必须先断开所有用户与该数据库的连接。
2、分离数据库会分离数据文件和日志文件。
3、分离和附加的位置可以不同。
4、进行分离数据库操作不能停止SQL server 服务。
二、架构
架构:逻辑命名空间,他是一个数据库对象的容器。架构相当于文件夹(不能同名,可以有多个),对象相当于文件(不同文件夹下的文件可以同名)。
关键字:
CASCADE:所有架构对象一起全部删除。
RESTRICT:包含架构对象则拒绝。
创建架构: create schema 【架构名】authorizetion 用户名
删除架构: DROP schema 架构名
考点:选择题
三、分区表
a、分区表是水平划分的子集。
b、优点:可以快速且有效地管理和访问数据子集。
c、是否创建分区表?(选择题) 主要取决于表当前的数据量大小以及将来的数据量大小,同时还取决于对表中数据进行的操作。
d、物理上将一张大表分成几张小表,逻辑上还是大表。
1、分区表两大步骤
创建分区函数:告诉数据库管理系统以什么方式对表进行分区。
create partition function PF_name(数据类型) as range [ left ] for values(分段1,分段2,分段3)
1
创建分区方案:将分区函数生成的分区映射到文件组中。
create partition scheme PS_name as partiton PF_name to(文件组1,文件组2,文件组3,文件组4)
1
PS:指定的文件组数一定要大于或等于分区函数所划分的分区数
四、索引
索引的创建: 关键字:
UNIQUE:唯一索引。 CLUSTERED:聚集索引。 NONCLUSTERED:默认选项,非聚集索引。
通常创建唯一聚集索引为:(填空题,加粗字体必背)
CREATE UNIQUE CLUSTERED INDEX DROP
CREATE UNIQUE CLUSTERED INDEX index_name ON Table_name(cname)
1
对索引键值进行升降排序: ps:系统默认查询结果按升序ASC排序。
CREATE INDEX index_name ON Table_name(cname1 ASC, cname2 DESC)
1
删除索引:
DROP INDEX index_name
1
五、索引视图
标准视图(虚拟表)结果集并不存储在数据库中,如果频繁使用这类视图会导致开销很多。 因此可以对视图创建唯一聚集索引的方式来提高查询性能。 对视图创建唯一聚集索引后,视图的结果集将存储在数据库中,就像带有聚集索引的表一样。成为索引视图(物化视图)。
做题: 索引视图可以提高查询类型的性能: 1、处理大量行的连接和聚合。 2、查询经常执行连接和聚合。 3、决策支持工作负荷。 总结:连接和聚合使用索引视图。
4、视图可以在视图上再定义视图。
考点:填空题,加粗字体。
需要死记得关键字:
primary(主要的)、create(创建)、filegrowth(增长)、modify(修改)、alter(改变)、DBCC、shrinkdatabase(收缩数据库)、shrinkfile(收缩文件)、remove(移除)、EXEC(执行)、
sp_detach_db(分离数据库)、DROP、schema(架构)、scheme(方案)、partition(划分)
第8章 数据库后台编程技术
一、存储过程
存储过程用于存储和执行T-SQL代码。 好处: 1、允许模块化程序设计。 2、改善性能。 3、减少网络流量。 4、增强应用程序的安全性。
创建存储过程
create procedure proc_name @parameter data_type , … @parameter2 type output AS T-SQL代码
1
执行存储过程
declare @x int , @y int EXEC proc_name ‘输入’ , @x output,@y output
1
删除存储过程
DROP PROC name
1
二、用户定义函数 (大题常考)
标量函数
返回值
创建标量函数
create function function_name(@parameter) returns type AS begin declare @x int T-SQL语句 return @x end
1
调用标量函数 函数拥有者名.函数名
内联函数
返回表
创建内联表值函数
create function name(@parameter) returns table AS return (T-SQL)
1
多语句表值函数
创建多语句表值函数
create function name(@parameter) returns @table_name table( 列名 type, … ) AS begin insert into @table_name T-SQL return end
1
删除用户自定义函数
DROP FUNCTION name
1
总结:存储过程与用户自定义函数的区别
1、存储过程相当于对复杂T-SQL进行预编译封装。
2、用户自定义函数相当于其他编程语言中的函数方法。
区别:
1、声明时,存储过程参数不需要使用括号,并且在输出参数后使用 output 。
2、用户自定义函数必须要有retrun返回值。
3、用户自定义函数一般使用BEGIN和END 将T-SQL语句包围起来。
总结:用户自定义函数中的区别
不同:
1、标量函数返回的是一个值。
2、内联表值函数返回的是select 查询 的一个表,类似于视图。并且一般不使用BEGIN和END。
3、多语句表值函数返回的是新定义的表。
相同:
1、他们的创建语句基本相同,不同的是返回类型。
2、调用方法相同。
三、触发器
一种特殊的存储过程,不需要由用户来直接调用,自动触发执行。 SQL Server 2008中有五种约束类型:主键约束、外键约束、唯一约束、缺省约束、检查约束。
触发器通常用在下列场合: 1、完成比CHECK约束更复杂的数据约束。(check约束只能实现同一个表中列之间的取值约束) 2、为了保证数据库性能而维护的非规范化数据。 3、可实现复杂的商业规则。 4、触发器也可以评估数据修改前后的表状态,并根据其差异采取对策。
三种触发器: 1、DML触发器(只讲)。2、DDL触发器。3、登录触发器。
1
创建触发器
create trigger trigger_name on table for [ after ][ instead of ] 操作类型(insert ,updata,delete) AS T-SQL
1
触发器的区别: 1、后触发型触发器: 使用FOR 或 AFTER 定义的触发器。(即等引发触发器执行的操作都已成功执行才执行触发器操作) 使用ROLLBACK撤销不正确的操作。(实际是回滚到引发触发器执行的操作之前的状态) 后触发型触发器同一个操作可以有多个触发器。 几个用途: a、维护数据操作完整性的触发器。 b、维护不同列之间的取值完整性的触发器。 c、维护数据的一致性的触发器。
2、前触发型触发器: 使用 INSTEAD OF 选项定义的触发器。(即不执行引发触发器的操作) 前触发型触发器同一个操作只能有一个触发器。
两个特殊的临时工作表:
INSERTED表与 DELETED表。
对于三种操作,insert 、updata、delete 的数据存放。
insert 、delete更新删除的数据存放到对应的表中,而updata操作前的数据存放到DELETED表中,操作后的数据存放到INSERTED表中,updata操作相当于对表数据先进行删除,然后在对表数据进行插入。
四、游标
声明游标 --> 打开游标 --> 提取数据 --> 关闭游标 -->释放资源
提取数据: FETCH
需要死记的关键字: procedure(程序)、declare(声明)、execute(执行)、trigger(触发)、ROLLBACK(回滚)、for after (后触发型)、instead of (前触发型)
第9章 安全管理
一、登录账户
创建登录账户:
create login log_name [ whit | from ] windows 用户名 | password = ‘ ’
1
修改登录账户:
alter login log_name enable | disable
1
删除登录账户:
drop login log_name
1
二、数据库用户
建立数据库用户:
create user user_name
1
删除数据库用户:
drop user user_name
1
三、Guest 用户
一个特殊的数据库用户。 启用:具有连接权限
grant connect to guest;
1
禁用:收回连接权限
revoke connect to guest
1
四、权限管理
授权语句:
grant 操作(select、insert、update、delete)on 被授权的对象(表、存储过程等) to 用户
1
拒绝权限:
deny 操作 on 被被授权对象 to 用户
1
授权语句:
revoke 操作 on 被授权对象 to 用户
1
语句级别的权限:
create database create procedure create table create view create function backup database backup log
1
五、角色
1、固定服务器角色
九大服务器级角色:
bulkadmin:不常见。
dbcreator:具有创建、修改、删除和还原数据库的权限。常考
diskadmin:具有管理磁盘的权限。
processadmin:不常见。
securityadmin:不常见。
serveradmin:具有设置服务器级别的配置选项和关闭服务器的权限。
setupadmin:不常见。
sysadmin:具有在服务器及数据库上执行任何操作的权限。常见
授权与删除:
授权:sp_addsrvrolemember
删除:sp_dropsrvrolemenber
ps:用户和角色语句位置的顺序: 先用户后角色
2、固定数据库角色
数据库级角色:
db_accessadmin:具有添加或删除数据库用户的权限。不常见
db_backupoperator:具有备份数据库、备份日志的权限。不常见
db_datareader:具有查询数据库中所有用户数据的权限。
db_datawriter:具有插入、删除、更改数据库中所有用户数据的权限。
db_ddladmin:具有执行数据定义语言(DDL)的权限。
db_denydatareader:不允许,与db_datareader权限相反。
db_denydatawriter:不允许,与db_datawriter权限相反。
db_owner:具有全部操作的权限。
db_securityadmin:具有管理权限。
授权与删除:
授权:==sp_addrolemember ==
删除:sp_denyrolemember
ps:用户和角色语句位置的顺序:先角色后用户
共同点: 固定数据库角色与固定服务器角色都具有一个相同的角色:public
3、用户定义的角色
create role name【authorization】用户或角色
1
需要死记的关键字:enable(启用)、disable(禁用)、grant(允许)、revoke(撤回)
第10章 数据库运行维护与优化
一、维护工作主要包括:
1、数据库的转储与恢复。
数据库管理员需要定期对转储的数据进行恢复测试工作。
2、数据库的安全性、完整性控制。
通过行政手段制定规范。
3、检测并改善数据库的性能。
4、数据库的重组与重构。
重组:不修改数据库原有设计的逻辑结构和物理结构。 重构:部分修改数据库的模式和内模式。
二、运行状态监控与分析:
1、自动监控机制。 2、手动监控机制。 分为对数据库构架体系的监控和对数据库性能的监控。
三、数据库性能优化。
1、外部调整:
当CPU在业务空闲时使用率超过90%,说明服务器缺乏CPU资源。
2、模式调整与优化:
a、增加派生性冗余列。(总价=单价*数量) b、增加冗余列。 c、重新组表。 d、分割表。 e、新增汇总表。
3、存储优化:
a、物化视图。 b、聚集。
4、查询优化:
a、合理使用索引。 b、避免或简化排序。 c、消除对大型表数据的顺序存取。 d、避免复杂的正则表达式。 e、使用临时表加速查询。 f、用排序来取代非顺序磁盘存取。 g、不充分的连接条件。 h、存储过程。 i、不要随意使用游标。 j、事务处理。
第11章 故障管理
一、四类故障:
1、事务内部故障:大部分是非预期的,由系统自动完成。 2、系统故障(软故障):所有正在运行的事务以非正常方式终止,需要系统重启。 3、介质故障(硬故障):破坏性最大。 4、计算机病毒故障:破坏方式以破坏数据库文件为主(不多见)。
二、数据转储(数据备份):
1、静态转储:转储操作和事务是互斥的,保证转储前后的一致性。 2、动态转储:允许转储操作和用户事务并发执行,但不能保证转储数据的一致性。
三、数据转储机制:
1、完全转储。 2、增量转储:只复制上次转储后发生变化的文件或数据块(复制部分)。 3、差量转储:对最近一次完全转储以来发生变化的数据进行转储。
4、完全转储加增量转储:其中任何一次转储出现问题都会导致恢复的失败,同时恢复时间较长。 5、完全转储加差量转储:操作简单,恢复时间短。但是需要移动和存储更多数据。
四、日志文件:
1、以记录为单位的日志文件: 日志文件中有BEGIN TRANSACTION 记录,而没有COMMIT 或 ROLLBACK 执行 UNDO操作。 日志文件中既有BEGIN TRANSACTION 记录,也有 COMMIT 或 ROLLBACK 执行REDO操作。
2、以数据块为单位的日志文件。
什么时候使用日志文件:
1、事务故障恢复和系统故障恢复必须使用日志文件。 2、在动态转储方式中必须建立日志文件。 3、在静态转储方式中,也可以使用日志文件。 检查点技术大幅度减少了数据库恢复时执行的日志恢复操作量。
五、磁盘保护技术:
1、RAID0:优点采用数据分块、并行传送方式,能够提高读写速度。缺点出现介质故障时无法恢复。 2、RAID1:提高了读速度,加强了系统的可靠性。缺点:硬盘的利用率低,冗余度为50%,同时写速度并未提高。 3、RAID5:磁盘空间利用率比RAID1高,存储成本相对较低。
六、数据库镜像分类:
1、双机互备援模式。 2、双机热备份模式。 3、三种实现方式:高可用性、高保护、高性能。
第12章、备份与恢复数据库
一、造成数据丢失的原因:
1、存储介质故障。 2、用户的操作错误。 3、服务器故障。 4、由于病毒的侵害而造成的数据丢失或损坏。 5、由于自然灾害而造成的数据丢失或损坏。
二、恢复模式:
1、简单恢复模式: 只用于测试和开发数据库或只读数据库,不备份事务日志、 2、完整恢复模式: 完整记录所有的事务,备份日志文件。 3、大容量日志恢复模式: 完整恢复模式的附加模式。
三、数据库备份:
1、完整数据库备份(完全转储): 备份所有。 2、差异数据库备份(差异转储):备份最近一次完整数据库备份之后的数据。
两种备份都备份在备份过程中用户对数据库进行的操作。
四、文件备份:
1、文件备份。 2、差异文件备份。
五、事务日志备份:
只备份日志记录。
1、纯日志备份: 不包含大容量备份模式下执行的任何大容量更改的备份。 2、大容量操作日志备份: 不允许对大容量操作日志备份进行时点恢复。 3、结尾日志备份: 在出现故障时进行,用于防止丢失数据。
ps:结尾日志备份可以防止数据丢失并确保日志链的完整性。 日志文件中包含恢复点或者希望移动或替换(覆盖)数据库,不一定需要结尾日志备份。
六、常用备份策略:
1、完整数据库备份 2、完整数据库备份加日志备份 3、完整数据库备份加差异数据库备份加日志备份
七、实现备份:
备份数据库与文件组:
backup database data_name to 备份设备 【with differential】 (进行差异备份,默认完全备份) 【disk | tape 】指定磁盘文件或磁带设备
1
备份日志:
backup log data_name to 备份设备 norecovrey
1
实现还原:
restore database data_name
1
第13章、大规模数据库架构
一、分布式数据库:
分布式数据库系统与分布式数据库的区别: 分布式数据库系统:物理上分散、逻辑上集中的数据库系统。 分布式数据库:是分布式数据库系统中各场地上数据库的逻辑集合。
分布式数据库的12个目标:
1、本地治理。 2、非集中式管理。 3、高可用性。 4、位置独立性。 5、数据分片独立性。 6、数据复制独立性。 7、分布式查询处理。
8、分布式事务管理。 9、硬件独立性。 10、操作系统独立性。 11、网络独立性。 12、数据库管理系统独立性。
数据分布策略: 先数据分片、后数据分配。
数据分片: 水平分片、垂直分片、导出分片、混合分片。
数据分配: 集中式、分割式、全复制式、混合式。
分布透明性:
1、分片透明性:最高级别、完全透明。
2、位置透明性:指数据分片的分配位置对用户是透明的。
3、局部数据模型透明性:不需要了解数据模型。
分布式数据库查询代价: 由CPU代价和 I/0代价来衡量,要考虑站点间传输数据的通信代价。 导致数据传输量大的主要原因:数据间的连接操作和并操作。
分布式事务管理: 恢复控制和并发控制。 恢复控制:基于二阶段的提交协议。 并发控制:基于封锁协议。
2、并行数据库:
体系结构: 1、共享内存结构:共享一个主存储器,实现简单、容易造成访问内存冲突。 2、共享磁盘结构:共享磁盘,会产生通信代价。 3、无共享结构:不共享任何资源。最好并行结构。缺点:通信代价和非本地磁盘访问的代价高。 4、层次结构:顶层无共享结构、底层共享内存或共享磁盘结构。
数据划分: 1、轮转法:顺序扫描、评价分配、适合于扫描整个关系。缺点:不适于点查询 和 范围查询。 2、散列划分:适合点查询 。缺点:散列函数的选用。 3、范围划分:适合点查询和范围查询。但是会造成数据分布不均匀。
3、云计算:
软件即服务(SaaS):软件分配模式。
平台即服务(PaaS):通过网络提供操作系统和相关服务,无需下载或安装。
基础设施即服务(IaaS):将用于支持运作的设备对外提供服务。
公共云: 即用即付的方式提供给公众。
私有云: 不对公众开放的企业或组织内部数据中心的资源。
目前主要的云计算平台: Amazon 的 AWS 、Goodle 的GAE 、开放的云计算平台Hadoop。
云计算的缺点: 1、数据安全问题。 2、对云的管理问题。 3、对因特网的依赖。
Google开发的模型简化的大规模分布式数据库BigTable: 索引: 行关键字、列关键字、时间戳。共同定位。
特点: 1、行关键字可以是任意的字符串。 2、列族是由列关键字组成的集合,是访问控制的基本单位。 3、时间戳记录BigTable中不同版本数据的时间标识。
第14章 数据仓库与数据挖掘
一、数据仓库:
是一个面向主题的 、集成的 、非易失的 、且随时间变化的数据集合,用来支持管理人员的决策。
体系结构: 操作型数据、操作型数据存储、数据仓库、数据集市、个体层数据(临时数据)。
四个级别: 1、早期细节级:老化以后的细节数据。 2、当前细节级:经过集成后,进入当前细节级。 3、轻度综合级:对当前细节级进行轻度综合。 4、高度综合级:对当前细节级进行高度综合。
粒度: 综合级别称为粒度。 粒度越小,细节程度越高,数据量越大。
元数据: 描述数据的结构、内容、链、索引等内容。 技术型元数据: 描述关于数据仓库技术细节的数据。 业务型元数据: 从业务角度描述了数据仓库中的数据。
ODS: 面向主题的、集成的、可变的、数据是当前或接近当前的。
ODS I: 第一类秒级。 ODS II:第二类小时级。 ODS III:第三类天级。 ODS IV:第四类根据数据来源方法和类型划分。
数据仓库的设计过程: 概念模型设计、技术评估、环境准备工作、 逻辑模型设计、物理模型设计、数据生成与应用实现、数据仓库运行与维护。
数据仓库的更新维护: 维护策略: 实时维护:触发条件:数据源进行数据的更新操作。(软硬件性能要求很高,难以实现) 延时维护:触发条件:数据发生变化后首次进行查询操作。(视图查询时间相对比较长) 快照维护:触发条件:时间。(通常无法提供最新的数据,广泛使用)
二、OLAP
多维分析的基本操作: 1、钻取与卷起。 2、切片与切块。 3、旋转。
OLAP的实现方式: 1、基于多维数据库的OLAP(MOLAP)。 2、基于关系数据库的OLAP(ROLAP)。 3、混合型的OLAP(HOLAP)。
三、数据挖掘:
三阶段: 数据准备、数据挖掘、结果解释评估。
关联规则挖掘: 1、支持度: 两者都买,占总数据仓库的百分比。 2、置信度: 两者都买,占其中买X的百分比。(买了X中有多少人买了Y的百分比)
分类挖掘: 构造方法:统计方法、机器学习方法、神经网络方法。
聚类挖掘: 使得每一组内的数据尽可能的相似而不同组间的数据尽可能的不同。 包括:统计方法、机器学习方法、神经网络方法、面向数据库的方法。
常见的创建语句:
CREATE DATABASE -----> 创建数据库
CREATE PARTITION FUNCTION -----> 创建分区表
CREATE UNQUE CLUSTERED | NONCLUSTERED -----> 创建索引
CREATE PROC ----->创建存储过程
CREATE FUNCTION -----> 创建标量|内联表值|多语句表值函数
CREATE TRIGGER -----> 创建触发器
事务的几种性质:
1、一致性: 2、完整性: 3、可串行性:两段锁协议保证
遗忘:
1、触发器通常用于保证业务规则和数据完整性。 2、与触发器相关的两张表使用大写(傻逼软件不区分大小写)
数据库设计各阶段所包含的内容:
逻辑设计阶段: 数据库逻辑结构设计、数据库事务概要设计、应用程序概要设计 概念设计阶段: 系统总体框架设计 物理设计阶段: 数据库逻辑模式调整、文件组织与存取设计、数据分布设计、安全模式设计、确定系统配置、物理模式评估 数据库运行和维护阶段: 日常维护、监控与分析、性能优化与调整、系统进化。 数据库实现和部署阶段: 创建数据库、数据装载、应用程序的编码和调试、数据库的试运行
数据库应用系统设计的四个层次:
1、表示层: 2、业务逻辑层: 3、数据访问层: 4、数据持久层: 设计工作属于数据组织与存储等方面的物理设计内容(包括索引设计),属于物理设计阶段
最后大题:
一、针对数据库系统本身及网络传输过程中可能的一些调优方案:
1、把数据、日志、索引放到不同的I/O设备上,增加读取速度,数据量越大,提高I/O越重要。 2、纵向、横向分割表,减少表的尺寸。
3、升级硬件,扩大服务器的内存,增加服务器CPU个数。
4、重建索引,收缩数据和日志,设置自动收缩日志,对于大的数据库不要设置数据库自动增长,它会降低服务器的性能。 5、优化锁结构。
二、SQL查询语句优化方案:
1、对查询进行优化,应尽量避免全表扫描,首先应考虑在where 及 order by 涉及的列上建立索引。
2、应尽量避免在where子句中使用 != 或 < > 操作符,否则将引擎放弃使用索引而进行全表扫描。
3、任何地方都不要使用select * from进行全表扫描,用具体的字段列表代替 “ * ” ,不要返回冗余字段。
4、避免频繁创建和删除临时表,以减少系统表只有的消耗。
5、尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
6、尽量避免大事务操作,提高系统并发能力。
三、对使用UNION 对大量数据进行查询的优化方法:
使用 union all 替代 union 进行合并查询,原因是union会自动压缩多个结果集中重复的数据(删除合并后重复的数据),而union all 则将所有的结果显示出来,减少了操作量。
四、磁盘阵列 RAID 的特点和选择:
三种RAID的特点与区别:
RAID 0 :采用数据分块,并行传输方式,能够提高读写速度。但是由于没有冗余备份,所有数据可靠性低(其中一个硬盘介质出现问题时,则无法恢复)。
RAID 1: 增加了镜像(冗余数据),所以数据 读速度提高(可以同时从原数据和冗余数据中读取),可靠性增加。硬盘利用率低(毕竟冗余数据占用50%)。
RAID 5: 只比RAID 0 增加了一个奇偶校验信息。
总的来说:RAID 0 单纯提高了性能,但是缺少数据可靠性。 RAID 1 提高了数据可靠性和读速度,但是CPU占用率高,磁盘利用率低。 RAID 5则是一种存储性能、数据安全和存储成本兼顾的方法。
PS:附上博主考试通过的证书照片
至此,数据库三级的相关知识点就汇聚完毕了,这个文档里边会不少于50分,后边大题这里边要背的SQL语句关键字也有,把这个文档搞清楚,基本上数据库三级考试也差不多。祝各位考生顺利通过计算机三级考试!!!
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_45922256/article/details/132917883