论文地址:https://arxiv.org/abs/2304.08485
代码地址:https://github.com/haotian-liu/LLaVA

- 简介
- Visual Instruction 数据生成
- 视觉指令微调
- 模型架构
- 训练
简介
人类对于世界的认知是通过视觉、语言多个途径的,因此设计出能够遵循多模态的视觉和语言指令的通用大模型成为了人工智能领域的核心目标之一。
当前,很多工作已经在视觉大模型方面取得成就,不过每一种任务(如分类、分割、图像生成编辑等)均由不同的 LVM 完成,且语言仅用于描述图像,这导致了我们不能很好地与模型进行交互,模型也缺失适应复杂指令的能力。
除此之外,LLM 展示出了语言的强大能力,各种各样的任务都可以通过指令来进行端到端的训练,很多模型如 GPT-4 应用了高质量的 instruction-following 数据,模型可以根据不同的指令来完成不同的任务。不过这些方法仅限于语言。
作者在 LLaVA 中将语言的微调方式推广到多模态大模型,具体来说本篇论文有以下 contributions:
- Multimodal instruction-following data. 利用 ChatGPT/GPT-4,将图像-文本对转化为了 instruction-following 形式的数据。
- Large multimodal models. 利用 CLIP 和 Vicuma 设计了一种 LMM,在科学 QA 上得到了 SOTA。
- Multimodal instruction-following benchmark. (LLaVA-Bench)
- Open-source.
Visual Instruction 数据生成
作者团队基于已有的图像-文本对数据,利用 ChatGPT/GPT-4 进行数据的扩充。
首先根据图像 \(X_v\) 以及相应的描述 \(X_c\),GPT 可以生成一个问题 \(X_q\),此时可以得到一轮对话数据:
Human : Xq, Xv <STOP>
Assistant : Xc <STOP>
不过只有上面简单的对话不能使模型学习到深层次的推理能力,因此作者团队应用 GPT 进行了包含视觉信息的 instruction-following 数据扩充。分为两种符号表示:
- Captions:从多个角度细致地描述视觉场景
- Bounding boxes:指出了每个物体的名称以及位置
此时视觉模型转化为了 LLM 可以理解的文本信息。作者团队接着基于 COCO 数据集生成了三种 instruction-following 数据(对话、细节描述、复杂推理)。对于每一种首先手工设计一些样例,然后以此作为 in-context 学习的模板询问 GPT-4 生成更多相关的数据。

作者总共收集了 158K 个单独的语言-图像指令跟随样本,包括 58K 个对话、23K 个细节描述、77K 个复杂推理。
视觉指令微调
模型架构
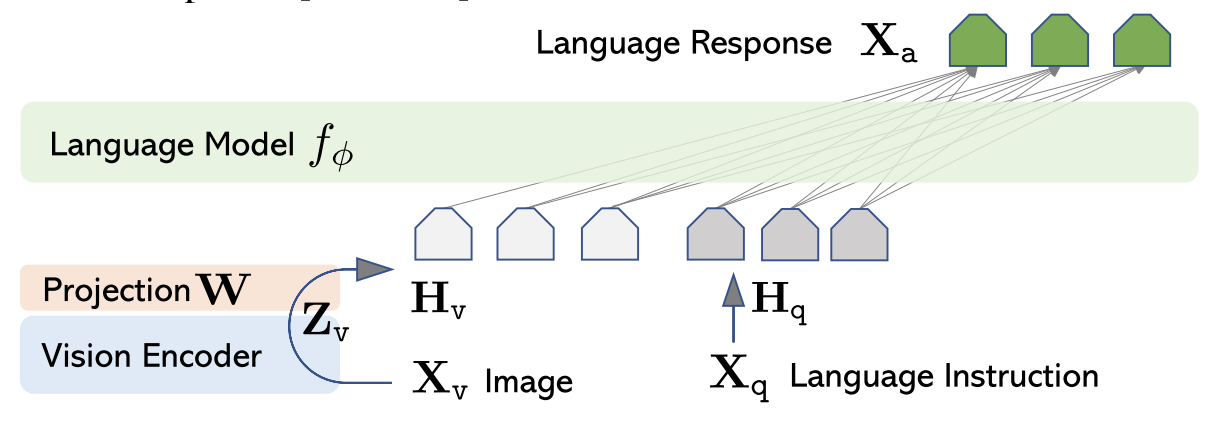
其中,\(X_v\) 是输入图像,Vision Encoder 使用预训练的 ViT-L/14,大语言模型 \(f_\phi\) 使用 Vicuna,\(W\) 是可训练的投影矩阵,\(H_v\) 和 \(H_q\) 分别为视觉和文本 token;对于输入图像,转化公式为:
训练
对于输入图片 \(X_v\),可以生成多轮对话:\((\mathbf{X_q^1},\mathbf{X_a^1},\cdots,\mathbf{X_q^T},\mathbf{X_a^T})\),则第 \(t\) 轮的指令为:
\(\mathbf{X}_{{\mathrm{instruct}}}^{t}=\begin{cases}&\text{Randomly choose }[\mathbf{X}_{{\mathrm{q}}}^{1},\mathbf{X}_{{\mathrm{v}}}]\ \ \mathrm{or~}[\mathbf{X}_{{\mathrm{v}}},\mathbf{X}_{{\mathrm{q}}}^{1}],\ \mathrm{the~first~turn~}t=1\\&\mathbf{X}_{{\mathrm{q}}}^{t},\qquad \qquad \qquad \qquad \qquad\qquad\mathrm{the~remaining~turns~}t>1&&\end{cases}\)
并利用其自身的自回归结构进行 next token prediction,也就是说,对于任何一个长度为 \(L\) 的序列,我们通过如下公式计算:
输入输出以下图方式组织,只有绿色部分才会参与计算 loss。

对于 LLaVA 的训练采用了两阶段的策略:
- Pre-training for Feature Alignment. 作者首先从 CC3M 筛选出 595K 的图像文本,然后利用第二节介绍的普通方法扩充为 instruction-following 数据。该阶段冻结 LLM 以及 Vision Encoder,只训练 \(W\)。
- Fine-tuning End-to-End. 该阶段训练 \(W\) 和 LLM,
- 利用 158K 的指令追随样本训练一个多模态 Chatbot
- 利用 ScienceQA benchmark,输入为文本或图像的单轮对话