交叉熵与似然函数的关系
在逻辑回归中:
模型输出的是类别 y的条件概率:

其中 σ(zi)是 Sigmoid 函数。
目标是通过最大化似然函数,使得模型参数 θ 能够最好地拟合数据。
1. 似然函数
似然函数定义为所有样本的联合概率:

对每个样本的概率,分类问题可以表示为:
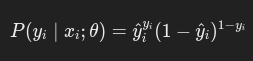
于是似然函数为:

2. 对数似然函数
取对数得到对数似然函数(Log-Likelihood, LL):

3. 损失函数(交叉熵)
在模型训练中,我们最小化的是负对数似然:
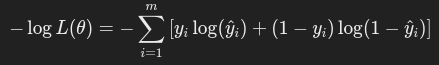
将负对数似然取平均,就得到了交叉熵损失函数:

在逻辑回归中:
模型输出的是类别 y的条件概率:
其中 σ(zi)是 Sigmoid 函数。
目标是通过最大化似然函数,使得模型参数 θ 能够最好地拟合数据。
似然函数定义为所有样本的联合概率:
对每个样本的概率,分类问题可以表示为:
于是似然函数为:
取对数得到对数似然函数(Log-Likelihood, LL):
在模型训练中,我们最小化的是负对数似然:
将负对数似然取平均,就得到了交叉熵损失函数:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/839370.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!