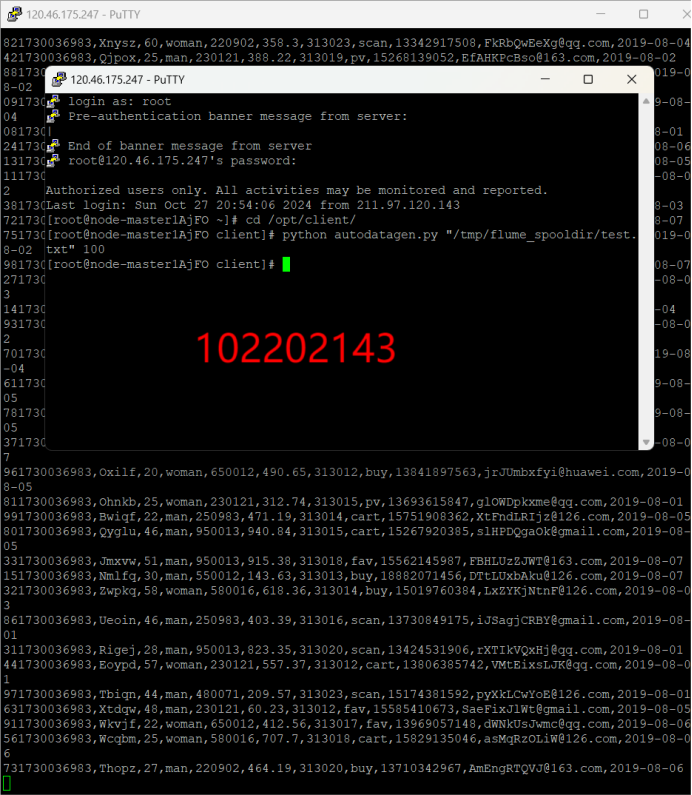
全文链接:https://tecdat.cn/?p=38354
原文出处:拓端数据部落公众号
本文旨在介绍一种利用贝叶斯优化方法来优化混合 CNN - RNN 和浅层网络超参数的简单方法,并展示了如何使贝叶斯优化器考虑离散值。通过对股票市场数据的模拟与分析,阐述了网络构建、数据预处理、超参数优化以及结果可视化等过程,探讨了股票市场预测这一具有挑战性任务中机器学习方法的应用与局限性。
引言
“我能计算天体的运动,却无法计算人类的疯狂。”
——艾萨克·牛顿爵士,在 1720 年春天被问及南海股票时所言。
如今,像我这样的数学家、物理学家、机器学习专家、数据科学家以及对数据充满好奇的爱好者们,都梦想着有朝一日能够借助人工智能预测未来。股票市场预测?它既困难又令人失望,同时也充满希望,这正是股票市场的本质所在。支撑时间序列预测基础的假设并不总是适用于股票市场现象。股票市场时间序列是众多受利润诱惑的投资者贪婪、野心、失望与希望的源泉。而这正是我们试图通过机器学习进行预测的内容;这无疑是一项极为艰巨的任务,但如果精心设计网络,就有可能识别出某些模式,并预测出接近未来现实的行为。
“过去的模式或许会在明天重现”。本文将展示一种利用贝叶斯优化来优化混合 CNN - RNN 和浅层网络超参数的简单方法。
关键要点
- 分别使用贝叶斯优化对混合 CNN - RNN 和浅层网络进行调优。
- 采用一种简单的方法使贝叶斯优化算法能够包含离散值。
- 本代码中使用了一种生成类似随机股票市场数据的简单程序。
输入参数
-
clearvars;
-
delete(gcp('nocreate'));
-
ratio = 0.9; % 用于划分训练集和测试集数据的比例
-
MaxEpochs = 600; % 两个网络的最大训练轮数
-
NetOption = []; % 所使用的网络
生成股票价格
生成随机股票市场数据并包含日期信息。
-
% 模拟股票数据
-
Period = 249 * 2;
-
data = stockpricesimulation(Period, true);
-
Past = datetime('today') - Period;
-
Date = Past:datetime('today');
可视化完整序列
首先查看数据总是有益的。
-
-
set(gca, 'FontSize', 12, 'FontName', 'Adobe Kaiti Std R', 'FontWeight', 'bold');
-
set(gca, 'Box', 'on', 'LineWidth', 1, 'Layer', 'top',...
-
'XMinorTick', 'on', 'YMinorTick', 'on', 'XGrid', 'on', 'YGrid', 'on',...
-
'TickDir', 'out', 'TickLength', [.015.015],...
-
'FontName', 'avantgarde', 'FontSize', 12, 'FontWeight', 'normal');
-
axis tight;

划分训练集和测试集序列
对数据进行训练集和测试集的划分。
准备自变量和因变量
浅层网络环境会在内部完成所有数据准备工作,但如果使用 CNN - RNN,则需要在训练网络之前准备序列。
超参数优化
有大量超参数需要调整和优化。NarNet 训练速度极快,所以如果计算机配置一般,此选项是不错的选择,并且仍能获得较好的拟合性能。如果计算机配备了最新一代处理器,则可以尝试使用贝叶斯优化来优化 CNN - RNN 参数。
在 CNN - RNN 优化中,使用了一个“技巧”来强制优化器处理离散值。通过将“MiniBatchSize”声明为分类变量,使其取值为’16’ ‘32’ ‘48’ ‘64’,然后将这些值转换为数值。
-
-
% 获取贝叶斯优化的最佳点
-
optVars = bestPoint(BayesObject);
-
% 使用最优参数评估和训练网络
-
[valError, ~, net, Ys, YPred, YPredStep, YTest] = BayesObject.ObjectiveFcn(optVars, true);
-
% 还原数据标准化
-
YPredStep = sig * YPredStep + mu;
-
YTest = sig * YTest + mu;
-
YPred = sig * YPred + mu;
-
% 评估网络性能
-
sMAPErr = sMAPE(con2seq(YTest), con2seq(YPred));
-
end

优化结果如下表所示:
-
optVars = 1×7 table
-
**learningrate** **performFcn** **mc** **processFcns** **Lag** **hiddenLayerSize1** **hiddenLayerSize2** **\_\_\_\_\_\_\_\_\_\_\_\_** **\_\_\_\_\_\_\_\_\_\_** **\_\_\_\_\_\_\_** **\_\_\_\_\_\_\_\_\_\_\_** **\_\_\_** **\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_** **\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_**
-
0.0014275 msesparse 0.73025 mapminmax 14 22 11
性能函数已替换为均方误差性能。
delete(gcp('nocreate'));该表展示了贝叶斯优化器找到的最佳参数。
可视化
将完整序列与测试数据和预测数据重叠显示。
-
figure;
-
plot(Date, data);
-
hold on;
-
idx = size(YPred, 2);
-
-
set(gca, 'FontSize', 12, 'FontName', 'Adobe Kaiti Std R', 'FontWeight', 'bold');
-
set(gca, 'Box', 'on', 'LineWidth', 1.1, 'Layer', 'top',...
-
'XMinorTick', 'on', 'YMinorTick', 'on', 'XGrid', 'on', 'YGrid', 'on',...
-
'TickDir', 'in', 'TickLength', [.015.015],...
-
'FontName', 'avantgarde', 'FontSize', 12, 'FontWeight', 'normal');
-
axis tight;

单独可视化预测数据和测试数据以便更好地理解。

绘制回归图:

预测未观测值
以下是浅层网络闭环预测超出观测值序列的情况。
-
if strcmp(NetOption, 'NarNet')
-
numTimeStepsTest = size(YTest, 2);
-
[x1, xio, aio, t] = preparets(net, {}, {}, XTrain);
-
[y1, xfo, afo] = net(x1, xio, aio);
-
[netc, xic, aic] = closeloop(net, xfo, afo);
-
X2 = num2cell(rand(1, numTimeStepsTest));
-
[YPredStep, xfc, afc] = netc(X2, xic, aic);
-
YPredStep = cell2mat(YPredStep);
-
end
一些可视化操作来检查网络性能。

绘制回归图: