乐观锁vs悲观锁
指的不是具体的锁,是一个抽象的概念,描述的是锁的特性,描述的是一类锁
乐观锁
假设数据一般情况下不会产生并发冲突,所以在数据进行提交更新的时候,才会正式对数据是否产生并发冲突进行检测,如果发现并发冲突了,就让返回用户错误的信息,让用户决定如何去做.(后续做的工作更少)
悲观锁
假设数据最坏的情况,每次去拿数据的时候都认为别人会修改,所以在拿数据的时候都会上锁,这样别人想要拿这个数据就会阻塞直到它拿到锁(后续做的工作更多)
Synchronized初始使用乐观锁策略,当发现锁竞争比较频繁的时候,就会自动切换为悲观锁策略
重量级锁vs轻量级锁
重量级锁
加锁的开销是比较大的(花的时间多,占用系统资源多)
一个悲观锁,很可能是重量级锁(不绝对)
轻量级锁
加锁的开销是比较小的(花的时间少,占用系统资源少)
一个乐观锁,很可能是轻量级锁(不绝对)
乐观悲观,是在加锁之前,对锁冲突的概率进行预测,决定工作的多少
重量轻量,是在加锁之后,考量实际的锁的开销
自旋锁(Spin Lock 轻量级)
在用户态下,通过自旋的方式(while循环),实现类似于加锁的效果的
这种锁,会消耗一定的CPU,但是可以做到快速拿到锁
挂起等待锁(重量级)
通过内核态,借助系统提供的锁机制,当出现锁冲突的时候,会牵扯到内核对于线程的调度,使冲突的线程出现挂起(阻塞等待)
这种方式,消耗的CPU资源的更少的,也就无法保证第一时间拿到锁
读写锁vs互斥锁
读写锁
把读操作加锁和写操作加锁分开了
如果两个线程,一个线程读加锁,另一个线程也是读加锁,不会产生锁竞争
如果两个线程,一个线程写加锁,另一个线程也写加锁,会产生锁竞争
如果两个线程,一个线程写加锁,另一个线程也是读加锁,会产生锁竞争
这里跟数据库事务中的隔离级别中的加锁不太一样
写加锁:写的时候,不能读
读加锁:读的时候,不能写
事务中的读加锁,写加锁,要比这里的读写锁粒度更细,情况分的更多
实际开发中,读操作的频率,往往比写操作,高很多
java标准库中,也提供了现成的读写锁


这个类表示一个读锁. 这个对象提供了 lock / unlock 方法进行
加锁解锁.

这个类表示一个写锁. 这个对象也提供了 lock / unlock 方法进
行加锁解锁.
公平锁vs非公平锁
假设三个线程 A, B, C. A 先尝试获取锁, 获取成功. 然后 B 再尝试获取锁, 获取失败, 阻塞等待; 然后C 也尝试获取锁, C 也获取失败, 也阻塞等待.
当线程 A 释放锁的时候, 会发生啥呢?
公平锁
遵守先来后到,阻塞时间越久的越先得到锁,B 比 C 先来的. 当 A 释放锁的之后, B 就能先于 C 获取到锁.
非公平锁
不遵守先来后到,每个线程都有可能获取到锁,B 和 C 都有可能获取到锁
操作系统内部的线程调度就可以视为是随机的. 如果不做任何额外的限制, 锁就是非公平锁. 如果要想实现公平锁, 就需要依赖额外的数据结构, 来记录线程们的先后顺序.
公平锁和非公平锁没有好坏之分, 关键还是看适用场景
synchronized 是非公平锁
可重入锁vs不可重入锁
可重入锁
可重入锁的字面意思是“可以重新进入的锁”,即允许同一个线程多次获取同一把锁,不会出现死锁(阻塞),
不可重入锁
同一个线程,不可以重复获取同一把锁,会出现阻塞的情况
public synchronized void increase(){synchronized (this){count++;}}
代码如果这样写,此时是否会存在问题呢
1.调用方法,先针对this进行加锁,假设此时加锁成功了
2.接下来往下执行到代码块中的synchronized ,此时,还是针对this来进行加锁
此时就会产生锁竞争,当前this对象已经处于加锁状态了,此时,线程就会阻塞,一直阻塞到锁被释放,才能有机会拿到锁,在这个代码中,this上的锁,得在increase方法执行结束之后,才能释放,得第二次加锁成功获取到锁,方法才能继续进行,才能执行完,要想要让代码继续往下执行,就需要把第二次加锁获取到,也就是把第一次加锁释放,想要第一把锁释放,又需要保证代码继续执行
此时,代码在这里就僵住了,这种情况也被称为死锁(死锁的第一种情形)
这里的关键在于,两次加锁,都是同一个线程,第二次尝试加锁的时候,该线程已经有了这个锁的权限了,这个时候,不应该加锁失败的,不应该阻塞等待的
如果是一个不可重入锁,这把锁不会保存,是哪个线程对他的加锁,只要他当前处于加锁状态之后,收到了加锁的请求,收到了加锁这样的请求,就会拒绝当前加锁,而不管当前的线程是哪个,就会产生死锁
可重入锁,则是让这个锁保存,是哪个线程加上的锁,后续接受到加锁的请求之后,就会先对比一下,看看加锁的线程是不是当前持有自己这把锁的线程,这时侯就可以灵活判定了.
synchronized 本身是一个可重入锁
synchronized (this){synchronized (this){synchronized (this){....}}}
这里的嵌套加锁,只有第一个是真正加锁了的,其他的只是进行了判定,并没有真正加锁,那么当我们的代码执行到第一个{}结束的时候,出了这个代码块,刚才加的锁释放要释放:不应该释放
如果在最里层的}处将锁给释放了,就意味着最外面的,以及中间的synchronized 后续的代码部分就没有处在锁的保护中了
真正要释放锁的地方是最后一个}处
那么,系统是怎么区分出哪个}是最后一个}呢
让这个锁持有一个计数器就可以了,让锁对象不仅要记录是哪个线程持有的锁,同时再通过一个整形变量来记录当前这个线程加了几次锁,每次遇到一个加锁就计数器加一,每次遇到一个解锁操作,就减一,当计数器的值被减为0的时候,才是真正执行释放的操作,其他的时候不会释放,这种计数器被称为"引用技术"
死锁
1.两个线程,一把锁,但是是不可重入锁,该线程针对这个锁连续加锁两次,就会出现死锁
2.两个线程,两把锁,这两个线程先分别获取到一把锁,然后再同时尝试获取对方的锁
public class demo4 {private static Object locker1 = new Object();private static Object locker2 = new Object();public static void main(String[] args) {Thread t1 = new Thread(()->{synchronized (locker1){try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}synchronized (locker2){System.out.println("t1两把锁加锁成功");}}});Thread t2 =new Thread(()->{synchronized (locker2){try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}synchronized (locker1){System.out.println("t2两把锁加锁成功");}}});t1.start();t2.start();}
}
结果什么都没打印,这也是出现了死锁的原因
3.三个线程N把锁
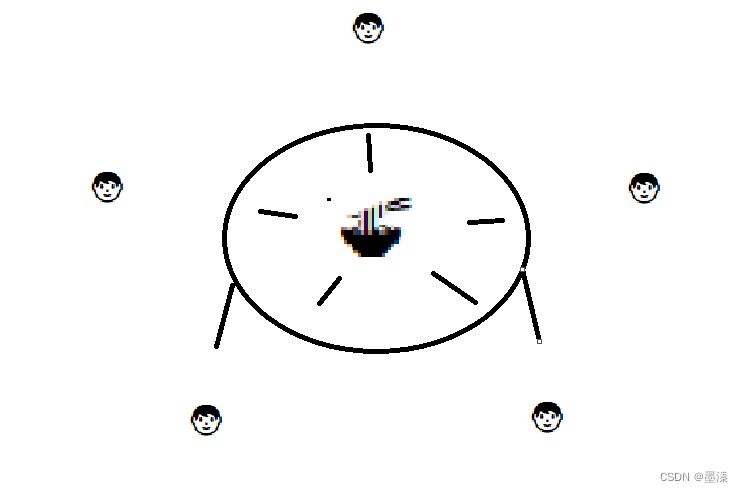
哲学家就餐问题:
5个哲学家就是5个线程
5个筷子就是五把锁
每个作家,主要做两件事
1.思考人生,会放下筷子
2.吃面,会拿起左手和右手的筷子,再去吃面条
其他设定:
1.每个哲学家,什么时候思考人生,什么时候吃面条,不确定
2.一旦吃面条,就一定会固执的完成这个操作,如果此时他的筷子被别人使用了,就会阻塞等待,并且等待的过程不会放下手中已经拿着的筷子
基于上述的模型设定,绝大部分情况下,这些哲学家都是可以很好的工作的
但是,如果出现了极端情况,也会出现死锁
同一时刻,五个哲学家都想吃面,并且同时伸出左手去拿左边的筷子,再尝试拿起右边的筷子
是否有办法避免死锁呢,先得明确死锁产生的原因,死锁的必要条件
死锁的四个必要条件(缺一不可,破一可避免死锁)
1.互斥作用:一个线程获取到一把锁之后,别的线程不能获取到这个锁(实际使用的锁,一般都是互斥的,锁的基本特性)
2.不可抢占:锁只能是被持有者主动释放,而不能是被其他线程直接抢走(锁的基本特性)
3.请求和保持:这个一个线程去尝试获取更多把锁,再获取第二把锁的过程中,会保持对第一把锁的获取状态(取决于代码结构)
4.循环等待:
t1尝试获取locker2,需要t2执行完,释放locker2;
t2尝试获取Locker1,需要t1执行完,释放locker1
(取决于代码结构,解决死锁的最关键的要点)
介绍一个解决死锁的方法:
针对锁进行编号,并且规定加锁的顺序,比如,约定好每个线程如果想要获取多把锁,必须先获取小编号的锁,后获取编号大 的锁,只要所有的线程加锁的顺序都严格按照上述顺序,就一定不会出现循环等待
synchronized 实现的锁策略
1.既是悲观锁也是乐观锁(自适应)
2.既是重量级,也是轻量级(自适应)
3.synchronized 重量级部分是基于互斥锁实现的(挂起等待锁),轻量级部分是基于自旋锁实现的
4.非公平锁
5.可重入锁
6.不是读写锁
内部实现策略(内部原理)
代码中写了一个synchronized 之后,这里可能会产生一系列的"自适应的过程",锁升级(锁膨胀)
无锁->偏向锁->轻量级锁->重量级锁
偏向锁,不是真的加锁,而只是做了一个"标记",如果有别的线程来竞争锁了,才会真的加锁,如果没有别的线程来竞争,就自始至终都不会真的加锁了(加锁本身,是需要一定的开销的)
锁消除
编译器,会智能判定,当前这个代码是否需要加锁,如果写了加锁,而实际上不需要加锁,编译器就会把加锁这个操作自动删除掉
锁粗化
关于锁的粒度:
如果要加锁的操作里要执行的代码越多,就认为锁的粒度更大
for (...){synchronized (this){count++;}}
synchronized (this){for (...){count++;}}
这两个代码显然是第二个代码的粒度更大
有的时候,希望锁的粒度小比较好,并发程度更高
有的时候,希望锁的粒度大比较好,因为锁本身也是有很大的开销