高可用服务
计算节点提供数据节点内的存储节点高可用,当主存储节点不可用时,计算节点将自动切换到从存储节点。
若要使用数据节点高可用,需满足以下前提:
- 在数据节点内配置主从存储节点与故障切换优先级规则;
- 主从存储节点之间必须已配置主从或双主的复制关系;
- 在计算节点配置文件中开启心跳功能。
数据节点高可用
默认情况下,计算节点心跳功能是开启的:
<property name="enableHeartbeat">true</property>
假设192.168.200.202的3309实例与192.168.200.203的3313实例为一对主从复制的存储节点数据库。
配置同一个节点内的主从存储节点,可以在管理平台中的"添加节点"页面或者"存储节点更新"页面中设置。
在管理平台页面中选择"配置"->"节点管理"->"添加节点",跳转到"添加节点"页面:
在下述操作中,生成一个数据节点"dn_08",并为该数据节点添加了一个主存储节点"ds_failover_master"和一个从存储节点"ds_failover_slave":

可直接勾选"自动适配切换规则",添加节点同时自动适配故障切换优先级。或在管理平台页面中选择"配置"->"节点管理"->"高可用配置"->"切换规则"->"添加切换规则",在数据节点下拉框中选择"dn_08",在存储节点的下拉框中选择主存储节点"ds_failover_master,在备用存储节点下拉框中选择"ds_failover_slave",在故障切换优先级选择高:
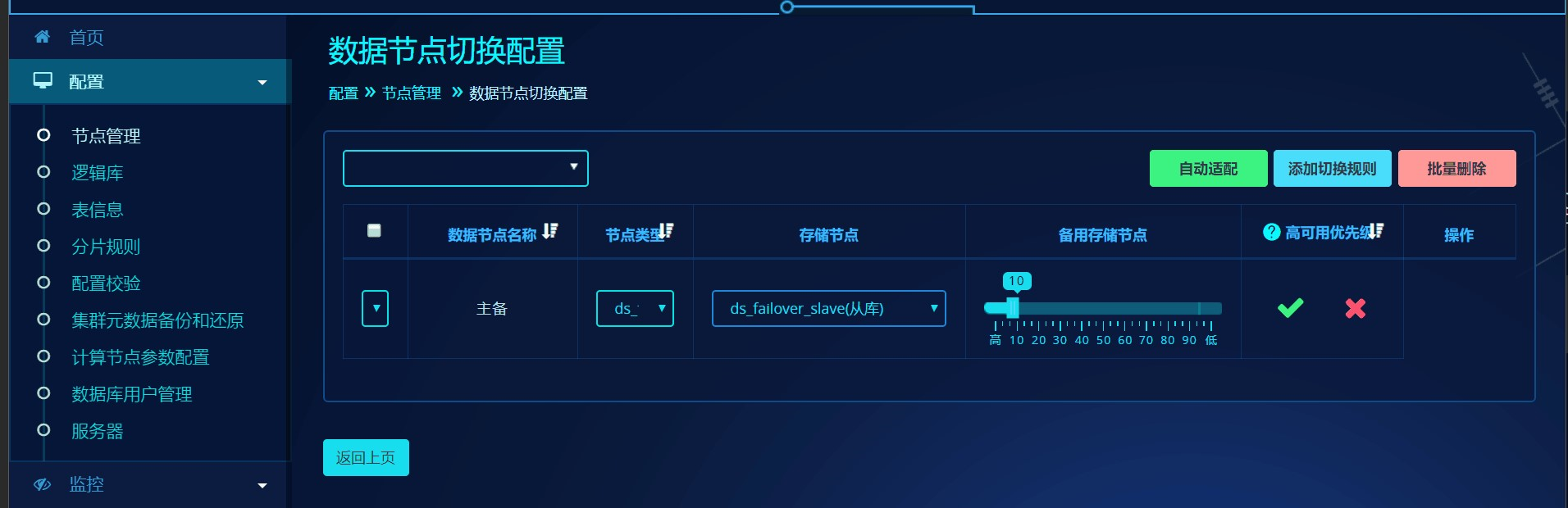
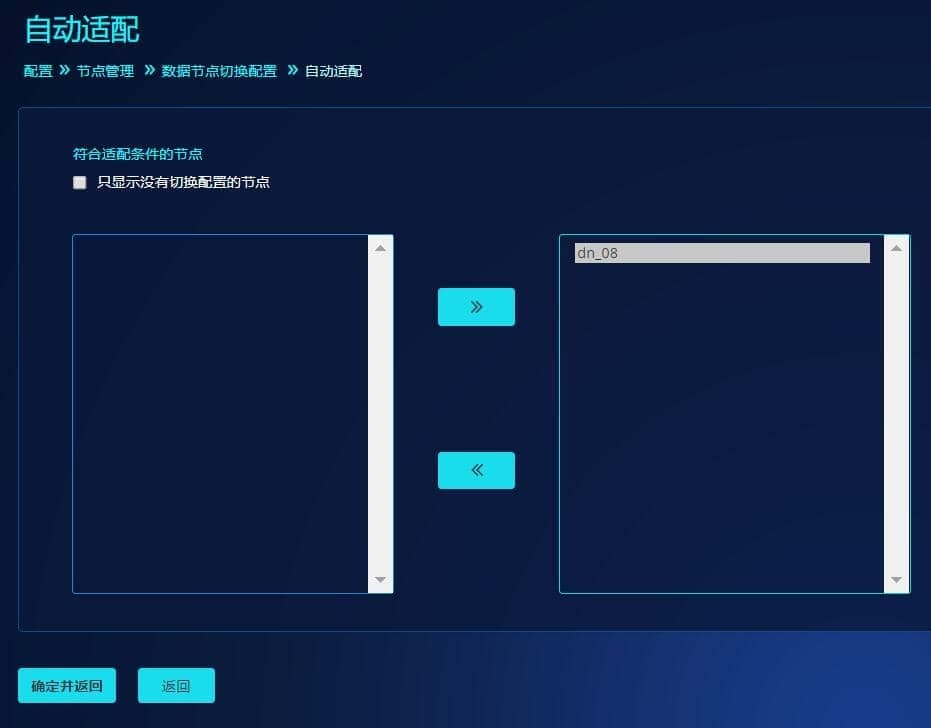
或点击"自动适配",选择dn_08节点,保存即可。
主从复制关系搭建:
虽然在节点dn_08下添加了一对主从存储节点,但若这2个存储节点实际并没有搭建主从复制关系,此时可以在"配置"->"节点管理"->"高可用配置"->"主从搭建"中,选择"dn_08"节点。
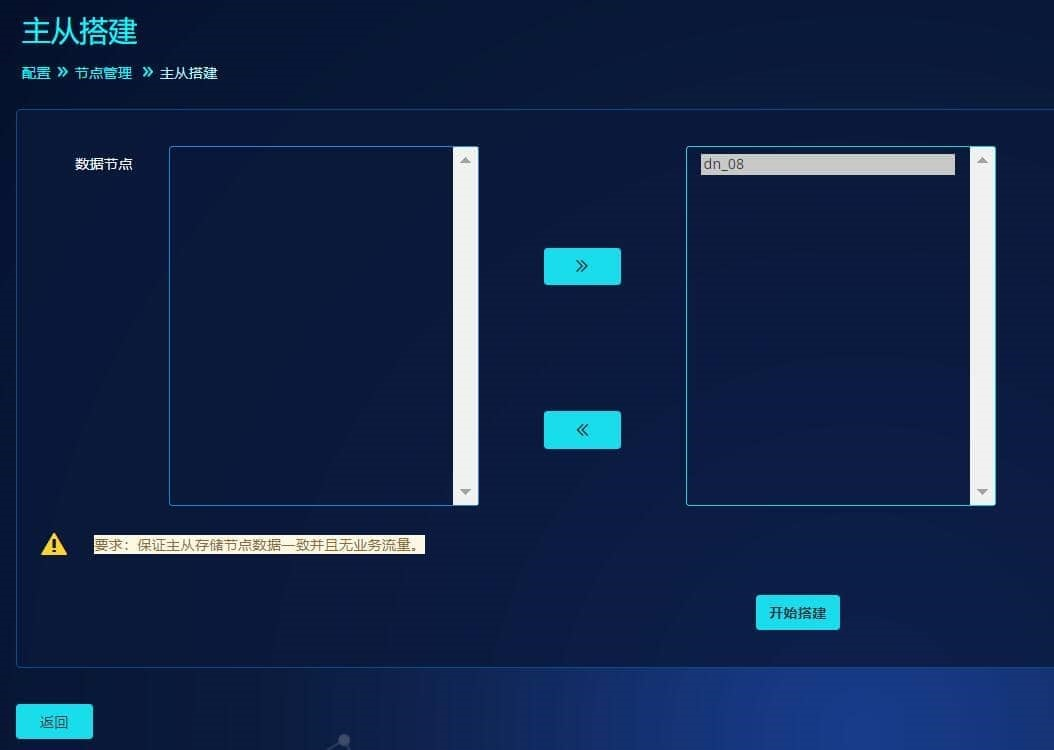
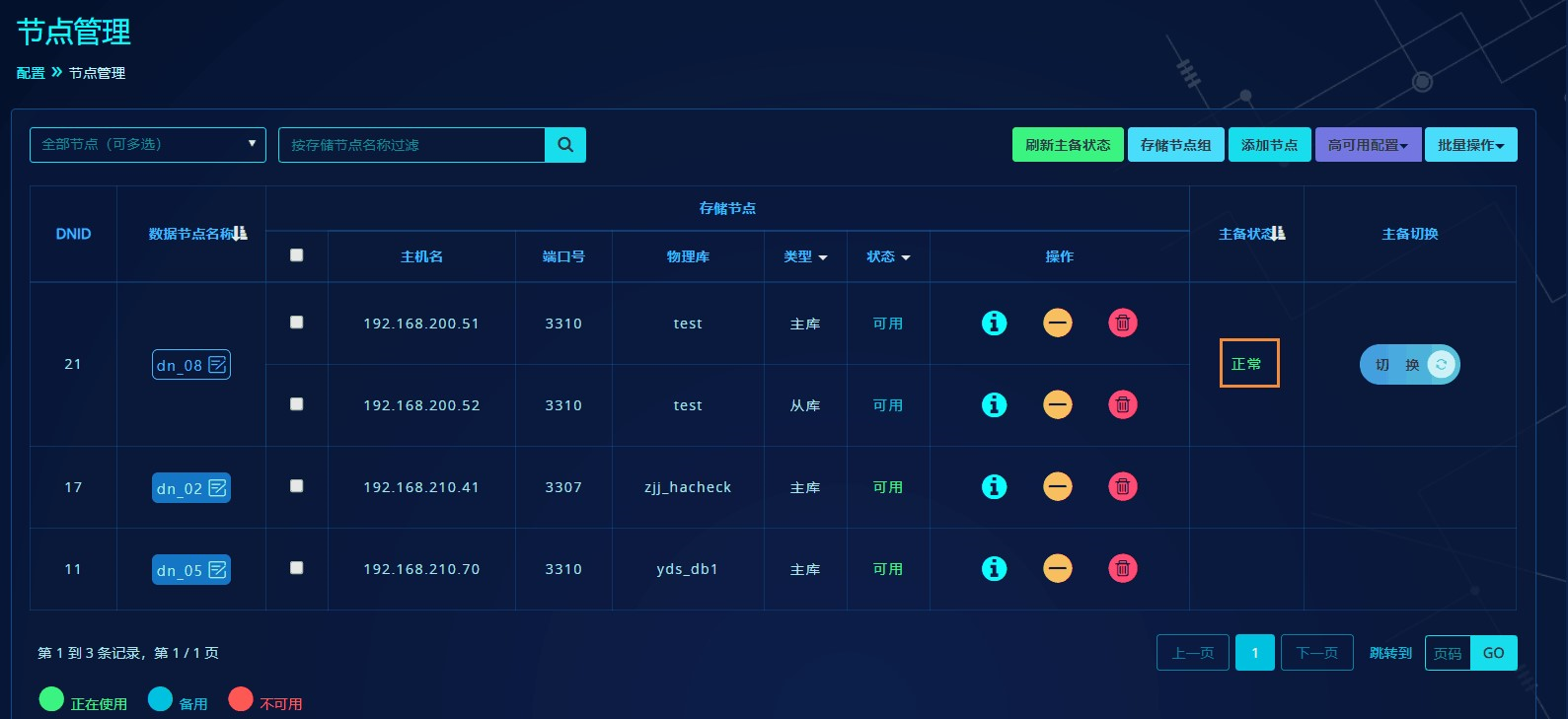
点击"开始搭建"后,系统会自动对存储节点搭建主从复制关系。当搭建成功后,列表中主从状态会正常显示:
手动切换
在"配置"->"节点管理",点击某个数据节点的切换即可完成:
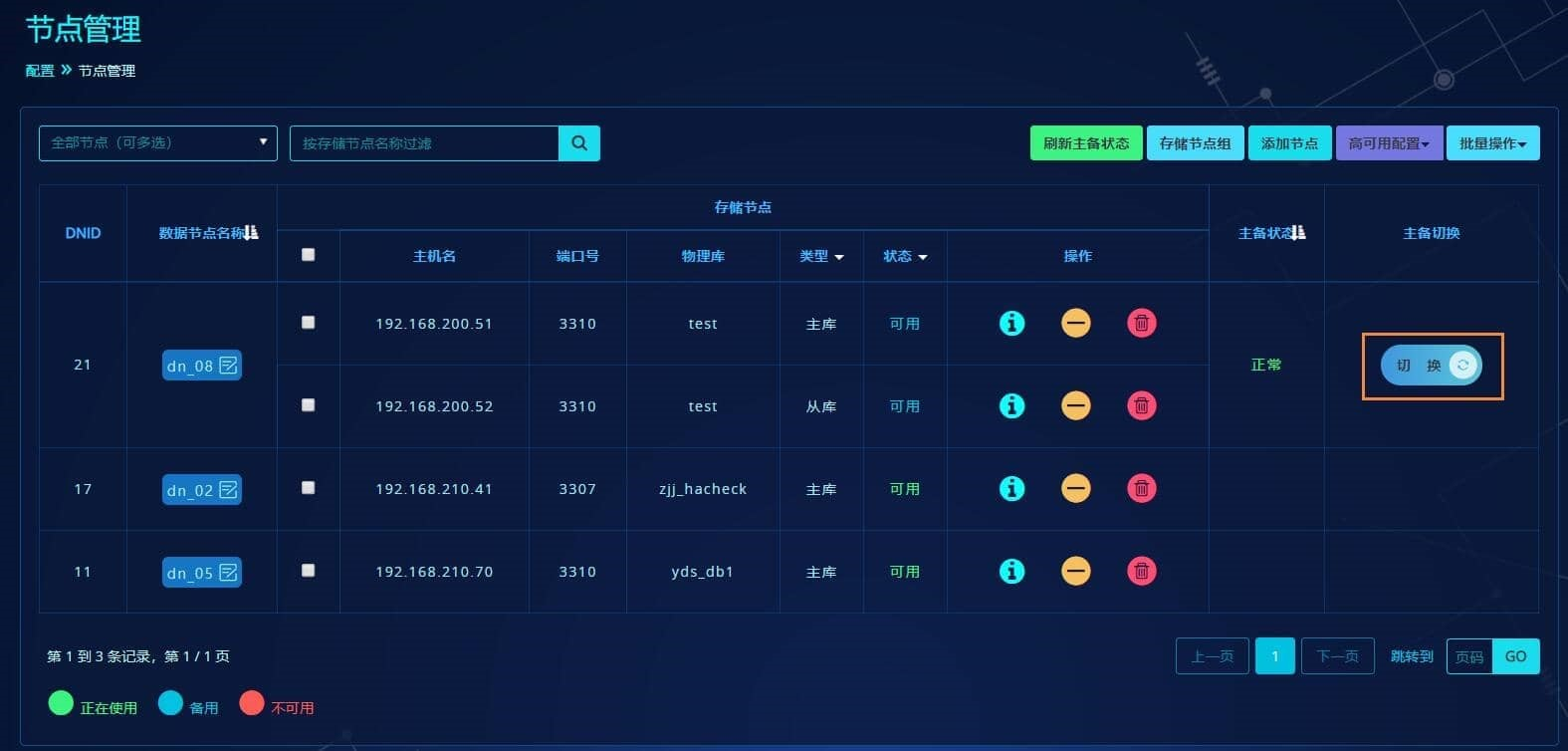
如果是主从,选择优先级最高的进行切换,切换后计算节点会将原主机和原主机的其他从机置为不可用,不能再进行切换。
如果是双主,切换后不会将原主库置为不可用,可以继续手动来回切换。若主存储节点故障,则只切换当前主库到双主备库的角色,且将原主库置为不可用,其级联从机会与新主库搭建复制关系。此时各存储节点均需开启GTID,若节点内存在未开启GTID的对象,则当前故障主库关联的其他备库会被级联置为不可用。用户可以通过计算节点参数switchSlaveMasterFailover,控制存储节点切换时其关联从库是否自动change master到主库。当此参数关闭时,则当前故障主库关联的其他备库会被级联置为不可用。
如果优先级最高从库不可用或延迟超过10s,依次选择剩余从库中优先级较高的进行切换,如果均不可用或存在延迟超过10s,则不切换,提示错误(切换失败日志提示switch datasource datasourceid failed due to:no available backup found)。
在计算节点手动切换时,会先检查当前的hotdb_datanode/hotdb_datasource/hotdb_failover表是否与running 表中一致,若不一致会提示:"当前存储节点的配置信息与内存中的配置信息不一致,无法进行切换,请动态加载后重试";若校验通过,在新备存储节点接管前,会将被接管的存储节点更新为主库,原主库更新为双主备库或从库(注:若为主从关系,原主库及其相关的从节点均被级联置为不可用,且切换时会同步清理原复制关系,将原主库与原从库的故障切换规则进行互换,待人工进行线下的复制关系重建)。
切换成功时,计算节点记录切换过程日志:
INFO [pool-1-thread-1064] (SwitchDataSource.java:78) -received switch datasourceid command from Manager : [连接信息]
WARN [pool-1-thread-1339] (BackendDataNode.java:263) -datanode id switch datasource:id to datasource:id in failover. due to: Manual Switch by User: username
INFO [pool-1-thread-1339] (SwitchDataSource.java:68) -switch datasource:id for datanode:id successfully by Manager.
在没有配置切换规则时,不会进行切换,提示错误: `switch datasource id failed due to:found no backup information)
在主从复制关系下,存储节点手动切换的选主逻辑同故障切换时一致,请参考上述内容。
故障切换
故障切换一般是因存储节点发生故障后自动产生的切换,说明如下:
-
在双主备关系下,若主存储节点故障,则备存储节点会被更新为主库,原主库更新为双主备库并置为不可用。原故障的存储节点所关联的从库会与新主库搭建复制关系,同时从库切换规则会变更到新主库。
-
在主从复制关系下,若主存储节点故障,则备存储节点会 被更新为主库,原主库变更为从库;同时原主库关联的从库均与新主库搭建复制关系,且原主从复制关系会被清理,并标记原主库为不可用。此时原主库与原从库的故障切换规则进行互换,需要人工重新搭建复制关系后,再启用原主库。
-
若只是从库故障,则会将故障从库的级联从库与主库搭建复制关系,原从库置为不可用。
以上需注意:各存储节点均需开启GTID,若节点内存在未开启GTID的对象,则当前故障主库关联的其他备库会被级联置为不可用。用户可以通过计算节点参数switchSlaveMasterFailover,控制存储节点切换时其关联从库是否自动change master到主库。当此参数关闭时,则当前故障主库关联的其他备库会被级联置为不可用。
- 如果从库状态为不可用,则不切换,计算节点记录日志。
WARN [pool-1-thread-2614] datanode id failover failed due to found no available backup
- 在server.xml可以配置参数waitForSlaveInFailover控制切换是否等待从库追上复制,该参数默认为true等待,在切换过程中,会等待从库追上复制,如果设置为false不等待,则会立即切换。(立即切换存在数据丢失的风险,不建议设置)。
- 一主多从的情况下,计算节点选择优先级最高的从库进行切换,如果优先级最高从库不可用,依次选择剩余从库中优先级较高的进行切换,如果均不可用,则不切换,计算节点记录日志WARN [pool-1-thread-2614] -datanode id failover failed due to found no available backup。
- 故障切换时,在新备存储节点接管前会将被接管的存储节点更新为主库,原主库更新为双主备库或从库,并置为不可用,原主库相关的从节点均被级联置为不可用(注:若为主从关系,切换时会同步清理原复制关系,且将原主库与原从库的故障切换规则进行互换,待人工进行线下的复制关系重建)。
- 故障切换过程中,主库心跳不停,如果连续两次成功,则放弃切换,计算节点记录日志。
INFO [$NIOREACTOR-6-RW] (Heartbeat.java:502) -heartbeat continue success twice for datasource 5 192.168.200.52:3310/phy243_05, give up failover.
- 切换成功时,计算节点记录日志,并记录切换原因:
如果是网络故障、服务器宕机,掉电等,则记录Network is unreachable;
如果网络可达,存储节点服务停止,没有响应,则记录MySQL Service Stopped;
如果存储节点服务开启,但是响应出现异常,则记录MySQL Service Exception;
例如:存储节点服务关掉时,整个切换过程提示如下:
02/21 15:57:29.342 INFO [HeartbeatTimer] (BackendDataNode.java:396) -start failover for datanode:5
02/21 15:57:29.344 INFO [HeartbeatTimer] (BackendDataNode.java:405) -found candidate backup for datanode 5 :[id:9,nodeId:5 192.168.200.51:331001_3310_ms status:1] in failover, start checking slave status.
02/21 15:57:29.344 WARN [$NIOREACTOR-0-RW] (HeartbeatInitHandler.java:44) -datasoruce 5 192.168.200.52:331001_3310_ms init heartbeat failed due to:MySQL Error Packet{length=36,id=1}
02/21 15:57:29.344 INFO [pool-1-thread-1020] (CheckSlaveHandler.java:241) -slave_sql_running is Yes in :[id:9,nodeId:5 192.168.200.51:331001_3310_ms status:1] during failover of datanode 5
02/21 15:57:29.424 WARN [pool-1-thread-1066] (BackendDataNode.java:847) -datanode 5 switch datasource 5 to 9 in failover. due to: MySQL Service Stopped
02/21 15:57:29.429 WARN [pool-1-thread-1066] (Heartbeat.java:416) -datasource 5 192.168.200.52:331001_3310_ms heartbeat failed and will be no longer used.
在没有配置切换规则时,不会进行切换,计算节点记录日志
WARN [pool-1-thread-177] (?:?) -datanode id failover failed due to found no backup information
- 在存储节点发生故障切换后,不论主从还是双主,我们统一要求,手动将存储节点置为可用的前提是操作人员必须清楚当前主从服务无异常,数据同步无异常,特别是主从模式,要保证期间备提供服务时的数据同步到了主存储节点。存储节点启用时,我们要养成习惯,不要跳过主备一致性检测。
配置库高可用
配置库、部分存储节点部署在同一实例或同一服务器时,若该实例出现故障,故障信息无法记入配置库,故计算节点支持配置库高可用功能,保证配置库可正常使用。
在server.xml里配置主从配置库的连接信息,保证主从关系正常;
<property name="url">jdbc:mysql://192.168.200.191:3310/hotdb_config</property><!-- 主配置库地址 -->
<property name="username">hotdb_config</property><!-- 主配置库用户名 -->
<property name="password">DRDS_config@2013</property><!-- 主配置库密码 -->
<property name="bakUrl">jdbc:mysql://192.168.200.190:3310/hotdb_config</property><!-- 从配置库地址 -->
<property name="bakUsername">hotdb_config</property><!-- 从配置库用户名 -->
<property name="bakPassword">DRDS_config@2013</property><!-- 从配置库密码 -->
-
当主配置库发生故障时会自动切换到从配置库。切换过程中若存在延迟会等待从配置库复制延迟追上后切换成功并提供服务。
-
当主配置库发生故障时,在从配置库会自动接管,但是主备配置库的类型不会发生改变,主配置库的角色仍旧是主,备配置库的角色依旧是备,而提供配置库服务的是备配置库。
-
若计算节点高可用服务涉及配置库的主从关系,需保证server.xml中一组计算节点高可用的主从配置库的配置完全相同,不能交错配置。
-
在灾备模式下,如果灾备机房的主配置库发生故障,其备配置库会级联标记为不可用。如果中心机房的主配置库故障切换到备配置库,中心机房的备配置库会与灾备机房的主配置库搭建复制关系(灾备机房主配置库为备库),若修复了中心机房的主配置库且启用, 动态加载回到中心机房的主配置库时,计算节点会先解除中心机房的备配置库与灾备机房的主配置库的复制关系, 并重新搭建中心机房新启用的主配置库与灾备机房的主配置库的灾备复制关系。此过程中需要人工保证中心机房的主配置库故障切换到中心机房的备配置库后,恢复中心机房的主配置库且中心机房的备配置库到中心机房的主配置库有复制回路,才可以启用中心机房的主配置库。
2.配置库同时支持MGR配置库(存储节点必须是5.7以上,配置库MGR暂时只支持三个节点),在server.xml中配置具有MGR关系的配置库信息,并且保证MGR关系正常。MGR关系不正确的情况下,配置库可能会无法正常提供服务,以及可能造成启动不成功。
<property name="url">jdbc:mysql://192.168.210.22:3308/hotdb_config_test250</property><!-- 配置库地址 -->
<property name="username">hotdb_config</property><!-- 配置库用户名 -->
<property name="password">DRDS_config@2013</property><!-- 配置库密码 -->
<property name="bakUrl">jdbc:mysql://192.168.210.23:3308/hotdb_config_test250</property><!-- 从配置库地址(如配置库使用MGR,必须配置此项) -->
<property name="bakUsername">hotdb_config</property><!-- 从配置库用户名(如配置库使用MGR,必须配置此项) -->
<property name="bakPassword">DRDS_config@2013</property><!-- 从配置库密码(如配置库使用MGR,必须配置此项) -->
<property name="configMGR">true</property><!-- 配置库是否使用MGR -->
<property name="bak1Url">jdbc:mysql://192.168.210.24:3308/hotdb_config_test250</property><!-- MGR配置库地址(如配置库使用MGR,必须配置此项) -->
<property name="bak1Username">hotdb_config</property><!-- MGR配置库用户名(如配置库使用MGR,必须配置此项) -->
<property name="bak1Password">DRDS_config@2013</property><!-- MGR配置库密码(如配置库使用MGR,必须配置此项) -->
MGR配置库在主库发生故障时,根据实际存储节点的重新选主逻辑,在选出新的主库时,会及时切换到新的主配置库。
计算节点高可用
计算节点支持高可用架构部署,利用keepalived高可用服务原理搭建主备服务关系,可保证在主计算节点(即Active计算节点) 服务故障后,自动切换到备计算节点 (即Standby计算节点),应用层面可借助Keepalived的VIP 访问数据库服务,保证服务不间断。
启动说明
在启动高可用架构下的主备计算节点服务时,需要注意启动的顺序问题,如下为标准启动顺序:
1.先启动主计算节点,再启动主计算节点所在服务器上的Keepalived:
查看计算节点日志:
2018-06-13 09:40:04.408 [INFO] [INIT] [Labor-3] j(-1) -- HotDB-Manager listening on 3325
2018-06-13 09:40:04.412 [INFO] [INIT] [Labor-3] j(-1) -- HotDB-Server listening on 3323
查看端口监听状态:
root> ss -npl | grep 3323
LISTEN 0 1000 *:3323 *:* users:(("java",12639,87))
root> ps -aux |grep hotdb
Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ
root 12639 60.7 34.0 4194112 2032134 ? Sl Jun04 7043:58 /usr/java/jdk1.7.0_80/bin/java -DHOTDB_HOME=/usr/local/hhdb-2.4/hotdb-server -classpath /usr/local/hhdb-2.4/hhdb-server/conf: ...省略更多... -Xdebug -Xrunjdwp:transport=dt_socket,address=8065,server=y,suspend=n -Djava.net.preferIPv4Stack=true cn.hotpu.hotdb.HotdbStartup
使用命令"ip a"可查看当前主计算节点的Keepalived VIP是否已绑定成功,如下例子中,192.168.200.190为主计算节点所在服务器地址;192.168.200.140为配置的VIP地址:
root> ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000
link/ether 00:1d:0f:14:8b<i class="fa brd ff"></i>ff:ff:ff:ff:ff
inet 192.168.200.190/24 brd 192.168.200.255 scope global eth1
inet 192.168.200.140/24 scope global secondary eth1:1
inet6 fe80::21d:ff:fe14:8bfa/64 scope link
valid_lft forever preferred_lft forever
2.再启动备计算节点,再启动备计算节点所在服务器上的Keepalived:
查看计算节点日志
2018-06-04 18:14:32:321 [INFO] [INIT] [main] j(-1) -- Using nio network handler
2018-06-04 18:14:32:356 [INFO] [INIT] [main] j(-1) -- HotDB-Manager listening on 3325
2018-06-04 18:14:32:356 [INFO] [AUTHORITY] [checker] Z(-1) -- Thanks for choosing HotDB
查看端口监听状态:
root> ss -npl | grep 3325
LISTEN 0 1000 *:3325 *:* users:(("java",11603,83))
root> ps -aux |grep hotdb
Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ
root 11603 12.0 13.6 3788976 1086196 ? Sl Jun04 1389:44 /usr/java/jdk1.7.0_80/bin/java -DHOTDB_HOME=/usr/local/hhdb-2.4/hotdb-server -classpath /usr/local/hhdb-2.4/hhb-server/conf: ...省略更多... -Xdebug -Xrunjdwp:transport=dt_socket,address=8065,server=y,suspend=n -Djava.net.preferIPv4Stack=true cn.hotpu.hotdb.HotdbStartup
高可用切换说明
当主计算节点(以192.168.200.190为例)服务故障时,检测脚本(vrrp_scripts)检测到主计算节点服务端口不可访问或hacheck连续失败超过3次,优先级会进行调整,变成 90(weight -10)。
备计算节点(以192.168.200.191为例)服务上的 keepalived 收到比自己优先级低的 vrrp 包(192.168.200.191上优先级为 95)后,将切换到 master 状态,抢占 vip(以192.168.200.140为例)。同时在进入 master 状态后,执行 notify_master 脚本,访问192.168.200.191上的计算节点管理端口执行 online 命令启动并初始化192.168.200.191上的计算节点服务端口。若该计算节点启动成功,则主备切换成功继续提供服务。192.168.200.191上的计算节点日志如下:
2018-06-12 21:54:45.128 [INFO] [INIT] [Labor-3] j(-1) -- HotDB-Server listening on 3323
2018-06-12 21:54:45.128 [INFO] [INIT] [Labor-3] j(-1) -- =============================================
2018-06-12 21:54:45.141 [INFO] [MANAGER] [Labor-4] q(-1) -- Failed to offline master Because mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.200.190' (111)
2018-06-12 21:54:45.141 [INFO] [RESPONSE] [$NIOREACTOR-8-RW] af(-1) -- connection killed for HotDB backup startup
...省略更多...
Keepalived的VIP已在192.168.200.191服务器上:
root> ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 18:a9:05:1b:0f:a8 brd ff:ff:ff:ff:ff:ff
inet 192.168.200.191/24 brd 192.168.200.255 scope global eth0
inet 192.168.200.140/24 scope global secondary eth0:1
inet6 fe80::1aa9:5ff:fe1b:fa8/64 scope link
valid_lft forever preferred_lft forever
注意
若通过管理平台手动切换,切换成功的会修改server.xml中的(haState、haNodeHost)的配置,将主备的信息互换,故障切换不会修改配置。
高可用重建
主备模式的计算节点主要通过server.xml以及keepalived.conf配置文件来标识主备的角色。高可用切换只能从主服务切换至备服务,当计算节点发生过故障切换或手动切换后,为保证下次计算节点故障还能顺利回切,需要通过高可用重建操作配置主备计算节点的相应。
例如,通过该功能可实现:当主计算节点(以192.168.200.190为例)发生故障切换,切换到备计算节点(以192.168.200.191为例)后,手动触发计算节点高可用重建功能,可重新配置两台服务器上计算节点服务的主备关系,其中192.168.200.191为主,192.168.200.190为备。当192.168.200.191服务器上计算节点再发生故障时,可自动进行回切到192.168.200.190。关于高可用重建详情请参考管理平台文档。