Python的环境配置
python安装
-
安装地址
- 官网网址:https://www.python.org
- 华为云镜像站地址:https://mirrors.huaweicloud.com/home
-
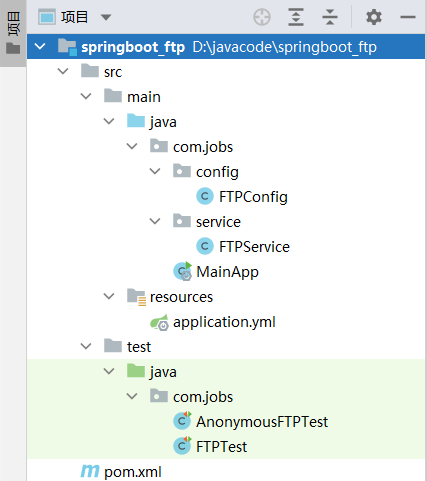
python根目录介绍
根目录截图

- python的根目录【安装目录】:D:\soft\Python37
- Scripts
- pip # 从python官网上下载第三方的库
- pip3.7
- pip3
- Lib # python自带的库供我们开发使用
- site-packages # 放离线下载好的第三方库文件
- python.exe # 用于解释运行符合python语法规范的文件
- Scripts
一个简单python程序的运行
- 打开命令行窗口
win + R 输入cmd
window下命令行的简单命令:
1、盘符: 切换盘符2、dir 查看当前目录下所有的文件或者文件夹3、cd 目标路径 切换目录4、cd.. 退回上一级目录
- 编写python文件
print('hello world')
- 使用python.exe解释运行符合python语法格式的文件
python.exe a1.txt

注意:原则上,若你写的是一个符合python语法格式的文件,那该文件严格来说应该以.py后缀,表示该文件是一个python文件。
python编辑器PyCharm的安装与使用
- 下载网址:https://www.jetbrains.com/pycharm/
- 修改安装目录

- 在本地创建pycharm项目文件夹作为将来项目存储位置

- 创建一个项目

- 项目结构

-
将python解释器修改成自己安装的路径

-
修改字体大小快捷键

修改pip源
举例:需要做爬虫操作,需要下载requests库
命令:pip install request
pip 修改 pip 源
找到系统盘下C:\Users\用户名\AppData\Roaming,APPData可能是隐藏文件,需要将隐藏关闭;
查看在Roaming文件夹下有没有一个pip文件夹,如果没有创建一个;
进入pip文件夹,创建一个pip.ini文件;
使用记事本的方式打开pip.ini文件,写入:
[global]
index-url=http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
临时修改
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy

不用阿里云下载的速度很慢因为官网是国外的

用阿里云下载速度比较快因为是国内的
python的基础语法
输入和输出 input
-
例子1:输入自己的姓名并输出
name=input("请输入您的名字:") print(name) -
例子2:输入自己的年龄并输出
age=input("请输入您的年龄:") print(age)#易错点:input函数接收的所有内容都是字符串格式的 -
作用:
-
接收键盘的录入的数据
-
表示停顿作用,没有任何变量接收
-
-
直接使用print(), 以默认的格式输出内容
print("hello world") print("杨浩东真帅!")输出的结果是有换行符的,默认在每一行输出结果后面有一个\n
-
查看print源码分析 先点ctrl 移动到鼠标点击打开源码
def print(self, *args, sep=' ', end='\n', file=None): # known special case of print"""print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)Prints the values to a stream, or to sys.stdout by default.Optional keyword arguments:file: a file-like object (stream); defaults to the current sys.stdout.sep: string inserted between values, default a space.end: string appended after the last value, default a newline.flush: whether to forcibly flush the stream."""pass -
参数理解
-
sep是用作分隔符的作用
name=input("请输入您的姓名:") print("您的姓名是:" ,name) #您的名字是:杨浩东修改拼接的修饰符
name=input("请输入您的姓名:") print("您的姓名是:" ,name,sep='-') #您的名字是:-杨浩东 -
end输出完最后一行,跟的符号,默认是\n换行符
#春眠不觉晓,处处闻啼鸟 print("春棉不觉晓",end=',') print("处处闻啼鸟")
-
格式化代码的快捷键:ctrl + alt + L
变量
在python程序运行过程中,其值可以发生改变的量,类似于数学中的未知数,将一个确定的值赋值给这个未知数
a=100 #将数值100赋值给左边变量a
-
定义变量时的一些规则:
-
变量由英文大小写字母,数字,或下划线组成
-
不能以数字开头
-
不能是python中的关键字
-
举例
name √ a1 √ 33name × 以数字开头 33_name × 以数字开头 name$ × 含除_以外的特殊字符 def × 是python中的关键
-
-
-
定义变量时的规范
-
要见名知意
-
命名要施行驼峰式命名法或者下划线命名法
-
驼峰式命名法 第一个单词全部小写,从第二个单词开始,首字母大写
highStudent playGame selectStudentWithName -
下划线命名法 所有单词全部小写,单词与单词之间使用下划线拼接
high_student play_game
-
-
数据类型
-
str字符类型
-
格式1:由单引号括起来的若干个字符序列
s1='这是一个字符串' -
格式2:由双引号括起来的若干个字符序列
s2="这也是一个字符串" -
格式3:由三个单引号括起来的若干个字符序列
s3='''这也是一个字符串''' -
格式4;由三个双引号括起来的若干个字符序列
s4="""这也是一个字符串序列"""区别:前两种格式不能换行表示,后两种可以
-
-
int整数类型
a1 = 100易错点: age=input("请输入您的年龄:") print(age + 1) # 报错! 原因:pytho中+号两边,要么都是数值类型,要么都是字符串类型,不能将字符串类型与数值做加法运算 -
float 小数类型
a2=13.34 -
bool布尔类型
True False
类型转换
-
查看变量的数据类型type()
age=input("请输入您的年龄:") print(type(age) ) -
转整数int(待转的值)
age=input("请输入您的年龄:") print(int(age)+1 )易错点:并非所有的值都能转化为数值 name=input("请输入您的年龄:") print(int(name) ) #报错 -
转小数float(待转的值)
-
转字符串str(待转的值)
-
转bool类型 bool(待转的值)
-
有些值转bool的结果一定是False
print(bool(0)) print(bool(0.0)) print(bool("")) print(bool(''))运行结果
-

-
-
转bool隐藏用法 只要不是上面的值,转bool的结果都是Ture
if 1:#bool(1)print("nihao")
-
注释
在python程序运行过程中,不会被解释运行的文字
-
单行注释 #
#使用python内置print函数输出一句话:hello worldprint("hello world!")print("hello world) #使用python内置print函数输出一句话:hello world -
多行注释 ''' 或者 """
'''print("hello world!1")print("hello world!2")print("hello world!3")print("hello world!4")print("hello world!5")print("hello world!6")print("hello world!7")print("hello world!8")'''
"""print("hello world!1")print("hello world!2")print("hello world!3")print("hello world!4")print("hello world!5")print("hello world!6")print("hello world!7")print("hello world!8")"""
易错点:若使用变量接收多行注释,那么就相当于一个大的字符串,若没有变量,相当于一个多行
注释:
注释的快捷键:ctrl+/按下一次,进行注释,再按一次打开注释。
pass关键字
主要是为了维护语法结构的完整性提供的
字符串的格式化
需求:输入自己的姓名,年龄,性别,爱好,并输出
-
方式1:使用+号拼接
name = input("请输入您的姓名:") age = input("请输入您的年龄:") gender = input("请输入您的性别:") like = input("请输入您的爱好:") print("您的姓名是:" + name + ", 年龄:" + age + ", 性别:" + gender + ", 爱好:" +like) -
方式2:使用.format进行格式化 【是python推荐的方式】
-
类型1:
name=input('请输入您的姓名:') age=input('请输入您的年龄:') gender=input('请输入您的性别:') like=input('请输入您的爱好:') # 方式二的类型1 print('您的姓名是:{0},年龄:{1},性别:{2},爱好:{3}'.format(name,age,gender,like)) -
类型2:{}
若大括号中不传索引,那么大括号取值的时候,按照后面的值的顺序进行取值
name=input('请输入您的姓名:') age=input('请输入您的年龄:') gender=input('请输入您的性别:') like=input('请输入您的爱好:') # 方式二的类型2 print("您的姓名是:{},年龄:{},性别:{},爱好:{}".format(name,age,gender,like)) -
类型3:
name = input("请输入您的姓名:") age = input("请输入您的年龄:") gender = input("请输入您的性别:") like = input("请输入您的爱好:") print("您的姓名是:{a1},年龄:{a2},性别:{a3},爱好:{a4}, 不好意思没听清,您的爱好是:{a4}".format(a1=name, a2=age, a3=gender,a4=like))
-
-
方式3:%
这种方式传参,需要考虑数据类型的问题
name = input("请输入您的姓名:")
age = input("请输入您的年龄:")
gender = input("请输入您的性别:")
like = input("请输入您的爱好:")
print("您的姓名是:%s,年龄:%s,性别:%s,爱好:%s" % (name, age, gender, like))
- f-{} 【老师推荐的使用方式】
name=input('请输入您的姓名:')
age=input('请输入您的年龄:')
gender=input('请输入您的性别:')
like=input('请输入您的爱好:')
print(f"您的姓名是:{name},您的年龄是:{age},性别:{gender},爱好:{like}") #f {}的形式比较简单推荐
语句结构
选择结构if
注意事项:
判断条件的结果必须是bool类型
语句体前面必须要有缩进,默认是一个tab键【4个空格】
-
格式1:
if 判断条件:当判断条件为True的时候执行 -
格式2:
if 判断条件:当判断条件为True的时候执行 else:当判断条件为False的时候执行 -
格式3:
if 判断条件1:当判断条件1为True的时候执行 elif 判断条件2:当判断条件2为True的时候执行 elif 判断条件3:当判断条件3为True的时候执行 elif 判断条件4:当判断条件4为True的时候执行 ... -
格式4:为了程序的严谨性,在格式3的基础上增加else
if 判断条件1:当判断条件1为True的时候执行 elif 判断条件2:当判断条件2为True的时候执行 elif 判断条件3:当判断条件3为True的时候执行 elif 判断条件4:当判断条件4为True的时候执行 ... #不满足条件就往下运行 else: 当上面所有的条件都不满足的时候执行扩展知识:在python中数值是可以进行连续比较。
循环结构for&while
-
range()内置函数
-
使用方法1:range(数值) 生成一个序列,序列范围是0 ~ 数值-1取值都是左闭右开
for i in range(10): print(i) -
使用方式2:range(开始值, 结束值) 生成一个序列,序列范围是 开始 ~ 结束-1
# 输出1-10 for i in range(1, 11): # 1~10 print(i) -
使用方式3:range(开始值, 结束值, 步长) 生成一个序列,序列范围是 开始 ~ 结束-1 ,取值的方式每隔步长取一次
for i in range(1, 11, 2): # 1 3 5 7 9 print(i)
-
-
for循环语句
-
格式1: 遍历序列
for 变量1[,变量2,变量3....] in 可遍历序列: 使用变量-
需求:求1-10之和
num = 0 for i in range(1, 11):num = num + i print(f"1-10之和为:{num}") -
需求:求1-100之间奇数和
num = 0 for i in range(1, 101):if i%2==1:num = num + i print(f"1-10之和为:{num}")
-
-
-
格式2:
for 变量1[,变量2,变量3....] in 可遍历序列:使用变量 else:语句体 # 当for循环正常结束的情况下,执行这里的else
-
-
while循环语句
-
格式1:
while 判断条件表达式:循环体-
例子:
注意: 使用while循环的时候,要注意结束循环的条件变化!否则一不小心就成了死循环
-
-
num=1
while num<=5:
print('好好学习,天天向上')
num=num+1
print('hello world')
```
-
-
格式2:
while 判断条件表达式:循环体 else:语句体 # 当while循环正常结束的情况下,执行这里的else
-
-
for循环和while循环的区别?
- 当你确定循环的范围的时候,优先考虑for循环 【吃葡萄】
- 若循环的范围不确定,但是能够知道循环的结束条件的时候,优先考虑while循环 【喝水】
控制流程语句
-
continue 继续,跳过当次循环,继续下一次循环
-
需求:遍历1-10,当遇到5的时候,使用一次continue
-
for循环实现
num=1 while num<=5:print('好好学习,天天向上')num=num+1 print('hello world') -
while循环实现
while num<=10:if num==5:num=num+1continueprint(num)num=num+1
-
-
-
break结束,终止整个循环
-
需求:遍历1-10,当遇到5时,使用一次break
-
for循环实现
for i in range(1,11):if i==5:breakprint(i)print('好好学习') -
while循环实现
num=1 while num<=10:if num==5:num=num+1breakprint(num)num=num+1 -
注意,遇到break的时候,无论是for循环,还是while循环,若存在else语法都不会执行
-
-
数据类型详解
字符串
概述:由若干个字符组成字符序列,称之为字符串
特点:字符串一旦被创建就不能被更改
-
定义一个字符串
s1='hello' -
字符串一旦被创建就不能被更改
s1 = "hello" s1 = "world" # 相当于将新的字符串内存中的地址值赋值给了s1,原本的"hello"的内容没有改变 print(s1)公共功能
-
len() python内置的函数,可以获取字符串的长度【字符个数】
s1='shujia' print(len(s1)) -
字符串具有索引的概念,可以通过索引获取对应的字符
-
从左向右,从0开始编号;从右向左,从-1开始编号
-
使用for循环遍历一个字符串,得到每一个字符
-
字符串通过索引获取字符语句格式:字符串变量名[索引]
s1='shujia' for i in range(len(s1)):print(s1[i],end='') #若下面想再打一行其他的东西可以加 else:print()print("hello world")
-
-
-
字符串具有切片功能
-
字符串变量名[开始索引 : 结束索引] 【注意:左闭右开】
s1 = "33期的同学们,大家好,欢迎来到数加科技!" print(s1[8:11]) #从左向右第一个为0 print(s1)s1 = "33期的同学们,大家好,欢迎来到数加科技!" print(s1[-13:-10]) #从右向左从-1开始并且顺序从小往大左闭右开区间 print(s1) -
字符串变量名[开始索引 : 结束索引 : 步长]
s1 = "33期的同学们,大家好,欢迎来到数加科技!" print(s1[::2]) #【开始索引 : 结束索引 : 步长】 print(s1)
-
-
in 用于判断某一个字符串,是否被包含在原有字符串中
s1 = input("请输入一个包含字母和数字的字符串:") if '数加' in s1:print("是数加的学生") else:print("不是数加的学生") -
not in 判断不在
独有功能
-
upper() 转大写
s1 = "hello" print(s1.upper()) # HELLO -
lower()转小写
s1 = "heLlO wORlD" print(s1.upper()) # HELLO print(s1.lower()) # hello world举个例子:登录应用
name=input("请输入您的姓名:") pwd=input("请输入您的密码:") if name=='root'and pwd=='123456':print('登录成功') else:print('登录失败') #------若想用户一直输入知道输入正确-------- while True:name=input("请输入您的姓名:")pwd=input("请输入您的密码:")if name=='root'and pwd=='123456':print('登录成功')breakelse:print('登录失败,请重新输入') #-------若用户忘记不愿意继续再登录了怎么改------ while True:name=input("请输入您的姓名:")if name=='Q' or name=='q':print('退出登录系统')breakpwd=input("请输入您的密码:")if name=='root'and pwd=='123456':print('登录成功')breakelse:print('登录失败,请重新输入') -
isdigit() 判断字符串内容是否是数字
s1=input('请输入一个字符串')# if s1.isdigit():print(int(s1)+1)#字符串不能和数字直接相加所以要用int转换一下 else:print('您输入的字符串内容不是一个数值')练习:输入一个长字符串,判断其中数字的个数
输入一个长字符串,判断其中数字的个数。
s1=input("请输入一个包含字母和数字的字符串:")
num=0
for i in s1: #字符串是可以直接被for循环遍历得到每一个字符
if i.isdigit():
num=num+1
print(f'该字符串中数字的个数为:{num}')
- startswith 判断字符串是否以某个小字符串开头```python
s1 = "shujia数加科技学习study"
b = s1.startswith('sh')
print(b) # True
-
endswith 判断字符串是否以某个小字符串结尾
s1="shujia数加科技学习study" b = s1.endswith('wdy') #判断s1中 print(b) # False -
split指定分隔符从左向右切进行切分
# 扩展知识:.csv后缀格式的文件,若以记事本打开的话, # 列和列之间,默认使用的是英文逗号分割的 # 1001,张三,18,男,33期 s1 = "1001,张三,18,男,33期" l1 = s1.split(',') print(l1)默认是所有分隔符都会切分,但是可以设置maxsplit参数值,指定切割的次数
s1 = "1001,张三,18,男,33期"
l1 = s1.split(',', maxsplit=2)
print(l1) # ['1001', '张三', '18,男,33期']
-
rsplit指定分隔符从右向左切进行切分
s1 = "1001,张三,18,男,33期" # l1 = s1.split(',', maxsplit=2) 从左向右切 # print(l1) # ['1001', '张三', '18,男,33期'] l1 = s1.rsplit(',', maxsplit=1) print(l1) -
join以调用该方法的字符串进行拼接
s1 = "1001,张三,18,男,33期" l1 = s1.split(',') print(l1) # 1001|张三|18|男|33期 print("---------------------") s2 = '|'.join(l1) print(s2) -
replace 指定新字符串替换旧字符串
s1 = '今天我在数加科技学习,今天学习了大数据相关的知识,在数加每一天都很充实!' s2 = s1.replace('数加', 'shujia') print(f"s1:{s1}") print(f"s2:{s2}") -
strip() 去除字符串两边的空白字符, 注意不会去除字符串中间本身的空白字符
s1 = ' hello world ' s2 = s1.strip() print(f"s1:{s1}") # s1: hello world print(f"s2:{s2}") # s2:hello world -
rstrip() 去除字符串右边的空白字符
-
ltrip() 去除字符串左边边的空白字符
-
例子:登陆例子
name = input("请输入您的姓名:") pwd = input("请输入您的密码:")if name.strip()=='root' and pwd.strip()=='123':print('登录成功!')else:print('登录失败!')
-
字符串练习
-
多次替换
每次替换都会得到一个新的结果字符串,下次替换,接着上一次结果继续替换
s1='今天我在数加科技学习,今天学习了大数据相关的知识,在数加每一天都很充实'
s2=s1.replace('数加','shujia')
s3=s2.replace('数据','data')
s4=s3.replace('每一天','every day')
print(s4)
使用一个变量,覆盖接收新的结果
s1='今天我在数加科技学习,今天学习了大数据相关的知识,在数加每一天都很充实'
s1=s1.replace('数加','shujia')
s1=s1.replace('数据','data')
s1=s1.replace('每一天','every day')
print(s1)
使用链式调用改进
s1 = ("今天我在数加科技学习,今天学习了大数据相关的知识,在数加每一天都很充实!".replace('数加','shujia').replace('数据','data').replace('每一天','every day'))
print(s1)
-
写代码实现,用户输入自己的国籍,如果是以中国开头,输出中国人,否则输出外国人
方式一:使用startswith实现
s1=input('请输入您的国籍')
if s1.startswith('中国'):print('中国人')
else:print('外国人')
方式2:单独取前两个字符判断
s1=input('请输入您的国籍')
if s1[0:2]=='中国':print("中国人")
else:print('外国人')
-
根据用户输入的文本信息,统计出‘数’这个字的出现次数
s1=input('请输入一个文本:') num=0 for i in s1: #遍历s1中的字符串if i=='数':num=num+1 print(f'一共出现了:{num}次') -
根据用户输入的文本信息(只包含英语字母和数字),将所有的字母和数字单独提取出来
# 根据用户输入的文本信息(只包含英语字母和数字),将所有的字母和数字单独提取出来 s1 = input("输入一个文本: ") # dsadsa78qwfq89faav7a96qw0fsa7875a number_str = '' zimu_str = '' for i in s1: if i.isdigit(): number_str = number_str + i else: zimu_str = zimu_str + i print(f"所有数字字符:{number_str}") print(f"所有非数字字符:{zimu_str}")
整数int
所有的整数都是int类型,包括负数
小数float
所有的小数都是float类型,包括负数
布尔bool
就两种值,Ture和False
列表list
用于存储多种元素的容器,列表中的元素具有有序【存储和取出的顺序一致】且可以发生重复的特点
同样具备索引的概念,同一个列表中的元素类型可以是不一样的
举例:[10, 12.23, '数加', True, [11,22,33,44], 'shujia']
公共功能
-
长度功能
# 如何创建一个空列表? # 方式1:直接使用[] list1 = [] # 方式2:使用内置函数list() list1 = list() # 使用len()函数获取元素的个数 list1 = [10, 12.23, '数加', True, [11,22,33,44], 'shujia'] print(f"list1列表中的元素个数为:{len(list1)}") # 6 # 列表本身就是一个可以迭代的序列,所以直接使用for循环获取元素 list1 = [10, 12.23, '数加', True, [11,22,33,44], 'shujia'] for i in list1: print(i) -
索引功能
# 0 1 2 3 4 5 list1 = [11, 22, 33, 44, 55, 66] # -6 -5 -4 -3 -2 -1 print(list1[2:5]) print(list1, type(list1)) # 使用负数索引获取33,44,55 print(list1[-4:-1]) # [33, 44, 55] # 按顺序取55,44,33 print(list1[-2:-5:-1]) # [55, 44, 33] -
in 判断某一个元素是否在列表中出现
list1 = [11,22,33,44,55,66,22,11,55,77,22,11,22]
if 77 in list1:
print("77出现在列表中")
else:
print("未出现")
独有功能 在列表自身的基础上做修改
-
增加元素
-
追加append
# 创建一个空列表 list1 = [] # list1 =list() list1.append(100) list1.append('hello') list1.append('world') list1.append(True) list1.append('hello') list1.append('flink') print(f"list1:{list1}") # list1:[100, 'hello', 'world', True, 'hello','flink']例子
name_list = [] while True:name = input("请输入登录用户的名字:")if name.upper() == 'Q':breakname_list.append(name) print(name_list) -
插入insert
list1=[100,'hello','world',True,'hello','flink'] print(f'list1:{list1}') list1.insert(2,'杨浩东') print(f'list1:{list1}')
-
-
删除元素
-
方式1:调用remove()函数 在已知要删除元素的值
list1 = [11, 22, 33, 44, 55, 66] list1.remove(44) # list1.remove(100) # 报错 print(f"list1: {list1}") print('hello world')注意:使用remove需要确保要删除的元素存在于列表中,否则报错,程序停止运行。
-
方式2:调用pop()函数 根据索引删除元素,返回被删除元素的值
list1 = [11, 22, 33, 44, 55, 66] s = list1.pop(3) print(f"list1: {list1}") print(s) print('hello world') -
方式3:使用python内置关键字 del
list1 = [11, 22, 33, 44, 55, 66] del list1[3] print(f"list1: {list1}")
-
-
修改元素 直接通过索引覆盖原有的值,起到修改的效果
list1 = [11, 22, 33, 44, 55, 66]list1[3] = 100print(f"list1: {list1}") -
反转功能 reverse
list1 = [11, 22, 33, 44, 55, 66] print(f"反转前:{list1}") list1.reverse() print(f"反转后:{list1}")练习:判断某一个字符串是否是对称字符串
# aba helloolleh hello owo str1 = input("请输入一个字符串:") list2 = list(str1) # 字符串转列表,每个字符作为列表中的元素 list2.reverse() # 将列表中的元素进行反转 str2 = ''.join(list2) # 将元素以指定分隔符拼接得到字符串 if str2==str1:print("该字符串是一个对称字符串!") else:print("不是对称字符串!") -
拷贝功能
-
浅拷贝 python列表中的copy()属于浅拷贝
-
拷贝单个元素列表的形式
list1 = [11, 22, 33, 44, 55, 66] list2 = list1.copy() print(f"list1:{list1}") print(f"list2:{list2}") print("-----------------------------") list1[3] = 100 print(f"list1:{list1}") print(f"list2:{list2}")画图解释
-
拷贝复杂元素列表的形式
list1 = [11, 22, 33, [100, 200, 300], 55, 66] list2 = list1.copy() print(f"list1:{list1}") print(f"list2:{list2}") print("-----------------------------") list1[3][1] = 'hello' print(f"list1:{list1}") print(f"list2:{list2}")画图解释
-
深拷贝
画图解释
-
-
-
-
count() 统计列表中某个元素的个数
list1=[11,22,33,[100,200,300],11,11,22,55,99] s1=list1.count(11) print(s1)
元组tuple
元素有序,也可以发生重复,但是元素中的元素,一旦确定了,就不能更改【无法完成增删改】
-
如何创建一个元组?
-
创建一个空元组
# 创建一个空元组 # t1 = () t1 = tuple() print(t1, type(t1)) -
创建一个非空元组
-
创建一个只有1个元素的元组 , 元素的后面要有一个逗号,若不加,等同于一个元素直接赋值
t1 = (11,) print(t1, type(t1)) -
创建一个元素个数大于等于2的元组 最后一个元素后面加逗号或者不加都行
# t2 = (11,22,33,) t2 = (11,22,33) print(t2, type(t2))
-
-
公共功能
-
长度功能 获取的是元素的个数
t2 = (11,22,33,) print(len(t2)) -
索引功能
t2 = (11,22,33,) print(t2[1])# 遍历元组 t1 = (11,22,33,44,55,66) for i in t1:print(i) -
切片功能
t1 = (11,22,33,44,55,66) print(t1[2:5]) # (33, 44, 55) -
in 包含
t1 = (11,22,33,44,55,66) if 44 in t1:print("yes") else:print("no")
独有功能
-
count()
-
index()
通常情况下,开发中我们将元组中存储固定的链接值,比如与数据库的连接信息,重要的路径信息。
字典dict
特点:
- 元素是由键值对构成,一个键值对看作一个元素
- 键是唯一的,不允许重复出现
- 值可以发生重复的
- 元素键和值的类型可以是不一样的
- 一个字典中的元素之间是有序的【python3.6版本之后】,【python3.6之前是无序的】
-
如何创建一个字典?
# 创建一个空字典 d1 = dict() print(d1, type(d1)) d2 = {} print(d2, type(d2))
公共功能
-
长度功能 获取的是键值对的个数
d1 = {'name':'张三', 'age':18, 'likes':['打游戏','看电影','跑步'], 'dog':{'name':'哮天犬','age':3}} print(len(d1)) # 4 -
索引功能
在字典类型里,索引指的是键,键是唯一,可以通过键获取对应的值
d1 = {'name':'张三', 'age':18, 'likes':['打游戏','看电影','跑步'], 'dog':{'name':'哮天犬','age':3}}
print(d1['age']) # 18
print(d1['likes'][1]) # 看电影
-
切片功能 字典没有切片
-
in 包含功能 判断的是键是否存在字典中
if 'name' in d1: print('存在这个键') # 存在!! else: print("不存在") # ----------------------------------------- if 18 in d1: print('存在这个键') else: print("不存在") # 不存在!! -
遍历
-
先获取所有的键,遍历得到每一个键,根据键获取每一个值
d1 = {'name': '张三', 'age': 18, 'gender': '男', 'clazz': '33期'} # 获取所有的键 keys = list(d1.keys()) for key in keys: # 根据键获取对应的值 value = d1.get(key) print(f"{key}-{value}") -
直接获取所有的键值对,遍历得到每一个键值对,得到每一个键和每一个值
key_values = list(d1.items()) # print(key_values, type(key_values)) for key_value in key_values:key = key_value[0]value = key_value[1]print(f"{key}={value}")
-
独有功能
- keys() 获取字典中所有的键
- get(键) 根据键获取值
- items() 获取所有的键值对
- clear() 清空字典中所有的元素
- pop 根据键从字典中移除一个键值对,返回一个值
集合set
元素唯一且无序
set集合创建的方式:
创建空set集合
s1 = set()创建有元素的集合
s2 = {11, 22, 33, 45, 6, 1, 1, 22, 33, 45, 11}
公共功能
-
没有索引的概念
-
没有切片的功能
-
长度功能
s2 = {11, 22, 33, 45, 6, 1, 1, 22, 33, 45, 11} # print(s2, type(s2)) print(s2) print(len(s2)) -
in 包含
s2 = {11, 22, 33, 45, 6, 1, 1, 22, 33, 45, 11} # print(s2, type(s2)) # print(s2) # print(len(s2)) if 22 in s2:print("yes") else:print("no") -
练习:去重列表中的重复元素
-
方法1:借助一个空列表
list1= [11, 22, 33, 45, 6, 1, 1, 22, 33, 45, 11] # print(list1)list2 = [] for i in list1:if i not in list2:list2.append(i) print(f"list2:{list2}") -
方式2:借助转set集合进行去重
list1= [11, 22, 33, 45, 6, 1, 1, 22, 33, 45, 11] list1 = list(set(list1)) print(list1)
-
独有功能
-
求差集
s1 = {11,22,33,44} s2 = {22,33,55,66} # res1 = s1 - s2 # 求差集 res1 = s1.difference(s2) print(res1) -
求并集
s1 = {11,22,33,44} s2 = {22,33,55,66} res1 = s1.union(s2) print(res1) -
求交集
s1 = {11,22,33,44} s2 = {22,33,55,66} res1 = s1.intersection(s2) print(res1) -
添加元素 add
s1 = {11,22,33,44} s1.add('hello') s1.add('world') s1.add(14) print(s1) -
删除一个元素
res1 = s1.pop() print(s1) print(res1) -
指定元素删除 remove()
若元素不存在,则报错
res1 = s1.remove(11) print(s1) print(res1) -
指定元素删除 discard()
若元素不存在,不会报错
s1 = {11,22,33,44} s1.discard(33) print(s1) -
指定元素删除 remove()
若元素不存在,则报错
res1 = s1.remove(11) print(s1) print(res1) -
指定元素删除 discard()
若元素不存在,不会报错
s1 = {11,22,33,44} s1.discard(33) print(s1)
列表推导式【列表生成式】
# 列表生成式
# 例子:将1-10之间所有的偶数*2 放入到一个列表中
# list1 = [i * 2 for i in range(1,11) if i%2==0]
# list1 = [i * 2 for i in range(1,11)]
list1 = [i * j for i in range(1,11) for j in range(1,11)]print(list1)# [部分1 部分2 [部分3]]
# 部分1:对元素要进行的操作 i * 2
# 部分2:循环取元素 for i in range(1,11)
# 部分3:可以对循环取的元素进行过滤 if i%2==0
作业讲解
在控制台中输出99乘法表 (做出之后,想一想能不能使用一行代码生成)
# 需求1:如何生成5行5列的*
'''
* * * * *
* * * * *
* * * * *
* * * * *
* * * * *
'''
# 生成一行的*
# print('*', end='\t')
# print('*', end='\t')
# print('*', end='\t')
# print('*', end='\t')
# print('*', end='\t')
# for j in range(1,6):
# print('*', end='\t')
# print()
#
# for j in range(1,6):
# print('*', end='\t')
# print()
#
# for j in range(1,6):
# print('*', end='\t')
# print()
#
# for j in range(1,6):
# print('*', end='\t')
# print()
#
# for j in range(1,6):
# print('*', end='\t')
# print()
# 双重for循环
# for i in range(1,6): # 外层for循环控制的是行数
# for j in range(1, 6): # 内层for循环控制的是列数
# print('*', end='\t')
# print()
# 需求2:输出以下三角形的图案
'''
* 第1行,共1列
* * 第2行,共2列
* * * 第3行,共3列
* * * * 第4行,共4列
* * * * * 第5行,共5列
... 第n行,共n列
'''
# for i in range(1, 10):
# for j in range(1, i + 1):
# print('*', end='\t')
# print()
# 输出99乘法表
# for i in range(1, 10):
# for j in range(1, i + 1):
# print(f"{j}*{i}={i * j}", end='\t')
# print()
# 一行生成99乘法表
list1 = [f"{j}*{i}={i * j}" for i in range(1, 10) for j in range(1, i + 1)]
print(list1)
现在有一个元组(1,3,2,4,5,1,2,3,4),请进行去重,最终得到的也是一个元组
list1 = ['华为mate60', 'iphone15 pro', '小米14 pro']
# 方式1:
# n = 1
# for i in list1:
# print(f"{n}.{i}")
# n = n + 1
# 方式2:使用内置函数
for index, e in enumerate(list1):print(f"{index + 1}.{e}")
杨辉三角
list1 = [1]
for i in range(10):print(list1)list1.append(0)list1 = [list1[j] + list1[j - 1] for j in range(i + 2)]
常量
在python程序运行过程中,其值不能改变的量。
在python中没有常量,人为规定,若变量的名字全部大写,这个变量我们今后用的时候,就认为它是常量。
运算符
- 操作数:参与运算的变量或者常量或具体的数值
- 操作符:将参与运算的量连接起来的符号
- 表达式:由操作数和操作符构成且符合python语法规范的式子,不同的操作符可以称为不同类型的表达式
算术运算符

-
-
-
-
/
-
%
-
**
-
//
a = 3 b = 4 print(a + b) # 7 print(a - b) # -1 print(a * b) # 12 print(a / b) # 0.75 print(a % b) # 3 print(a ** b) # 81 print(a // b) # 0 整除
比较(关系)运算符

注意:
= 赋值运算符,== 比较运算符
比较运算符的结果一定是bool类型的
扩展知识:比较两个非基本数据类型的变量
list1 = [11, 22, 33] list2 = [11, 22, 33] # python中==比较列表,元组,字典比较的是内容值 # print(list1 == list2) # True # 比较两个非基本数据类型: # 方式1:使用is关键字 # print(list1 is list2) # False# 方式2:使用python内置函数id() # print(id(list1)) # print(id(list2)) print(id(list1) == id(list2)) # False
赋值运算符

# = 将右边的值赋值给左边的变量或常量
a = 3# a += 4 # a = a + 3
# print(a)
# a -= 4
# print(a)
# a *= 4
# print(a)
# a /= 4
# print(a)
# a %= 4
# print(a)
# a **= 4
# print(a)
a //= 4
print(a)
逻辑运算符

-
and 且 有False则False
a = 3 b = 4 print(a > 3 and b > 4) # False and False = False print(a == 3 and b > 4) # True and False = False print(a > 3 and b == 4) # False and True = False print(a == 3 and b == 4) # True and True = True -
or 或 有True则True
a = 3 b = 4 print(a > 3 or b > 4) # False or False = False print(a == 3 or b > 4) # True or False = True print(a > 3 or b == 4) # False or True = True print(a == 3 or b == 4) # True or True = True -
not 将True变成False, 将False变成True
a = 3 b = 4 print(not a > b) # True
位运算符
进制
将整数分了几种进制表示法: 二进制:由0,1构成,逢2进1,以0b开头 八进制:由0,1,2,3,4,5,6,7构成,逢8进1,以0开头 十进制:由0,1,2,3,4,5,6,7,8,9构成,逢10进1,默认就是10进制 十六进制:由0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f,逢16进1,以0x开头
如何从其他进制转10进制
十进制转十进制 十进制:12345 十进制:12345 12345 = 10000 + 2000 + 300 + 40 + 5= 1*10^4 + 2*10^3 + 3*10^2 + 4*10^1 + 5*10^0= 10000 + 2000 + 300 + 40 + 5= 12345规律口诀:系数*进制的幂次方之和 二进制:0b10011 10011 => 1*2^4 + 0*2^3 + 0*2^2 + 1*2^1 + 1*2^0 = 16 + 2 + 1 = 19如何从10进制转其他进制
除基取余,直到商为0,余数反转
十进制:108 二进制:0b1101100108/2 = 54 ......0 54/2 = 27 ......0 27/2 = 13 ......1 13/2 = 6 ......1 6/2 = 3 ......0 3/2 = 1 ......1 1/2 = 0 ......1如何从其他进制转其他进制
拆分组合法【只适合二进制转八进制或者16进制】
二进制转八进制 从右向左,每3位一组合,每个组合算自己的10进制结果,拼接
二进制转十六进制 从右向左,每4位一组合,每个组合算自己的10进制结果,拼接
二进制:0b1101100 八进制:0154 100->4 101->5 001->1 二进制:0b1101100 十六进制:0x6c 1100->12 0110->6先转10进制,再转其他进制
原码 反码 补码
在计算机所有数据的运算采用的是补码进行的
原码 反码 补码均都是数据的二进制的形式
原码:正数:数值位就是二进制的表现形式,最高位符号位就是0负数:数值位和正数保持一致,但是最高符号位为1 举例:3的原码:1. 3的二进制:112. 3的原码: 00000011-4的原码:1. 4的二进制:1002. -4的原码: 10000100反码:
正数:和原码保持一致
负数:符号位原码保持一致,数值位按位取反
举例:
3的反码: 00000011
-4的反码:11111011
补码:
正数:和原码保持一致
负数:是反码的基础之上末尾+1
举例:
3的补码: 00000011
-4的补码:11111100
举例:-4+3 = -1
-4的补码+3的补码:
00000011
- 11111100
补码:11111111
我们最终看到的结果是转原码再转10进制之后的结果 -1
已知补码求原码:
符号位 数值位
补码: 1 1111111
反码: 1 1111110
原码: 1 0000001数值位转10进制:1,又因为最高位是1,所以是负数,索引最终的结果是 -1

3的补码: 00000011
-4的补码:11111100a = 3
b = -4
print(a & b) # 0 有0则000000011
& 11111100
------------------00000000
print(a | b) # -1 有1则100000011
| 11111100
-----------------
补码:11111111
已知补码求原码
补码: 11111111
反码: 11111110
原码: 10000001
----------------
结果: -1print(a ^ b) # -1 相同则0,不同则100000011
& 11111100
-----------------
补码:11111111
已知补码求原码
补码: 11111111
反码: 11111110
原码: 10000001
----------------
结果: -1
print(~ b) # 3
~ 11111100
-------------0000001112的补码: 00001100
-12的补码:11110100print(12<<2) 左移,左边多的位丢弃,右边用0补齐,左移n位相当于*2^n00001100
左移2位 (00)00110000
--------------------00110000 -> 32+16 = 48
print(-12<<2) # -48print(12>>2) 右移,右边多的位丢弃,左边若最高位是0就用0补齐,若最高位是1就用1补齐,右移相当于除以2^n次方00001100右移2位 00000011(00)
---------------------------
结果:3print(-12>>2) # -3
文件操作
编码
'中' - 11011010
'国' - 1100001011011010 - '儿'
11000010 - '子
常见的编码表
-
ASCII码表 采用一个字节存储键盘上任意一个字符
需要记忆的符号对应的ASCII码值: '0' - 十进制:48 - 二进制:00110000 'A' - 十进制:65 - 二进制:01000001 'a' - 十进制:97 - 二进制:01100001 -
GB2312 | GBK 中国简体汉字字符表示,一个汉字字符占用2个字节
-
BIG-5 大5码 用于表示中国台湾香港繁体字
-
unicode 万国码,表示一个字符占用4个字节 python默认的编码
-
utf-8 是unicode编码的压缩格式,表示一个字符占用3个字节
体验编码-解码的过程
-
编码【看得懂->看不懂的
# 编码 str1 = '今天晚上我们一起去爬大蜀山吧' b1 = str1.encode('UTF-8') print(b1) -
解码【看不懂的->看得懂的】
# 解码 s2 = b1.decode('UTF-8') print(s2)
文件操作的步骤:
- 打开文件【创建与系统资源的连接】
- 操作文件【写 读】
- 关闭文件【释放|关闭系统资源的连接】
写操作 open()
-
方式1:以字节的方式覆盖写数据到文件中 wb模式
f = open('test1.txt', mode='wb') # 若写数据目标文件不存在,则自动创建 # 写数据到文件中 f.write('黄沪生是33期最帅的男人!'.encode('UTF-8')) # 以指定编码变成字节 f.close()路径分类:
-
相对路径:以项目作为根路径进行查找
-
绝对路径:[完整路径|带盘符的路径
f=open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test1.txt', mode='wb') # 写数据到文件中 f.write('黄沪生是33期最帅的男人!'.encode('UTF-8')) f.close() -
方式2:以字节的方式追加写数据到文件中 ab模式
f=open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test1.txt', mode='ab') # 写数据到文件中 f.write('黄沪生是33期最帅的男人!\r\n'.encode('UTF-8')) f.close() -
方式3:以字符的方式以指定的编码覆盖写入 w模式
f = open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test2.txt', mode='w', encoding='UTF-8') # 写数据到文件中 f.write('数加科技666!\r\n') f.close() -
方式4:以字符的方式以指定的编码覆盖写入 a模式
f = open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test2.txt', mode='a', encoding='UTF-8') # 写数据到文件中 f.write('数加科技666!\n') f.close()
读取操作 open()
-
方式1:以字节的形式读取文件数据
f = open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test2.txt', mode='rb') s1 = f.read().decode('GBK') f.close() print(s1) -
方式2:以字符的形式读取文件数据
f = open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test2.txt', mode='r', encoding='GBK') # s1 = f.read() res1 = f.readlines() f.close() # print(res1) for i in res1: if '\n' in i: str1 = i[:-1] else: str1 = i print(str1) print("-" * 50)
文件操作的应用场景
代码中的数据存储到文件中【用户注册】
while True:
name = input("请输入您的姓名:")
if name.upper() == 'Q':
break
pwd = input("请输入您的密码:")
email = input("请输入您的邮箱:")
infos = f"{name},{pwd},{email}\n"
f = open('data/users.csv',mode='a',encoding='UTF-8')
f.write(infos)
f.close()
f = open('data/users.csv',mode='a',encoding='UTF-8')
while True:
name = input("请输入您的姓名:")
if name.upper() == 'Q':
break
pwd = input("请输入您的密码:")
email = input("请输入您的邮箱:")
infos = f"{name},{pwd},{email}\n"
f.write(infos) # 这里的写实际上是往内存中写的
f.flush()
f.close() # 原则上是在关闭连接之前将内存的数据刷到磁盘中
代码逻辑中的数据写到文件中
f = open('data/jj.txt','a',encoding='UTF-8')
for i in range(1, 10):
for j in range(1, i + 1):
f.write(f"{j}*{i}={i * j}\t")
f.write('\n')
f.flush()
f.close()
将网络中的资源写到文件中【爬虫】
json
本质上是一个大的字符串,里面的格式类似于python中的字典,字符串是由双引号括起来的。可以将这样的一个大字符串转成json的格式。
import requests
import json
url = 'https://car-web-api.autohome.com.cn/car/price/getrecommendseries?
appid=8a1aebddbaab9cd59eec077d7563bca0&cityid=340100&type=pccookie&id=E7CA393F-
8482-4658-84A8-8152D7798995'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
response = requests.get(url=url, headers=headers)
text = response.content.decode('UTF-8')
text = text.replace(' ', '').replace('\n', '').replace('\r\n', '')
j = json.loads(text)
car_list = j['result']['serieslist']
f = open('data/cars.csv', mode='a', encoding='UTF-8')
f.write(f"品牌,车型,运作方式,最低售价,最高售价\n")
f.flush()
for car in car_list:
seriesname = car['seriesname']
levelname = car['levelname']
fueltypedetailname = car['fueltypedetailname']
minprice = car['minprice']
maxprice = car['maxprice']
infos = f"{seriesname},{levelname},{fueltypedetailname},{minprice},
{maxprice}\n"
f.write(infos)
f.flush()
f.close()
打开文件的另一种方式
# 第一种
# f = open('data/cars.csv', mode='r', encoding='UTF-8')
# text = f.read()
# print(text)
# f.close()
# 第二种
text = ''
with open('data/cars.csv', mode='r', encoding='UTF-8') as f:
text = f.read()
#
# text = f.read() # f出了with就会被close掉
print(text)
函数
引言:比如植物大战僵尸,这个游戏本身也是由代码编写,现在假设有一种豌豆射手,每发射一次
炮弹会执行100行逻辑代码
如果我在程序,每当需要发射炮弹的时候,都要编写100行逻辑代码,就会觉得该程序过于冗余,
代码重复度较高。
解决方案:
如果我将这100行代码放到一个区域中,然后给这个区域起一个名字,今后在需要发射炮弹的代码
逻辑中,通过这个名字就可以调用起这100行代码。这个区域【代码段】在python中称之为函
数,先将函数定义出来,并对该函数起一个名字,将来在合适的地方通过函数名调用该函数,执行
该函数的内部逻辑。
函数的定义
- 语句定义格式:
# 使用python中的关键字 def
def 函数名(...):
函数代码逻辑
函数使用特点
- 函数不调用不执行
- 定义函数必须在调用之前出现
函数的参数
-
参数种类
- 形式参数:指的是函数定义时,小括号中定义的参数
- 实际参数:指的是将来调用函数时,实际传入进去的具体的值
def fun1(hhs, zcy): # hhs zcy是形式参数,名字自定义print(hhs + zcy)a1 = int(input("请输入第一个数值:"))b1 = int(input("请输入第二个数值:"))fun1(a1,b1) # a1 b1 是实际参数,可以是变量,也可以是具体的值本身 -
参数的传值方式
-
位置传参
def show1(a, b, c):print(f"a:{a},b:{b},c:{c}") # a:11,b:22,c:33show1(11, 22, 33) -
关键字传参 【通过形参的名字传参】
def show1(a, b, c):print(f"a:{a},b:{b},c:{c}")show1(b=100, c=200, a=300) -
混合传参
def show1(a, b, c):print(f"a:{a},b:{b},c:{c}")show1(100, c=200, b=300)注意: 混合传参的时候,前面没有关键字的实参是会按照形参的位置来的,后面关键字传参可以顺序不一样。
函数传参的场景【扩展知识】
# 未使用函数 ''' 编写登录时的逻辑代码 ''' 编写发送邮件的代码 50行 ''' 编写注册时的逻辑代码 ''' 编写发送邮件的代码 50行# 使用函数 def send_email(xxx,xxx): 编写发送邮件的代码 ''' 编写登录时的逻辑代码 ''' send_email(xxx,xxx) ''' 编写注册时的逻辑代码 ''' send_email(xxx,xxx)def send_email(msg_to, send_info): import smtplib from email.mime.text import MIMEText from email.header import Header msg_from = '1165872335@qq.com' # 发送方邮箱 passwd = 'owbciardnivafija' # 填入发送方邮箱的授权码(填入自己的授权码,相当于 邮箱密码) # msg_to = ['','',''] subject = "33期邮件信息" # 主题 # 生成一个MIMEText对象(还有一些其它参数) msg = MIMEText(send_info) # 放入邮件主题 msg['Subject'] = subject # 也可以这样传参 # msg['Subject'] = Header(subject, 'utf-8') # 放入发件人 msg['From'] = msg_from # 放入收件人 # 通过ssl方式发送,服务器地址,端口 s = smtplib.SMTP_SSL("smtp.qq.com", 465) # 登录到邮箱 s.login(msg_from, passwd) # 发送邮件:发送方,收件方,要发送的消息 s.sendmail(msg_from, msg_to, msg.as_string()) print('成功') p = input("请输入要接收邮件的qq邮箱地址:") info = input("请输入要发送的内容:") send_email(p, info) -
默认值传参
需求:调用一个函数,传入一个大字符串和一个小字符串,查找小字符串在大字符串中出现的次数,调用函数的时候,可以不传小字串,默认查找字符'a'在大字符串中的出现次数。
def str_number(big_str, small_str='a'): # 定义函数时,可以设置形式参数的值,作为默 认值 # dadqwwfwqfjwqaoiaiosijpoaospjfqwasaapjosajalist1 = list(big_str)counts = list1.count(small_str)print(f"{small_str}在大字符串中总共出现了{counts}次。。。")str_number('dadqwwfwqfjwqaoiaiosijpoaospjfqwasaapjosaja') # 调用时若不传入第二个 参数,使用的就是定义时的默认值 str_number('dadqwwfwqfjwqaoiaiosijpoaospjfqwasaapjosaja','f') # 若传入第二个参 数,使用的就是实际传入的值 -
动态传参
未使用动态参数时,解决需求,比较麻烦,参数需要另外定义一个函数
# 需求1:定义一个函数,将来传入两个int类型的值求和 def sum1(a, b):print(a + b)sum1(10, 20)def sum2(a, b, c):print(a + b + c) # 需求2:定义一个函数,将来传入三个int类型的值求和 sum2(10, 20, 30)使用动态参数,只需要定义一个函数就可以了
def sum1(*num):# 这里的num 是一个元组,接收若干个将来调用时传入的实参n = 0for i in num:n = n + iprint(f"总和为:{n}")sum1(10, 20) # (10, 20) sum1(10, 20, 30) # (10, 20, 30) sum1(10, 20, 30, 40) # (10, 20, 30, 40)使用动态参数时的注意事项
- 传参的内容,多个参数的类型可以是不一样的
def sum1(*num):# 这里的num 是一个元组,接收若干个将来调用时传入的实参# n = 0# for i in num:# n = n + i# print(f"总和为:{n}")print(num, type(num))# sum1(10, 20) # (10, 20) # sum1(10, 20, 30) # (10, 20, 30) # sum1(10, 20, 30, 40) # (10, 20, 30, 40) # sum1(11) # (11,) # sum1(11, '小虎', [11, 22, 33]) # (11, '小虎', [11, 22, 33]) sum1((11,22,33)) # ((11, 22, 33),)传入两个**的动态参数
def sum1(**num):print(num, type(num))sum1(name='小虎', age=18)结论
* : 表示传入的每一个单独的元素都被封装成一个元组 ** : 表示传入的是一个一个的键值对,所有的键值对会被封装成一个字典 我们今后开发的时候,定义动态参数时,起名字是固定的,若一个*的动态参数,名字起为*args, 若**的动态参数,名字起为**kwargs 动态参数定义的时候,必须 def show1(a, b, *args, **kwargs):print(args, type(args))print(kwargs, type(kwargs)) # show1(11,22,33,44,name='小虎',address='合肥') show1(11, 22, 33, 44, name='小虎', address='合肥') -
函数的返回值
有些函数,我们调用完之后,是能够得到结果的,理论上来说,python中所有的函数都有返回值
python中提供了一个关键字给我们在函数中使用,表示调用完后返回的值,这个关键字叫做return
-
例子
def sum1(a, b):c = a + breturn c res1 = sum1(10, 20) print(res1) print(res1+20) -
函数返回值的特点
- 一个函数中如果没有写return, 默认情况下,这个函数最后一句话会有一个return None
- return 和print的区别?
- return是调用完函数时,可以返回一个值给调用者
- print就直接输出了,没有返回值
- 一个函数中,如果遇到了return,那么这个函数就结束了,函数中的后续代码不执行
def fun1(a, b):print("今天是星期二")c = a + breturn cprint("明天自习") # 不执行res1 = fun1(10, 20) print(res1)- 一个函数中只能有一个return
def fun1(a, b):print("今天是星期二")c = a + breturn cprint("明天自习") # 不执行return 100 # 无效代码res1 = fun1(10, 20) print(res1)def fun1():for i in range(1,11):return ires1 = fun1() print(res1) # 1- 函数返回值return后面,要返回的类型可以是任意的类型
-
函数参数和返回值的练习
- 定义 两个函数,第一个函数用户循环输入要累加的数值,函数内部将用户输入的值封装成一个列表返回;第二个函数将第一个函数返回的列表当作参数传入,返回列表中所有数据之和的结果。
def get_list():list1 = []while True:n = int(input("请输入一个数值:"))if n == -1:breaklist1.append(n)return list1def sum_list(l2):n = 0for i in l2:n += ireturn nl1 = get_list() print(l1) res2 = sum_list(l1) print(res2) -
函数返回值的的一些进阶用法
- 直接返回多个值,多个值之间使用英文逗号分隔,实际返回的内容是一个元组
def show1():return 11, 22, 33res1 = show1() print(res1, type(res1))- 分别接收每个返回元素的值
def show1():return 11, 22, 33a1, a2, a3 = show1() print(f"a1:{a1}") print(f"a2:{a2}") print(f"a3:{a3}")def show1():return 11, ['hello','world','python'], 33a1, a2, a3 = show1() print(f"a1:{a1}") # a1:11 print(f"a2:{a2}") # a2:['hello', 'world', 'python'] print(f"a3:{a3}") # a3:33
函数的分类
- 无参无返回值
def login():# 登录的操作逻辑login()
- 无参有返回值
def get_number():# 随机生成一个数return num
n = get_number()
print(n)
- 有参无返回值
def sum1(a,b):print(a+b)sum1(10,20)
- 有参有返回值
def fun1(s1):return "shujia:" + s1res1 = fun1('hello')
函数可以进行嵌套
- 嵌套调用
def fun1():print("hello world 1")def fun2():return 100def fun3(a1, b1):fun1() # 调用fun1函数res1 = fun2() # 调用fun2函数return a1 + b1 + res1res2 = fun3(11,22)
print(res2)
- 嵌套定义
def fun1():a = 10def fun2():print("hello world")print(a)fun2() # 不调用 不执行fun1()
fun2() # 报错,调用不了函数内部定义的函数