目录
- 概
- Lion
- 代码
Chen X., Liang C., Huang D., Real E., Wang K., Liu Y., Pham H., Dong X., Luong T., Hsieh C., Lu Y. and Le Q. V. Symbolic discovery of optimization algorithms. NeurIPS, 2024.
概
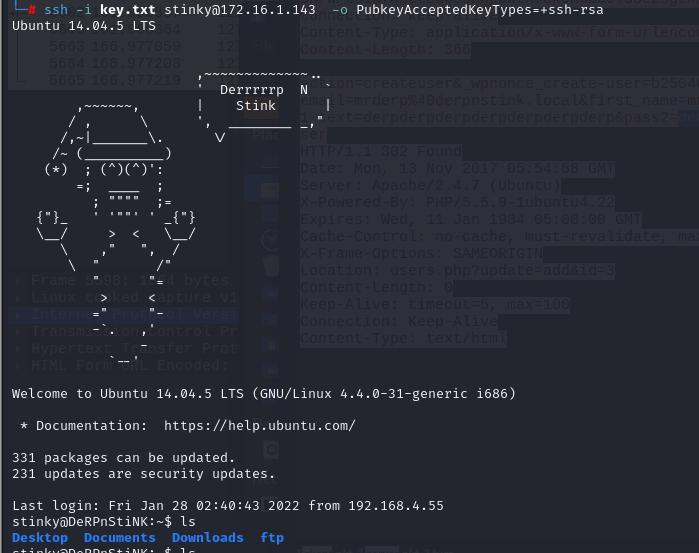
本文搜索出了一个优雅的, 且经验上似乎更好的优化器: Lion.
Lion

-
作者通过一些技巧, 搜索出了一个优雅的优化器, 和 Adam 的最大不同在于:
- 它仅需要维护一个 momentum (一阶);
- 更新的时候采用的是符号梯度更新.
-
特别地,
\[c_t \leftarrow \beta_1 m_{t-1} + (1 - \beta_1) g_t, \]这个保证了我们可以像 Adam 一样通过 \(\beta_1\) 控制对当前梯度 \(g_t\) 的一个倾向.
-
作者认为, 符号梯度 \(\text{sign}(c_t)\) 的一个优势就是能够保证模型整体的参数的大小是保持一致的, 所以泛化性更好. 实际上, 作者发现, 有些时候, Lion 最终的收敛的损失可能是比 AdamW 要高的, 但是最终在验证集上的实际精度却是要更高, 这一定程度上说明了猜想的合理性.
-
在权重调节方面, 与 AdamW 稍有不同:
- \((\beta_1, \beta_2)\) 的建议大小为 \((0.9, 0.99)\) 而不是和 AdamW 一样的 \((0.9, 0.999)\).
- Lion 学习率差不多为 AdamW 的学习率的 1/10~1/3 (既然采用的是符号梯度);
- Lion 所需要的 weight_decay 系数则要相应的乘上 3-10, 则是为了保持:\[lr * \lambda \]不变.
代码
[official-code]