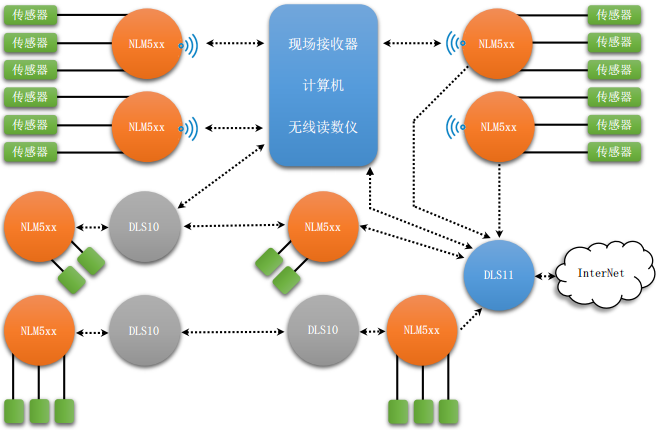
NeRF 学习笔记参考资料十分钟带你快速入门NeRF原理_哔哩哔哩_bilibili
任务概述

网络结构:

输入
1. 采样点位置

数据集是五维数据。theta phi决定了射线的方向,xyz是相机位置。
但是感觉x,y,z,theta phi为什么不直接用xyz表示?感觉剩下两个信息是冗余的。因为可能和射线有关,所以需要表示出射线的方向
实际上输入网络的数据,xyz是采样点的位置。采样点位置的计算方式是:采样点位置=相机原点+采样距离*相机观测方向(估计是通过解析几何中的向量来表达计算)
2.位置编码

如果不涉及位置编码,则图像会比较平滑,也就是像素点和像素点之间的差距不大。但是设计了Positional Encoding之后,可以看出并不是图像像素点之间高维信息变多了,更接近真实图像,
一个说的不错的位置编码的设计原因:[NeRF坑浮沉记]思考Positional Encoding - 知乎
总结一下,就是采样点位置就是三维,其秩最高就是三,经过线性变换左乘W之后r(Wx)<=3,并且激活函数引入的非线性不会让其表达能力进行大幅度提高。故需设计一个映射将输入的秩尽可能的拉高,从而让输入矩阵的表达能力更大的提高,映射为————将原始输入映射为傅里叶特征。而映射完的向量叫做Positional Encoding。(具体为啥叫这个不晓得)
但是其中的数学原理还需要深究,即傅里叶特征细节的细节。说不定可以参考的部分如下:NeRF(Neural Radiance Fields)基础知识点和研究方向 - 知乎,但是和图形学方向比较靠近,可能理论难度比较大
在工程上的体现就是经过变换之后,维度由5维扩展到了60维,并将3维的数据在concate到Position E上,这个综合之后就是输入矩阵了
MLP
由图可知,刚开始进入的是1024×63×64的数据,先把feature扩充到256,即1024 256 64。之后concate采样点的shortcut(1024 63 64)
在最后一层加入观测角度和位置编码的concate,在倒数第二层输出密度值(因为作者解释密度值和视角无关),再降维到128,再到3
最后就是(1024,4,64),也就是一张图片的1024个像素点(射线),每个像素点对应的64个采样点,每个采样点上的四个颜色维度。
输出处理
采样点的选择
像素点值的计算

之前输出的是所有采样点的RGBA数据,可以看到c图就是在射线上不同采样点的不透明度。可以看出,上图在第一个波峰的时候从视角看出了有一个面的产生。下图在第一个波峰才是视角碰到的第一个面,第二个波峰是后面那个面,是不会被显现的。
实际上通过一个相机角度看到的一个射线方向只有一个像素点,所以要对体积雾渲染进行积分(具体原理没看)
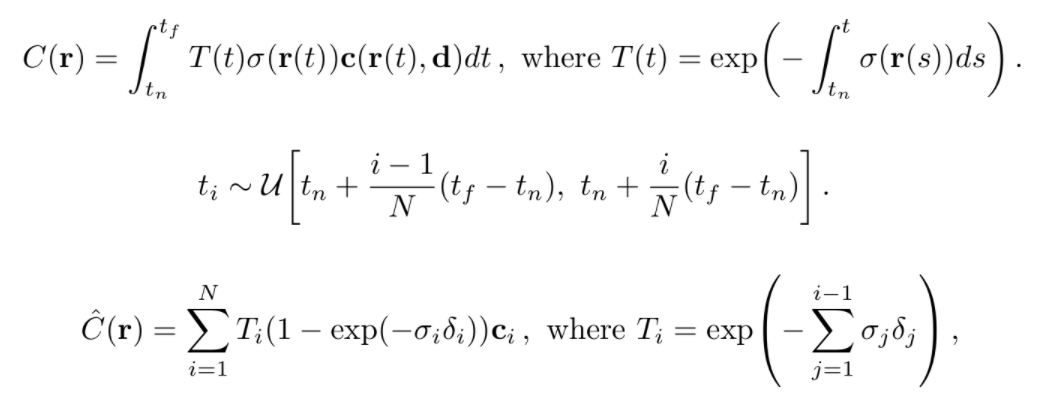
第一个公式是理论情况下的像素点的值,第二个公式位置(猜测可能是像素点的位置选取),第三个公式是实际情况下像素点的值。
\(T(t)\)是用来控制只有第一个波峰有效的小工具,即随着不透明度(的波峰)在后面的增加,他对像素点的贡献度会产生指数级下降。
\(\sigma(r(t))\)是不透明度函数,\(c(r(t),d)\)是RGB值。
积分长生的就是像素点的值,下面就是积分的近似。