算术运算符
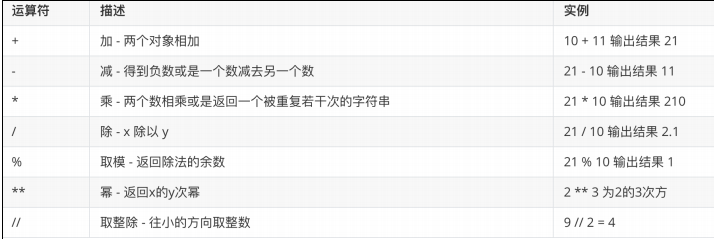
a = 3
b = 4
print(a + b) # 7
print(a - b) # -1
print(a * b) # 12
print(a / b) # 0.75
print(a % b) # 3
print(a ** b) # 81
print(a // b) # 0 整除
比较(关系)运算符
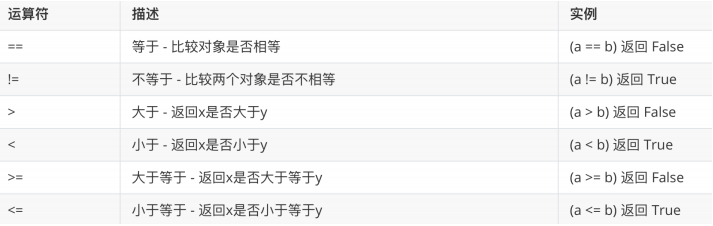
注意:
- =是赋值运算符,==是比较运算符
- 比较运算符的结果一定是bool类型的
扩展知识:比较两个非基本数据类型的变量
list1 = [11, 22, 33] list2 = [11, 22, 33] # 在python中==比较列表,元组,字典比较的是内容值 print(list1 == list2) # True# 比较两个非基本数据类型: # 方式1:使用is关键字 print(list1 is list2) # False# 方式2:使用python内置函数id() print(id(list1)) print(id(list2)) print(id(list1) == id(list2)) # False
赋值运算符

逻辑运算符

- and 且 有False则False
a = 3
b = 4
print(a > 3 and b > 4) # False and False = False
print(a == 3 and b > 4) # True and False = False
print(a > 3 and b == 4) # False and True = False
print(a == 3 and b == 4) # True and True = True
- or 或 有True则True
a = 3
b = 4
print(a > 3 or b > 4) # False or False = False
print(a == 3 or b > 4) # True or False = True
print(a > 3 or b == 4) # False or True = True
print(a == 3 or b == 4) # True or True = True
- not 将True变成False, 将False变成True
a = 3
b = 4
print(not a > b) # True
位运算符
进制
将整数分了几种进制表示法: 二进制:由0,1构成,逢2进1,以0b开头 八进制:由0,1,2,3,4,5,6,7构成,逢8进1,以0开头 十进制:由0,1,2,3,4,5,6,7,8,9构成,逢10进1,默认就是10进制 十六进制:由0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f,逢16进1,以0x开头
- 如何从其他进制转10进制
十进制转十进制 十进制:12345 十进制:12345 12345 = 10000 + 2000 + 300 + 40 + 5 = 1*10^4 + 2*10^3 + 3*10^2 + 4*10^1 + 5*10^0 = 10000 + 2000 + 300 + 40 + 5 = 12345 规律口诀:系数*进制的幂次方之和 例如: 二进制:0b10011 10011 => 1*2^4 + 0*2^3 + 0*2^2 + 1*2^1 + 1*2^0 = 16 + 2 + 1 = 19
- 如何从10进制转其他进制
除基取余,直到商为0,余数反转
十进制:108 二进制:0b1101100 108/2 = 54 ......0 54/2 = 27 ......0 27/2 = 13 ......1 13/2 = 6 ......1 6/2 = 3 ......0 3/2 = 1 ......1 1/2 = 0 ......1
如何从其他进制转其他进制
- 拆分组合法【只适合二进制转八进制或者16进制】
- 二进制转八进制 从右向左,每3位一组合,每个组合算自己的10进制结果,拼接
- 二进制转十六进制 从右向左,每4位一组合,每个组合算自己的10进制结果,拼接
二进制:0b1101100 八进制:0154100->4 101->5 001->1 二进制:0b1101100 十六进制:0x6c1100->12 0110->6先转10进制,再转其他进制
原码 反码 补码
- 在计算机所有数据的运算采用的是补码进行的
- 原码 反码 补码均都是数据的二进制的形式
原码:正数:数值位就是二进制的表现形式,最高位符号位就是0负数:数值位和正数保持一致,但是最高符号位为1 举例:3的原码:1. 3的二进制:112. 3的原码: 00000011-4的原码:1. 4的二进制:1002. -4的原码: 10000100反码:正数:和原码保持一致负数:符号位原码保持一致,数值位按位取反 举例:3的反码: 00000011-4的反码:11111011补码: 正数:和原码保持一致负数:是反码的基础之上末尾+1 举例:3的补码: 00000011-4的补码:11111100举例:-4+3 = -1 -4的补码+3的补码:00000011+ 11111100----------- 补码:11111111我们最终看到的结果是转原码再转10进制之后的结果 -1 已知补码求原码:符号位 数值位补码: 1 1111111反码: 1 1111110原码: 1 0000001 -------------------------- 数值位转10进制:1,又因为最高位是1,所以是负数,索引最终的结果是 -1

3的补码: 00000011
-4的补码:11111100a = 3
b = -4
print(a & b) # 0 有0则000000011& 11111100------------------00000000print(a | b) # -1 有1则100000011| 11111100
-----------------
补码:11111111
已知补码求原码
补码: 11111111
反码: 11111110
原码: 10000001
----------------
结果: -1print(a ^ b) # -1 相同则0,不同则100000011
& 11111100
-----------------
补码:11111111
已知补码求原码
补码: 11111111
反码: 11111110
原码: 10000001
----------------
结果: -1
print(~ b) # 3
~ 11111100
-------------0000001112的补码: 00001100
-12的补码:11110100print(12<<2) 左移,左边多的位丢弃,右边用0补齐,左移n位相当于*2^n00001100
左移2位 (00)00110000
--------------------00110000 -> 32+16 = 48
print(-12<<2) # -48print(12>>2) 右移,右边多的位丢弃,左边若最高位是0就用0补齐,若最高位是1就用1补齐,右移相当于除以2^n次方00001100右移2位 00000011(00)
---------------------------
结果:3
print(-12>>2) # -3
文件操作
常见的编码表
- ASCII码表 采用一个字节存储键盘上任意一个字符
需要记忆的符号对应的ASCII码值:
'0' - 十进制:48 - 二进制:00110000
'A' - 十进制:65 - 二进制:01000001
'a' - 十进制:97 - 二进制:01100001
- GB2312 | GBK 中国简体汉字字符表示,一个汉字字符占用2个字节
- BIG-5 大5码 用于表示中国台湾香港繁体字
- unicode 万国码,表示一个字符占用4个字节 python****默认的编码
- utf-8 是unicode编码的压缩格式,表示一个字符占用3个字节
体验编码-解码的过程
- 编码【正常->乱码】
# 编码
str1 = '今天晚上我们一起去爬大蜀山吧'
b1 = str1.encode('UTF-8')
print(b1)
- 解码【乱码->正常】
# 解码
s2 = b1.decode('UTF-8')
print(s2)
文件操作的步骤:
- 打开文件【创建与系统资源的连接】
- 操作文件【写 读】
- 关闭文件【释放|关闭系统资源的连接】
写操作open()
- 方式1:以字节的方式覆盖写数据到文件中 wb模式
f = open('test1.txt', mode='wb') # 若写数据目标文件不存在,则自动创建
# 写数据到文件中
f.write('我今天学习了很多!'.encode('UTF-8')) # 以指定编码变成字节
f.close()
路径分类:
- 相对路径:以项目作为根路径进行查找
- 绝对路径:[完整路径|带盘符的路径]
f = open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test1.txt', mode='wb') # 写数据到文件中 f.write('我今天学习了很多!'.encode('UTF-8')) f.close()
- 方式2:以字节的方式追加写数据到文件中 ab模式
f = open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test1.txt',
mode='ab')
# 写数据到文件中
f.write('我今天学习了很多!\r\n'.encode('UTF-8'))
f.close()
- 方式3:以字符的方式以指定的编码覆盖写入 w模式
f = open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test2.txt',
mode='w', encoding='UTF-8')
# 写数据到文件中
f.write('python666!\r\n')
f.close()
- 方式4:以字符的方式以指定的编码追加写入 a模式
f = open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test2.txt',
mode='a', encoding='UTF-8')
# 写数据到文件中
f.write('python666!\n')
f.close()
读取操作open()
- 方式1:以字节的形式读取文件数据
f = open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test2.txt',
mode='rb')
s1 = f.read().decode('GBK')
f.close()
print(s1)
- 方式2:以字符的形式读取文件数据
f = open('E:\\Projects\\PycharmProjects\\bigdata33\\day04\\data\\test2.txt',
mode='r', encoding='GBK')
# s1 = f.read()
res1 = f.readlines()
f.close()
# print(res1)
for i in res1:if '\n' in i:str1 = i[:-1]else:str1 = iprint(str1)print("-" * 50)
文件操作的应用场景
代码中的数据存储到文件中【用户注册】
while True:name = input("请输入您的姓名:")if name.upper() == 'Q':breakpwd = input("请输入您的密码:")email = input("请输入您的邮箱:")infos = f"{name},{pwd},{email}\n"f = open('data/users.csv',mode='a',encoding='UTF-8')f.write(infos)f.close()
f = open('data/users.csv',mode='a',encoding='UTF-8')
while True:name = input("请输入您的姓名:")if name.upper() == 'Q':breakpwd = input("请输入您的密码:")email = input("请输入您的邮箱:")infos = f"{name},{pwd},{email}\n"f.write(infos) # 这里的写实际上是往内存中写的f.flush()
f.close() # 原则上是在关闭连接之前将内存的数据刷到磁盘中
代码逻辑中的数据写到文件中
f = open('data/jj.txt','a',encoding='UTF-8')
for i in range(1, 10):for j in range(1, i + 1):f.write(f"{j}*{i}={i * j}\t")f.write('\n')f.flush()
f.close()
将网格中的资源写到文件中【爬虫】
json
本质上是一个大的字符串,里面的格式类似于python中的字典,字符串是由双引号括起来的。
可以将这样的一个大字符串转成json的格式。
import requests
import jsonurl = 'https://car-web-api.autohome.com.cn/car/price/getrecommendseries?
appid=8a1aebddbaab9cd59eec077d7563bca0&cityid=340100&type=pccookie&id=E7CA393F-
8482-4658-84A8-8152D7798995'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
response = requests.get(url=url, headers=headers)
text = response.content.decode('UTF-8')
text = text.replace(' ', '').replace('\n', '').replace('\r\n', '')
j = json.loads(text)car_list = j['result']['serieslist']f = open('data/cars.csv', mode='a', encoding='UTF-8')
f.write(f"品牌,车型,运作方式,最低售价,最高售价\n")
f.flush()for car in car_list:seriesname = car['seriesname']levelname = car['levelname']fueltypedetailname = car['fueltypedetailname']minprice = car['minprice']maxprice = car['maxprice']infos = f"{seriesname},{levelname},{fueltypedetailname},{minprice},{maxprice}\n"f.write(infos)f.flush()
f.close()
打开文件的另一种方式
# 第一种
f = open('data/cars.csv', mode='r', encoding='UTF-8')
text = f.read()
print(text)
f.close()#第二种
text = ''
with open('data/cars.csv', mode='r', encoding='UTF-8') as f:text = f.read()
# text = f.read() # f出了with就会被close掉
print(text)