文章目录
- 一、Conditional DETR 是怎么被提出来的
- 二、Conditional DETR 的具体实现
- 2.1 框架结构
- 2.2 DETR 的 cross-attention 和 Conditional DETR 的 cross-attention 对比
- 三、效果
论文:Conditional DETR for Fast Training Convergence
代码:https://github.com/Atten4Vis/ConditionalDETR
出处:ICCV2021
一、Conditional DETR 是怎么被提出来的
DETR 方法自被提出以来,就以其端到端的结构得到了很大的关注,DETR 方法首次将 Transformer 结构引入了目标检测任务中,且使用二分匹配的方式让一个目标只有一个输出框,免去了 NMS 的操作,使用 object queries 的方式免去了手工设置 anchor 的过程。
但是 DETR 的缺点也很明显:
- 收敛速度慢:需要 500 个 epoch 才能收敛(是 Faster RCNN 的 10~20 倍)
- 对小目标效果不好:DETR 使用的是 CNN 抽取的最后一层特征(1/32),分辨率较低,细节信息缺失严重,所以小目标检出效果较差
DETR 的基本流程:
- CNN backbone 提取图像的 feature
- Transformer Encoder 通过 self-attention 建模全局关系对 feature 进行增强
- Transformer Decoder 的输入是 object queries 和 Transformer encoder 的输出,主要包含 self-attention 和 cross-attention 的过程。Cross- attention 主要是将 object query 当做查询,encoder feature 当做 key,为了查询和 query 有关的区域。Self-attention 主要是对每个 query 做交互,让每个 query 能看到其他 query 在查询什么东西,从而不重复,类似与 NMS 的作用
- 对 Decoder 输出的查询好了的 query,使用 FFN 提取出 bbox 的位置和类别信息
针对 DETR 的收敛慢的问题,Conditional DETR 对 DETR 的结构进行了进一步的探索,从 DETR 的 decoder 入手,回顾一下 DETR 中提到的 decoder 的主要作用是关注目标的边界位置(extremity),如下图所示,包括边界位置的大象鼻子、大象蹄子、斑马蹄子等,都是对边界定位很重要的边界信息。

然后我们再看看 DETR 不同训练 epoch 的模型对边界位置的定位能力,如图 1 所示,在 DETR 训练 50 个 epoch 时(第二行),从空间 attention 图中可以明显的看出来模型并不能很好的找到目标的边界,在训练到 500 个 epoch 的时候(第三行),模型就能很好的找到目标的边界位置的。这里的每个列表示不同 head 的输出。

为什么会出现这样的问题呢,作者就进行了 DETR 结构的重新思考,并且提出了对之后的多篇工作影响很大的 content query/key 和 spatial query/key 的概念
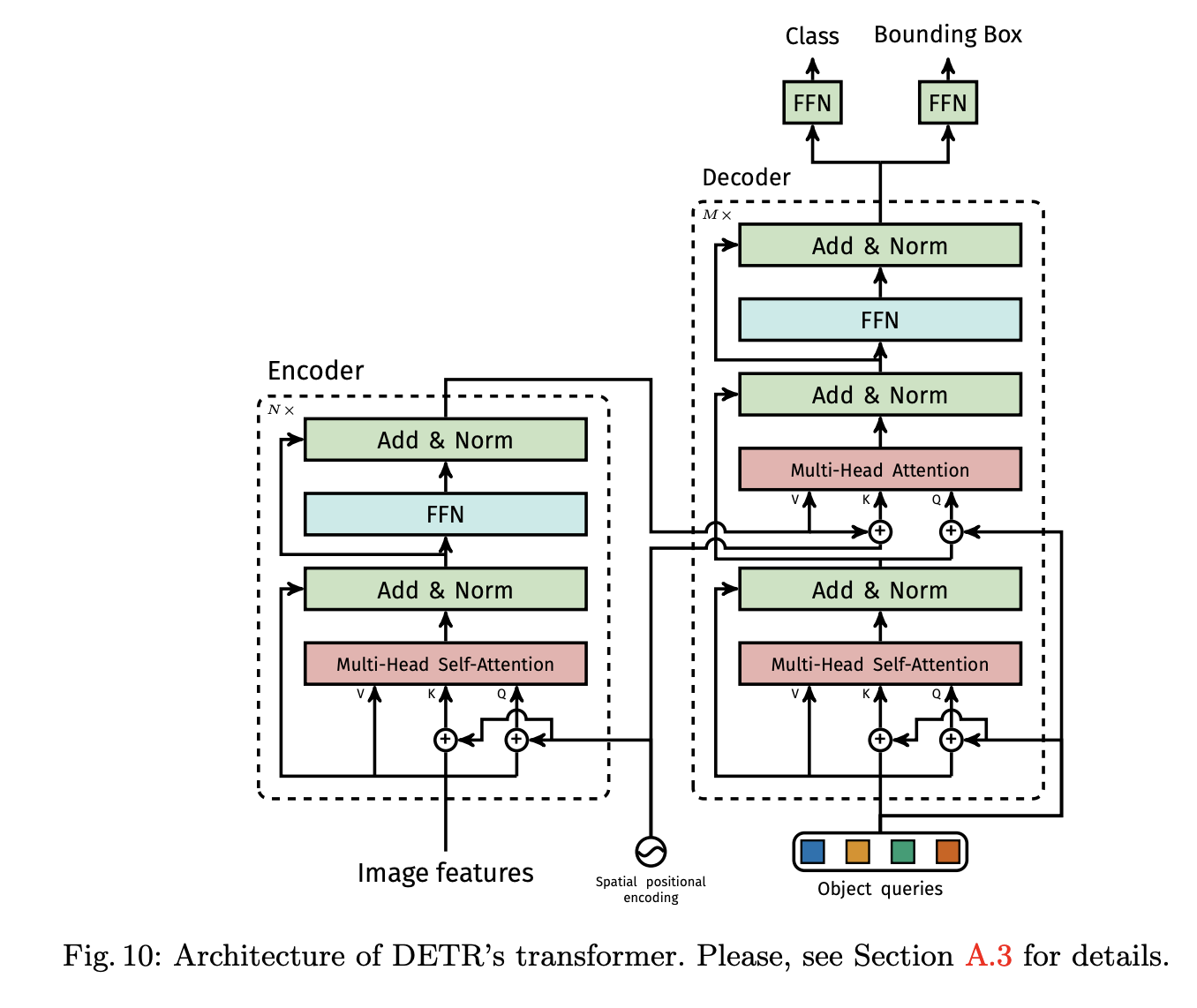
在 DETR 中,DETR decoder 的 cross-attention 如下图所示(图来自 DETR 原文,cross-attention 是右边分支中间位置的模块),是对 encoder 的输出和 object query 做交叉注意力的模块,会有三个输入:
- queries:每个 query 都是 decoder 第一层 self-attention 的输出( content query )+ object query( spatial query ),这里的 object query 就是 DETR 中提出的概念,每个 object query 都是候选框的信息,经过 FFN 后能输出位置和类别信息(本文 object query 个数 N 为 300)
- keys:每个 key 都是 encoder 的输出特征( content key ) + 位置编码( spatial key )构成的,可以看 k 的下边是有一个 + 号的
- values:只有来自 encoder 的输出
基于上面提到的 content 和 spatial 的概念,我们就可以继续往下看了,作者本文的动机来源于这么一个结论:
- 在 cross-attention 中,content embedding 贡献很大,spatial embedding 贡献很小
- 假设移除 key 中的 positional embedding 和第二层的 object query(但是第一层的 object query 是一定不能移除的哦!!!),AP 只会下降很小的值
影响究竟有多小呢:
- 训练 50 个 epoch 的时候,不使用 spatial embedding 的话,AP 从 34.9 降到了 34.0
- 训练 300 个 epoch 的时候,不使用 spatial embedding 的话,AP 下降 1.4
所以 DETR 是把 content key/query 和 spatial key/query 合在一起训练的,既然 spatial 影响不大,那就说明 content 的影响很大,需要要求 content 质量很高,才能得到较好的效果,当 content 质量不高的时候,spatial 再挣扎也没用。所以说,DETR 收敛慢的原因很大程度上是来源于 content 的质量太低了,且难以提升,所以 DETR 需要更大的训练 epoch 才能得到较好的效果,也进一步说明边界位置的定位能力其实来源于 content 特征,要想更快的提升模型对边界位置的定位能力,要能更快的让 content 特征优化得当才行。
说到这里,Conditional DETR 就提出了自己的方法,主要解决的就是 decoder 中的 cross-attention 的 content 难以学习的问题,Conditional DETR 从前一个 decoder 的输出为每个 query 都学习一个 conditional spatial embedding,来为 decoder 的 cross-attention 形成一个所谓的 【 conditional spatial query】。
二、Conditional DETR 的具体实现
2.1 框架结构
Conditional DETR 的方法沿用了 DETR 的整体流程,包括 CNN backbone,transformer encoder,transformer decoder, 以及 object class 和 box 位置的预测器。Encoder 和 Decoder 各自由6个相同的 layer 堆叠而成。Conditional DETR 相对于 DETR 的改动主要在 decoder 的 cross-attention 部分。
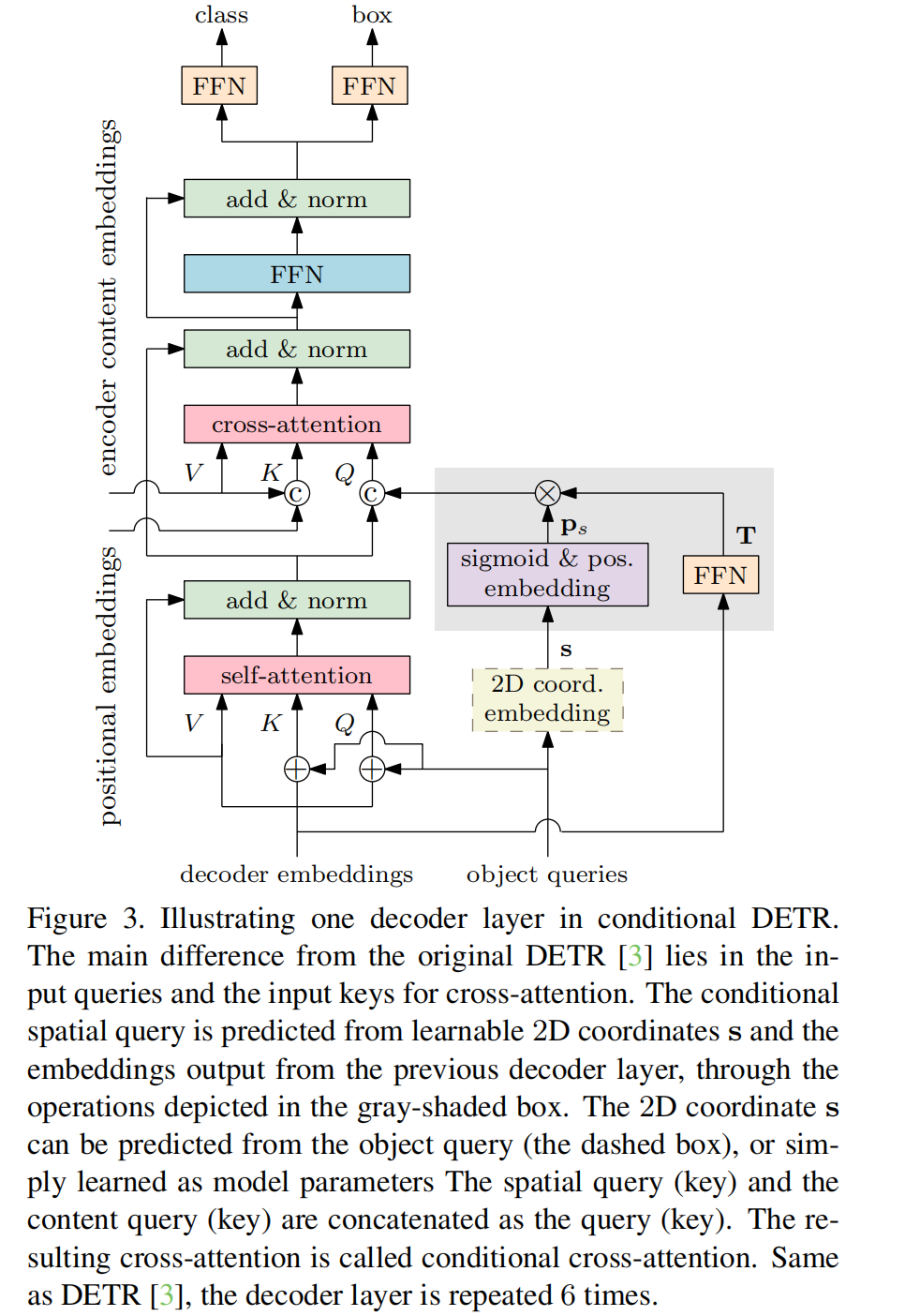
改动后的 decoder 的一层如图 3 所示,有三层:
- 第一层: 输入为上一层 decoder 的输出,self-attention 过程用于去除冗余的预测,self-attention 就是来求 object query embedding 之间的关系,在每个特征都互相交流之后,就能知道每个 query 在预测什么样的特征,从而避免预测的特征冗余了,尽量都预测不一样的特征才好。
- 第二层:cross-attention 层,用于聚合 encoder 的输出和 decoder 内部的特征,进一步加强特征
- 第三层:FFN 层
Box 位置的回归:
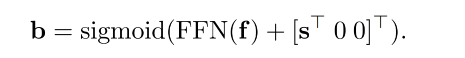
- f 是 decoder embedding
- b 是 4d 向量 [x, y, w, h]
- sigmoid 用于将输出归一化为 [0,1]
- s 是参考点的未经归一化的 2D 坐标,在 DETR 中是 (0,0)
类别 预测:
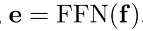
conditional DETR 的 cross-attention 主要的作用:
- 定位目标区域,也就是定位 bbox 的 4 个边界位置来定位,识别框内的目标区域用于分类
- 通过引入 conditional spatial queries ,能够提升定位能力,且加速训练过程
2.2 DETR 的 cross-attention 和 Conditional DETR 的 cross-attention 对比
1、DETR
在 DETR 中,DETR decoder 的 cross-attention 如下图所示(图来自 DETR 原文,cross-attention 是右边分支中间位置的模块),是对 encoder 的输出和 object query 做交叉注意力的模块,会有三个输入:
- queries:每个 query 都是 decoder 第一层 self-attention 的输出( content query c q c_q cq)+ object query( spatial query p q p_q pq ),这里的 object query 就是 DETR 中提出的概念,每个 object query 都是候选框的信息,经过 FFN 后能输出位置和类别信息(本文 object query o q o_q oq个数 N 为 300)
- keys:每个 key 都是 encoder 的输出特征( content key c k c_k ck ) + 位置编码( spatial key p k p_k pk)构成的,可以看 k 的下边是有一个 + 号的
- values:只有来自 encoder 的输出
因为所有的 spatial 的 content query/key 都是加在一起的,所以 attention 时候操作过程如下:
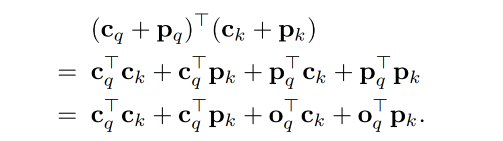
2、Conditional DETR
conditional cross-attention 方法将 content 和 spatial 分开了,使用如下的方式进行,让 spatial query 聚焦于 spatial attention,content query 聚焦于 content attention
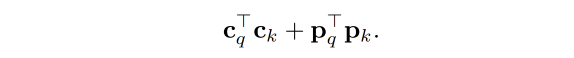
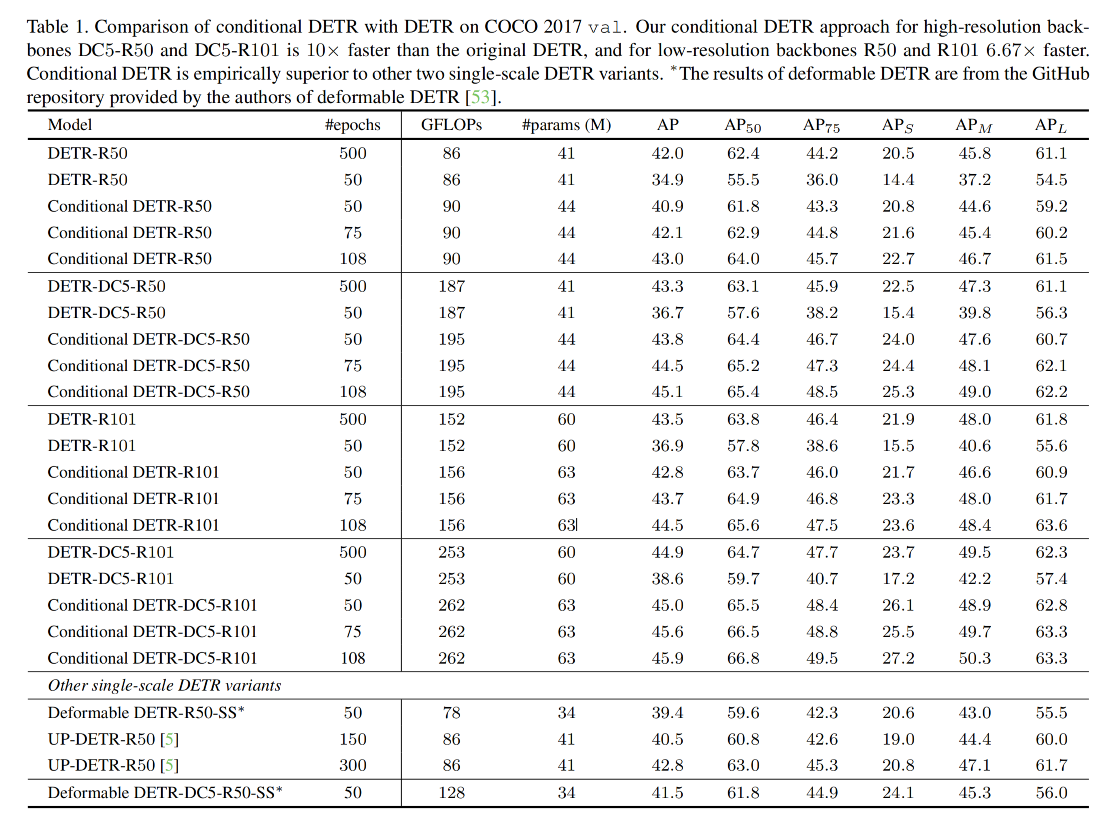
三、效果