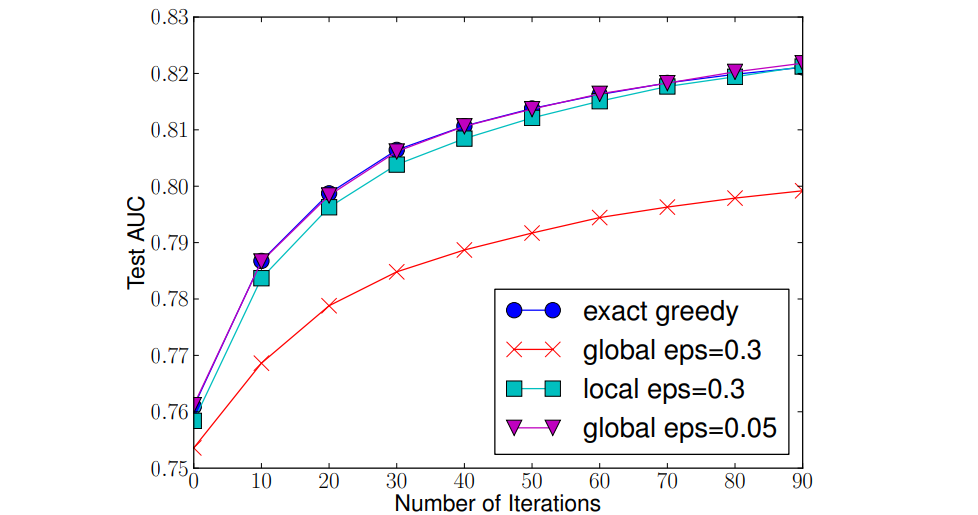
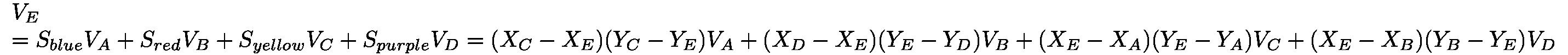import pandas as pd
import scipy.stats as stats
data = pd.read_excel('9.2.xlsx')
data_values = data.values.flatten().tolist()
statistic, p_value = stats.shapiro(data_values)
print("Shapiro-Wilk 统计量:", statistic)
print("p 值:", p_value)
if p_value > 0.05:
print("滚珠直径服从正态分布 N(15.0780, 0.4325^2)")
else:
print("滚珠直径不服从正态分布 N(15.0780, 0.4325^2)")