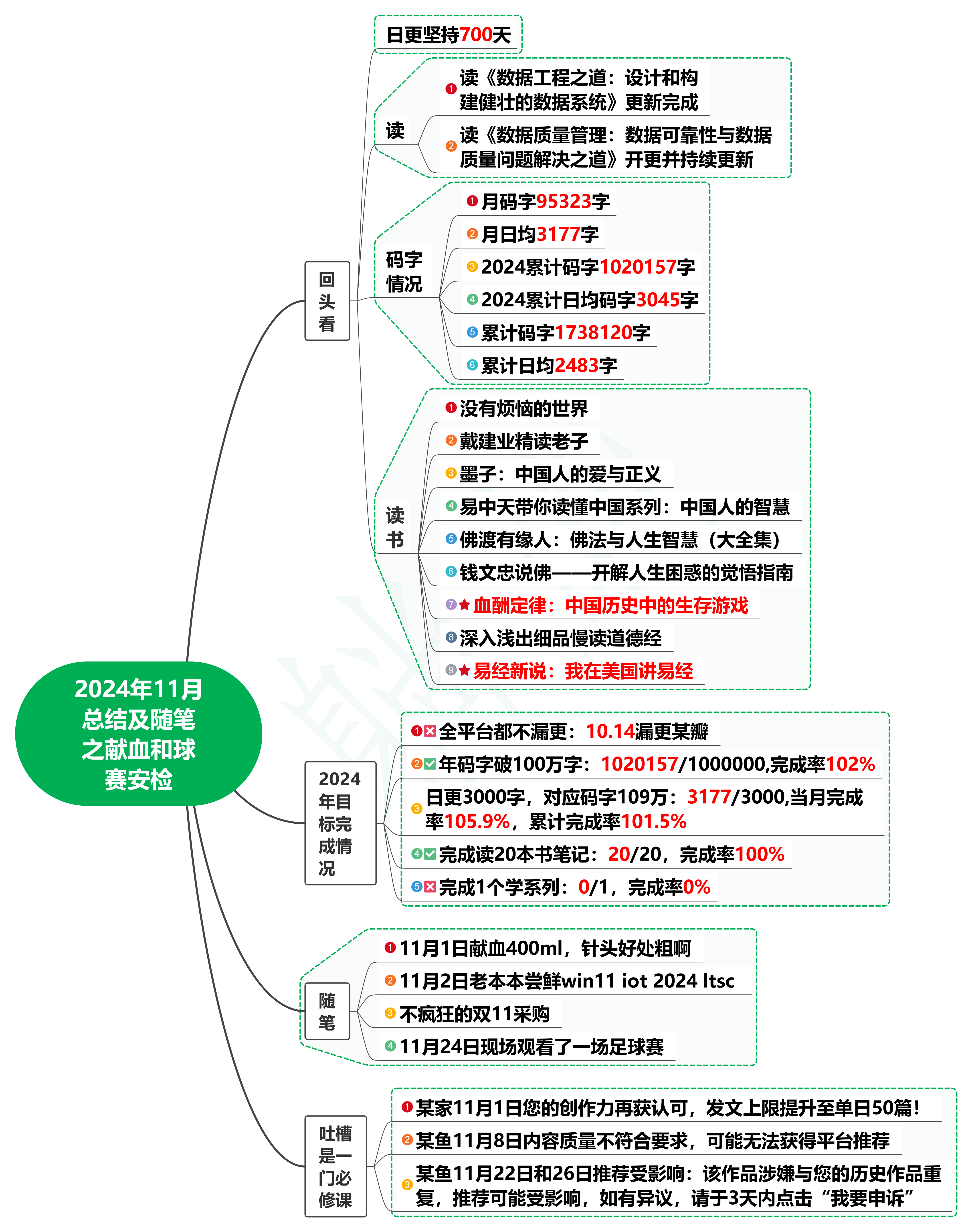
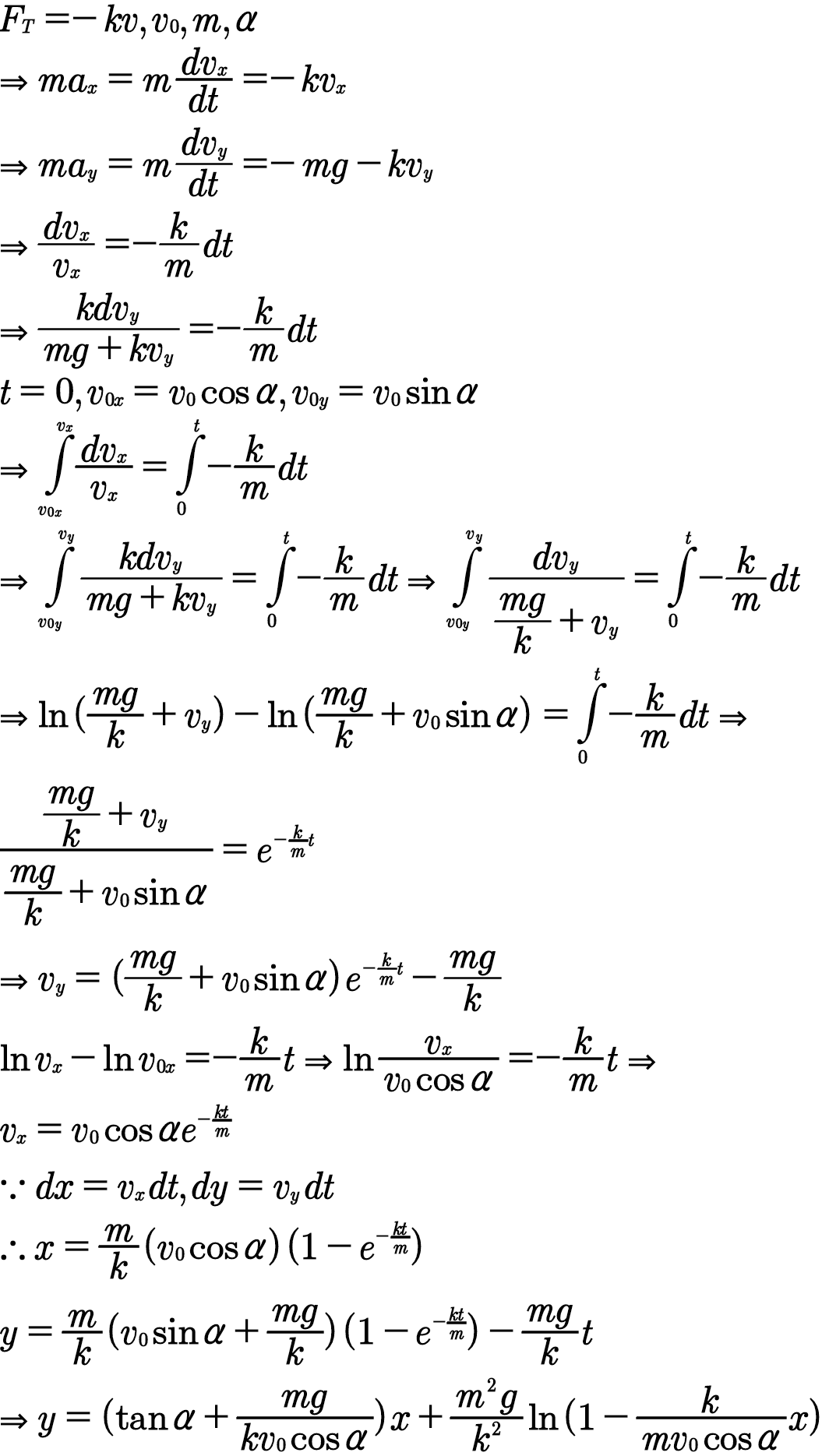在前端开发中,getElementById 和 querySelector 都是用于选择 HTML 元素的常用方法,但它们各有优缺点,适用场景略有不同。我通常会根据具体情况选择更合适的方法:
getElementById:
-
优点:
- 速度最快: 因为它直接通过 ID 查找,浏览器可以进行优化,使其速度非常快。
- 代码简洁: 语法简单,易于使用。
-
缺点:
- ID 必须唯一: HTML 规范要求 ID 在整个文档中必须是唯一的。如果出现重复 ID,
getElementById通常只会返回第一个匹配的元素,这可能导致错误。 - 不够灵活: 只能通过 ID 选择元素,无法进行更复杂的筛选。
- ID 必须唯一: HTML 规范要求 ID 在整个文档中必须是唯一的。如果出现重复 ID,
querySelector:
-
优点:
- 非常灵活: 可以使用 CSS 选择器语法选择元素,支持各种复杂的筛选条件,例如类名、标签名、属性、伪类等等。
- 可以返回多个元素:
querySelectorAll可以返回所有匹配的元素,形成一个 NodeList。
-
缺点:
- 速度相对较慢: 相比
getElementById,querySelector需要解析 CSS 选择器,速度会略慢一些,尤其是在大型文档中。 - 代码略复杂: 需要编写 CSS 选择器,对于不熟悉 CSS 的开发者来说可能需要一些学习成本。
- 速度相对较慢: 相比
我的选择倾向和建议:
-
如果需要选择单个,且 ID 已知的元素,优先使用
getElementById。 因为它速度最快,代码也最简洁。这是最常见的场景,例如获取表单元素、操作特定的弹窗等。 -
如果需要根据类名、标签名、属性等条件选择元素,或者需要选择多个元素,则使用
querySelector或querySelectorAll。 例如,根据类名修改样式、根据属性筛选元素等。 -
避免滥用 ID: 虽然
getElementById速度很快,但过度依赖 ID 会降低代码的可维护性和复用性。建议合理使用类名和语义化的标签,并结合querySelector进行更灵活的选择。 -
性能优化: 在处理大量元素或频繁操作 DOM 时,
querySelector的性能可能会成为瓶颈。在这种情况下,可以考虑缓存查询结果,或者使用更高效的 DOM 操作库。
总而言之,getElementById 和 querySelector 都是非常有用的工具,选择哪个取决于具体的场景和需求。理解它们的优缺点,并根据实际情况选择合适的方法,才能写出更高效、更易维护的前端代码。