lab 3: 进程与线程
前言:timeout情况不再赘述。
有没有感到编译时间已经长到难以忍受?是的,作者在第一次编译的时候甚至深受编译的困扰(长达10分钟!)评分的时候,大家也想要很快地看到绿色的100分,因此,作者提供一个歪招给大家参考(慎用!)
在Scripts/kernel.mk中的grade处,注释掉make distclean。
慎用!慎用!
实验报告仅供个人参考,不对正确性负责!
Contents
用户进程是操作系统对在用户模式运行中的程序的抽象。在Lab 1 和Lab 2 中,已经完成了内核的启动和物理内存的管理,以及一个可供用户进程使用的页表实现。现在,我们将一步一步支持用户态程序的运行。 本实验包括五个部分:
- 代码导读,了解Chcore微内核的核心机制以及用户态和内核态是如何进行交互的。
- 线程管理: 支持创建第一个用户态进程和线程,分析代码如何从内核态切换到用户态。
- 异常处理: 完善异常处理流程,为系统添加必要的异常处理的支持。
- 系统调用:正确处理部分系统调用,保证用户程序的正常输出。
- 用户态程序编写:编写一个简单用户程序,使用提供的 ChCore libc 进行编译,并加载至内核镜像中。
3.1 代码导读
首先我们需要结合lab2中的main函数来了解内核初始化的过程。本次代码导读主要聚焦从main函数开始自上而下讲解Lab2 Lab3内核态的资源管理机制以及用户态和内核态的互相调用。
内核初始化
/** @boot_flag is boot flag addresses for smp;* @info is now only used as board_revision for rpi4.*/
void main(paddr_t boot_flag, void *info)
{u32 ret = 0;/* Init big kernel lock */ret = lock_init(&big_kernel_lock);kinfo("[ChCore] lock init finished\n");BUG_ON(ret != 0);/* Init uart: no need to init the uart again */uart_init();kinfo("[ChCore] uart init finished\n");/* Init per_cpu info */init_per_cpu_info(0);kinfo("[ChCore] per-CPU info init finished\n");/* Init mm */mm_init(info);kinfo("[ChCore] mm init finished\n");void lab2_test_buddy(void);lab2_test_buddy();void lab2_test_kmalloc(void);lab2_test_kmalloc();void lab2_test_page_table(void);lab2_test_page_table();
#if defined(CHCORE_KERNEL_PM_USAGE_TEST)void lab2_test_pm_usage(void);lab2_test_pm_usage();
#endif/* Mapping KSTACK into kernel page table. */map_range_in_pgtbl_kernel((void*)((unsigned long)boot_ttbr1_l0 + KBASE), KSTACKx_ADDR(0),(unsigned long)(cpu_stacks[0]) - KBASE, CPU_STACK_SIZE, VMR_READ | VMR_WRITE);/* Init exception vector */arch_interrupt_init();timer_init();kinfo("[ChCore] interrupt init finished\n");/* Enable PMU by setting PMCR_EL0 register */pmu_init();kinfo("[ChCore] pmu init finished\n");/* Init scheduler with specified policy */
#if defined(CHCORE_KERNEL_SCHED_PBFIFO)sched_init(&pbfifo);
#elif defined(CHCORE_KERNEL_RT)sched_init(&pbrr);
#elsesched_init(&rr);
#endifkinfo("[ChCore] sched init finished\n");init_fpu_owner_locks();/* Other cores are busy looping on the boot_flag, wake up those cores */enable_smp_cores(boot_flag);kinfo("[ChCore] boot multicore finished\n");#ifdef CHCORE_KERNEL_TESTkinfo("[ChCore] kernel tests start\n");run_test();kinfo("[ChCore] kernel tests done\n");
#endif /* CHCORE_KERNEL_TEST */#if FPU_SAVING_MODE == LAZY_FPU_MODEdisable_fpu_usage();
#endif/* Create initial thread here, which use the `init.bin` */create_root_thread();kinfo("[ChCore] create initial thread done\n");kinfo("End of Kernel Checkpoints: %s\n", serial_number);/* Leave the scheduler to do its job */sched();/* Context switch to the picked thread */eret_to_thread(switch_context());
}
以下为Chcore内核初始化到运行第一个用户线程的主要流程图
我们在Lab2中主要完成mm_init以及内存管理器与vmspace和pmo的互联,现在我们再从第一个线程创建的数据流来梳理并分析
Chcore微内核的资源管理模式。
内核对象管理
在Chcore中所有的系统资源都叫做object(对象),用面向对象的方法进行理解的话,object即为不同内核对象例如vmspace, pmo, thread(等等)的父类,
Chcore通过能力组机制管理所有的系统资源,能力组本身只是一个包含指向object的指针的数组
- 所有进程/线程都有一个独立的能力组,拥有一个全局唯一ID (Badge)
- 所有对象(包括进程或能力组本身)都属于一个或多个能力组当中,也就是说子进程与线程将属于父进程的能力组当中,在某个能力组的对象拥有一个能力组内的能力ID(cap)。
- 对象可以共享,即单个对象可以在多个能力组中共存,同时在不同cap_group中可以有不同的cap
- 对所有对象的取用和返还都使用引用计数进行追踪。当引用计数为0后,当内核垃圾回收器唤醒后,会自动回收.
- 能力组内的能力具有权限,表明该能力是否能被共享(CAP_RIGHT_COPY)以及是否能被删除(CAP_RIGHT_REVOKE)
struct object {u64 type;u64 size;/* Link all slots point to this object */struct list_head copies_head;/* Currently only protect copies list */struct lock copies_lock;/** refcount is added when a slot points to it and when get_object is* called. Object is freed when it reaches 0.*/volatile unsigned long refcount;/** opaque marks the end of this struct and the real object will be* stored here. Now its address will be 8-byte aligned.*/u64 opaque[];
};
const obj_deinit_func obj_deinit_tbl[TYPE_NR] = {[0 ... TYPE_NR - 1] = NULL,[TYPE_CAP_GROUP] = cap_group_deinit,[TYPE_THREAD] = thread_deinit,[TYPE_CONNECTION] = connection_deinit,[TYPE_NOTIFICATION] = notification_deinit,[TYPE_IRQ] = irq_deinit,[TYPE_PMO] = pmo_deinit,[TYPE_VMSPACE] = vmspace_deinit,
#ifdef CHCORE_OPENTRUSTEE[TYPE_CHANNEL] = channel_deinit,[TYPE_MSG_HDL] = msg_hdl_deinit,
#endif /* CHCORE_OPENTRUSTEE */[TYPE_PTRACE] = ptrace_deinit
};
void *obj_alloc(u64 type, u64 size)
{u64 total_size;struct object *object;total_size = sizeof(*object) + size;object = kzalloc(total_size);if (!object)return NULL;object->type = type;object->size = size;object->refcount = 0;/** If the cap of the object is copied, then the copied cap (slot) is* stored in such a list.*/init_list_head(&object->copies_head);lock_init(&object->copies_lock);return object->opaque;
}
void __free_object(struct object *object)
{
#ifndef TEST_OBJECTobj_deinit_func func;if (object->type == TYPE_THREAD)clear_fpu_owner(object);/* Invoke the object-specific free routine */func = obj_deinit_tbl[object->type];if (func)func(object->opaque);
#endifBUG_ON(!list_empty(&object->copies_head));kfree(object);
}
所有的对象都有一个公共基类,并定义了虚构函数列表,当引用计数归零即完全被能力组移除后内核会执行deinit代码完成销毁工作。
根据上面的描述,梳理根进程创建以及普通进程创建的异同,梳理出创建进程的方式。
相同点:
- 首先,我们需要为从用户态的进程分配一个能力组,提供给一个全局的id。那么就需要分配一个object,将这个类型选择为
cap_group. - 初始化我们的cap_group,创建PCB。
- 需要注意的是,所有的进程相关信息都通过object来进行抽象。因此vmspace也是通过分配object分配而来的。
- 创建进程的线程。在线程内,为线程分配内存对象PMO和初始执行环境,分配虚拟地址空间,处理器上下文,内核栈。
不同点:
- 创建根进程的全局id和能力(capability)和其他进程的相对应id和能力不同。
- 根进程所具有的虚拟地址与普通进程不相同。
用户态构建
我们在Lab1的代码导读阶段说明了kernel目录下的代码是如何被链接成内核镜像的,我们在内核镜像链接中引入了procmgr这个预先构建的二进制文件。在Lab3中,我们引入了用户态的代码构建,所以我们将procmgr的依赖改为使用用户态的代码生成。下图为具体的构建规则图。
procmgr是一个自包含的ELF程序,其代码在procmgr中列出,其主要包含一个ELF执行器以及作为Chcore微内核的init程序启动,其构建主要依赖于fsm.srv以及tmpfs.srv,其中fsm.srv为文件系统管理器其扮演的是虚拟文件系统的角色用于桥接不同挂载点上的文件系统的实现,而tmpfs.srv则是Chcore的根文件系统其由ramdisk下面的所有文件以及构建好libc.so所打包好的ramdisk.cpio构成。当构建完tmpfs.srv后其会跟libc.so进行动态链接,最终tmpfs.srv以及fsm.srv会以incbin脚本的形式以二进制的方式被连接至procmgr的最后。在构建procmgr的最后一步,cmake会调用read_procmgr_elf_tool将procmgr这个ELF文件的缩略信息粘贴至procmgr之前。此后procmgr也会以二进制的方式进一步嵌套进入内核镜像之后,最终会在create_root_thread的阶段通过其elf符号得以加载。 最终,Chcore的Kernel镜像的拓扑结构如下
3.2 线程管理
权利组创建(我觉得应该是权力组)
在AArch64体系结构中,我们拥有从低到高4个异常级别EL0,EL1,EL2,EL3.在Chcore中采用两个特权级别,EL0,EL1。后者为内核模式。
在/kernel目录下的代码运行于内核级别,也就是EL1。在/user目录下的代码运行于用户态,也就是EL0。我们在ChCore中的第一个进程为procmgr,也接受cap_group和capability的管理。在创建该进程后,再进行内核态向用户态的切换。
创建用户程序至少需要包括创建对应的 cap_group、加载用户程序镜像并且切换到程序。在内核完成必要的初始化之后,内核将会跳转到创建第一个用户程序的操作中,该操作通过调用 create_root_thread 函数完成,本函数完成第一个用户进程的创建,其中的操作包括从procmgr镜像中读取程序信息,调用create_root_cap_group创建第一个 cap_group 进程,并在 root_cap_group 中创建第一个线程,线程加载着信息中记录的 elf程序(实际上就是procmgr系统服务)。此外,用户程序也可以通过 sys_create_cap_group 系统调用创建一个全新的 cap_group.
练习题1:
在kernel/object/cap_group.c中完善sys_create_cap_group、create_root_cap_group函数。在完成填写之后,你可以通过 Cap create pretest 测试点。
Hint
阅读kernel/object/capability.c中的各个与cap机制相关的函数以及相关参考文档。
我们首先先看一下我们的能力组和对象的相关结构。
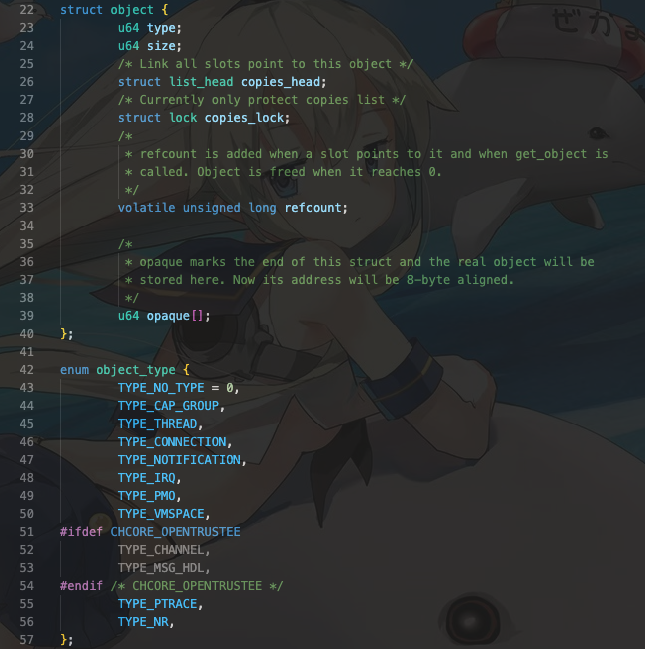
我们可以看见,object(对象)可以看作是一切系统资源的基类,其中在object_type中有着其派生出来的类别,包括能力组,线程,连接,提示,中断请求(irq),物理内存对象(pmo),虚拟地址空间等。object对象中,type指明了该对象的类型,size是大小,copies_head提供了从链表中获取该资源的方式(可以说是后门hhh),copies_lock是锁结构,用于保证多线程访问和共享安全。refcount可以用于垃圾回收装置(gc),而真正的内容存储在64位的opaque内存中。
接下来我们来看cap_group的相关定义。
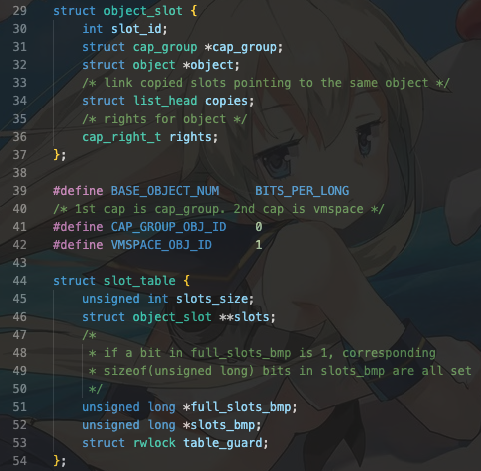
首先是有关object的链表结构的定义,这里定义了能力组指向的链表,以及链表的每个槽slot指向的object。object_slot内储存着slot的id,所属于的能力组,所含有的object,索引方式copies,以及对象所拥有的权力(不是“利”)。在kernel/user-include/uapi/types.h中的注释中我们可以发现:该权力分为两类,一种是对象独有的权力,一种是普遍的权力。这会在后面有所体现。
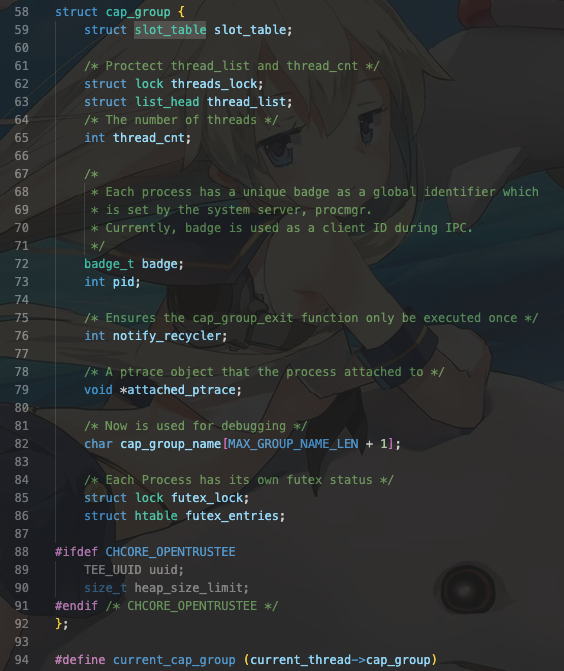
接下来就是有关能力组的定义。如上图所示,首先,能力组包含了slot_table. 其次,thread_cnt记录了该能力组所拥有的线程的数目。badge是全局的id,由procmgr设置,也可以视为内核态的id。pid则是用户态中该进程的id。
我们接着来理清我们创建进程所需要的过程:
- 首先,我们需要为进程分配一个能力组,并且为该能力组提供给一个全局的id。那么就需要分配一个object(所有进程,线程和能力组都是对象的派生),将这个类型选择为
cap_group. - 调用初始化函数,将object初始化我们的cap_group。
- 为我们的进程,也就是这个能力组分配虚拟空间。
- 创建线程。一个进程至少有一个以上的线程,相关的上下文信息和PMO通过线程进行管理。
参考我们的capability.c,具体的部分可以参见注释。
cap_t sys_create_cap_group(unsigned long cap_group_args_p)
{struct cap_group *new_cap_group;struct vmspace *vmspace;cap_t cap;int r;struct cap_group_args args = {0};r = hook_sys_create_cap_group(cap_group_args_p);if (r != 0)return r;if (check_user_addr_range((vaddr_t)cap_group_args_p,sizeof(struct cap_group_args))!= 0)return -EINVAL;r = copy_from_user(&args, (void *)cap_group_args_p, sizeof(struct cap_group_args));if (r) {return -EINVAL;}/* cap current cap_group *//* LAB 3 TODO BEGIN *//* Allocate a new cap_group object *//** 为我们的能力组分配对应类型的对象。* 我们的函数在capability.c: * void *obj_alloc(u64 type, u64 size)*/new_cap_group = obj_alloc(TYPE_CAP_GROUP, sizeof(*new_cap_group));/* LAB 3 TODO END */if (!new_cap_group) {r = -ENOMEM;goto out_fail;}/* LAB 3 TODO BEGIN *//* initialize cap group from user*/// 初始化我们的能力组。为进程分配用户态id。// 函数原型:注意最后一个需要传入引用。// __maybe_unused static int cap_group_init_user(struct cap_group *cap_group, unsigned int size, struct cap_group_args *args)cap_group_init_user(new_cap_group, BASE_OBJECT_NUM, &args);new_cap_group->pid = args.pid;/* LAB 3 TODO END */// 在能力组内分配槽位。如果没有足够的槽位则前往新的能力组。cap = cap_alloc(current_cap_group, new_cap_group);if (cap < 0) {r = cap;goto out_free_obj_new_grp;}/* 1st cap is cap_group */// 分配自身能力capability,放入槽表中的第一个槽。if (cap_copy(current_thread->cap_group,new_cap_group,cap,CAP_RIGHT_NO_RIGHTS,CAP_RIGHT_NO_RIGHTS)!= CAP_GROUP_OBJ_ID) {kwarn("%s: cap_copy fails or cap[0] is not cap_group\n",__func__);r = -ECAPBILITY;goto out_free_cap_grp_current;}/* 2st cap is vmspace *//* LAB 3 TODO BEGIN */// 分配虚拟空间并且放入能力组的槽表的第二个槽。vmspace = obj_alloc(TYPE_VMSPACE, sizeof(*vmspace));/* LAB 3 TODO END */if (!vmspace) {r = -ENOMEM;goto out_free_obj_vmspace;}vmspace_init(vmspace, args.pcid);r = cap_alloc(new_cap_group, vmspace);if (r != VMSPACE_OBJ_ID) {kwarn("%s: cap_copy fails or cap[1] is not vmspace\n",__func__);r = -ECAPBILITY;goto out_free_obj_vmspace;}return cap;
out_free_obj_vmspace:obj_free(vmspace);
out_free_cap_grp_current:cap_free(current_cap_group, cap);new_cap_group = NULL;
out_free_obj_new_grp:obj_free(new_cap_group);
out_fail:return r;
}/* This is for creating the first (init) user process. */
// procmgr的创建,和上面大同小异。有不同的地方将会注释标出。
struct cap_group *create_root_cap_group(char *name, size_t name_len)
{struct cap_group *cap_group = NULL;struct vmspace *vmspace = NULL;cap_t slot_id;/* LAB 3 TODO BEGIN */// UNUSED(vmspace);// UNUSED(cap_group);// 分配能力组对象。cap_group = obj_alloc(TYPE_CAP_GROUP, sizeof(*cap_group));/* LAB 3 TODO END */BUG_ON(!cap_group);/* LAB 3 TODO BEGIN *//* initialize cap group with common, use ROOT_CAP_GROUP_BADGE */// 按照注释调用common初始化能力组。cap_group_init_common(cap_group, BASE_OBJECT_NUM, ROOT_CAP_GROUP_BADGE);/* LAB 3 TODO END */slot_id = cap_alloc(cap_group, cap_group);BUG_ON(slot_id != CAP_GROUP_OBJ_ID);/* LAB 3 TODO BEGIN */// 分配虚拟地址空间vmspace = obj_alloc(TYPE_VMSPACE, sizeof(*vmspace));/* LAB 3 TODO END */BUG_ON(!vmspace);/* fixed PCID 1 for root process, PCID 0 is not used. */vmspace_init(vmspace, ROOT_PROCESS_PCID);/* LAB 3 TODO BEGIN */// 为自身分配槽id。对照上一个函数的写法并且适配下面的assert。slot_id = cap_alloc(cap_group, vmspace);/* LAB 3 TODO END */BUG_ON(slot_id != VMSPACE_OBJ_ID);/* Set the cap_group_name (process_name) for easing debugging */memset(cap_group->cap_group_name, 0, MAX_GROUP_NAME_LEN + 1);if (name_len > MAX_GROUP_NAME_LEN)name_len = MAX_GROUP_NAME_LEN;memcpy(cap_group->cap_group_name, name, name_len);root_cap_group = cap_group;return cap_group;
}
附录:不想阅读这部分的可以跳过。我们将会结合
capability.c来梳理整个流程。创建一个进程后,用户态下陷到内核态,接下来就会在内核态创建该进程的PCB内核态部分。
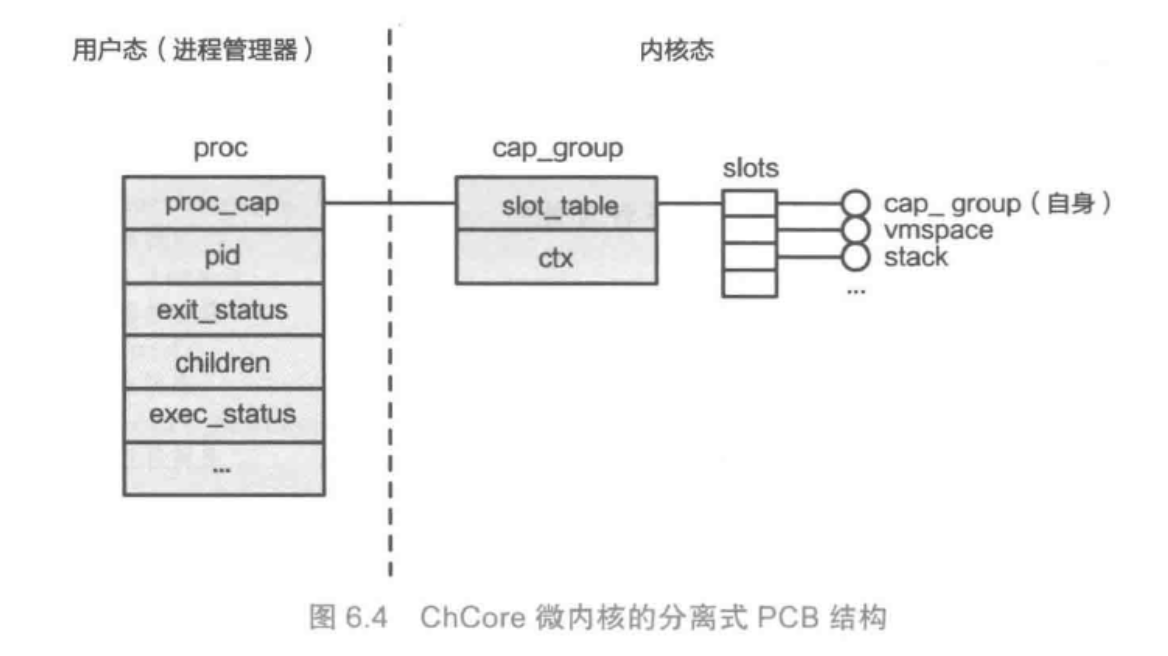
- 判断内核是否能够唤起创建能力组。采用
hook_sys_create_cap_group。 - 从用户态中的
proc_cap部分获取信息,传递到内核态。 - 分配内核态的能力组。该能力组也是对象。
obj_alloc. - 调用普通进程的能力组初始化。
cap_group_init_user。在这一操作中,首先,将进程pid赋予给能力组。然后,初始化线程数和ptrace,并且分配内核态全局标识(badge)。 - 接下来初始化能力组的槽表(slot_table)。
cap_alloc。首先获取当前进程中的线程的能力组(通过current_cap_group宏定义得到),然后进入到cap_alloc_with_rights中。 - 分配能力与权力
cap_alloc_with_rights。首先获得当前进程能力组对象真正存储的地址(也就是我们熟悉的container_of宏定义,计算地址量的偏差然后回溯到结构体的所在地址),并且关联到线程拥有的槽表。 - 为槽表分配id,并且在槽表中分配一个槽。将线程自身的cap_group放入第一个槽(如图中所示)。
- 将新的对象加入到链表中(前面的虚拟内存/物理内存管理需要),并且更新进程的能力组的槽表的id。
install_slot - 接下来为vmspace(虚拟地址空间)分配对象和能力组。
这样我们就完成了线程管理的第一部分。
ELF加载
然而,完成 cap_group 的分配之后,用户程序并没有办法直接运行,因为cap_group只是一个资源集合的概念。线程才是内核中的调度执行单位,因此还需要进行线程的创建,将用户程序 ELF 的各程序段加载到内存中。
(此为内核中 ELF 程序加载过程,用户态进行 ELF 程序解析可参考user/system-services/system-servers/procmgr/libs/libchcoreelf/libchcoreelf.c,如何加载程序可以对user/system-services/system-servers/procmgr/srvmgr.c中的procmgr_launch_process函数进行详细分析)
练习题2: 在
kernel/object/thread.c中完成create_root_thread函数,将用户程序 ELF 加载到刚刚创建的进程地址空间中。
- 程序头可以参考
kernel/object/thread_env.h。 - 内存分配操作使用 create_pmo,可详细阅读
kernel/object/memory.c了解内存分配。
回顾我们创建进程的过程。我们整体的进程创建有五步:
- 创建PCB。(√)
- 虚拟内存初始化。(√)
- 内核栈初始化。
- 加载可执行文件到内存。
- 初始化用户栈和运行环境。
接下来我们需要完成3,4,5步来完成我们根进程的第一个线程。
首先,我们先了解我们的ELF文件。可以参见Lec 04 系统调用的第五节。我们的ELF文件具有如下的格式:
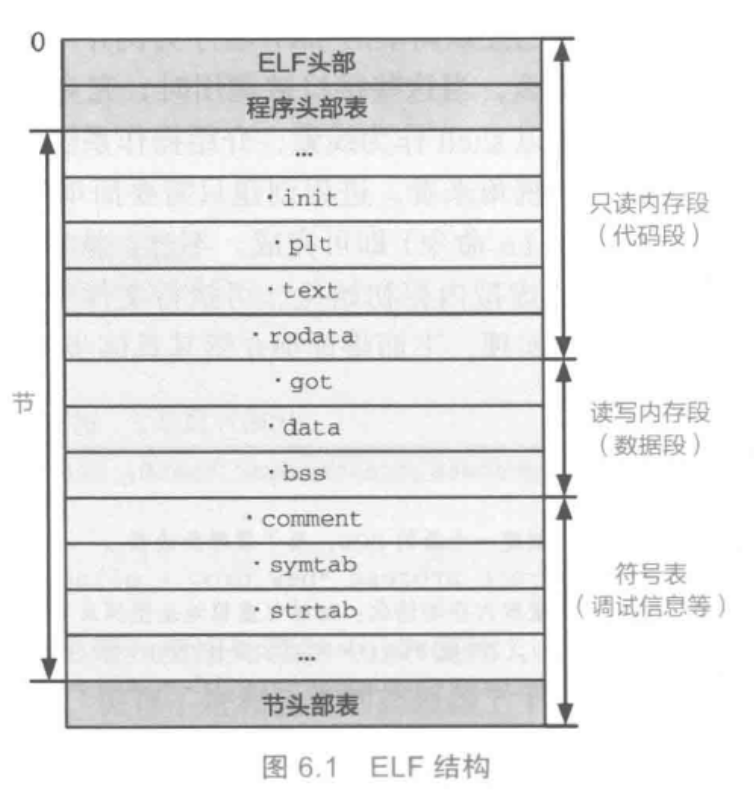
其次,我们来到我们的create_root_thread函数中。
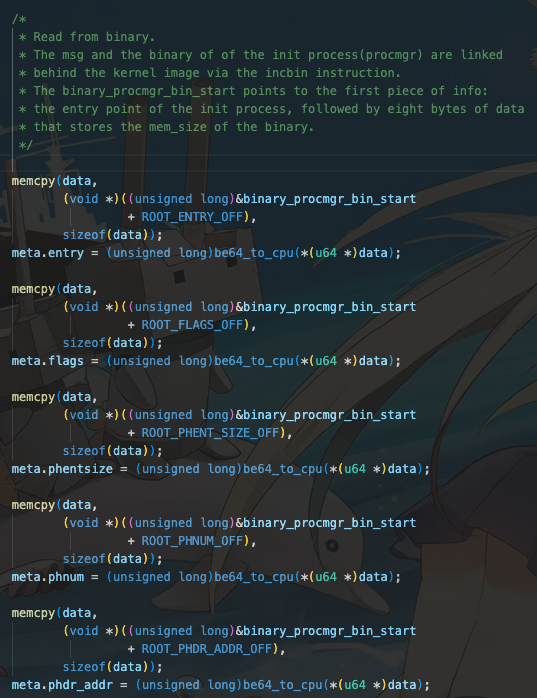
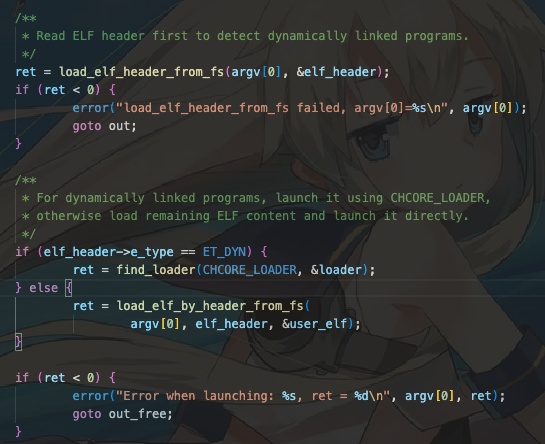
1.我们需要将我们的启动服务(也就是procmgr)的ELF头部加载进入我们的内存中。因为这是我们的根进程。如下图所示。
2.然后为我们的根进程内的第一个线程创建所属于的能力组,并且分配和初始化虚拟内存空间。

3.接下来创建物理内存对象,创建页表,建立物理内存与虚拟内存之间的映射。
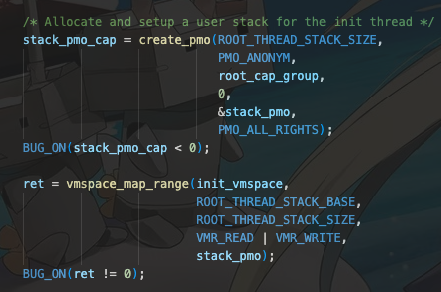
4.创建线程(线程也是对象),然后正式进入加载程序ELF的程序头部表部分。
其实程序都给我们一个例子。我们有:
memcpy(data,(void *)((unsigned long)&binary_procmgr_bin_start+ ROOT_PHDR_OFF + i * ROOT_PHENT_SIZE+ PHDR_FLAGS_OFF),sizeof(data));
flags = (unsigned int)le32_to_cpu(*(u32 *)data);来获得flags的信息。
这样我们直接照葫芦画瓢,找到对应的在thread_env.h偏移定义即可。
/* LAB 3 TODO BEGIN */
/* Get offset, vaddr, filesz, memsz from image*/
// UNUSED(flags);
// UNUSED(filesz);
// UNUSED(offset);
// UNUSED(memsz);
memcpy(data,(void *)((unsigned long)&binary_procmgr_bin_start+ ROOT_PHDR_OFF + i * ROOT_PHENT_SIZE+ PHDR_OFFSET_OFF),sizeof(data));
offset = (unsigned long)le64_to_cpu(*(u64 *)data);
memcpy(data,(void *)((unsigned long)&binary_procmgr_bin_start+ ROOT_PHDR_OFF + i * ROOT_PHENT_SIZE+ PHDR_VADDR_OFF),sizeof(data));
vaddr = (unsigned long)le64_to_cpu(*(u64 *)data);
memcpy(data,(void *)((unsigned long)&binary_procmgr_bin_start+ ROOT_PHDR_OFF + i * ROOT_PHENT_SIZE+ PHDR_FILESZ_OFF),sizeof(data));
filesz = (unsigned long)le64_to_cpu(*(u64 *)data);
memcpy(data,(void *)((unsigned long)&binary_procmgr_bin_start+ ROOT_PHDR_OFF + i * ROOT_PHENT_SIZE+ PHDR_MEMSZ_OFF),sizeof(data));
memsz = (unsigned long)le64_to_cpu(*(u64 *)data);
/* LAB 3 TODO END */
5.接下来还要为程序头部表分配物理内存对象。在分配这里是我们使用段物理内存对象,也就是segment_pmo。然后,每次分配一个物理页大小的段内存,并且映射到虚拟空间中。因此这里需要计算程序头部表中需要多少个物理页,并且从虚拟地址中计算出物理地址,填写到对应的段成员中。我们有:
struct pmobject *segment_pmo = NULL;
/* LAB 3 TODO BEGIN */
// UNUSED(segment_pmo);
size_t pmo_size = ROUND_UP(memsz, PAGE_SIZE)
vaddr_t segment_content_kvaddr = ((unsignelong) &binary_procmgr_bin_start) + offset;
/* LAB 3 TODO END */
BUG_ON(filesz != memsz);
ret = create_pmo(PAGE_SIZE,PMO_DATA,root_cap_group,0,&segment_pmo,PMO_ALL_RIGHTS);
BUG_ON(ret < 0);
kfree((void *)phys_to_virt(segment_pmo -> start));
/* LAB 3 TODO BEGIN */
/* Copy elf file contents into memory*/
segment_pmo -> start = virt_to_phys(segment_content_kvaddr);
segment_pmo -> size = pmo_size;
/* LAB 3 TODO END */
6.接下来设置虚拟空间的权限。因为这是程序头部表部分,需要让程序能够对虚拟空间进行读写和执行。回顾我们在lab2中设置flag的经验,我们采用或的方式设置。(位于OS-Course-Lab/lab2/kernel/mm/vmspace.c)中。
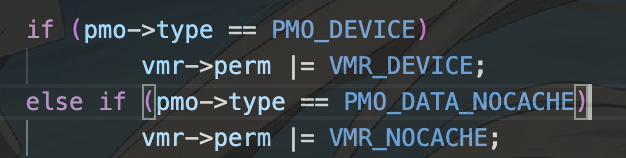
因此我们有:
/* LAB 3 TODO BEGIN */
/* Set flags*/
if(flags & PHDR_FLAGS_R)vmr_flags |= VMR_READ;
if(flags & PHDR_FLAGS_W)vmr_flags |= VMR_WRITE;
if(flags & PHDR_FLAGS_X)vmr_flags |= VMR_EXEC;
/* LAB 3 TODO END */
这样我们就完成了ELF加载过程。
以下内容可以跳过。关于
srvmgr.c中的procmgr_launch_process的相关解读
int procmgr_launch_process(int argc, char **argv, char *name,bool if_has_parent, badge_t parent_badge,struct new_process_args *np_args, int proc_type,struct proc_node **out_proc)
这是一个通过根进程procmgr加载指定名字的可执行文件的程序。首先,先读取我们的ELF文件,判断这是不是一个动态链接程序。
- 动态链接VS静态链接?
- 静态链接:这是我们最为常用的方式。对于几个已经编写好的程序,我们利用make,cmake等确定编译规则和链接规则。然后进行以下三步:(1)预处理。也就是粗暴地将头文件,预编译指令等等直接插入程序中生成.i文件。(2)编译,详情参见
编译原理,通过编译器将程序生成.s汇编文件。(3)汇编:将汇编指令翻译成机器指令,生成可重定位二进制目标文件。(4)链接:我们将生成的.o文件根据依赖关系进行链接,最后生成一个可以执行的程序。最后一个过程就是静态链接。在linux中可以将可执行文件打包生成静态链接库为.a。 - 动态链接:为了解决空间问题和更新困难问题,可以将程序按照模块拆分成相对独立的部分。只有在程序运行时才将他们连接在一起,而不是在运行前就链接形成可执行文件。并且,可复用性很强。当程序一已经加载了动态链接程序时,程序二也需要使用时,只需要将相同的物理地址映射到不同的程序的不同虚拟空间内的虚拟地址即可。这样大大减少了物理内存的占用,不需要重复加载相同的程序块到内存中。
接下来从文件中读取elf的文件头,再根据文件头读取elf程序文件。
随后进入到启动进程部分。首先检查是否有父节点(是否是一个进程唤起的子线程,例如fork)。接着就是创建线程节点。一样的过程(分配object,初始化进程节点)。
然后,将elf内的相关信息和传入该函数的相关信息用于初始化新的进程的相关成员。接着根据是否为动态/静态链接来启动这个进程。最后初始化进程节点的相关状态,成员组等元信息。
这就是整个函数的大致过程。
在
user/system-services/system-servers/procmgr/include/libchcoreelf.h中具有elf的详细定义和相关信息。
进程调度
完成用户程序的内存分配后,用户程序代码实际上已经被映射在root_cap_group的虚拟地址空间中。接下来需要对创建的线程进行初始化,以做好从内核态切换到用户态线程的准备。
练习题3:在
kernel/arch/aarch64/sched/context.c中完成init_thread_ctx函数,完成线程上下文的初始化。
首先,我们需要回顾我们的上下文结构。

在进行上下文切换时,我们需要保存上述的通用寄存器,特殊寄存器中的用户栈寄存器(我们的stack虚拟地址)以及系统寄存器中用于保存PC(也就是我们传进来的函数的虚拟地址)和PSTATE的寄存器。此时进行初始化的时候,应该设定我们的PSTATE在用户态上,也就是SPSR_EL0t.


这样初始化就可以直接完成如下:
void init_thread_ctx(struct thread *thread, vaddr_t stack, vaddr_t func,u32 prio, u32 type, s32 aff)
{/* Fill the context of the thread *//* LAB 3 TODO BEGIN *//* SP_EL0, ELR_EL1, SPSR_EL1*/thread->thread_ctx->ec.reg[SP_EL0] = stack; // 用户栈寄存器thread->thread_ctx->ec.reg[ELR_EL1] = func; // PC寄存器thread->thread_ctx->ec.reg[SPSR_EL1] = SPSR_EL1_EL0t; // 状态寄存器/* LAB 3 TODO END *//* Set the state of the thread */thread->thread_ctx->state = TS_INIT;/* Set thread type */thread->thread_ctx->type = type;/* Set the cpuid and affinity */thread->thread_ctx->affinity = aff;/* Set the budget and priority of the thread */if (thread->thread_ctx->sc != NULL) {thread->thread_ctx->sc->prio = prio;thread->thread_ctx->sc->budget = DEFAULT_BUDGET;}thread->thread_ctx->kernel_stack_state = KS_FREE;/* Set exiting state */thread->thread_ctx->thread_exit_state = TE_RUNNING;thread->thread_ctx->is_suspended = false;
}
至此,我们完成了第一个用户进程与第一个用户线程的创建。接下来就可以从内核态向用户态进行跳转了。 回到kernel/arch/aarch64/main.c,在create_root_thread()完成后,分别调用了sched()与eret_to_thread(switch_context())。 sched()的作用是进行一次调度,在此场景下我们创建的第一个线程将被选择。
switch_context()函数的作用则是进行线程上下文的切换,包括vmspace、fpu、tls等。并且将cpu_info中记录的当前CPU线程上下文记录为被选择线程的上下文(完成后续实验后对此可以有更深的理解)。switch_context() 最终返回被选择线程的thread_ctx地址,即target_thread->thread_ctx。
eret_to_thread最终调用了kernel/arch/aarch64/irq/irq_entry.S中的 __eret_to_thread 函数。其接收参数为target_thread->thread_ctx,将 target_thread->thread_ctx 写入sp寄存器后调用了 exception_exit 函数,exception_exit 最终调用 eret 返回用户态,从而完成了从内核态向用户态的第一次切换。
注意此处因为尚未完成exception_exit函数,因此无法正确切换到用户态程序,在后续完成exception_exit后,可以通过 gdb 追踪 pc 寄存器的方式查看是否正确完成内核态向用户态的切换。
思考内核从完成必要的初始化到第一次切换到用户态程序的过程是怎么样的?尝试描述一下调用关系。
我们有如下的流程图
然而,目前任何一个用户程序并不能正常退出,也不能正常输出结果。这是由于程序中包括了 svc #0 指令进行系统调用。由于此时 ChCore 尚未配置从用户模式(EL0)切换到内核模式(EL1)的相关内容,在尝试执行 svc 指令时,ChCore 将根据目前的配置(尚未初始化,异常处理向量指向随机位置)执行位于随机位置的异常处理代码,进而导致触发错误指令异常。同样的,由于错误指令异常仍未指定处理代码的位置,对该异常进行处理会再次出发错误指令异常。ChCore 将不断重复此循环,并最终表现为 QEMU 不响应。后续的练习中将会通过正确配置异常向量表的方式,对这一问题进行修复。
3.3 异常处理
由于 ChCore 尚未对用户模式与内核模式的切换进行配置,一旦 ChCore 进入用户模式执行就再也无法正常返回内核模式使用操作系统提供其他功能了。在这一部分中,我们将通过正确配置异常向量表的方式,为 ChCore 添加异常处理的能力。
在 AArch64 架构中,异常是指低特权级软件(如用户程序)请求高特权软件(例如内核中的异常处理程序)采取某些措施以确保程序平稳运行的系统事件,包含同步异常和异步异常:
- 同步异常:通过直接执行指令产生的异常。同步异常的来源包括同步中止(synchronous abort)和一些特殊指令。当直接执行一条指令时,若取指令或数据访问过程失败,则会产生同步中止。此外,部分指令(包括
svc等)通常被用户程序用于主动制造异常以请求高特权级别软件提供服务(如系统调用)。 - 异步异常:与正在执行的指令无关的异常。异步异常的来源包括普通中 IRQ、快速中断 FIQ 和系统错误 SError。IRQ 和 FIQ 是由其他与处理器连接的硬件产生的中断,系统错误则包含多种可能的原因。本实验不涉及此部分。
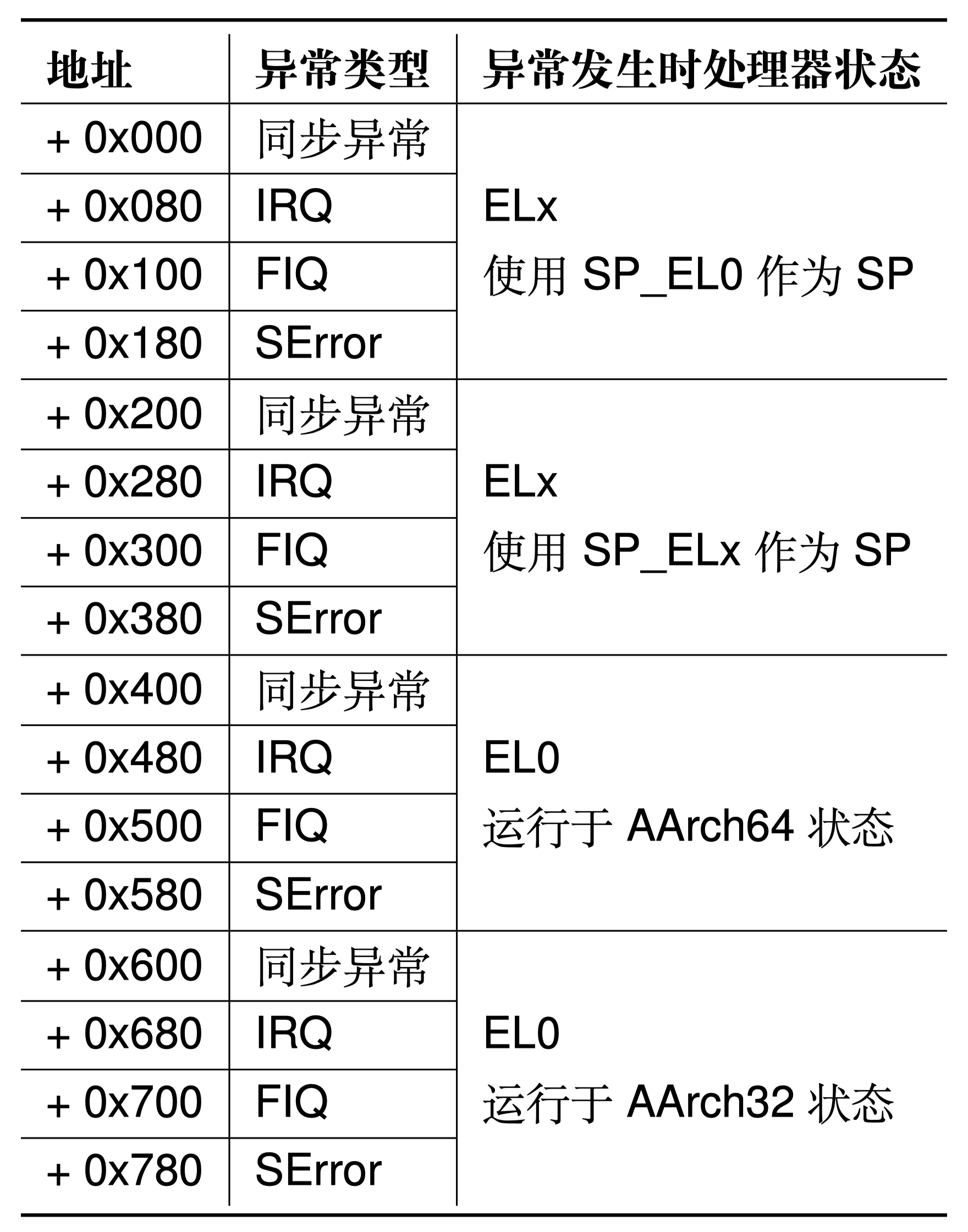
发生异常后,我们需要从kernel/arch/aarch64/irq/irq_entry.S中找到对应的异常处理程序代码(异常向量)执行。每个异常级别在aarch64中有自己独立的异常向量表,其虚拟地址由该异常级别下的异常向量基地址寄存器(VBAR_EL3,VBAR_EL2 和 VBAR_EL1)决定。每个异常向量表中包含 16 个条目,每个条目里存储着发生对应异常时所需执行的异常处理程序代码。以上表格给出了每个异常向量条目的偏移量。
在 ChCore 中,仅使用了 EL0 和 EL1 两个异常级别,因此仅需要对 EL1 异常向量表进行初始化即可。在本实验中,ChCore 内除系统调用外所有的同步异常均交由 handle_entry_c 函数进行处理。遇到异常时,硬件将根据 ChCore 的配置执行对应的汇编代码,将异常类型和当前异常处理程序条目类型作为参数传递,对于 sync_el1h 类型的异常,跳转 handle_entry_c 使用 C 代码处理异常。对于 irq_el1t、fiq_el1t、fiq_el1h、error_el1t、error_el1h、sync_el1t 则跳转 unexpected_handler 处理异常。
按照前文所述的表格填写
kernel/arch/aarch64/irq/irq_entry.S中的异常向量表,并且增加对应的函数跳转操作。
配置EL1级别下和EL0级别下的异常向量,填写异常向量表。根据上边的表格描述,我们发现针对不同异常发生时的处理器状态(四种)和不同的异常情况(四种)共分成16种情况,每种情况按照0x80对齐(128字节)。因此我们可以使用前面的 exception_entry 汇编宏定义,将我们的异常按照128字节对齐后跳转到对应的异常类型的异常处理向量。因此我们可以:
/* LAB 3 TODO BEGIN */exception_entry sync_el1t // Synchronous EL1texception_entry irq_el1t // IRQ EL1texception_entry fiq_el1t // FIQ EL1texception_entry error_el1t // Error EL1texception_entry sync_el1h // Synchronous EL1hexception_entry irq_el1h // IRQ EL1hexception_entry fiq_el1h // FIQ EL1hexception_entry error_el1h // Error EL1hexception_entry sync_el0_64 // Synchronous 64-bit EL0exception_entry irq_el0_64 // IRQ 64-bit EL0exception_entry fiq_el0_64 // FIQ 64-bit EL0exception_entry error_el0_64 // Error 64-bit EL0exception_entry sync_el0_32 // Synchronous 32-bit EL0exception_entry irq_el0_32 // IRQ 32-bit EL0exception_entry fiq_el0_32 // FIQ 32-bit EL0exception_entry error_el0_32 // Error 32-bit EL0/* LAB 3 TODO END */
进行128字节对齐,这样虽然每种类型的异常处理向量数目不同,但是每种类型都等长地占据相同的空间,减少异常处理的时间。
3.4 系统调用
内核支持
系统调用是系统为用户程序提供的高特权操作接口。在本实验中,用户程序通过 svc 指令进入内核模式。在内核模式下,首先操作系统代码和硬件将保存用户程序的状态。操作系统根据系统调用号码执行相应的系统调用处理代码,完成系统调用的实际功能,并保存返回值。最后,操作系统和硬件将恢复用户程序的状态,将系统调用的返回值返回给用户程序,继续用户程序的执行。
通过异常进入到内核后,需要保存当前线程的各个寄存器值,以便从内核态返回用户态时进行恢复。保存工作在 exception_enter 中进行,恢复工作则由 exception_exit 完成。可以参考kernel/include/arch/aarch64/arch/machine/register.h 中的寄存器结构,保存时在栈中应准备ARCH_EXEC_CONT_SIZE大小的空间。
完成保存后,需要进行内核栈切换,首先从TPIDR_EL1寄存器中读取到当前核的per_cpu_info(参考kernel/include/arch/aarch64/arch/machine/smp.h),从而拿到其中的cpu_stack地址。
填写
kernel/arch/aarch64/irq/irq_entry.S中的exception_enter与exception_exit,实现上下文保存的功能,以及switch_to_cpu_stack内核栈切换函数。如果正确完成这一部分,可以通过 Userland 测试点。这代表着程序已经可以在用户态与内核态间进行正确切换。显示如下结果
Hello userland!
首先我们先完成异常进入和异常退出部分。
这一部分可以直接参照书本上的内容。首先,进入异常处理前需要进行保存上下文,然后进行异常处理。最后恢复上下文。我们有:


先保存x0——x29通用寄存器,再保存x30和三个寄存器(用户栈寄存器SP_EL0,PC寄存器ELR_EL1和用户状态寄存器SPSR_EL0)。恢复时先恢复x30和三个寄存器,再恢复x0-x29.
/* See more details about the bias in registers.h */
.macro exception_enter/* LAB 3 TODO BEGIN */sub sp, sp, #ARCH_EXEC_CONT_SIZE// saving general register.stp x0, x1, [sp, #16 * 0]stp x2, x3, [sp, #16 * 1]stp x4, x5, [sp, #16 * 2]stp x6, x7, [sp, #16 * 3]stp x8, x9, [sp, #16 * 4]stp x10, x11, [sp, #16 * 5]stp x12, x13, [sp, #16 * 6]stp x14, x15, [sp, #16 * 7]stp x16, x17, [sp, #16 * 8]stp x18, x19, [sp, #16 * 9]stp x20, x21, [sp, #16 * 10]stp x22, x23, [sp, #16 * 11]stp x24, x25, [sp, #16 * 12]stp x26, x27, [sp, #16 * 13]stp x28, x29, [sp, #16 * 14]/* LAB 3 TODO END */// special register saving.mrs x21, sp_el0mrs x22, elr_el1mrs x23, spsr_el1/* LAB 3 TODO BEGIN */stp x30, x21, [sp, #16 * 15]stp x22, x23, [sp, #16 * 16]/* LAB 3 TODO END */.endm.macro exception_exit/* LAB 3 TODO BEGIN */// do upside down of enter.ldp x22, x23, [sp, #16 * 16]ldp x30, x21, [sp, #16 * 15] /* LAB 3 TODO END */msr sp_el0, x21msr elr_el1, x22msr spsr_el1, x23/* LAB 3 TODO BEGIN */ldp x0, x1, [sp, #16 * 0]ldp x2, x3, [sp, #16 * 1]ldp x4, x5, [sp, #16 * 2]ldp x6, x7, [sp, #16 * 3]ldp x8, x9, [sp, #16 * 4]ldp x10, x11, [sp, #16 * 5]ldp x12, x13, [sp, #16 * 6]ldp x14, x15, [sp, #16 * 7]ldp x16, x17, [sp, #16 * 8]ldp x18, x19, [sp, #16 * 9]ldp x20, x21, [sp, #16 * 10]ldp x22, x23, [sp, #16 * 11]ldp x24, x25, [sp, #16 * 12]ldp x26, x27, [sp, #16 * 13]ldp x28, x29, [sp, #16 * 14]add sp, sp, #ARCH_EXEC_CONT_SIZE/* LAB 3 TODO END */eret
.endm
接着根据我们前面提及的:
- 对于 sync_el1h 类型的异常,跳转
handle_entry_c使用 C 代码处理异常。 - 对于 irq_el1t、fiq_el1t、fiq_el1h、error_el1t、error_el1h、sync_el1t 则跳转
unexpected_handler处理异常。
需要注意的是,在sync_el1h类型的异常,跳转到C函数后,退出异常前需要保存好返回值。(如注释里所说)。因为大部分的sync错误来源于以下四种情况,因此需要储存好我们的返回值。

这样我们将会有以下方式:
irq_el1t:
fiq_el1t:
fiq_el1h:
error_el1t:
error_el1h:
sync_el1t:/* LAB 3 TODO BEGIN */bl unexpected_handler/* LAB 3 TODO END */sync_el1h:exception_entermov x0, #SYNC_EL1hmrs x1, esr_el1mrs x2, elr_el1/* LAB 3 TODO BEGIN *//* jump to handle_entry_c, store the return value as the ELR_EL1 */bl handle_entry_cstr x0, [sp, #16 * 16] /* store the return value as the ELR_EL1 *//* LAB 3 TODO END */exception_exit
这样我们完成了异常向量配置和异常进入/退出部分。
用户态libc支持
在本实验中新加入了 libc 文件,用户态程序可以链接其编译生成的libc.so,并通过 libc 进行系统调用从而进行向内核态的异常切换。在实验提供的 libc 中,尚未实现 printf 的系统调用,因此用户态程序无法进行正常输出。实验接下来将对 printf 函数的调用链进行分析与探索。
printf 函数调用了 vfprintf,其中文件描述符参数为 stdout。这说明在 vfprintf 中将使用 stdout 的某些操作函数。
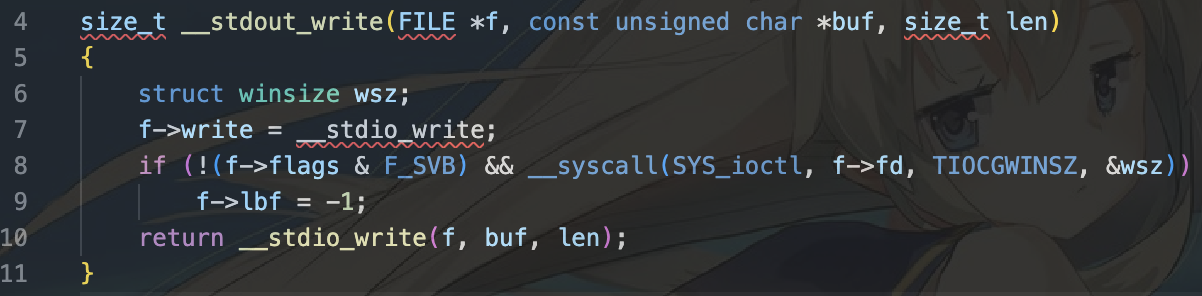
在 user/chcore-libc/musl-libc/src/stdio/stdout.c 中可以看到 stdout 的 write 操作被定义为 __stdout_write,之后调用到 __stdio_write 函数。
最终 printf 函数将调用到 chcore_stdout_write。
printf如何调用到chcore_stdout_write?
chcore_write中使用了文件描述符,stdout描述符的设置在user/chcore-libc/musl-libc/src/chcore-port/syscall_dispatcher.c中。
chcore_stdout_write 中的核心函数为 put,此函数的作用是向终端输出一个字符串。
printf函数定义在user/chcore-libc/musl-libc/src/stdio/printf.c.
我们有如下的调用链:
1.调用vfprintf()函数。
2.使用printf_core()函数检查相关的输入格式是否正确。
3.调用f->write函数。此时,因为传入的流为stdout。这个定义于stdout.c文件中:
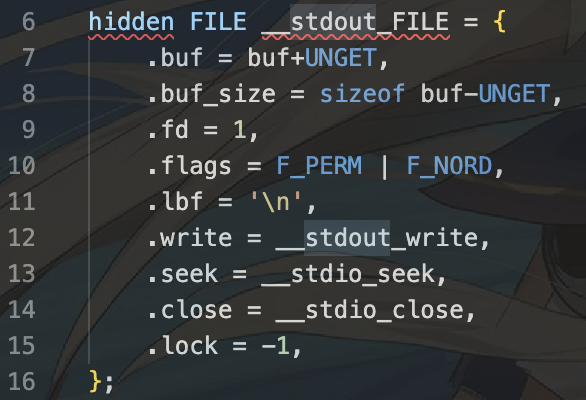
因此将会调用__stdout_write函数。随后调用到__stdio_write函数。
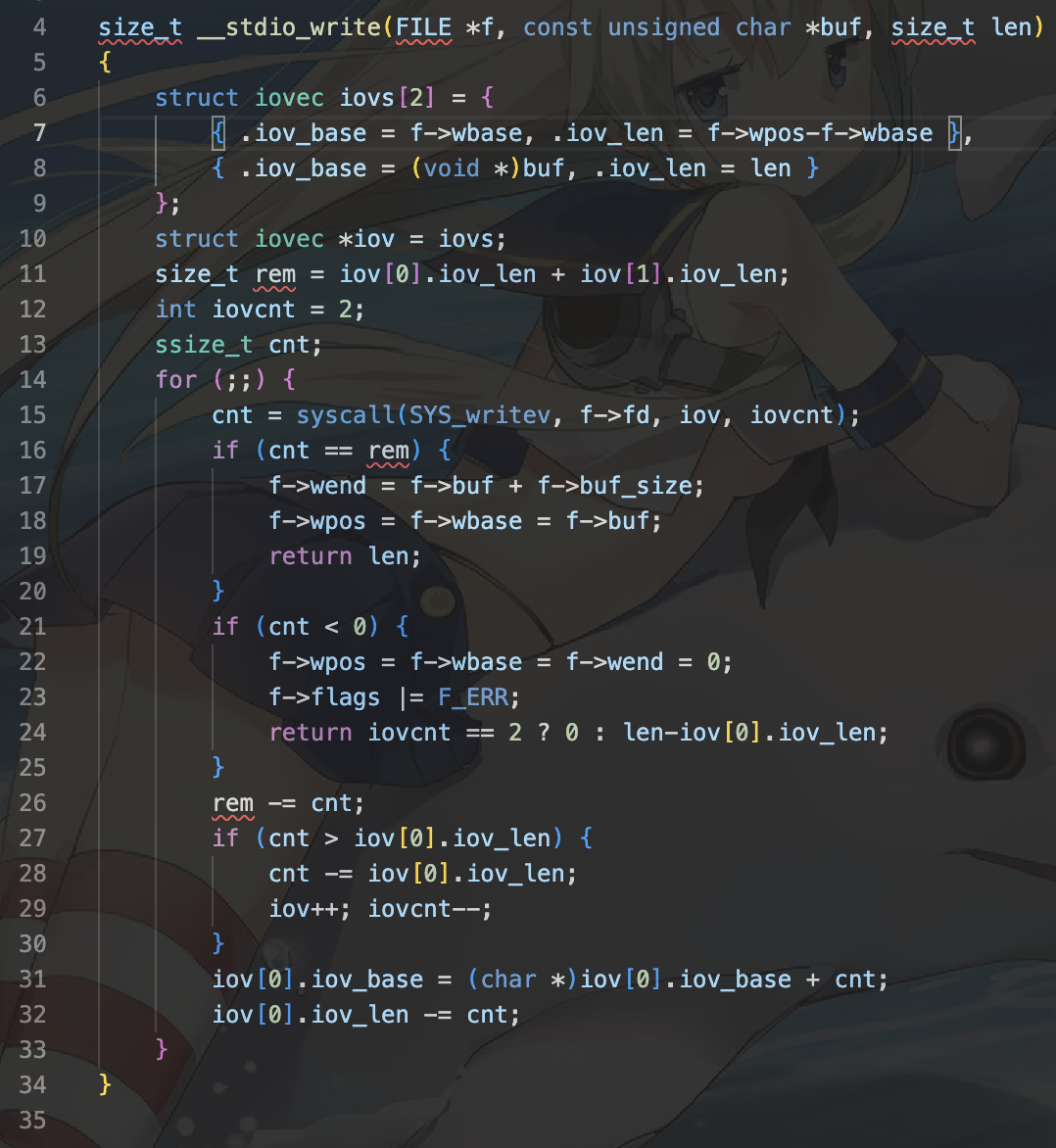
4.此时将会调用系统服务,也就是定义在syscall_dispatcher中。syscall有宏定义:
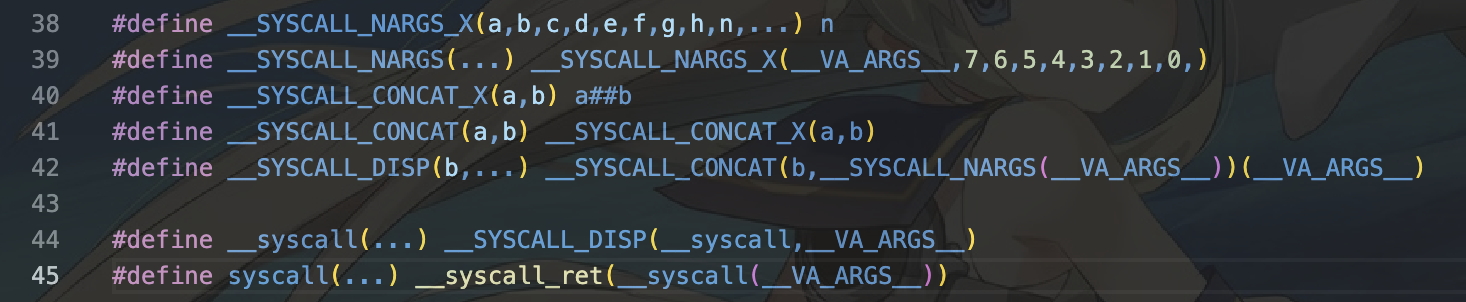
5.这里首先根据宏定义确定具体的系统调用(syswritev),随后确定参数量为3,因此最终调用__syscall3,随后在case SYS_writev下调用__syscall6.所以实际上对于需要x个参数的系统调用,需要传入x+1个参数,其中第一个参数为需要内核进行的具体系统调用函数类型。
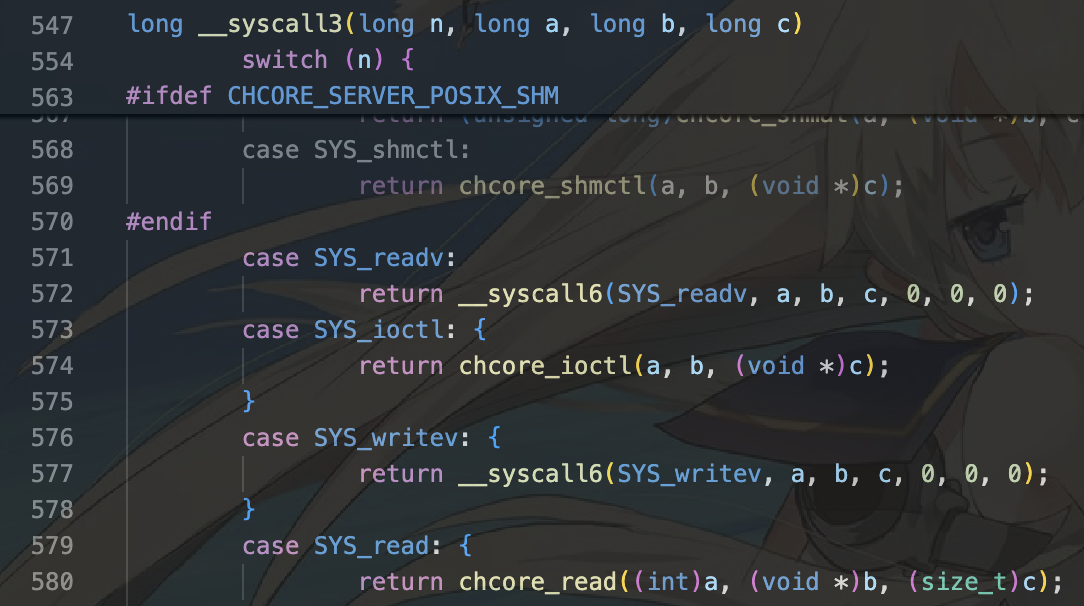
6.调用chcore_write函数,需要从我们的描述符中判断应该调用哪种write函数。我们有:

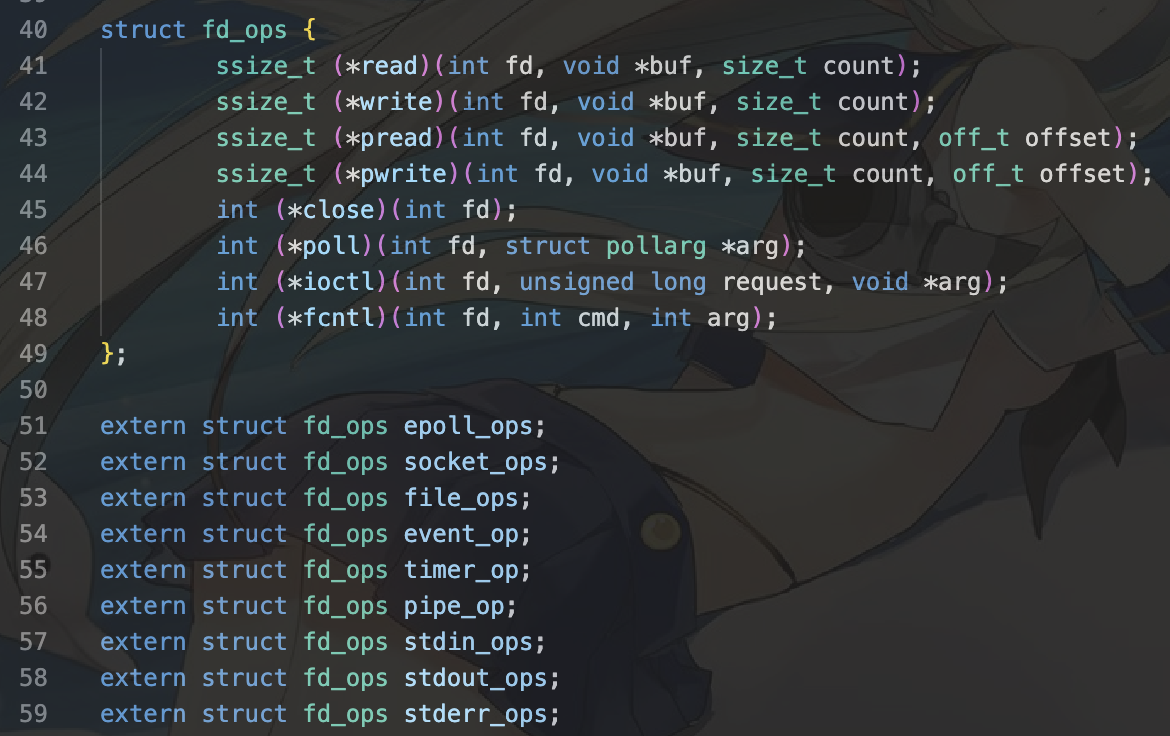
7.此时我们的文件描述符是STDOUT,因此执行的fd_ops类中的write时,应该执行的是stdout_ops对象描述的write。我们再观察stdout_ops.
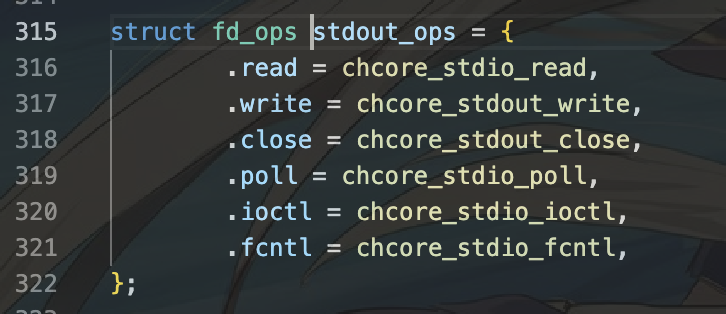
因此执行到了chcore_stdout_write函数。其相对地址在user/chcore-libc/libchcore/porting/overrides/src/chcore-port/stdio.c中。
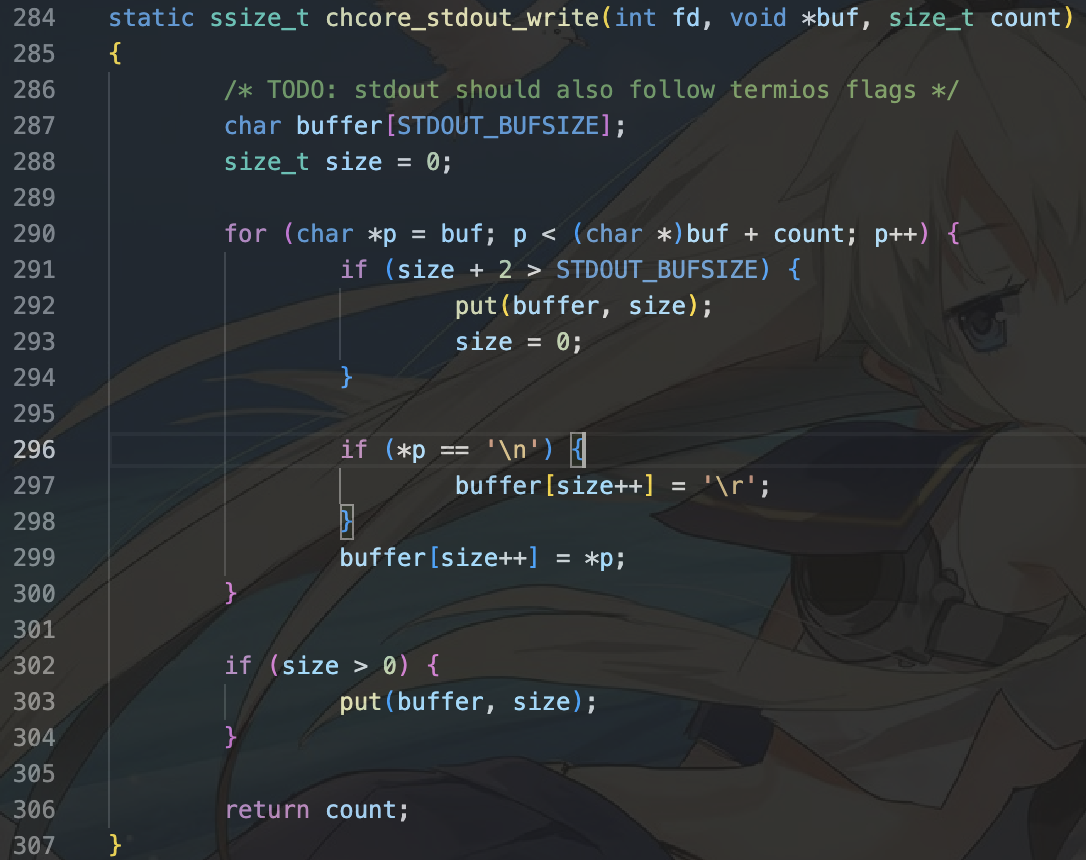
在其中添加一行以完成系统调用,目标调用函数为内核中的
sys_putstr。使用chcore_syscallx函数进行系统调用。
观察,我们的put有两个参数,因此我们需要调用需要(使用)两个参数的系统调用,也就是chcore_syscall2即可。在先前我们已经发现,需要(使用)两个参数的系统调用需要传入三个参数。因此我们有:
static void put(char buffer[], unsigned size)
{/* LAB 3 TODO BEGIN */// 2 arguments for syscall2.chcore_syscall2(CHCORE_SYS_putstr, (vaddr_t)buffer, size);/* LAB 3 TODO END */
}
至此,我们完成了对 printf 函数的分析及完善。从 printf 的例子我们也可以看到从通用 api 向系统相关 abi 的调用过程,并最终通过系统调用完成从用户态向内核态的异常切换。
3.5 编写用户态程序
终于到了最后一刻。万事俱备,我们开始编写我们的用户态程序,通过libc执行系统调用,利用Chcore的libc进行编译,加载到内核镜像中运行。
我们首先编写文件如下。为了防止出现意外,我们的stdio头文件采用libc内的头文件。
# include "build/chcore-libc/include/stdio.h"
int main()
{printf("Hello ChCore!");return 0;
}
接下来使用工具进行编译并且重定向到目标文件夹。在命令行中输入:
./build/chcore-libc/bin/musl-gcc printf.c -o ./ramdisk/hello_world.bin
直接运行程序。
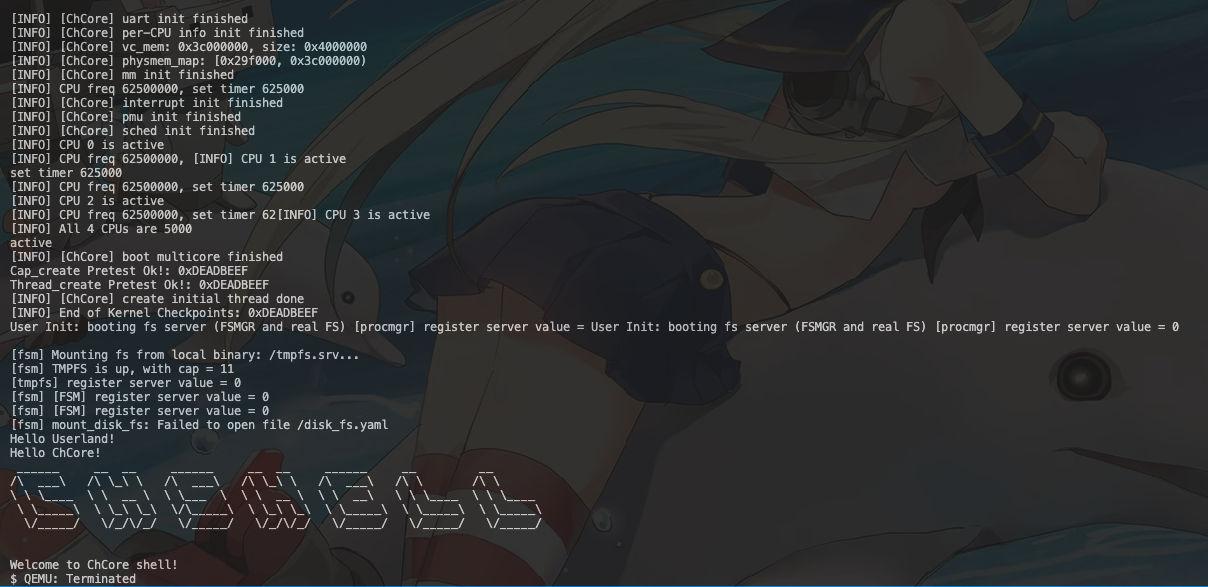
我们可以看到我们在userland后运行了hello chcore。
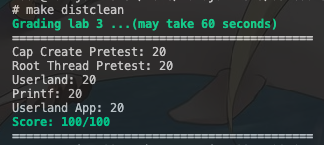


![Natasha v9.0 为 .NET 开发者提供 [热执行] 方案.](https://img2024.cnblogs.com/blog/1119790/202406/1119790-20240622020357627-628105246.gif)