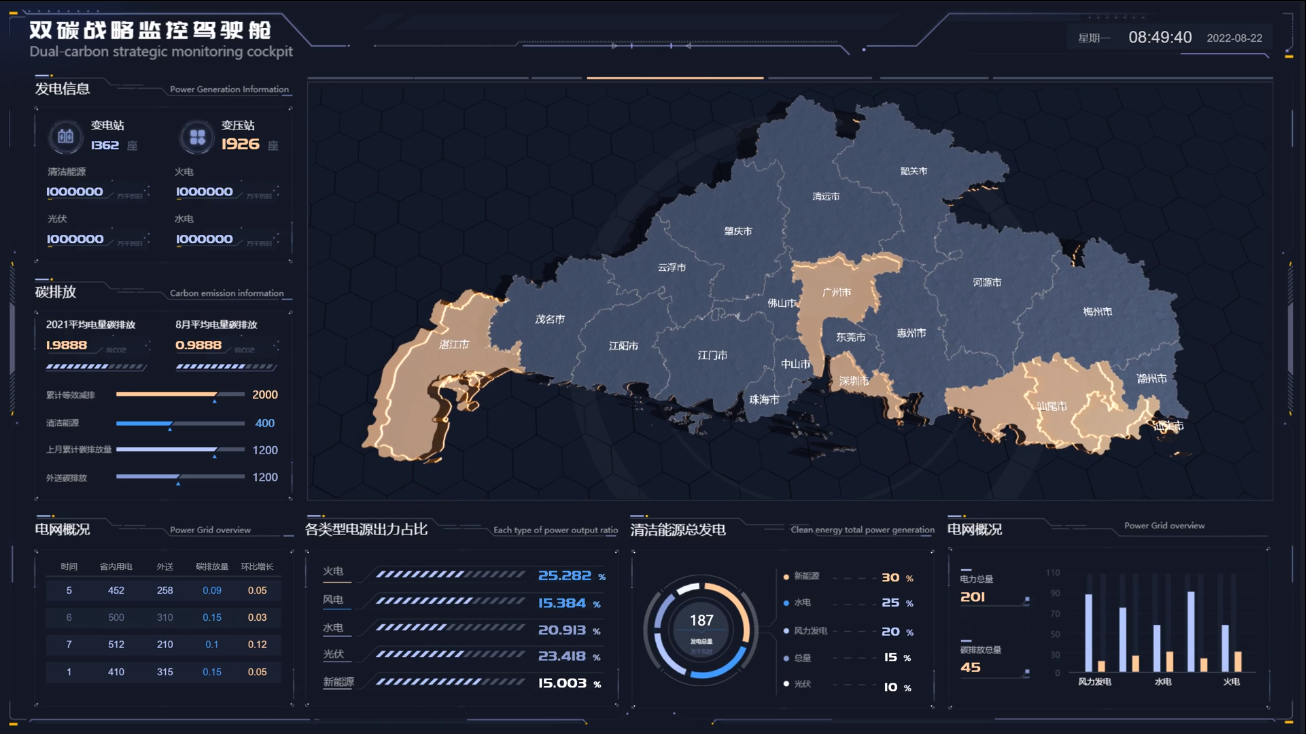
一.Adam优化器
旨在根据历史梯度信息来调整每个参数的学习率,从而实现更高效的网络训练。Adam算法的核心思想是同时计算梯度的一阶矩(均值)和二阶矩(未中心的方差)的指数移动平均,并对它们进行偏差校正,以确保在训练初期时梯度估计不会偏向于0。Adam优化器是一种梯度下降算法的变体,它结合了随机梯度下降算法(SGD)和自适应学习率算法,能够快速收敛并且减少训练时间。Adam优化器计算出每个参数的独立自适应学习率,不需要手动调整学习率的大小,因此在实践中被广泛使用。
Adam优化器的更新规则如下:
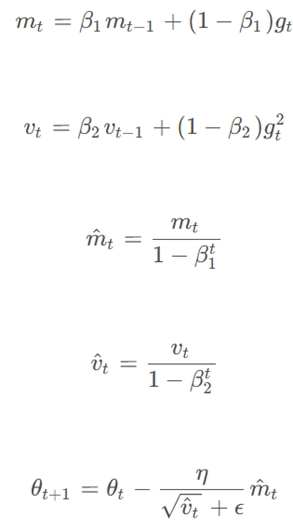
![]()
Adam优化器的主要优点是它能够自适应地调整每个参数的学习率,从而提高模型的收敛速度和泛化能力。此外,Adam优化器的计算量相对较小,使得它在大规模深度学习任务中非常受欢迎。
二.Adam与策略梯度法结合
在训练模型时,参数会根据计算出的梯度和学习率进行更新。文中的梯度上升参数的更新公式为𝜃←𝜃+𝛼∇𝜃𝐽(𝜃)。式中的学习率α来自于Adam优化器,梯度来自于强化算法。在训练过程中,策略梯度算法计算出梯度,表明参数更新的大致方向,Adam优化器根据其自适应学习率机制,调整在这个方向上的更新步长。两者相互配合,既保证了参数更新朝着提升奖励(即提高模型性能)的方向进行,又避免了因步长过大或过小导致的收敛问题,使训练过程更加稳定和高效。