自从我们开始使用 Spring,我们经常听到过滤器(Filter)和拦截器(Interceptor)。然而,当真正需要使用它们时,可能会对它们的区别和相似点感到困惑。产生这种困惑的主要原因是它们的用途相似(例如,授权检查、日志处理、数据压缩/解压等)。
使用过滤器可以实现的场景同样可以用拦截器实现,因此它们的边界变得模糊不清。为了解释它们的差异和相似之处,我们将深入探讨两者的起源和设计理念。
本文基于 SpringBoot 2.7.5 版本进行讲解。
过滤器:外来引入的概念
基本概念
仔细研究源代码,我们会发现过滤器的概念实际上是从 Servlet 引入的外来概念,它遵循 Servlet 规范。可以看一下 Filter 类的全限定名称:
javax.servlet.Filter
可以看出,Filter 用于Tomcat 等 Web 容器中的 Servlet 相关处理,而并非 Spring 原生的工具。这一发现有助于我们理解为什么 Spring 中的过滤器和拦截器具有相似的功能。
由于它们分别由不同的作者为各自的系统创建,因此出现了类似的思想和实现方法也是可以理解的。毕竟,英雄所见略同。
随后,Spring 引入并兼容了 Tomcat 容器的处理逻辑,使得两个相似的概念可以存在于同一应用上下文中(注意,Spring 并没有将它们合并,而只是使其兼容),这也导致开发人员容易产生困惑。
为了更好地理解 Filter 的作用,让我们引入官方的注释进行说明:
过滤器是一个对象,它可以对对资源的请求(如 servlet 或静态内容)或资源的响应或两者执行过滤任务。
从这个定义中,我们可以提取两条有用的信息:
1、执行时机:Filter 的执行时机有两个,在请求处理前和在响应返回前。
2、执行内容:过滤器本质上执行的是过滤任务,而过滤条件基于对资源的请求或对资源的响应。
除了上述信息外,结合 Tomcat 中 Servlet 容器的结构设计,我们可以推导出 Filter 的执行流程图:
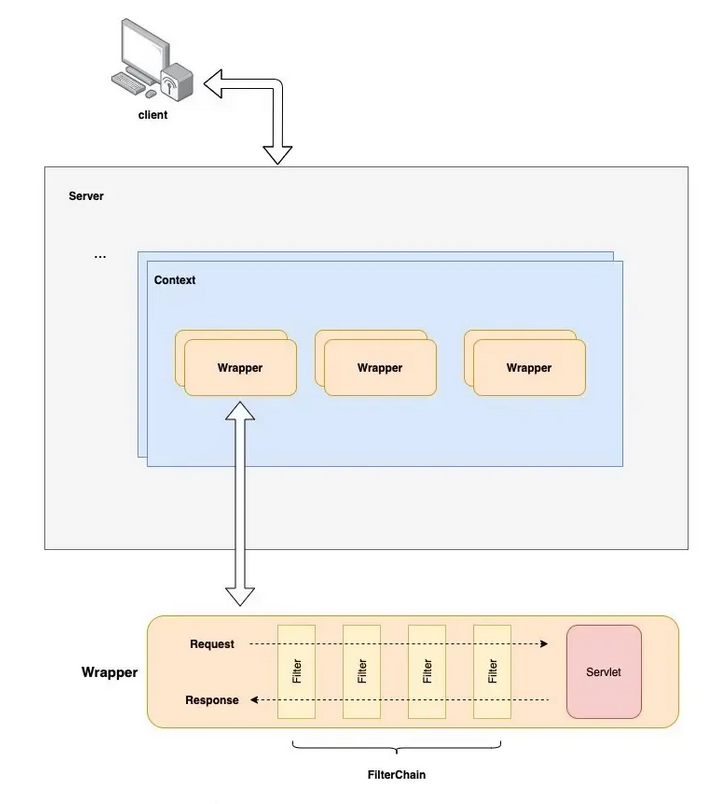
在实际开发场景中,资源请求的预处理或资源响应的后处理可能并不限于单一类型的过滤任务。
因此,Tomcat 设计中使用了责任链模式来处理需要多种不同类型过滤器处理请求或响应的场景。
这一概念也体现在前面提到的流程图中。需要注意的是,由于采用了线性数据结构(链结构),在实际的过滤器操作过程中存在固有的执行顺序。这意味着在实现自定义过滤器时,必须确保过滤器之间不存在依赖反转。
当然,如果过滤器之间没有依赖关系,那么执行顺序就不是问题。Tomcat 使用 org.apache.catalina.core.ApplicationFilterChain 来实现上述的责任链模式。可以通过以下代码更好地理解这一概念:
publicfinalclassApplicationFilterChainimplementsFilterChain{publicvoiddoFilter(ServletRequest request,ServletResponse response)
throwsIOException,ServletException{if(Globals.IS_SECURITY_ENABLED){
finalServletRequest req = request;
finalServletResponse res = response;
try{
java.security.AccessController.doPrivileged(
(java.security.PrivilegedExceptionAction<Void>)()->{
// 实际执行过滤操作
internalDoFilter(req,res);
returnnull;
}
);
}catch(PrivilegedActionException pe){
...
}
}else{
// 实际执行过滤操作
internalDoFilter(request,response);
}
}privatevoidinternalDoFilter(ServletRequest request,
ServletResponse response)
throwsIOException,ServletException{// 如果存在下一个过滤器,则调用它
if(pos < n){
ApplicationFilterConfig filterConfig = filters[pos++];
try{
Filter filter = filterConfig.getFilter();
...
if(Globals.IS_SECURITY_ENABLED){
...
}else{
// 结合 Filter 类进行分析,实际上是执行回调函数,
// 该方法的第三个参数传递了当前的 applicationFilterChain 对象,结合上面的 pos 指针确定过滤链是否已完全执行filter.doFilter(request, response,this);
}
}catch(IOException|ServletException|RuntimeException e){
throw e;
}catch(Throwable e){
...
}
return;
}// 执行到链的末端——调用 servlet 实例
try{
...
// 实际执行 servlet 服务,注意这仅是进入 servlet 实例,而未真正进入具体处理器servlet.service(request, response);
...
}catch(IOException|ServletException|RuntimeException e){
throw e;
}catch(Throwable e){
...
}finally{
...
}
}
}
从上述代码可以看出,Tomcat 使用 pos 指针来记录过滤器链中过滤器的执行位置。
只有在链中的所有过滤器都执行完毕并通过后,request 和 response 对象才会提交给 servlet 实例进行相应的服务处理。
需要注意的是,此时尚未涉及具体的 handler,意味着过滤器的处理无法细化到具体处理器类的请求/响应,而只能较为模糊地处理整个 servlet 实例级别的请求/响应。
当然,从上述代码中还可以看出一个问题,即似乎仅对资源请求进行过滤处理,而没有对资源响应进行过滤处理。
实际上,资源响应的过滤处理隐藏在每个过滤器的 doFilter 方法中。当实现自定义过滤器时,需要遵循以下逻辑来处理资源响应:
@Override
publicvoiddoFilter(ServletRequest request,ServletResponse response,FilterChain chain)throwsIOException,ServletException{
// TODO 前置处理
// 调用 applicationFilterChain 对象的 doFilter 方法(这实际上是回调逻辑)。必须包含这一步,否则链式结构会在此处中断。chain.doFilter(request, response);
// TODO 后置处理
}
结合 ApplicationFilterChain 中的 internalDoFilter 方法,可以发现隐含的入栈和出栈逻辑(本质上是方法堆栈)。资源请求的前置处理实际上是一个入栈过程,当所有前置处理过滤器入栈完毕后,servlet.service(request, response) 开始执行。
在 servlet 服务处理完成后,出栈过程开始,逐个按顺序执行后置处理逻辑,直至方法结束退出。
必须指出,这种逻辑对初学者来说不太友好。由于 Filter 只是一个接口,无法像抽象类那样提供模板方法,初学者在没有参考示例的情况下可能很难使用,若只是查看源码可能会有类似疑问。
还要提醒大家,实现自定义过滤器时必须遵循上述模板,否则可能会导致链式流程被破坏或后置逻辑无法实现。
在 Spring 中的使用
虽然提到了 Spring,但这里实际讨论的是 Spring Boot 中的使用方法。要在 Spring Boot 中实现自定义过滤器,只需添加注入逻辑将其放入 Spring 容器。Spring Boot 提供了两种方式来完成此操作:
1、在自定义过滤器上使用 @Component 注解;
2、在自定义过滤器上使用 @WebFilter 注解,并在启动类上使用 @ServletComponentScan 注解;
推荐使用第二种方法注入过滤器,因为 Spring 提供了 Tomcat 原生处理不具备的额外功能,即 URL 匹配功能。
结合 @WebFilter 注解中的 urlPattern 字段,Spring 能进一步细化过滤器处理的粒度,使开发者更灵活。此外,可通过 Spring 提供的 @Order 注解来自定义过滤器的注入顺序。
拦截器:Spring 原生功能
基本概念
探讨完过滤器后,我们将目光转向拦截器。此时发现,拦截器的概念源自 Spring,对应的接口类为 HandlerInterceptor(还有一个异步拦截器接口类,此处不展开,有兴趣的同学可自行阅读源码)。
查看相应源码后发现,HandlerInterceptor 提供了三个与执行时机相关的方法,而不同于 Filter 仅提供一个简单的 doFilter 方法:
preHandle:在执行相应处理程序之前执行,进行前置处理;
postHandle:在请求处理完成后但在渲染 ModelAndView 对象之前执行,进行与 ModelAndView 对象相关的后置处理;
afterCompletion:在渲染 ModelAndView 对象后且在返回响应前执行,对结果进行后置处理;
与 Filter 类仅提供的 doFilter 方法相比,HandlerInterceptor 的方法定义更为精准和易用。无需阅读源码或参考示例,便可大致猜测如何实现自定义拦截器。
结合 org.springframework.web.servlet.DispatcherServlet#doDispatch 的源码,可以绘制出以下流程图(此处不贴出具体代码,有兴趣的同学可自行查看):

可以看到,拦截器的执行逻辑全部包含在 servlet 实例中。
结合前述过滤器的执行流程说明,不难发现过滤器就像夹心饼干的两片饼干,将 servlet 和拦截器包在中间,拦截器的执行时机在过滤器前置处理之后、后置处理之前。
此外,通过阅读源码还可发现,Spring 在使用拦截器时同样使用了责任链模式。在不同任务和逻辑需顺序执行的场景中,这种模式十分有用。
需要注意的是,由于 Spring 在设计拦截器时已明确定义了不同阶段的方法,因此拦截器的实际执行过程并未采用与过滤器相同的推栈和弹栈方式。
在 Spring 中的使用
要在 Spring Boot 中使用拦截器,除了实现 HandlerInterceptor 接口外,还需要显式地在 Spring 的 Web 配置中进行注册,如下所示:
@Configuration
publicclassWebConfigimplementsWebMvcConfigurer{@Override
publicvoidaddInterceptors(InterceptorRegistry registry){registry.addInterceptor(newDemoInterceptor()).addPathPatterns("/api/*").excludePathPatterns("/api/ok");
}
}
从上述代码可以看到,Spring 也为自定义拦截器提供了与过滤器相同的路径匹配功能。借助该功能,自定义拦截器可以更细致地处理请求和响应。这一点再次重叠了过滤器的功能,但这当然是 Spring 内部提供的功能。
常见使用场景
确实,在文章开头我们已介绍了一些两者的功能。这里再简单总结一下。
从以上分析可以看出,过滤器和拦截器的设计初衷是将请求的前置处理和响应的后置处理从业务代码中分离出来,作为通用处理逻辑供开发者扩展实现。这一设计思想类似于 AOP。
在实际开发中,自定义过滤器或拦截器常用于实现以下操作:
用户登录验证;权限检查;日志拦截;数据压缩/解压;加解密处理;…
这里不展示各场景的编码实现,有兴趣的同学可以自行搜索学习。
一点建议:虽然上述场景看似繁多,但其实本质都是在处理请求参数或响应结果。理解这一点后,设计和实现这些场景就会相对容易。
总结
通过以上分析可见,过滤器和拦截器在Spring Boot中的核心区别在于执行时机、应用场景及使用便捷性。过滤器围绕请求的全流程运行,适合系统级通用逻辑处理(如数据压缩、编码设置),而拦截器位于控制器层面,更适合业务逻辑扩展(如权限校验、日志记录)。
设计上,过滤器通过“推入-弹出”机制延续过滤链,逻辑较为复杂;而拦截器提供明确的接口方法,执行流程更为直观。此外,二者均采用职责链模式,体现AOP思想,帮助实现请求的分层处理。
因此,开发中根据需求选择工具即可:系统级处理优先过滤器,业务级处理优先拦截器。
原创 编程疏影