本文深入简出介绍了 Transformers 框架中的 token-classification 任务,从基础概念到实际应用,包括命名实体识别、分词和词性标注,最后还会提供详细的代码示例和 WebUI 界面操作,帮助你快速上手词元分类和命名实体识别……
本文深入简出介绍了 Transformers 框架中的 token-classification 任务,从基础概念到实际应用,包括命名实体识别、分词和词性标注,最后还会提供详细的代码示例和 WebUI 界面操作,帮助你快速上手词元分类和命名实体识别……微信公众号:老牛同学
公众号标题:Transformers 框架 Pipeline 任务详解(三):词元分类(token-classification)和命名实体识别
公众号链接:https://mp.weixin.qq.com/s/r2uFCwPZaMeDL_eiQsEmIQ
在自然语言处理(NLP)领域,Token-Classification(词元分类)任务是一项关键的技术,这项技术广泛应用于命名实体识别(NER)、分词、词性标注等场景。借助Transformers框架的Pipeline API,我们可以轻松地使用预训练模型执行词元分类,而无需深入了解底层复杂的模型结构和算法。本文将详细介绍Transformers框架中token-classification任务的各个方面,包括任务简介、应用场景、任务配置、实战案例以及Web UI界面。

1. 任务简介
词元分类是指根据给定的文本内容,为文本中的每一个词元分配一个类别标签的过程。词元分类的核心思想是通过机器学习模型从大量标注好的文本数据中学习特征,并根据这些特征对新的文本中的每个词元进行分类。具体步骤如下:
- 数据准备:收集并标注大量的文本数据,每个词元都对应一个类别标签。
- 特征提取:将文本转换为模型可以理解的数值表示,通常是通过分词、向量化等方式。
- 模型训练:使用标注好的数据训练一个分类模型,模型会学习如何根据输入的文本特征预测正确的类别。
- 模型推理:对于新的未见过的文本,模型会根据学到的特征为每个词元进行分类预测。
根据Hugging Face官网的数据,当前已有超过20,531个词元分类模型供选择,涵盖了多种语言和应用场景:
2. 应用场景
词元分类技术广泛应用于各个领域,以下是几个典型的应用场景:
- 命名实体识别(NER):NER可以帮助企业或研究机构自动识别文本中的重要信息,如人物、地点、组织等。这在新闻报道、法律文件分析、情报收集等领域尤为有用。
- 分词:分词是中文和其他一些非空格分隔的语言的基本预处理步骤。准确的分词对于后续的NLP任务至关重要。
- 词性标注:词性标注有助于理解句子的结构和含义,可应用于机器翻译、问答系统、文本摘要等多个方面。
- 情感分析:虽然情感分析通常被视为文本分类任务,但在某些情况下,了解哪些具体的词语表达了情感也是非常重要的,这时词元级别的分类就显得尤为重要了。
- 医疗记录解析:在医疗领域,词元分类可以用于解析病历,帮助医生快速定位关键信息,比如症状、疾病名称、药物名称等。
3. 任务配置
在 Transformers 框架中,ner和token-classification都是词元分类任务的不同名称。尽管两者在 Pipeline 配置中有别名关系,但在实际使用时没有区别,框架最终统一使用token-classification作为任务名称。
我们可以在 Transformers 框架的源代码中看到以下配置(源代码文件:./transformers/pipelines/__init__.py):
TASK_ALIASES = {# 其他省略......"ner": "token-classification",# 其他省略......
}SUPPORTED_TASKS = {# 其他省略......"token-classification": {"impl": TokenClassificationPipeline,"tf": (TFAutoModelForTokenClassification,) if is_tf_available() else (),"pt": (AutoModelForTokenClassification,) if is_torch_available() else (),"default": {"model": {"pt": ("dbmdz/bert-large-cased-finetuned-conll03-english", "4c53496"),"tf": ("dbmdz/bert-large-cased-finetuned-conll03-english", "4c53496"),},},"type": "text",},# 其他省略......
}
从上面的配置可以看出,Transformers框架默认使用的是dbmdz/bert-large-cased-finetuned-conll03-english模型,这是一个在CoNLL-2003 NER数据集上微调过的BERT大模型,专门用于英文命名实体识别任务。该模型是Hugging Face上下载量较大的词元分类模型之一,具有较高的准确性和效率。
4. 实体类型解释
在命名实体识别任务中,实体(entity)指的是文本中被标记为特定类别的词或短语。常用的实体标签遵循一种叫做 IOB 标记格式,其中 I 表示 Inside,O 表示 Outside,B 表示 Begin。IOB 标记法允许我们区分实体内部的词和实体开始的词。以下是一些常见的实体标签及其含义:
- O: 不属于任何命名实体。
- B-PER: 个人名字的开始部分,例如 "B-PER" 可能标记 "John"。
- I-PER: 个人名字的中间或结尾部分,例如 "I-PER" 可能标记 "Doe"。
- B-ORG: 组织机构名称的开始部分,例如公司、政府机关等。
- I-ORG: 组织机构名称的中间或结尾部分。
- B-LOC: 地理位置的开始部分,例如国家、城市、州等。
- I-LOC: 地理位置的中间或结尾部分。
- B-MISC: 各种杂项实体的开始部分,如事件、产品等,不属于上述三类。
- I-MISC: 杂项实体的中间或结尾部分。
此外,还有可能遇到更细化的标签,例如:
- B-DATE: 日期的开始部分。
- I-DATE: 日期的中间或结尾部分。
- B-TIME: 时间的开始部分。
- I-TIME: 时间的中间或结尾部分。
- B-MONEY: 货币金额的开始部分。
- I-MONEY: 货币金额的中间或结尾部分。
- B-PERCENT: 百分数的开始部分。
- I-PERCENT: 百分数的中间或结尾部分。
- B-LANGUAGE: 语言名称的开始部分。
- I-LANGUAGE: 语言名称的中间或结尾部分。
请注意,不同的数据集可能会有不同的标签集合。例如,CoNLL-2003 数据集主要关注 PER(人名)、ORG(组织)、LOC(地点)和 MISC(杂项)四个类别。而在其他数据集中,可能会有更多或更少的类别,以及不同类型的实体。
5. 词元分类实战
首先,确保安装了Transformers库和其他必要的依赖包:
pip install transformers torch
方法一:自动下载模型
我们可以直接从Hugging Face下载模型。如果您的网络环境允许,可以直接下载;否则,可以通过设置镜像来加速下载过程:
import os# 设置代理
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"# 设置本地缓存目录
cache_dir = os.path.join('D:', os.path.sep, 'ModelSpace', 'Cache')
os.environ['HF_HOME'] = cache_dirfrom transformers import pipeline# 创建Pipeline任务
nlp = pipeline("token-classification", model="dbmdz/bert-large-cased-finetuned-conll03-english")# 执行词元分类任务
result = nlp("My name is Wolfgang and I live in Berlin.")
for entity in result:print(f"Word: {entity['word']}, Entity: {entity['entity']}")# 输出:Word: Wolfgang, Entity: I-PER# 输出:Word: Berlin, Entity: I-LOC
Pipeline任务的输出结果将类似于以下格式:
[{'word': 'Wolfgang', 'entity': 'I-PER'}, {'word': 'Berlin', 'entity': 'I-LOC'}]
其中,word表示被分类的词元,entity表示对应的类别标签,例如I-PER表示一个人名中间或结尾部分,I-LOC表示一个地名的中间或结尾部分。
方法二:自主下载模型
如果您希望通过本地模型文件进行推理,可以按照以下步骤操作。实际上,与自动下载相比,唯一的区别是指定分词器和模型即可。假设我们下载的模型目录是/models/pipeline,则用法如下:
from transformers import AutoTokenizer, AutoModelForTokenClassification, pipeline
import os# 下载模型目录
model_dir = '/models/pipeline'# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_dir, local_files_only=True)
model = AutoModelForTokenClassification.from_pretrained(model_dir, torch_dtype="auto", device_map="auto", local_files_only=True)# 创建Pipeline任务
nlp = pipeline("token-classification", tokenizer=tokenizer, model=model)# 后续用法与自动下载相同
我们可以看到,任务的输出结果,和自动下载是一样的。
6. WebUI 页面
通过Gradio,我们可以轻松地为Transformers框架中的token-classification任务创建一个可视化的WebUI界面,用户可以通过浏览器输入文本并实时获得分类结果。
首先,我们需要安装依赖包:
pip install gradio
接下来,我们开始创建Web页面,我们可以复用Pipeline实例:
import sys# 直接复用Pipeline实例
sys.path.append("./")
pipeline = __import__("03-token-classification")import gradio as gr# 定义分类函数
def classify_tokens(text):# 使用Pipeline进行分类result = pipeline.nlp(text)# 提取分类标签和词元output = []for entity in result:word = entity['word']label = entity['entity']output.append((word, label))# 返回格式化后的结果return output# 创建Gradio界面
with gr.Blocks() as demo:gr.Markdown("# 词元分类器")gr.Markdown("这是一个基于Transformers框架的命名实体识别工具。您可以输入任意文本,点击“提交”按钮后,系统将自动标记文本中的实体。")with gr.Row():input_text = gr.Textbox(placeholder="请输入要分类的文本...", label="输入文本")with gr.Row():submit_button = gr.Button("提交")with gr.Row():output_label = gr.HighlightedText(label="分类结果")# 设置按钮点击事件,触发分类函数submit_button.click(classify_tokens, inputs=input_text, outputs=output_label)# 启动Gradio应用
if __name__ == "__main__":demo.launch()
运行上述代码,我们可以看到URL信息:
* Running on local URL: http://127.0.0.1:7860To create a public link, set `share=True` in `launch()`.
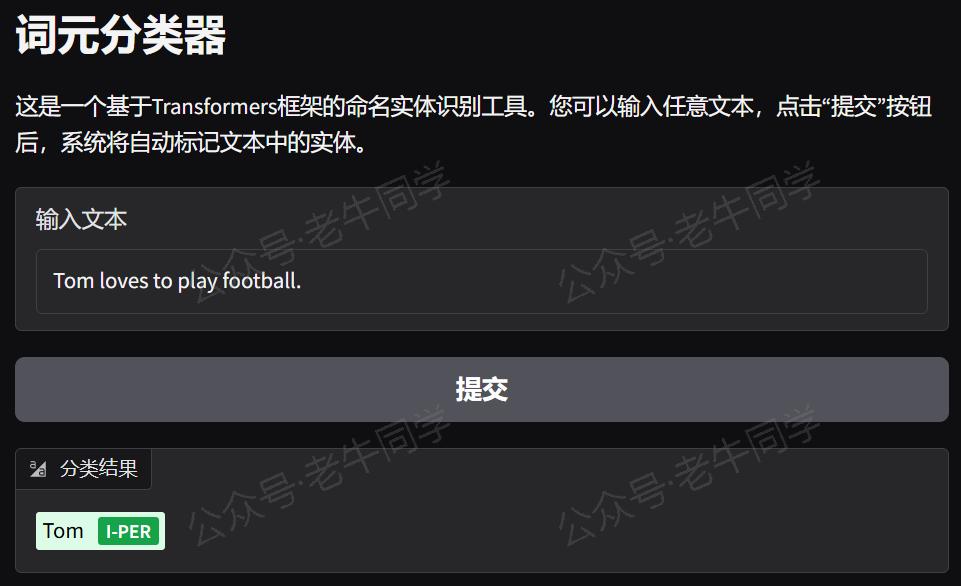
通过浏览器打开地址,就可以通过可视化的方式进行词元分类了:
7. 总结
本文详细介绍了Transformers框架中的token-classification任务,涵盖了任务描述、应用场景、示例代码以及具体的实战案例。通过使用Transformers的Pipeline API,我们可以轻松地实现词元分类任务,而无需深入了解复杂的模型结构和算法。无论是命名实体识别、分词还是词性标注,Transformers框架都能提供强大的支持,帮助您快速构建高效的文字处理系统。
老牛同学将继续推出更多关于Transformers框架Pipeline任务的文章,敬请期待!大家若有任何问题或建议,欢迎在评论区留言交流!
Pipeline任务:
Transformers 框架任务概览:从零开始掌握 Pipeline(管道)与 Task(任务)
Transformers框架 Pipeline 任务详解:文本转音频(text-to-audio或text-to-speech)
Transformers 框架 Pipeline 任务详解:文本分类(text-classification)
往期推荐文章:
深入解析 Transformers 框架(一):包和对象加载中的设计巧思与实用技巧
深入解析 Transformers 框架(二):AutoModel 初始化及 Qwen2.5 模型加载全流程
深入解析 Transformers 框架(三):Qwen2.5 大模型的 AutoTokenizer 技术细节
深入解析 Transformers 框架(四):Qwen2.5/GPT 分词流程与 BPE 分词算法技术细节详解
基于 Qwen2.5-Coder 模型和 CrewAI 多智能体框架,实现智能编程系统的实战教程
vLLM CPU 和 GPU 模式署和推理 Qwen2 等大语言模型详细教程
基于 Qwen2/Lllama3 等大模型,部署团队私有化 RAG 知识库系统的详细教程(Docker+AnythingLLM)
使用 Llama3/Qwen2 等开源大模型,部署团队私有化 Code Copilot 和使用教程
基于 Qwen2 大模型微调技术详细教程(LoRA 参数高效微调和 SwanLab 可视化监控)
ChatTTS 长音频合成和本地部署 2 种方式,让你的“儿童绘本”发声的实战教程