文章目录
- 1. 组件简介
- 2. 项目实践
- 2.1 负载均衡
- 2.1.1 需求
- 2.1.2 配置
- 2.1.3 运行
- 2.2 故障转移
- 2.2.1 需求
- 2.2.2 配置
- 2.2.3 运行
1. 组件简介
Sink Processors类型包括这三种:Default Sink Processor、Load balancing Sink Processor和Failover Sink Processor。
- Default Sink Processor是默认的,不用配置Sink group,就是咱们现在使用的这种最普通的形式,一个Channel后面接一个Sink的形式;
- Load balancing Sink Processor是负载均衡处理器,一个Channle后面可以接多个Sink,这多个Sink属于一个Sink group,根据指定的算法进行轮询或者随机发送,减轻单个Sink的压力;
- Failover Sink Processor是故障转移处理器,一个Channle后面可以接多个Sink,这多个Sink属于一个Sink group,按照Sink的优先级,默认先让优先级高的Sink来处理数据,如果这个Sink出现了故障,则用优先级低一点的Sink处理数据,可以保证数据不丢失。
2. 项目实践
2.1 负载均衡
使用Load balancing Sink Processor,即负载均衡处理器,一个Channle后面可以接多个Sink,这多个Sink属于一个Sink group,根据指定的算法进行轮询或者随机发送,减轻单个Sink的压力。其参数为:
- processor.sinks:指定这个sink groups中有哪些sink,指定sink的名称,多个的话中间使用空格隔开即可;
- processor.type:针对负载均衡的sink处理器,这里需要指定load_balance;
- processor.selector:此参数的值内置支持两个,round_robin和random,round_robin表示轮询,按照sink的顺序,轮流处理数据,random表示随机。
- processor.backoff:默认为false,设置为true后,故障的节点会列入黑名单,过一定时间才会再次发送数据,如果还失败,则等待时间是指数级增长,一直到达到最大的时间。如果不开启,故障的节点每次还会被重试发送,如果真有故障节点的话就会影响效率;
- processor.selector.maxTimeOut:最大的黑名单时间,默认是30秒。
2.1.1 需求
采集指定端口的数据,并实现两个sink通道的负载均衡,采用轮询方式发送数据,为了展现实验效果,使用avro sink,每到一个event就写一次数据(默认是积攒接收一百个再写一次数据)。
2.1.2 配置
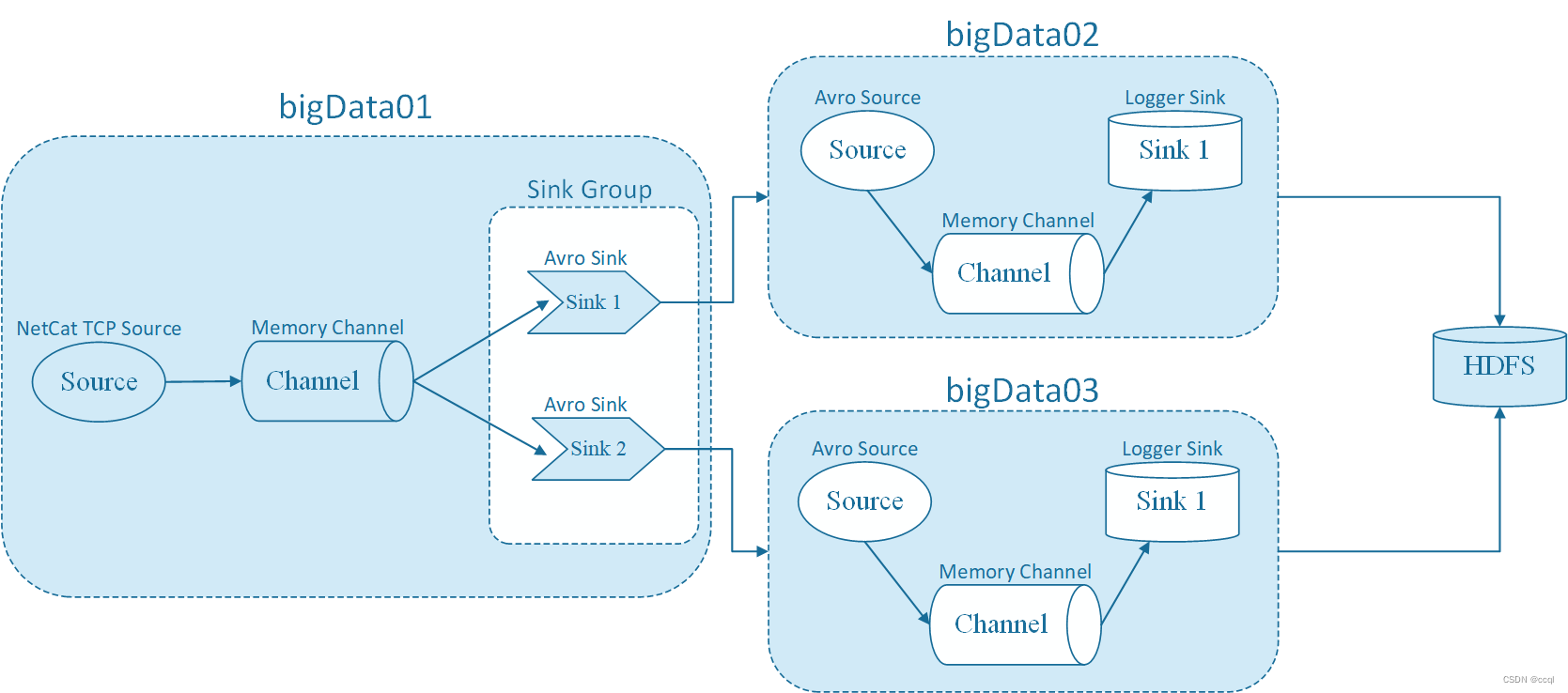
配置bigData01上的Flume Agent:
[root@bigdata01 apache-flume-1.9.0-bin]# cat conf/load-balancing.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
# 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件,[为了方便演示效果,把batch-size设置为1]
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=192.168.152.101
a1.sinks.k1.port=41414
a1.sinks.k1.batch-size = 1
a1.sinks.k2.type=avro
a1.sinks.k2.hostname=192.168.152.102
a1.sinks.k2.port=41414
a1.sinks.k2.batch-size = 1
# 配置sink策略
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin # 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
配置bigData02上的Flume Agent:
[root@bigdata02 apache-flume-1.9.0-bin]# cat conf/load-balancing-101.conf
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件[为了区分两个sink组件生成的文件,修改filePrefix的值]
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.152.100:9000/load_balance
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = data101
a1.sinks.k1.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置bigData03上的Flume Agent:
[root@bigdata03 apache-flume-1.9.0-bin]# cat conf/load-balancing-102.conf
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件[为了区分两个sink组件生成的文件,修改filePrefix的值]
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.152.100:9000/load_balance
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = data102
a1.sinks.k1.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.1.3 运行
先启动bigdata02和bigdata03上的Agent,最后启动bigdata01上的Agent:
[apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/load-balancing-101.conf -Dflume.root.logger=INFO,console
[apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/load-balancing-102.conf -Dflume.root.logger=INFO,console
apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/load-balancing.conf -Dflume.root.logger=INFO,console
向指定端口发送数据,模拟输入:
[root@bigdata01 apache-flume-1.9.0-bin]# telnet localhost 44444
Trying ::1...
Connected to localhost.
Escape character is '^]'.
hehe
OK
haha
OK
查看HDFS中的保存的运行结果:
[root@bigdata01 apache-flume-1.9.0-bin]# hdfs dfs -ls -R /
-rw-r--r-- 2 root supergroup 175 2023-06-22 00:08 /README.txt
drwxr-xr-x - root supergroup 0 2023-06-22 00:47 /load_balance
-rw-r--r-- 2 root supergroup 6 2023-06-22 00:47 /load_balance/data101.1687366028115.log.tmp
-rw-r--r-- 2 root supergroup 6 2023-06-22 00:47 /load_balance/data102.1687366024769.log.tmp
[root@bigdata01 apache-flume-1.9.0-bin]# hdfs dfs -cat /load_balance/data101.1687366028115.log.tmp
haha
[root@bigdata01 apache-flume-1.9.0-bin]# hdfs dfs -cat /load_balance/data102.1687366024769.log.tmp
hehe
2.2 故障转移
使用Failover Sink Processor,即故障转移处理器,一个channle后面可以接多个sink,这多个sink属于一个sink group,按照sink的优先级,默认先让优先级高的sink来处理数据,如果这个sink出现了故障,则用优先级低一点的sink处理数据,可以保证数据不丢失。其参数为:
- processor.type:针对故障转移的sink处理器,使用failover;
- processor.priority.:指定sink group中每一个sink组件的优先级,默认情况下channel中的数据会被优先级比较高的sink取走;
- processor.maxpenalty:sink发生故障之后,最大等待时间。
2.2.1 需求
实现两个sink的故障转移。
2.2.2 配置
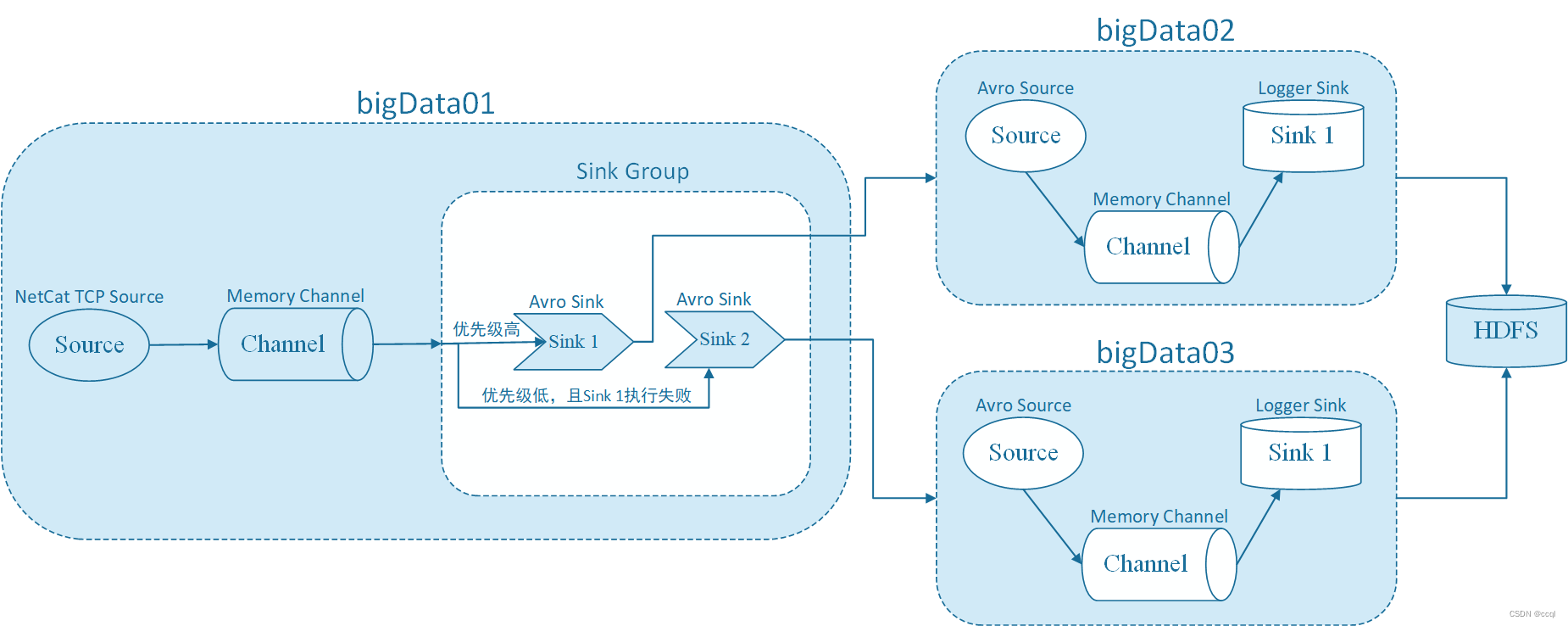
配置bigData01上的Flume Agent:
[root@bigdata01 conf]# cat failover.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
# 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件,[为了方便演示效果,把batch-size设置为1]
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.152.101
a1.sinks.k1.port = 41414
a1.sinks.k1.batch-size = 1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = 192.168.152.102
a1.sinks.k2.port = 41414
a1.sinks.k2.batch-size = 1
# 配置sink策略
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
配置bigData02上的Flume Agent:
[root@bigdata02 conf]# cat failover-101.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件[为了区分两个sink组件生成的文件,修改filePrefix的值]
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.152.100:9000/failover
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = data101
a1.sinks.k1.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置bigData03上的Flume Agent:
[root@bigdata03 conf]# cat failover-102.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件[为了区分两个sink组件生成的文件,修改filePrefix的值]
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.152.100:9000/failover
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = data102
a1.sinks.k1.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.2.3 运行
- 先启动bigdata02和bigdata03上的Agent,最后启动bigdata01上的Agent:
bin/flume-ng agent --name a1 --conf conf --conf-file conf/failover-101.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent --name a1 --conf conf --conf-file conf/failover-102.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent --name a1 --conf conf --conf-file conf/failover.conf -Dflume.root.logger=INFO,console
- 向指定端口发送数据,模拟输入两个数据
test1和test2:
[root@bigdata01 apache-flume-1.9.0-bin]# telnet localhost 44444
Trying ::1...
Connected to localhost.
Escape character is '^]'.
test1
OK
test2
OK
- 查看HDFS中的保存的运行结果:
因为bigdata03的优先级高,可以看到两个数据都是由其写入。
[root@bigdata01 hadoop-3.3.5]# hdfs dfs -ls -R /
-rw-r--r-- 2 root supergroup 175 2023-06-22 00:08 /README.txt
drwxr-xr-x - root supergroup 0 2023-06-22 09:51 /failover
-rw-r--r-- 2 root supergroup 7 2023-06-22 09:51 /failover/data102.1687398676525.log.tmp
drwxr-xr-x - root supergroup 0 2023-06-22 00:52 /load_balance
-rw-r--r-- 2 root supergroup 6 2023-06-22 00:52 /load_balance/data101.1687366028115.log
-rw-r--r-- 2 root supergroup 6 2023-06-22 00:52 /load_balance/data102.1687366024769.log
[root@bigdata01 hadoop-3.3.5]# hdfs dfs -cat /failover/data102.1687398676525.log.tmp
test1
test2
- 关闭bigdata03,再输入测试数据
test3
[root@bigdata01 apache-flume-1.9.0-bin]# telnet localhost 44444
Trying ::1...
Connected to localhost.
Escape character is '^]'.
test1
OK
test2
OK
test3
OK
- 查看HDFS中的保存的运行结果:
关闭bigdata03后,数据就由优先度较低的bigdata02写入,保证数据不丢失,达到故障转移的目的,此时若再次开启bigdata03,则数据就又会由优限度更高的bigdata03传输。
[root@bigdata01 hadoop-3.3.5]# hdfs dfs -ls -R /
-rw-r--r-- 2 root supergroup 175 2023-06-22 00:08 /README.txt
drwxr-xr-x - root supergroup 0 2023-06-22 09:54 /failover
-rw-r--r-- 2 root supergroup 7 2023-06-22 09:54 /failover/data101.1687398846336.log.tmp
-rw-r--r-- 2 root supergroup 14 2023-06-22 09:53 /failover/data102.1687398676525.log
drwxr-xr-x - root supergroup 0 2023-06-22 00:52 /load_balance
-rw-r--r-- 2 root supergroup 6 2023-06-22 00:52 /load_balance/data101.1687366028115.log
-rw-r--r-- 2 root supergroup 6 2023-06-22 00:52 /load_balance/data102.1687366024769.log
[root@bigdata01 hadoop-3.3.5]# hdfs dfs -cat /failover/data101.1687398846336.log.tmp
test3