| 这个项目属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 组名 | 从你的全世界爬过 团队logo:  |
| 项目简介 | 项目名称:博物识植 项目logo:  项目介绍:在探索自然奥秘的旅途中,我们常与动植物相伴而行,却无法准确识别它们,更难以深入了解他们的特征。为了更好地理解和欣赏自然界的多样性,提升我们对动植物的认识和保护意识,我们需要一个智能系统。该系统能够根据用户拍摄的动植物照片,智能识别并匹配相应的信息,同时为用户提供丰富的学习资源,帮助人们更深入地了解和学习动植物知识。通过这样的方式,我们不仅能够更准确地识别和欣赏周围的生命,还能够在日常生活中,随时随地增长见识,体验探索自然的乐趣。 项目背景:人类的生活离不开动植物的支持,动植物的多样性是一切地球生物的依赖。在生活中随处可见很多动植物,动植物是人类生活必不可少的一部分。 保护大自然保护动植物就是在保护人类自己。在保护动植物的过程中,首先要解决的是动植物识别的问题。 项目意义:提供了一种我们与自然界互动的方式。其应用场景广泛,渗透到了教育、旅游等多个领域。在学校,它可以是生物课程的辅助工具,通过实践学习生物多样性;在旅游行业,它可以帮助游客更好地了解他们所参观的自然景观,提升旅行体验 |
| 团队成员学号 | 042201401陈高菲、102202107王勤琛、102202108王露洁、102202115孙佳会、102202123张铭心、102202130林烨、102202138徐婉瑜、102202140郭心怡 |
| 项目目标 | 本系统旨在实现以下功能: a.图片识别功能:用户上传动植物图片,系统通过图像识别技术自动识别物种,返回准确的物种名称。 b.物种详细信息:识别后,用户将获取该物种的详细信息,包括外形特点、生长环境、分布区域等相关数据。 c.物种图片展示:系统将提供该物种的高质量图片,帮助用户更直观地了解物种特征。 d.名称搜索功能:用户可以手动输入动植物的名称,系统将返回该物种的相关信息,方便快速查询。 e.网站部署上线:通过华为云的弹性计算服务部署网站,确保系统高可用和稳定运行,实现网站上线。 |
| 其他参考文献 | 1.yanjingang/pigimgclassification: 图像分类 2.基于改进SE-MnasNet骨干网络YOLOv5的动植物树木识别系统_开源 树木识别 |
| gitee链接 | 2024学年数据采集与融合技术大作业——博物识植 团队:从你的全世界爬过 |
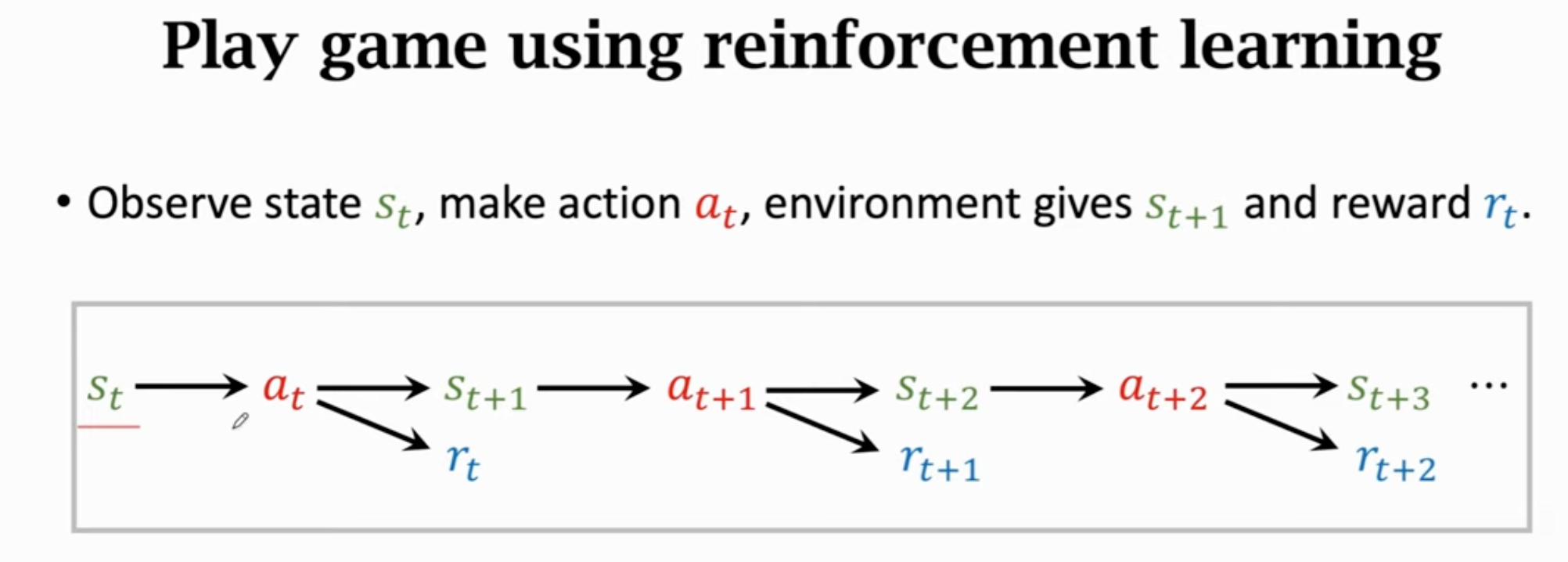
一、系统总体技术概述
1.1 系统架构概述
系统分为前端、后端、数据库、AI接口、爬虫模块、部署等多个层级。前后端之间通过RESTful API进行通信。具体分为以下几个部分:
- 前端:使用HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。用户可以上传文本、图片等文件。
- 后端:使用Python语言和Flask框架实现,处理图像识别、查询请求、调用AI接口和爬虫数据存储等业务逻辑。
- 数据库:存储动植物物种的详细信息,包括图像、分布、特点等。存储物种识别的历史记录信息。
- 图像识别与AI接口:利用图像识别模型或调用第三方AI服务(如百度AI、Google Vision等)识别图片并返回结果。
- 爬虫:提前爬取动植物相关网站数据,补充物种数据库。使用Selenium框架进行实时图片爬取。
- 部署平台:使用华为云平台部署系统,保证系统的高可用和稳定性。
1.2 各模块技术实现
1.2.1 图像识别模块
- 目标:用户上传图片,系统通过图像识别技术返回物种名称。
- 技术方案:
使用深度学习模型:基于改进SE-MnasNet骨干网络YOLOv5和卷积神经网络cnn opencv进行图像分类和识别。
基于识别精确度的考虑调用第三方云服务百度智能云的动植物识别API提供快速而准确的图像识别。 - 流程:
用户上传图片,前端将图片通过API发送至后端。
后端调用模型或AI图像识别API分析图片,获取可能的物种标签。
后端将物种名称返回给前端,前端展示识别结果。
1.2.2 物种信息查询功能
- 目标:根据识别后的物种名称或用户输入的名称,返回该物种的详细信息。
- 技术方案:
利用selenium技术和scrapy框架爬取信息网站所有物种信息(如外形特点生长环境、分布区域等)存储在csv表导入数据库并定期更新。
利用查询语句在数据库中进行查找并返回详细信息。
若数据库中没有相关信息,则调用百度智能云的千帆大模型识别物种名称,查询物种相关信息。 - 流程:
后端识别出物种名称时,系统首先查询数据库,若没有该物种的信息,再调用AI接口获取。
1.2.3 相似图片展示
- 目标:根据用户上传的图片,返回物种的相似图片,帮助用户直观了解物种。
- 技术方案:
运用selenium爬虫技术实时爬取百度识图返回的相似图片 - 流程:
后端接收前端传入的图片后,将图片作为输入文件传入百度识图网站实时爬取相似图片,在系统返回物种详细信息时,将图片URL一并返回。
1.2.4 保存历史记录
- 目标:将用户的历史搜索记录保存至数据库,方便用户在“我的图鉴”页面查看并跳转至物种详情页,随时查看过去的搜索记录。
- 技术方案:
创建一个数据库表专门用来保存用户的搜索记录,包括用户上传的图片、识别出来的物种名称、物种的详细信息(如描述、分布、图片URL等) - 流程:
当用户获取识别结果时,后端系统会将物种信息保存至数据库中。在点击我的图鉴中的物种名称时,后端调取数据库信息展示在前端界面。
1.2.5 部署与部署架构
- 目标:将整个系统部署到华为云服务器上,让非本地用户可以访问。
- 技术方案:
使用华为云ECS(Elastic Cloud Server)部署后端服务。
使用华为云OBS 存储图片等静态资源。
使用RDS(Relational Database Service)存储物种信息数据库。
前端可以使用 Nginx 进行负载均衡和反向代理 - 流程:
前后端文件上传部署完成后即可实现非本地用户的访问。
1.3 源码运行步骤
- gitee仓库下载源码
- 启动文件中的ai.py与database.py文件
- 运行index.html文件
(!注意在本地主机运行代码时请更换代码中的路径名)
二、个人分工
1.前期项目调研与思考
思路是以 前端组(张铭心、孙佳会、王露洁) 为单位挖掘
1.1 同类型app调研
有了初步idea的时候,我们调查了市面上现有的app,例如“形色”、“花伴侣”等app,以及“识花君”、“懂鸟”小程序
我们发现了这些软件都已具备的功能有:
- 识别植物/动物(图片/音频eg.叫声)
- 返回对应名称/百科/地图
- 发帖分享
以形色为例(个人认为相对其他的页面和功能都相对完善):

1.主要以帖子分享的形式产生结果,包括其他现有的app更注重互动性,而缺少直接记录的功能,更多是查了就走,知识也就是“一轮游”了!
↓
这里在构建软件的时候选择开发的是存储功能,替换了普遍的发帖分享。
也是观察到市面上基本上是以发帖形式记录,而我们更倾向于拥有一个属于自己的、更直观的小百科,所以还是把小识图鉴抬上来力
2.现有动物识别应用也很少,大部分都是在某一个物种上、对单一数据类型进行处理的专精识别,泛用性低!
3.再观察现有动植物科普网站,模块划分都有点混乱,更适用于专业人员,热爱自然的小白更是难以上手!
↓
鉴于我们探索自然的好奇心之宽广,动物也好、植物也罢,需要在各大小程序、app上跳转以悉知各生物实在是麻烦,所以我们推出了“博物识植”网站!
旨在将上述我们需要的功能(动植物识别、搜索、百科查看与存储)集成在一个网站上!
1.2 接口功能考虑
原本我们意向的识别功能是:上传图片+文字描述/仅图片/仅文字 → 识别结果
经过考虑,文字描述获得识别结果实在不大可能,我们的描述还是很难接近现实的正确答案的
因此,最后修改为:
- 上传图片->识别结果
- 输入物种名称->搜索百科
2.项目整体架构搭建
使用工具的确定:
前端:HBuilderX(html、css、JavaScript)
后端:Python flask
采用前后端分离的形式
2.1 前端整体设计
通过初步调研的结果我开始设计前端
主要设计了四大页面
- 拍拍园地(首页:项目及其团队的特色介绍)
- 植物百科(植物识别页面:识别图片/搜索物种并返回结果 注:结果也是一个details页面)
- 动物绘本(动物识别页面:同上)
- 我的图鉴(将搜索的结果通过点击“记录”键存入小识图鉴)
整体采用符合项目主题的绿色清新风,干净整洁的ui设计是让生物爱好者在此停留品味自然的关键。
同时我也自主通过ai设计了项目logo和团队logo,很好地将主题融入设计中。
本人主要完成页面为拍拍园地、我的图鉴,以及识别页面的完善:
完成页面展示:
①首页-拍拍园地+顶部导航栏设计
②我的图鉴(2.2详细介绍技术)
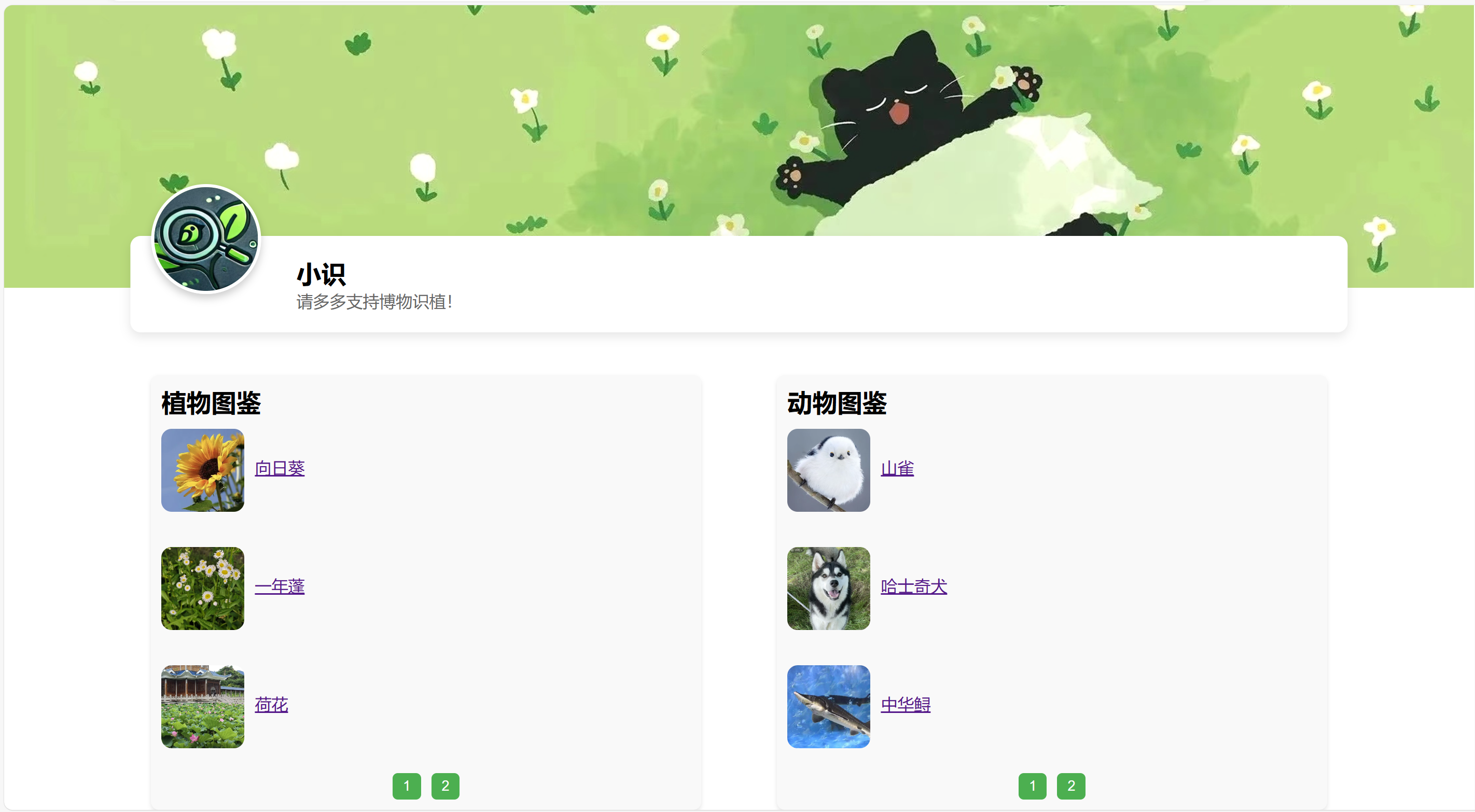
2.2 图鉴记录功能
思路构建(思路很简单,关键是对获取的数据进行处理,以及构建好数据库的连接):
- 将details页面获取的各种数据封装存入MySQL数据库
- 根据存入的动植物id调取数据库内容并显示
*注:这里后续配合了华为云上传处理的高菲同学完成了云部署
功能实现的过程失败了很多次
整理失败原因:
1.本地上传的图片url非常长,一开始仅设计变量类型为varchar只有255个字符不足以存储
解决:改为text,但还是太长了,最终修改为longtext成功存储
2.由于前后端是分离的,按照平时上课的方式按照template文件夹存放html的方式做是错误的
解决:将路径标明,同时接收跨域请求cors,注意端口号不要和之前的ai接口python文件重复,不然同时运行会出问题
3.处理实时爬取图片的数据是一个难题,爬取的路径比较复杂,不能直接以单个标点(例如逗号)分隔出url列表
解决:用正则表达式划分,以http开头为一个单位
或者后续直接以http作为分隔符,后续再给列表里的url加入http头
实现前后端代码关键部分(点击可展开查看详情):
图鉴详情数据处理调出脚本代码
<script>// 获取 URL 中的植物 IDconst urlParams = new URLSearchParams(window.location.search);const plantId = urlParams.get('id');// 如果没有获取到 ID,则跳转到错误页面或做提示if (!plantId) {alert("植物ID未提供!");window.location.href = "plants_get.html"; // 如果没有ID,跳转到植物列表页}// 调用后端接口获取植物详情fetch(`http://localhost:5001/api/get_plant_details?id=${plantId}`).then(response => response.json()).then(data => {if (data.status === 'success') {const plant = data.plant;// 填充页面内容document.getElementById('plant-name').textContent = plant.name;document.getElementById('plant-image').src = plant.image_url;document.getElementById('plant-image').alt = plant.name;document.getElementById('plant-details').textContent = plant.details;// 填充相似图片const similarImagesList = document.getElementById('similar-images-list');similarImagesList.innerHTML = ''; // 清空现有内容// 如果相似图片存在并且不为空if (plant.similar_images && plant.similar_images.trim() !== "") {// 使用http为分隔符将字符串转换为数组const similarImagesArray = plant.similar_images.split('http').map(url => url.trim()).filter(url => url !== "");// 添加每个图片 URL 前的 http 并渲染成图片const similarImagesList = document.getElementById('similar-images-list');similarImagesArray.forEach(imageUrl => {// 每个 imageUrl 加上 httpconst fullImageUrl = "http" + imageUrl;// 创建新的 li 和 img 标签const listItem = document.createElement('li');const imgTag = document.createElement('img');imgTag.src = fullImageUrl; // 设置图片的源imgTag.alt = "相似图片"; // 图片的alt文本listItem.appendChild(imgTag); // 将 img 添加到 li 中similarImagesList.appendChild(listItem); // 将 li 添加到 ul 中});}} else {alert("未找到植物信息!");}}).catch(error => {console.error('获取植物详情失败:', error);alert("无法加载植物详情!");});
</script>
图鉴调出显示脚本代码
<script>// 初始化当前页码let currentPlantPage = 1;let currentAnimalPage = 1;// 每页显示的记录数const recordsPerPage = 3;// 获取植物数据并渲染function fetchPlants(page) {fetch(`http://localhost:5001/api/get_plants?page=${page}`).then(response => response.json()).then(data => {if (data.status === "success") {renderPlants(data.plants); // 渲染植物数据renderPagination(data.total_pages, 'plants-pagination', fetchPlants); // 渲染植物分页按钮} else {alert('加载植物数据失败');}}).catch(error => {console.error('Error:', error);alert('获取植物数据失败');});}// 渲染植物数据function renderPlants(plants) {const container = document.getElementById('plants-container');container.innerHTML = '';plants.forEach(plant => {if (!plant.id) {console.error('植物ID缺失:', plant);return;}const plantItem = document.createElement('div');plantItem.classList.add('plant-item');plantItem.innerHTML = `<div class="plant-image"><img src="${plant.image_url}" alt="${plant.name}" /></div><div class="my-name"><a href="my_details.html?id=${plant.id}">${plant.name}</a></div>`;container.appendChild(plantItem);});}// 获取动物数据并渲染function fetchAnimals(page) {fetch(`http://localhost:5001/api/get_animals?page=${page}`).then(response => response.json()).then(data => {if (data.status === "success") {renderAnimals(data.animals); // 渲染动物数据renderPagination(data.total_pages, 'animals-pagination', fetchAnimals); // 渲染动物分页按钮} else {alert('加载动物数据失败');}}).catch(error => {console.error('Error:', error);alert('获取动物数据失败');});}// 渲染动物数据function renderAnimals(animals) { // 修改参数名为 'animals'const container = document.getElementById('animals-container');container.innerHTML = '';animals.forEach(animal => { // 使用正确的变量名if (!animal.id) {console.error('动物ID缺失:', animal);return;}const animalItem = document.createElement('div');animalItem.classList.add('animal-item');animalItem.innerHTML = `<div class="animal-image"><img src="${animal.image_url}" alt="${animal.name}" /></div><div class="my-name"><a href="my_details_animal.html?id=${animal.id}">${animal.name}</a></div>`;container.appendChild(animalItem);});}// 渲染分页按钮function renderPagination(totalPages, paginationId, fetchFunction) {const pagination = document.getElementById(paginationId);pagination.innerHTML = '';for (let i = 1; i <= totalPages; i++) {const pageButton = document.createElement('button');pageButton.textContent = i;pageButton.classList.add('pagination-button');pageButton.onclick = () => {fetchFunction(i);};pagination.appendChild(pageButton);}}// 页面加载时,加载第一页的植物和动物数据document.addEventListener('DOMContentLoaded', () => {fetchPlants(currentPlantPage);fetchAnimals(currentAnimalPage);});</script>
数据库连接后端代码
from flask import Flask, request, jsonify
import mysql.connector
from mysql.connector import Error
from flask_cors import CORSapp = Flask(__name__)
CORS(app) # 允许所有来源的跨域请求def get_db_connection():try:connection = mysql.connector.connect(host='ip已覆盖',database='plants_and_animals',user='root',password='密码已覆盖')if connection.is_connected():print("成功连接到数据库")return connectionexcept Error as e:print(f"连接数据库失败: {e}")return None@app.route('/api/save_plant', methods=['POST'])
def save_plant():try:data = request.get_json()if not data:return jsonify({'status': 'fail', 'message': '未提供数据'}), 400name = data.get('plant_name')image_url = data.get('image_url') # 获取图片路径(而非 base64)similar_images = data.get('similar_images')details = data.get('details')if not name or not image_url:return jsonify({'status': 'fail', 'message': '植物名称和图片是必填项'}), 400connection = get_db_connection()if connection is None:return jsonify({'status': 'fail', 'message': '无法连接到数据库'}), 500cursor = connection.cursor()# 插入数据insert_query = """INSERT INTO plants (name, image_url, details, similar_images)VALUES (%s, %s, %s, %s)"""cursor.execute(insert_query, (name, image_url, details, similar_images))connection.commit()cursor.close()connection.close()return jsonify({'status': 'success', 'message': '植物信息已保存'}), 200except Exception as e:print(f"数据库操作失败: {e}")return jsonify({'status': 'fail', 'message': str(e)}), 500@app.route('/api/save_animal', methods=['POST'])
def save_animal():try:data = request.get_json()if not data:return jsonify({'status': 'fail', 'message': '未提供数据'}), 400name = data.get('animal_name')image_url = data.get('image_url') # 获取图片路径(而非 base64)similar_images = data.get('similar_images')details = data.get('details')if not name or not image_url:return jsonify({'status': 'fail', 'message': '动物名称和图片是必填项'}), 400connection = get_db_connection()if connection is None:return jsonify({'status': 'fail', 'message': '无法连接到数据库'}), 500cursor = connection.cursor()# 插入数据insert_query = """INSERT INTO animals (name, image_url, details, similar_images)VALUES (%s, %s, %s, %s)"""cursor.execute(insert_query, (name, image_url, details, similar_images))connection.commit()cursor.close()connection.close()return jsonify({'status': 'success', 'message': '动物信息已保存'}), 200except Exception as e:print(f"数据库操作失败: {e}")return jsonify({'status': 'fail', 'message': str(e)}), 500@app.route('/api/get_plants', methods=['GET'])
def get_plants():try:page = int(request.args.get('page', 1)) # 获取当前页,默认是第一页per_page = 3 # 每页显示 3 条记录offset = (page - 1) * per_page # 计算偏移量# 获取数据库连接connection = get_db_connection()if connection is None:return jsonify({'status': 'fail', 'message': '无法连接到数据库'}), 500cursor = connection.cursor(dictionary=True)# 修改后的查询,包含 id 字段query = f"""SELECT id, name, image_url FROM plantsLIMIT {per_page} OFFSET {offset};"""cursor.execute(query)plants = cursor.fetchall()# 获取总植物数量,用于分页cursor.execute("SELECT COUNT(*) AS total FROM plants")total_count = cursor.fetchone()['total']# 计算总页数total_pages = (total_count // per_page) + (1 if total_count % per_page != 0 else 0)return jsonify({'status': 'success','plants': plants,'total_pages': total_pages})except Error as e:return jsonify({'status': 'fail', 'message': str(e)}), 500@app.route('/api/get_animals', methods=['GET'])
def get_animals():try:page = int(request.args.get('page', 1)) # 获取当前页,默认是第一页per_page = 3 # 每页显示 3 条记录offset = (page - 1) * per_page # 计算偏移量# 获取数据库连接connection = get_db_connection()if connection is None:return jsonify({'status': 'fail', 'message': '无法连接到数据库'}), 500cursor = connection.cursor(dictionary=True)# 修改后的查询,包含 id 字段query = f"""SELECT id, name, image_url FROM animalsLIMIT {per_page} OFFSET {offset};"""cursor.execute(query)animals = cursor.fetchall()# 获取总植物数量,用于分页cursor.execute("SELECT COUNT(*) AS total FROM animals")total_count = cursor.fetchone()['total']# 计算总页数total_pages = (total_count // per_page) + (1 if total_count % per_page != 0 else 0)return jsonify({'status': 'success','animals': animals,'total_pages': total_pages})except Error as e:return jsonify({'status': 'fail', 'message': str(e)}), 500@app.route('/api/get_plant_details', methods=['GET'])
def get_plant_details():try:plant_id = request.args.get('id')if not plant_id:return jsonify({'status': 'fail', 'message': '未提供植物ID'}), 400print(f"接收到的植物ID: {plant_id}") # 添加调试输出connection = get_db_connection()if connection is None:return jsonify({'status': 'fail', 'message': '无法连接到数据库'}), 500cursor = connection.cursor(dictionary=True)# 查询指定ID的植物信息query = """SELECT name, image_url, details, similar_images FROM plantsWHERE id = %s;"""cursor.execute(query, (plant_id,))plant = cursor.fetchone()cursor.close()connection.close()if plant:print(f"查询到的植物数据: {plant}") # 添加调试输出return jsonify({'status': 'success', 'plant': plant}), 200else:return jsonify({'status': 'fail', 'message': '未找到指定植物'}), 404except Error as e:print(f"数据库操作失败: {e}")return jsonify({'status': 'fail', 'message': '数据库操作失败'}), 500except Exception as e:print(f"发生错误: {e}")return jsonify({'status': 'fail', 'message': '发生错误'}), 500@app.route('/api/get_animal_details', methods=['GET'])
def get_animal_details():try:animal_id = request.args.get('id')if not animal_id:return jsonify({'status': 'fail', 'message': '未提供动物ID'}), 400print(f"接收到的动物ID: {animal_id}") # 添加调试输出connection = get_db_connection()if connection is None:return jsonify({'status': 'fail', 'message': '无法连接到数据库'}), 500cursor = connection.cursor(dictionary=True)# 查询指定ID的动物信息query = """SELECT name, image_url, details, similar_images FROM animalsWHERE id = %s;"""cursor.execute(query, (animal_id,))animal = cursor.fetchone() # 修改变量名为 'animal'cursor.close()connection.close()if animal:print(f"查询到的动物数据: {animal}") # 添加调试输出return jsonify({'status': 'success', 'animal': animal}), 200 # 修改键名为 'animal'else:return jsonify({'status': 'fail', 'message': '未找到指定动物'}), 404except Error as e:print(f"数据库操作失败: {e}")return jsonify({'status': 'fail', 'message': '数据库操作失败'}), 500except Exception as e:print(f"发生错误: {e}")return jsonify({'status': 'fail', 'message': '发生错误'}), 500if __name__ == '__main__':app.run(host='0.0.0.0', port=5001, debug=True)功能实现展示:
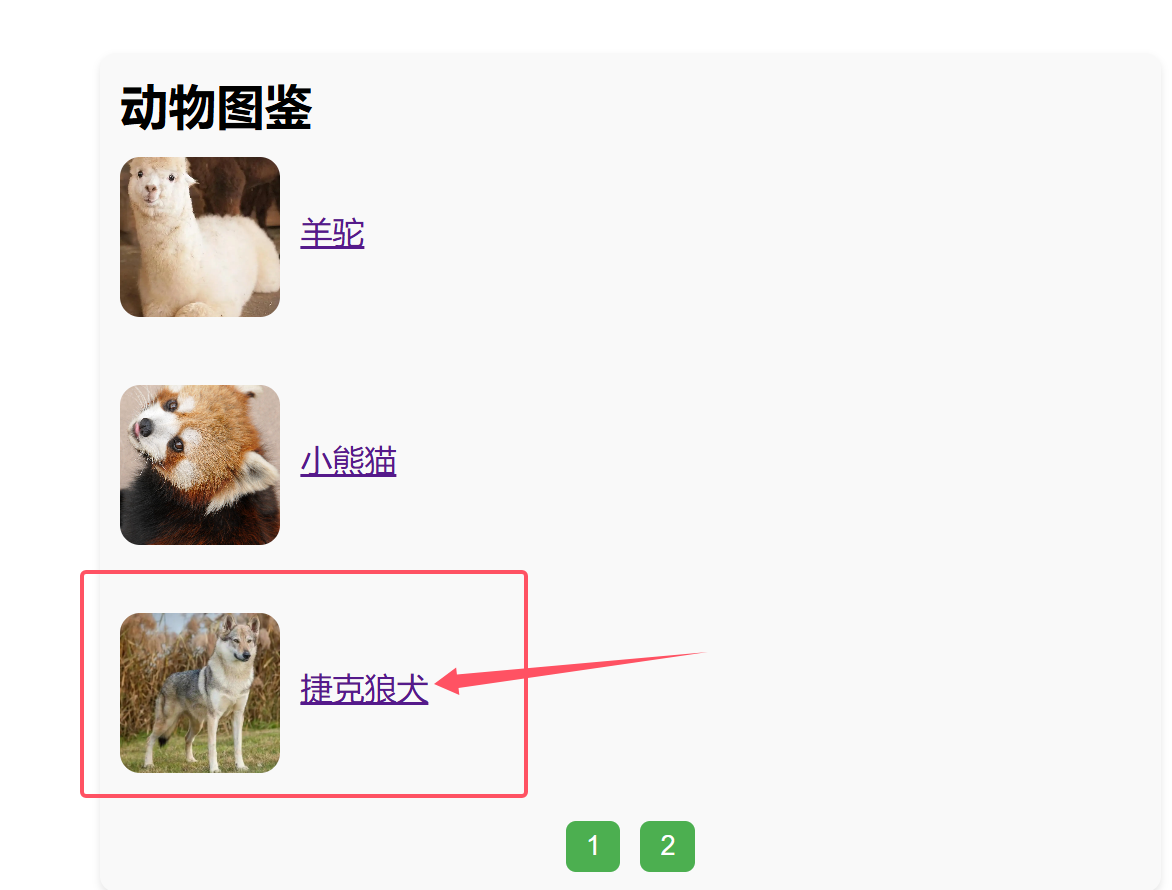
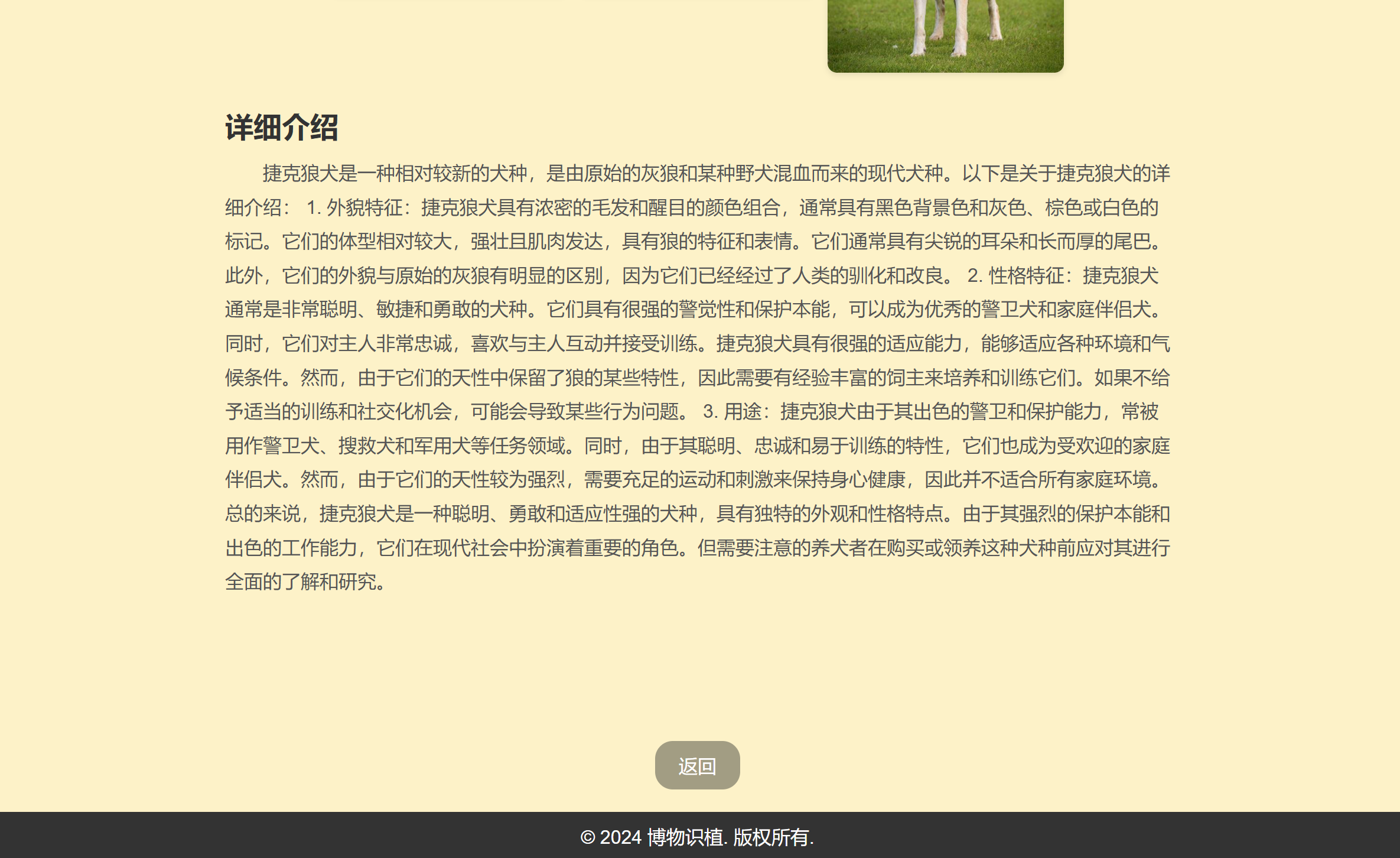
1.在识别详情界面点击“记录”获得记录响应
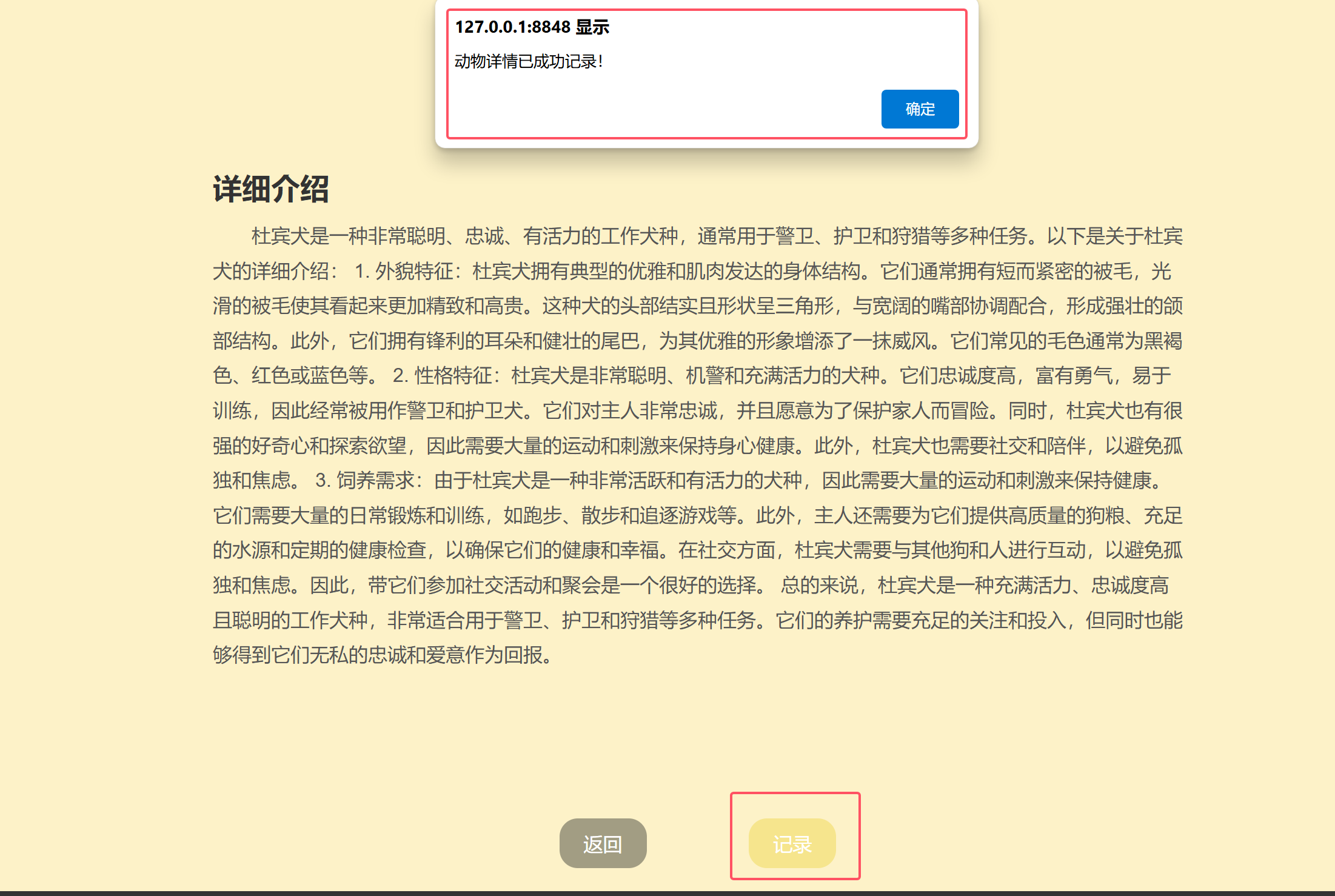

2.到我的图鉴处点击记录名称即可从数据库获取数据显示在界面上

3.识别页面的完善
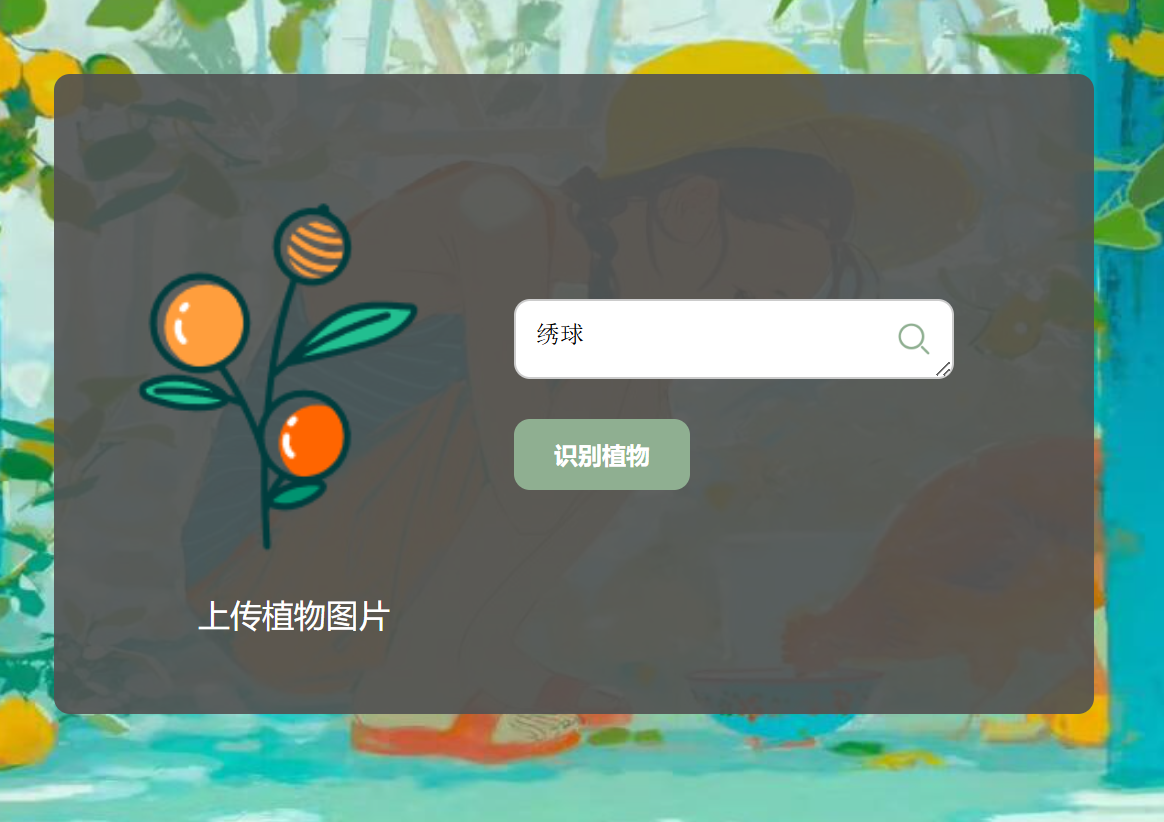
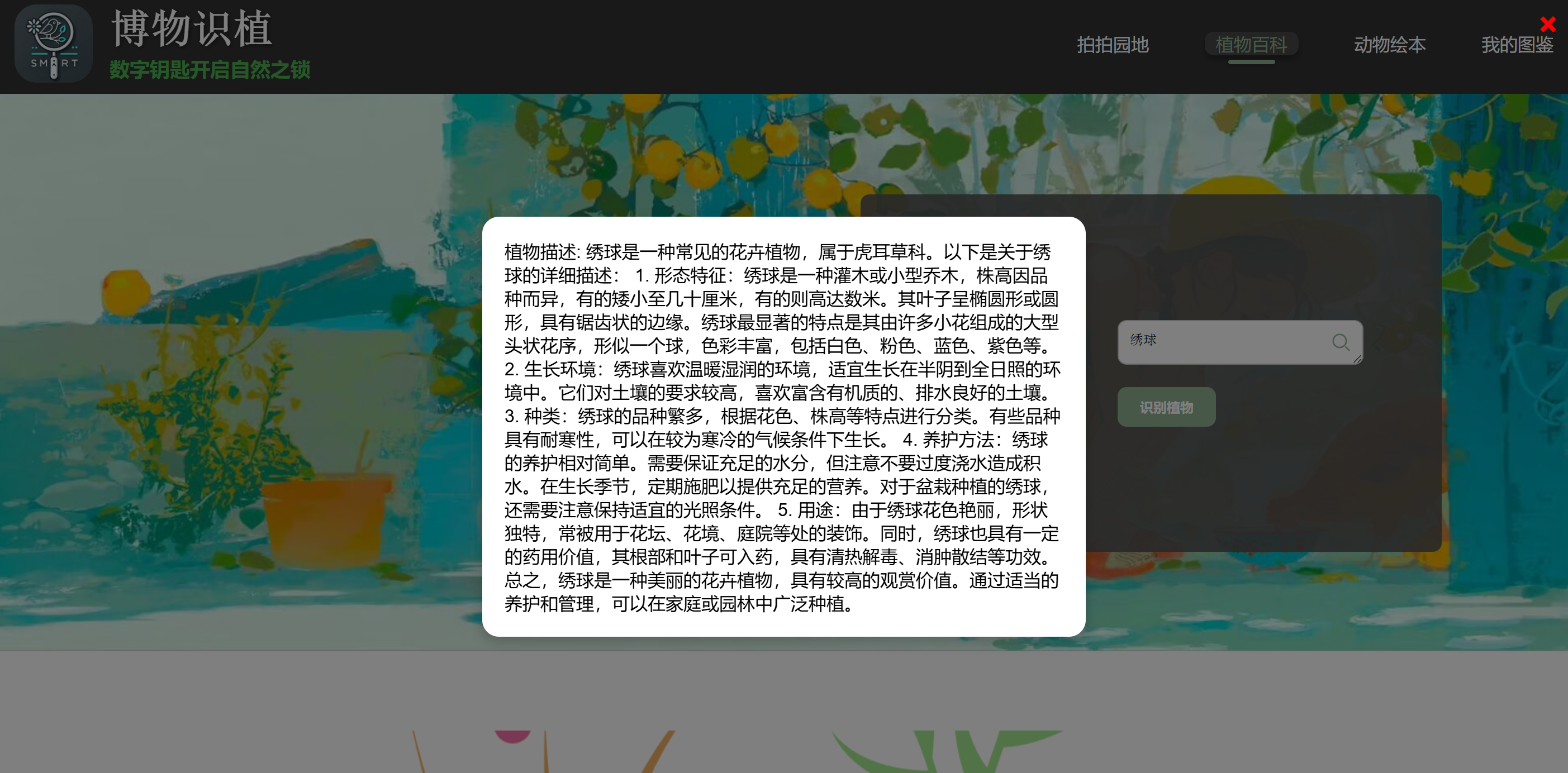
前面也说明了项目推进过程的idea修改过程——推出了直接搜索关键词的功能
优化了搜索框的样式,添加了弹窗显示功能:
个人感想
这次数据采集大作业学到了很多!
虽然爬虫不是我负责的,这个实时爬取显示相似图片的idea是大家一起为了丰富界面想出来的。在看着实时爬虫写进后端在识别的时候一起实现的过程,我们都觉得很欣喜,有了相似图片的参照也可以作为判别识别准确度的一个指标。
其次,由于用了好多接口:①ai识图打tag的接口 ②实时爬虫的接口 ③传送tag给数据库判别是否在csv文件的接口 ④千帆大模型获得百科详情的接口,也是第一次把这么多接口都集成在一个功能按键上,前端的构建也花费了一定的时间!(这个最终不是我做出来的,也和前端组组员一起试错了很多次识别结果的显示)我们的网站需要等待较长时间,但好在结果都很丰富可观!
最后也是在部署上掺和了一脚,发现了没给前端配端口的bug。写博客的时候还在配合推进云端的部署,现在还是觉得华为云把大家都害惨了无数次()方法总比困难多了!
等等,最后的最后,请多多支持我们小识吧!TT